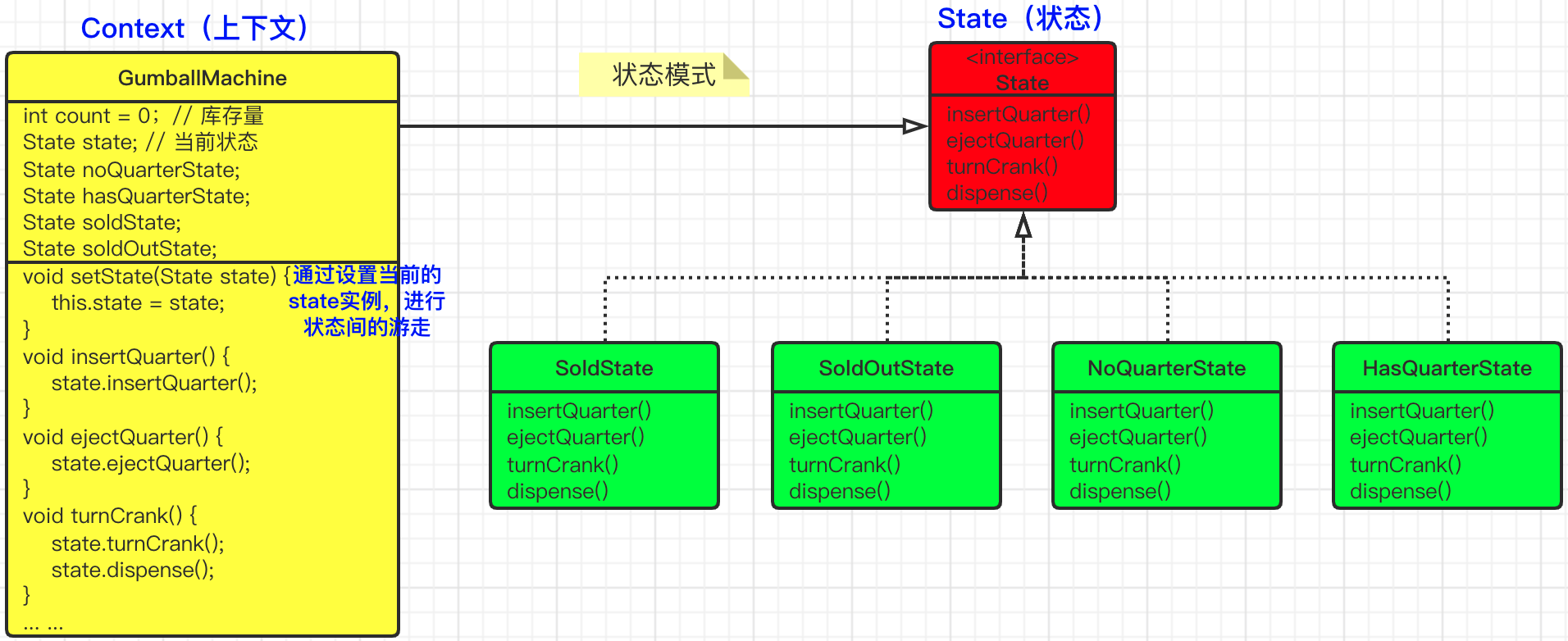
1、问题还原:
在做openai机器人时,后台使用 SseEmitter+EventSource 实现流式获取数据,前端通过 EventSourcePolyfill 函数接收后端的数据,在页面流式输出到页面,做成逐字打稿的效果。本地测试后,可以正常获取到数据,页面也可以流式打印输出。工程发布到线上后,前端使用的nginx作反向代理。在postman中直接访问代理的路径,几乎是没有反应,几秒后就会告诉你连接超时。
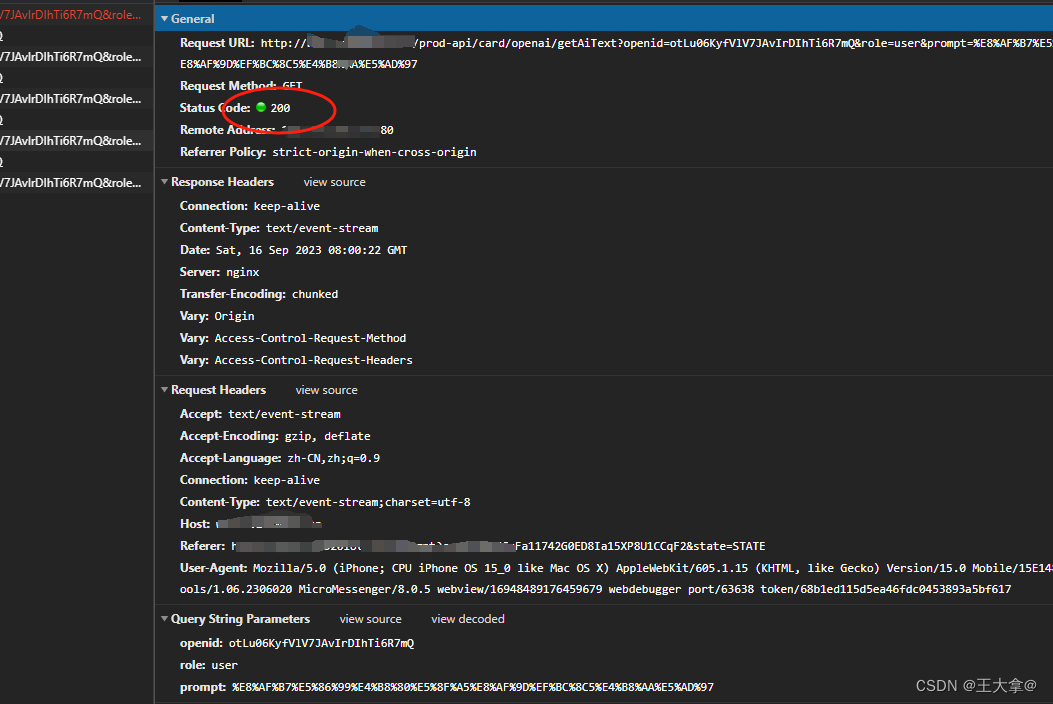
这里虽然显示 成功 200,但是却没有认识数据的返回。
2、问题分析:
本地工程不存在这个问题,只有在线上环境才出现。说明线上的环境出现了问题,因为在本地是通过本地的ip+port访问,可以直接获取到openai 的返回数据(大家直接请求官方的可能会很慢/大概率是被墙,在这里我做了代理)速度就很快了。我会把做好的openai放到最后。言归正传,线上唯一不同的是使用的nginx反向代理,毫不质疑问题就在nginx上面,SseEmitter是一个长连接,nginx想必是做了缓冲,导致数据迟缓最后超时。
3、问题解决:
nginx中有一个参数是:proxy_buffering, 默认是开启的状态。这个参数用来控制是否打开后端响应内容的缓冲区,如果这个设置为off,那么proxy_buffers和proxy_busy_buffers_size这两个指令将会失效。 但是无论proxy_buffering是否开启,对proxy_buffer_size都是生效的。
