一、Flink架构及核心概念
1.系统架构
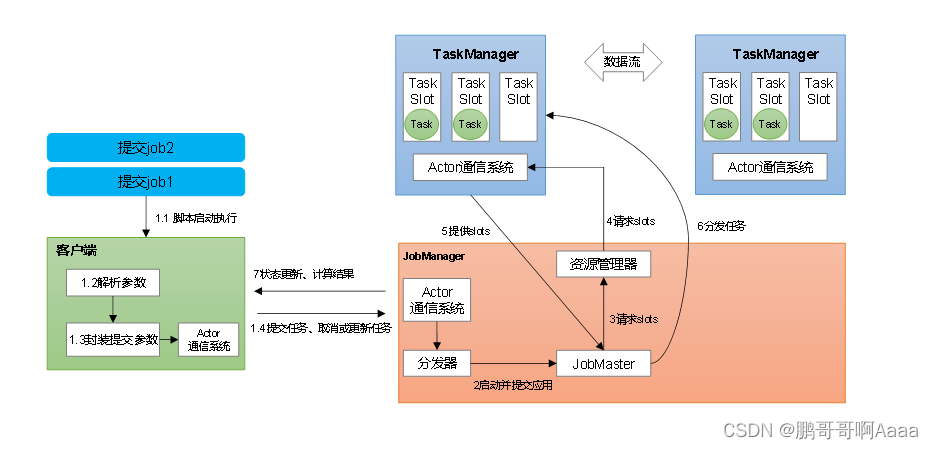
- JobMaster是JobManager中最核心的组件,负责处理单独的作业(Job)。
- 一个job对应一个jobManager
2.并行度
(1)并行度(Parallelism)概念
一个特定算子的子任务(subtask)的个数被称之为其并行度(parallelism)。这样,包含并行子任务的数据流,就是并行数据流,它需要多个分区(stream partition)来分配并行任务。
流程序的并行度 = 其所有算子中最大的并行度。一个程序中,不同的算子可能具有不同的并行度。
(2)设置并行度
对某个具体算子设置并行度:
stream.map(word -> Tuple2.of(word, 1L)).setParallelism(2);全局设置并行度:
env.setParallelism(2);提交任务时指定:
- 通过页面上传jar的时候可以指定
- 可以在命令行启动的时候通过 -p 3指定
flink-conf.yaml中配置:
parallelism.default: 2优先级:
代码中具体算子 > 代码中全局 > 提交任务指定 > 配置文件中指定
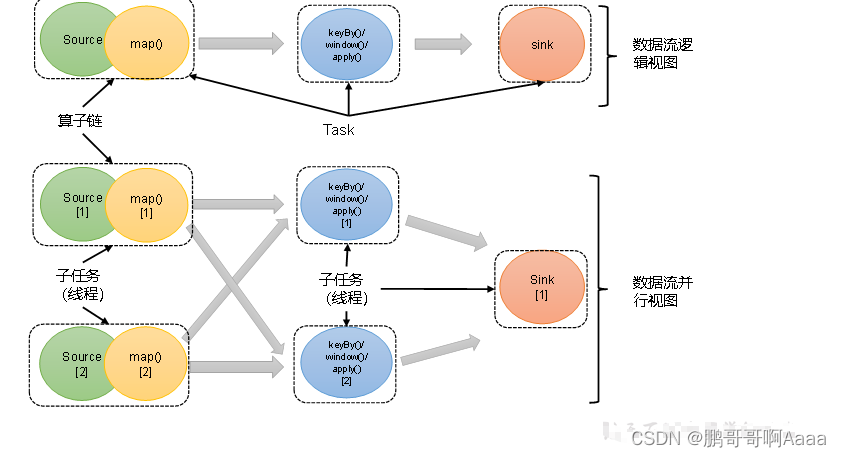
3.算子链

(1)算子间的数据传输
*1)一对一(One-to-one,forwarding)
这种模式下,数据流维护着分区以及元素的顺序。它们之间不需要重新分区,也不需要调整数据的顺序。map、filter、flatMap等算子都是这种one-to-one的对应关系。这种关系类似于Spark中的窄依赖。
*2)重分区(Redistributing)
在这种模式下,数据流的分区会发生改变。每一个算子的子任务,会根据数据传输的策略,把数据发送到不同的下游目标任务。这些传输方式都会引起重分区的过程,这一过程类似于Spark中的shuffle。
(2)合并算子链
在Flink中,并行度相同的一对一(one to one)算子操作,可以直接链接在一起形成一个“大”的任务(task),这样原来的算子就成为了真正任务里的一部分
// 禁用算子链,该算子不会和前面和后面串在一起
.map(word -> Tuple2.of(word, 1L)).disableChaining();// 全局禁用算子链
env.disableChaining();// 从当前算子开始新链
.map(word -> Tuple2.of(word, 1L)).startNewChain()- 当一对一的时候,每个运算量都很大,这个时候不适合串在一起。
- 当需要定位具体问题的时候,不串在一起更容易排查问题
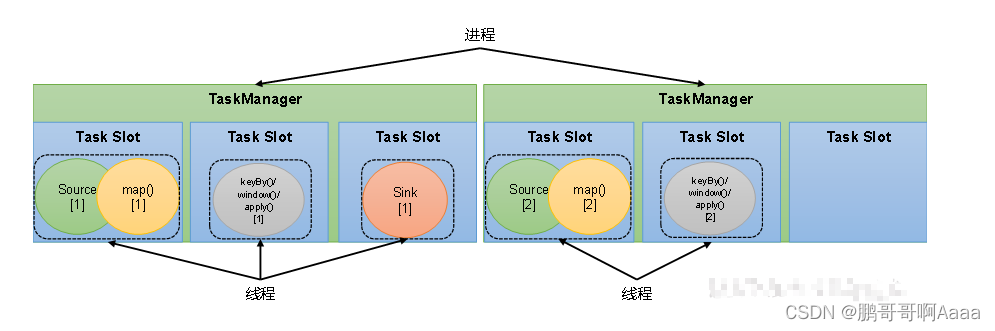
4.任务槽
(1)任务槽(Task Slots)概念
Flink中每一个TaskManager都是一个JVM进程,它可以启动多个独立的线程,来并行执行多个子任务(subtask)。
TaskManager的计算资源是有限的,为了控制并发量,TaskManager对每个任务运行所占用的内存资源做出明确的划分,这就是所谓的任务槽(task slots)。
每个任务槽的大小是均等的,且任务槽之间的资源不可以互相借用。
如图,每个TaskManager有三个任务槽,每个槽运行自己的任务。槽的大小均等。
(2)任务槽数量的设置
在Flink的/opt/module/flink-1.17.0/conf/flink-conf.yaml配置文件中,可以设置TaskManager的slot数量,默认是1个slot。
taskmanager.numberOfTaskSlots: 8slot目前仅仅用来隔离内存,不会涉及CPU的隔离。在具体应用时,建议将slot数量配置为机器的CPU核心数。
(3)任务对任务槽的共享
在同一个作业中,不同任务节点的并行子任务可以放在同一个slot上执行

可以共享:
- 同一个job中,不同算子的子任务才可以共享同一个slot。这些子任务是同时运行
- 前提是:属于同一个slot共享组,默认都是“default”
手动指定共享组:
.map(word -> Tuple2.of(word, 1L)).slotSharingGroup("1");共享的好处:允许我们保存完整的作业管道。这样一来,即使某个TaskManager出现故障宕机,其他节点也可以完全不受影响,作业的任务可以继续执行
