企业级数据仓库-理论知识






本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/139147.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
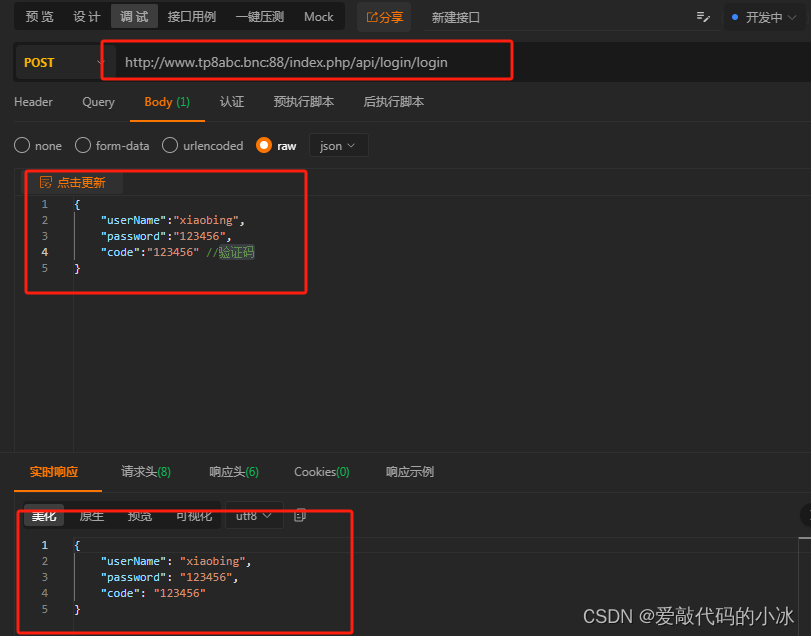
thinkphp8路由
thinkphp8已出来有好一段时间了。这些天闲来无事,研究了下tp8的路由。默认情况下,tp8的路由是在route\app.php的文件里。但在实际工作中,我们并不会这样子去写路由。因为这样不好管理。更多的,是通过应用级别去管理路由。假如项目…

设计模式之解释器模式
一、定义
1、定义 Given a language,define a representation for its grammar along with an interpreter that uses the representation to interpret sentences in the language.(给定一门语言,定义它的语法的一种表示,并定义一个解释器&…
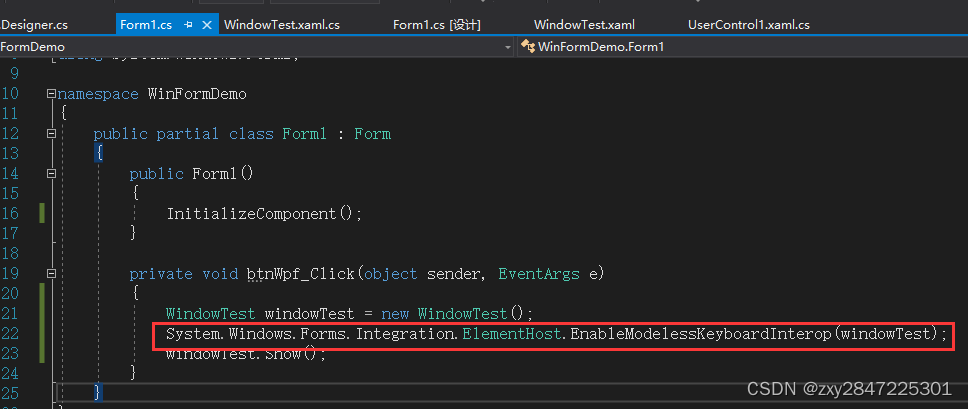
Winform直接与Wpf交互
Winform项目中,可以直接使用wpf中的自定义控件和窗体 测试环境:
vistual studio 2017
window 10 一 winform直接使用wpf的自定义控件
步骤如下:
1 新建winfrom项目,名为WinFormDemo,默认有一个名为Form1的窗体…

【GAMES103】基于物理的计算机动画入门(1)前置的基础数学知识
GAMES103: 基于物理的计算机动画入门 链接:GAMES103
1. 坐标系的划分
在游戏引擎中分为右手和左手坐标系,区分的依据是什么? 上图可以看到如果是左手坐标系,那么所有的物体都在屏幕后面,意味着x,y&#x…