proxy_buffering开启的情况下,nignx会把后端返回的内容先放到缓冲区当中,然后再返回给客户端(边收边传,不是全部接收完再传给客户端)。 临时文件由proxy_max_temp_file_size和proxy_temp_file_write_size这两个指令决定的。如果响应内容无法放在内存里边,那么部分内容会被写到磁盘上。
如果proxy_buffering关闭,那么nginx会立即把从后端收到的响应内容传送给客户端,每次取的大小为proxy_buffer_size的大小,这样效率肯定会比较低。
nginx不尝试计算被代理服务器整个响应内容的大小,nginx能从服务器接受的最大数据,是由指令proxy_buffer_size指定的.
特别注意:
1、 proxy_buffering启用时,要提防使用的代理缓冲区太大。这可能会吃掉你的内存,限制代理能够支持的最大并发连接数。
2、对于基于长轮询(long-polling)的Comet 应用来说,关闭 proxy_buffering 是重要的,不然异步响应将被缓存导致Comet无法工作
重点看红色部分,正是因为这个参数默认是开启状态,我们配置nginx的时候也可能想不到要去修改,所以就导致线上获取数据超时直至失败。下面是修改后的参数:
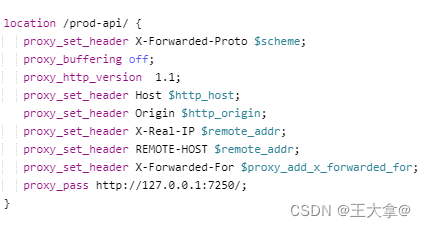
搞定,收工!
这个是已经做好的 机器人助理,支持语言问答,论文写作,日常问答同时还可以绘图,画画。
问答机器人直通车:
http://wdn.zs2020iot.cn/chatgpt?appid=wx3414ace02bb7d650 d![]() http://wdn.zs2020iot.cn/chatgpt?appid=wx3414ace02bb7d650
http://wdn.zs2020iot.cn/chatgpt?appid=wx3414ace02bb7d650
大家爱好技术,喜欢交流技术的,诚意邀请,进入我们的大家庭!