(4)任务槽和并行度的关系
- 任务槽是静态的概念,是指TaskManager具有的并发执行能力,可以通过参数taskmanager.numberOfTaskSlots进行配置
- 并行度是动态概念,也就是TaskManager运行程序时实际使用的并发能力,可以通过参数parallelism.default进行配置
如果是yarn模式,申请的TaskManager的数量 = job并行度 / 每个TM的slot数量,向上取整
即:假设10个并行度的job,每个TM的slot是3个,那么需要10/3,向上取整,即需要最少4个TaskManager
二、作业提交流程
1.Standalone会话模式作业提交流程
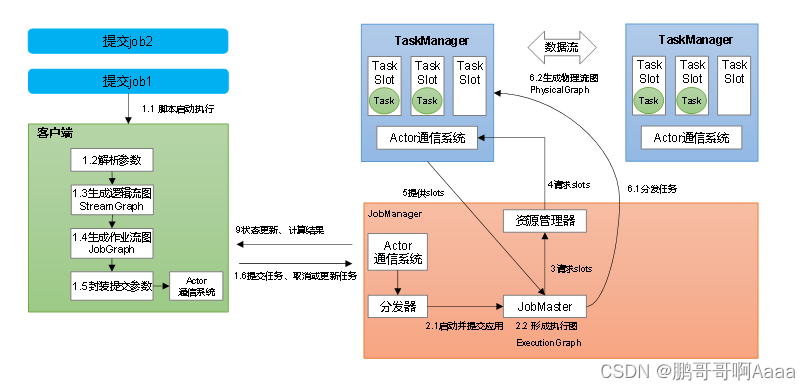
逻辑流图(StreamGraph)→ 作业图(JobGraph)→ 执行图(ExecutionGraph)→ 物理图(Physical Graph)。


- 逻辑流图:列出并行度,算子,各算子之间关系(一对一还是需要重分区)
- 作业图:将一对一的算子做算子链的优化,作业中间会有中间结果集
- 执行图:将并行度展开,并标注每个并行处理的算子
- 物理图:基本同执行图,是执行图的落地
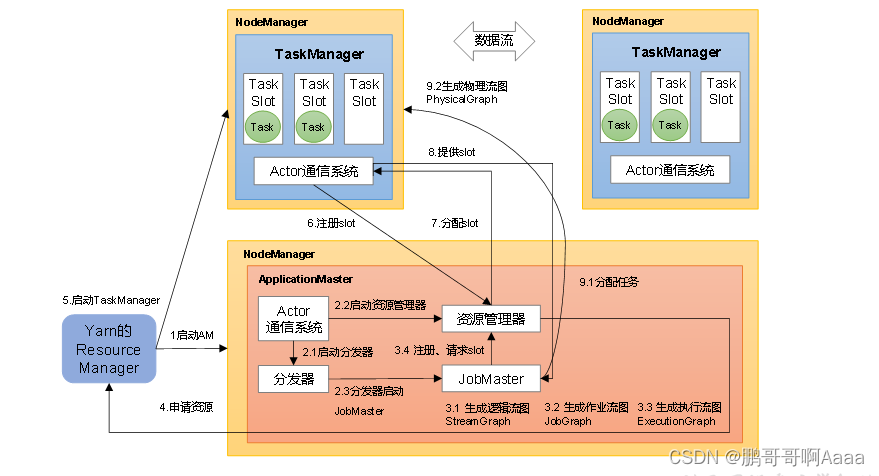
2.Yarn应用模式作业提交流程
三、 DataStream API
DataStream API是Flink的核心层API。一个Flink程序,其实就是对DataStream的各种转换。
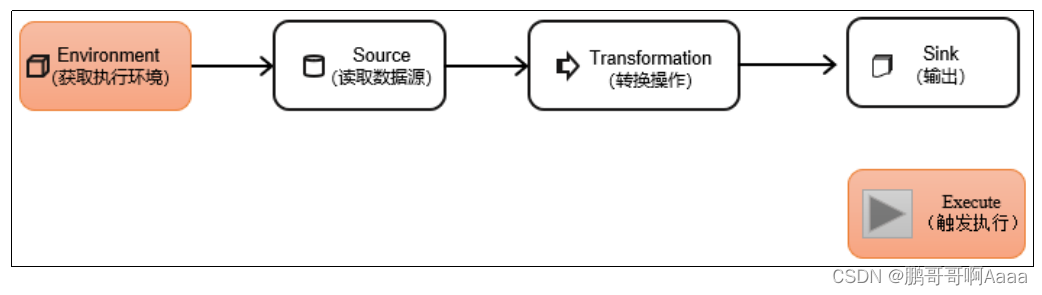
1.执行环境(Execution Environment)
(1)创建执行环境
*1)StreamExecutionEnvironment.getExecutionEnvironment();
它会根据当前运行的上下文直接得到正确的结果:如果程序是独立运行的,就返回一个本地执行环境;如果是创建了jar包,然后从命令行调用它并提交到集群执行,那么就返回集群的执行环境
*2)StreamExecutionEnvironment.createLocalEnvironment();
这个方法返回一个本地执行环境。可以在调用时传入一个参数,指定默认的并行度;如果不传入,则默认并行度就是本地的CPU核心数
*3)StreamExecutionEnvironment
.createRemoteEnvironment(
"host", // JobManager主机名
1234, // JobManager进程端口号
"path/to/jarFile.jar" // 提交给JobManager的JAR包
);
这个方法返回集群执行环境。需要在调用时指定JobManager的主机名和端口号,并指定要在集群中运行的Jar包。
(2)执行模式(Execution Mode)
流批一体:代码api是同一套,可以指定为 批,也可以指定为 流。
通话代码配置:
env.setRuntimeMode(RuntimeExecutionMode.BATCH);通过命令行配置:
bin/flink run -Dexecution.runtime-mode=BATCH(3)触发程序执行
当main()方法被调用时,并没有真正处理数据。只有等到数据到来,才会触发真正的计算,这也被称为“延迟执行”或“懒执行”。
所以我们需要显式地调用执行环境的execute()方法,来触发程序执行。execute()方法将一直等待作业完成,然后返回一个执行结果(JobExecutionResult)。
如果在一段代码里面执行多个任务,可以使用env.executeAsync();
package com.atguigu.env;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.configuration.RestOptions;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;/*** TODO** @author cjp* @version 1.0*/
