目录
一、实验介绍
二、实验环境
1. 配置虚拟环境
2. 库版本介绍
三、实验内容
0. 导入必要的工具包
1. 逻辑回归Logistic类
a. 构造函数__init__
b. __call__(self, x)方法
c. 前向传播forward
d. 反向传播backward
2. 模型训练
3. 代码整合
一、实验介绍
- 实现逻辑回归模型(Logistic类)
- 实现前向传播forward
- 实现反向传播backward
二、实验环境
本系列实验使用了PyTorch深度学习框架,相关操作如下:
1. 配置虚拟环境
conda create -n DL python=3.7 conda activate DLpip install torch==1.8.1+cu102 torchvision==0.9.1+cu102 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
conda install matplotlib conda install scikit-learn2. 库版本介绍
| 软件包 | 本实验版本 | 目前最新版 |
| matplotlib | 3.5.3 | 3.8.0 |
| numpy | 1.21.6 | 1.26.0 |
| python | 3.7.16 | |
| scikit-learn | 0.22.1 | 1.3.0 |
| torch | 1.8.1+cu102 | 2.0.1 |
| torchaudio | 0.8.1 | 2.0.2 |
| torchvision | 0.9.1+cu102 | 0.15.2 |
三、实验内容
ChatGPT:
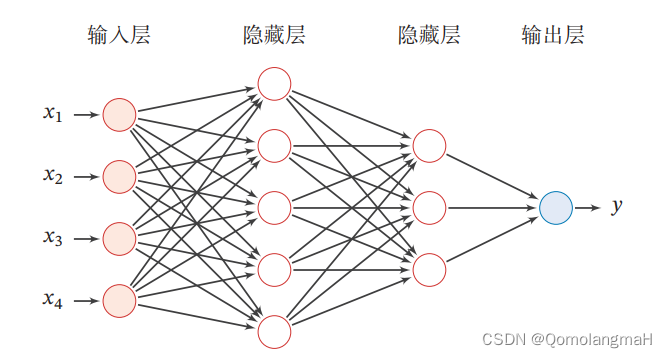
前馈神经网络(Feedforward Neural Network)是一种常见的人工神经网络模型,也被称为多层感知器(Multilayer Perceptron,MLP)。它是一种基于前向传播的模型,主要用于解决分类和回归问题。
前馈神经网络由多个层组成,包括输入层、隐藏层和输出层。它的名称"前馈"源于信号在网络中只能向前流动,即从输入层经过隐藏层最终到达输出层,没有反馈连接。
以下是前馈神经网络的一般工作原理:
输入层:接收原始数据或特征向量作为网络的输入,每个输入被表示为网络的一个神经元。每个神经元将输入加权并通过激活函数进行转换,产生一个输出信号。
隐藏层:前馈神经网络可以包含一个或多个隐藏层,每个隐藏层由多个神经元组成。隐藏层的神经元接收来自上一层的输入,并将加权和经过激活函数转换后的信号传递给下一层。
输出层:最后一个隐藏层的输出被传递到输出层,输出层通常由一个或多个神经元组成。输出层的神经元根据要解决的问题类型(分类或回归)使用适当的激活函数(如Sigmoid、Softmax等)将最终结果输出。
前向传播:信号从输入层通过隐藏层传递到输出层的过程称为前向传播。在前向传播过程中,每个神经元将前一层的输出乘以相应的权重,并将结果传递给下一层。这样的计算通过网络中的每一层逐层进行,直到产生最终的输出。
损失函数和训练:前馈神经网络的训练过程通常涉及定义一个损失函数,用于衡量模型预测输出与真实标签之间的差异。常见的损失函数包括均方误差(Mean Squared Error)和交叉熵(Cross-Entropy)。通过使用反向传播算法(Backpropagation)和优化算法(如梯度下降),网络根据损失函数的梯度进行参数调整,以最小化损失函数的值。
前馈神经网络的优点包括能够处理复杂的非线性关系,适用于各种问题类型,并且能够通过训练来自动学习特征表示。然而,它也存在一些挑战,如容易过拟合、对大规模数据和高维数据的处理较困难等。为了应对这些挑战,一些改进的网络结构和训练技术被提出,如卷积神经网络(Convolutional Neural Networks)和循环神经网络(Recurrent Neural Networks)等。
本系列为实验内容,对理论知识不进行详细阐释
(咳咳,其实是没时间整理,待有缘之时,回来填坑)
0. 导入必要的工具包
import torch1. 逻辑回归Logistic类
a. 构造函数__init__
def __init__(self):self.inputs = Noneself.outputs = Noneself.params = None 初始化了类的成员变量self.inputs、self.outputs和self.params,它们分别用于保存输入、输出和参数。
b. __call__(self, x)方法
__call__(self, x)方法使得该类的实例可以像函数一样被调用。它调用了forward(x)方法,将输入的x传递给前向传播方法。
def __call__(self, x):return self.forward(x)c. 前向传播forward
def forward(self, inputs):outputs = 1.0 / (1.0 + torch.exp(-inputs))self.outputs = outputsreturn outputs forward(self, inputs)方法执行逻辑回归的前向传播。它接受输入inputs作为参数,并通过逻辑回归的公式计算输出值outputs。最后,将计算得到的输出保存在self.outputs中,并返回输出值。
d. 反向传播backward
def backward(self, outputs_grads=None):if outputs_grads is None:outputs_grads = torch.ones(self.outputs.shape)outputs_grad_inputs = torch.multiply(self.outputs, (1.0 - self.outputs))return torch.multiply(outputs_grads, outputs_grad_inputs) backward(self, outputs_grads=None)方法执行逻辑回归的反向传播。
- 接受一个可选的参数
outputs_grads,用于传递输出的梯度。 - 如果没有提供
outputs_grads,则默认为全1的张量,表示对输出的梯度都为1。 - 根据逻辑回归的导数公式,可以将输出值与(1-输出值)相乘,然后再乘以传入的梯度值,得到输入的梯度。
- 返回计算得到的输入梯度。
2. 模型训练
act = Logistic()
x = torch.tensor([3,3,4,2])
y = act(x)z = act.backward()
print(z)
- 创建一个
Logistic的实例act; - 传入张量
x进行前向传播,得到输出张量y; - 调用
act.backward()进行反向传播,得到输入x的梯度; - 将结果打印输出。
tensor([0.0452, 0.0452, 0.0177, 0.1050])3. 代码整合
# 导入必要的工具包
import torchclass Logistic():def __init__(self):self.inputs = Noneself.outputs = Noneself.params = Nonedef __call__(self, x):return self.forward(x)def forward(self, inputs):outputs = 1.0 / (1.0 + torch.exp(-inputs))self.outputs = outputsreturn outputsdef backward(self, outputs_grads=None):if outputs_grads is None:outputs_grads = torch.ones(self.outputs.shape)outputs_grad_inputs = torch.multiply(self.outputs, (1.0 - self.outputs))return torch.multiply(outputs_grads, outputs_grad_inputs)act = Logistic()
x = torch.tensor([3,3,4,2])
y = act(x)z = act.backward()
print(z)注意:
本实验仅实现了逻辑回归的前向传播和反向传播部分,缺少了模型的参数更新和训练部分。完整的逻辑回归,需要进一步编写训练循环、损失函数和优化器等部分,欲知后事如何,请听下回分解。



![[杂谈]-八进制数](https://img-blog.csdnimg.cn/8f8fb0457025428a992f6ff950ee05d2.png#pic_center)



![[面试] k8s面试题 2](https://img-blog.csdnimg.cn/38d5cac439894d3eb3a90e71d54fc706.jpeg#pic_center)