物联网的未来:连接的智能世界
物联网(IoT)是引领我们走向未来的一项关键技术。它让物品通过互联网进行连接,交流,开创了智能生活新时代。预计到2025年,全球将拥有超过410亿的IoT设备。在对人类生活的每个方面产生影响的同时,物联网也正在…

2023华为杯研究生数学建模竞赛CDEF题思路+模型代码
全程更新华为杯研赛CDEF题思路模型及代码,大家查看文末名片获取
华为杯C题思路分析
问题一 在每个评审阶段,作品通常都是随机分发的,每份作品需要多位评委独立评审。为了增加不同评审专家所给成绩之间的可比性,不同专家评审的作…

【kafka实战】03 SpringBoot使用kafka生产者和消费者示例
本节主要介绍用SpringBoot进行开发时,使用kafka进行生产和消费
一、引入依赖
<dependencies><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency><depen…

zabbix自定义监控、钉钉、邮箱报警
目录
一、实验准备
二、安装
三、添加监控对象
四、添加自定义监控项
五、监控mariadb
1、添加模版查看要求
2、安装mariadb、创建用户
3、创建用户文件
4、修改监控模版
5、在上述文件中配置路径
6、重启zabbix-agent验证
六、监控NGINX
1、安装NGINX,…
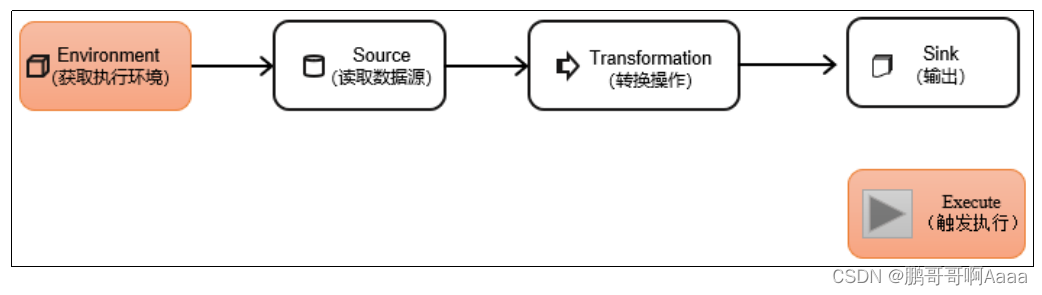
207.Flink(二):架构及核心概念,flink从各种数据源读取数据,各种算子转化数据,将数据推送到各数据源
一、Flink架构及核心概念
1.系统架构 JobMaster是JobManager中最核心的组件,负责处理单独的作业(Job)。一个job对应一个jobManager 2.并行度
(1)并行度(Parallelism)概念
一个特定算子的子任务(subtask)的个数被称之为其并行度(parallelism)。这样,包含并行子任…
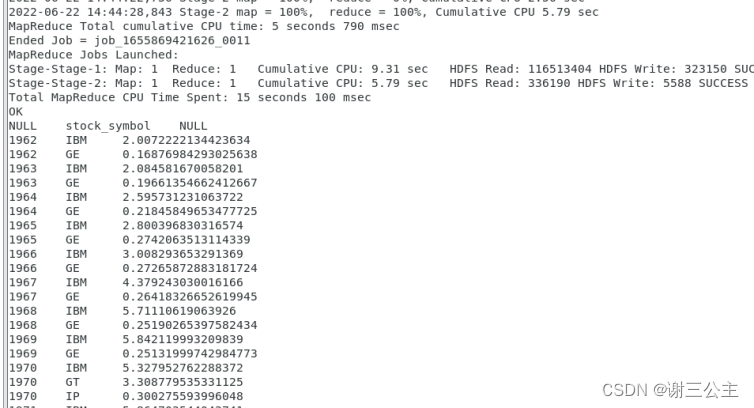
实验五 熟悉 Hive 的基本操作
实验环境: 1.操作系统:CentOS 7。 2.Hadoop 版本:3.3.0。 3.Hive 版本:3.1.2。 4.JDK 版本:1.8。 实验内容与完成情况:
(1)创建一个内部表 stocks,字段分隔符为英文逗号…