public class EnvDemo {public static void main(String[] args) throws Exception {Configuration conf = new Configuration();conf.set(RestOptions.BIND_PORT, "8082");StreamExecutionEnvironment env = StreamExecutionEnvironment
// .getExecutionEnvironment(); // 自动识别是 远程集群 ,还是idea本地环境.getExecutionEnvironment(conf); // conf对象可以去修改一些参数// .createLocalEnvironment()
// .createRemoteEnvironment("hadoop102", 8081,"/xxx")// 流批一体:代码api是同一套,可以指定为 批,也可以指定为 流// 默认 STREAMING// 一般不在代码写死,提交时 参数指定:-Dexecution.runtime-mode=BATCHenv.setRuntimeMode(RuntimeExecutionMode.BATCH);env
// .socketTextStream("hadoop102", 7777).readTextFile("input/word.txt").flatMap((String value, Collector<Tuple2<String, Integer>> out) -> {String[] words = value.split(" ");for (String word : words) {out.collect(Tuple2.of(word, 1));}}).returns(Types.TUPLE(Types.STRING, Types.INT)).keyBy(value -> value.f0).sum(1).print();env.execute();/** TODO 关于execute总结(了解)* 1、默认 env.execute()触发一个flink job:* 一个main方法可以调用多个execute,但是没意义,指定到第一个就会阻塞住* 2、env.executeAsync(),异步触发,不阻塞* => 一个main方法里 executeAsync()个数 = 生成的flink job数* 3、思考:* yarn-application 集群,提交一次,集群里会有几个flink job?* =》 取决于 调用了n个 executeAsync()* =》 对应 application集群里,会有n个job* =》 对应 Jobmanager当中,会有 n个 JobMaster*/
// env.executeAsync();// ……
// env.executeAsync();}
}
2.源算子(Source)
从Flink1.12开始,主要使用流批统一的新Source架构:
DataStreamSource<String> stream = env.fromSource(…)(1)创建pojo对象
需要空参构造器,所有属性的类型都是可以序列化的
package com.atguigu.bean;import java.util.Objects;/*** TODO** @author cjp* @version 1.0*/
public class WaterSensor {public String id;//水位传感器类型public Long ts;//传感器记录时间戳public Integer vc;//水位记录// 一定要提供一个 空参 的构造器public WaterSensor() {}public WaterSensor(String id, Long ts, Integer vc) {this.id = id;this.ts = ts;this.vc = vc;}public String getId() {return id;}public void setId(String id) {this.id = id;}public Long getTs() {return ts;}public void setTs(Long ts) {this.ts = ts;}public Integer getVc() {return vc;}public void setVc(Integer vc) {this.vc = vc;}@Overridepublic String toString() {return "WaterSensor{" +"id='" + id + '\'' +", ts=" + ts +", vc=" + vc +'}';}@Overridepublic boolean equals(Object o) {if (this == o) {return true;}if (o == null || getClass() != o.getClass()) {return false;}WaterSensor that = (WaterSensor) o;return Objects.equals(id, that.id) &&Objects.equals(ts, that.ts) &&Objects.equals(vc, that.vc);}@Overridepublic int hashCode() {return Objects.hash(id, ts, vc);}
}
(2)从集合中读取数据
package com.atguigu.source;import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;/*** TODO** @author cjp* @version 1.0*/
public class CollectionDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// TODO 从集合读取数据DataStreamSource<Integer> source = env.fromElements(1,2,33); // 从元素读
// .fromCollection(Arrays.asList(1, 22, 3)); // 从集合读source.print();env.execute();}
}
(3)从文件读取数据
先添加配置:
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-files</artifactId><version>1.17.0</version></dependency>package com.atguigu.source;import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.connector.file.src.FileSource;
import org.apache.flink.connector.file.src.reader.TextLineInputFormat;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;/*** TODO** @author cjp* @version 1.0*/
public class FileSourceDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// TODO 从文件读: 新Source架构FileSource<String> fileSource = FileSource.forRecordStreamFormat(new TextLineInputFormat(),new Path("input/word.txt")).build();env.fromSource(fileSource, WatermarkStrategy.noWatermarks(), "filesource").print();env.execute();}
}
/**** 新的Source写法:* env.fromSource(Source的实现类,Watermark,名字)**/(4)从Socket读取数据
DataStream<String> stream = env.socketTextStream("localhost", 7777);(5)从Kafka读取数据
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>1.17.0</version>
</dependency>package com.atguigu.source;import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.time.Duration;/*** TODO** @author cjp* @version 1.0*/
public cl