爬虫 — Scrapy 框架(一)
目录 一、介绍1、同步与异步2、阻塞与非阻塞 二、工作流程三、项目结构1、安装2、项目文件夹2.1、方式一2.2、方式二 3、创建项目4、项目文件组成4.1、piders/__ init __.py4.2、spiders/demo.py4.3、__ init __.py4.4、items.py4.5、middlewares.py4.6、pipelines.py4.7、sett…

BOM与DOM--记录
BOM基础(BOM简介、常见事件、定时器、this指向)
BOM和DOM的区别和联系
JavaScript的DOM与BOM的区别与用法详解
DOM和BOM是什么?有什么作用? 图解BOM与DOM的区别与联系
BOM和DOM详解 JavaScript 中的 BOM(浏览器对…

睿趣科技:抖音开通蓝V怎么操作的
在抖音这个充满创意和活力的社交媒体平台上,蓝V认证成为了许多用户的梦想之一。蓝V认证不仅是身份的象征,还可以增加用户的影响力和可信度。但是,要在抖音上获得蓝V认证并不是一件容易的事情。下面,我们将介绍一些操作步骤&#x…
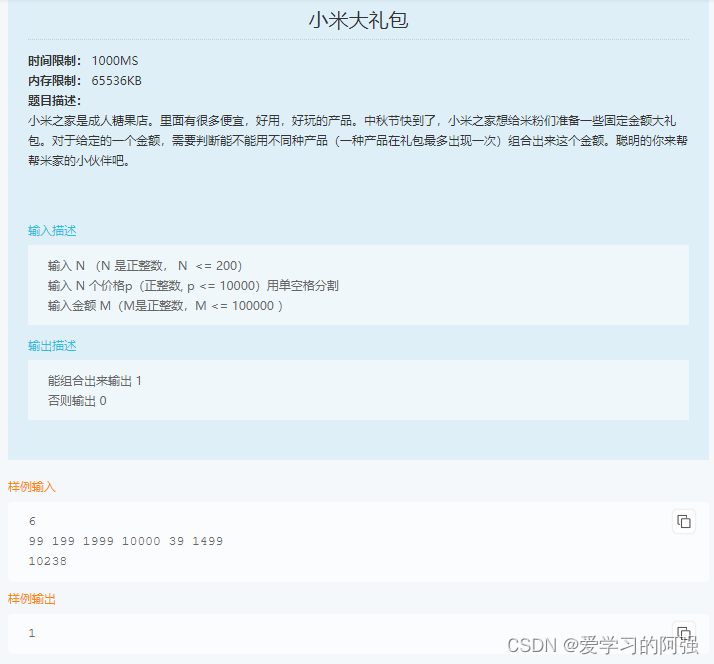
小米笔试题——01背包问题变种
这段代码的主要思路是使用动态规划来构建一个二维数组 dp,其中 dp[i][j] 表示前 i 个产品是否可以组合出金额 j。通过遍历产品列表和可能的目标金额,不断更新 dp 数组中的值,最终返回 dp[N][M] 来判断是否可以组合出目标金额 M。如果 dp[N][M…
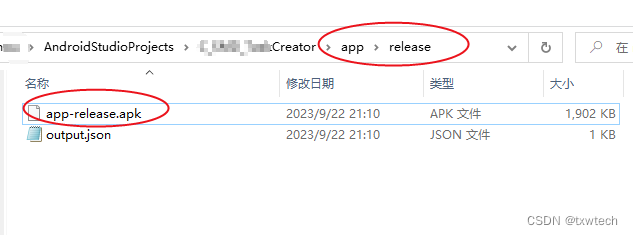
Android studio安卓生成APK文件安装包方法
1.点击Build->Generate Signed Bundle/APK 2.选择APK 3.首次生成,没有jks文件,就点击Create new。再次生成,直接点Next 4.选择创建jks文件路径 5.点击Next 6.选择release 7.生成完成的apk安装包路径
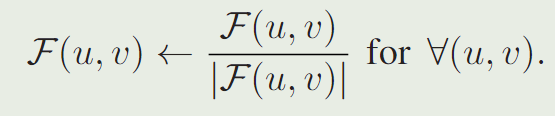
【论文阅读 08】Adaptive Anomaly Detection within Near-regular Milling Textures
2013年,太老了,先不看 比较老的一篇论文,近规则铣削纹理中的自适应异常检测
1 Abstract 在钢质量控制中的应用,我们提出了图像处理算法,用于无监督地检测隐藏在全局铣削模式内的异常。因此,我们考虑了基于…
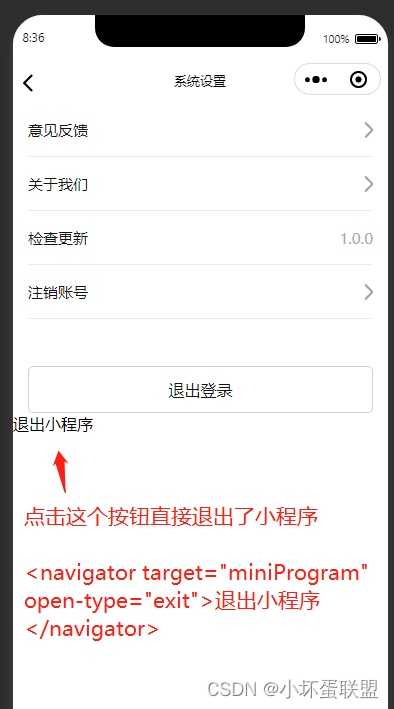
uniapp小程序点击按钮直接退出小程序效果demo(整理)
点击按钮直接退出小程序
<navigator target"miniProgram" open-type"exit">退出小程序</navigator>
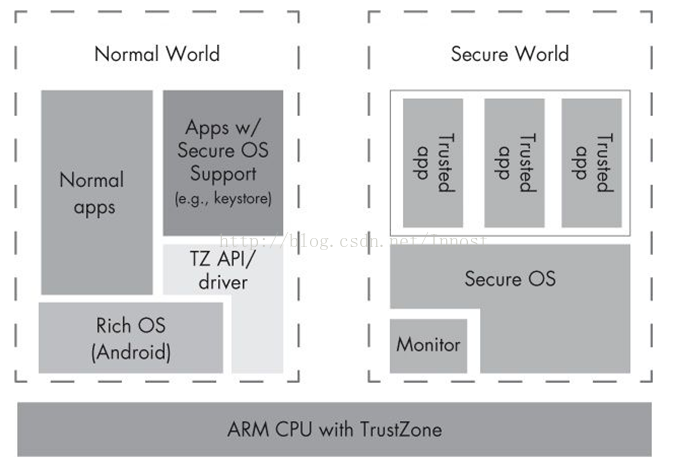
Android Key/Trust Store研究+ssl证书密钥
前言:软件搞环境涉及到了中间件thal trustzone certificate key,翻译过来是thal信任区域证书密钥 ,不明白这是什么,学习一下 ssl证书密钥
SSL密钥是SSL加密通信中的重要组成部分。SSL证书通过加密算法生成,用于保护网…

Oracle 11g RAC部署笔记
搭了三次才搭好,要记录一下。
1. Oracle 11g RAC部署的相关步骤以及需要的包,可以参考这里。
Oracle 11g RAC部署_12006142的技术博客_51CTO博客Oracle 11g RAC部署,Oracle11gRAC部署操作环境:CentOS7.4Oracle11.2.0.4一、主机网…
解决老版本Oracle VirtualBox 此应用无法在此设备上运行问题
问题现象
安装华为eNSP模拟器的时候,对应的Oracle VirtualBox-5.2.26安装的时候提示兼容性问题,无法进行安装,具体版本信息如下:
软件对应版本备注Windows 11专业工作站版22H222621eNSP1.3.00.100 V100R003C00 SPC100终结正式版…
推荐文章
- 婚礼准备程序
- 日语语法笔记【翻译】
- 生产者消费者问题(条件变量 互斥锁)
- Python---练习:打印直角三角形(利用wihle循环嵌套)
- LeetCode解法汇总1379. 找出克隆二叉树中的相同节点
- LeetCode解法汇总1465. 切割后面积最大的蛋糕
- LeetCode解法汇总2476. 二叉搜索树最近节点查询
- time --- 时间的访问和转换
- # mongodb_基础到进阶 -- MongoDB 高级--MongoDB 集群部署与安全性(四)
- (22)Task.Delay与Thread.Sleep,Wait与When,复习
- (8)香橙派+apache2与php+天猫精灵=自建平台语音支持--天猫精灵对接3
- (python)空值处理