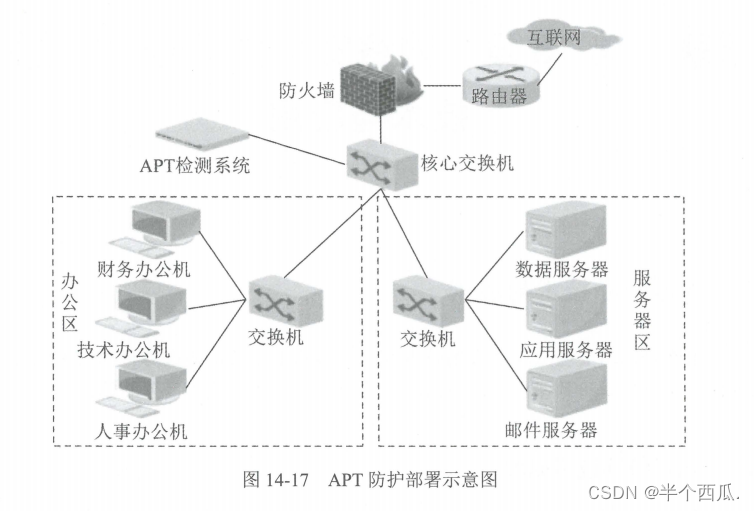
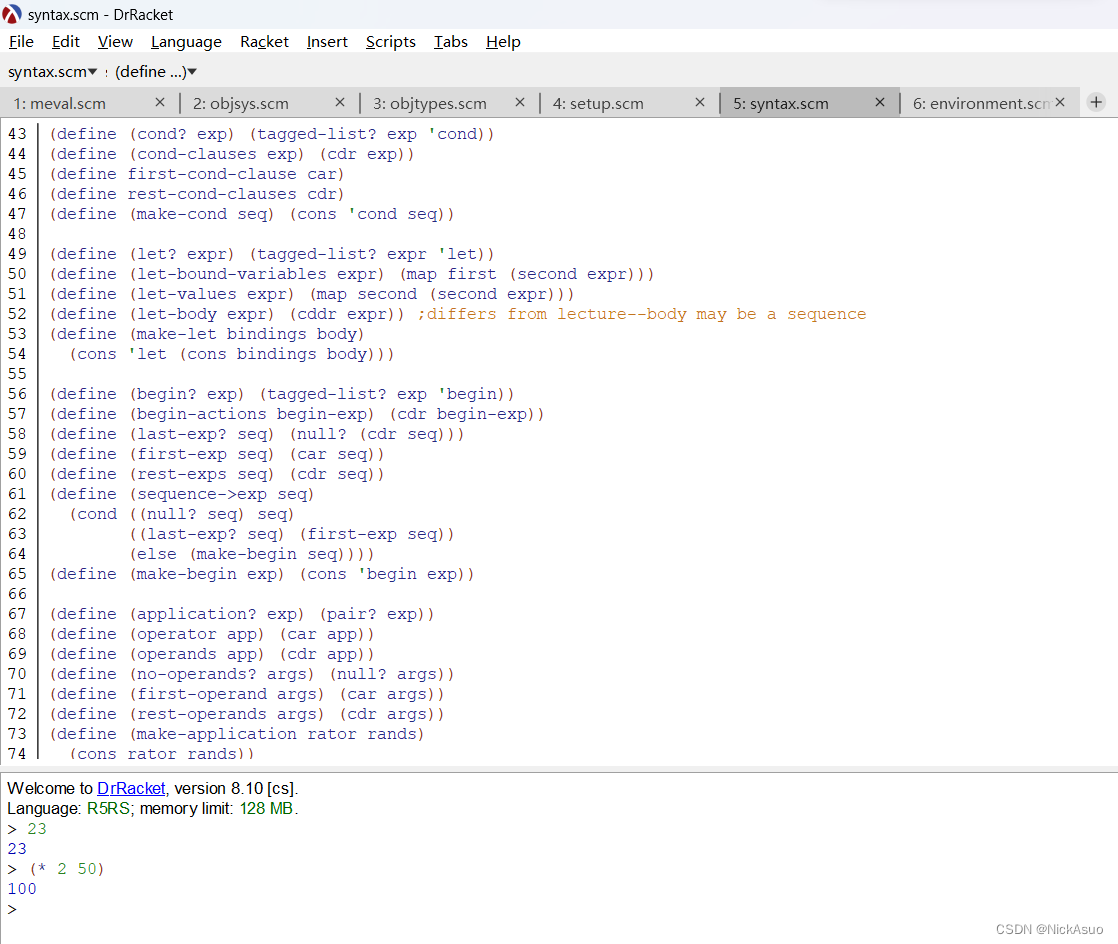
一、背景:
CDC数据中包含了,数据的变更过程。当CDC写入传统数据库最终每一个primary key下会保存一条数据。当然可以使用特殊手段保存多分记录但是显然造成了数据膨胀。
另外数据湖Hudi(0.13.1)是不支持保存所有Changelog其Compaction机制会清除所有旧版本的内容。Iceberg支持TimeTravel,能查到某个时间点的数据状态,但是不能列举的单条记录的Change过程。
所以目前只能手动实现。
其实,实现思路很简单,将原PrimaryKey+Cdc的 ts_ms 一起作为新表的 PrimaryKey就可以了。但需要注意的是一条数据可能变更很多次,但一般需要保存近几次的变更,所以就需要删除部分旧变更记录。ts_ms 就是CDC数据中记录的日志实际产生的时间,具体参见debezium 。如果原表primarykey是联合主键,即有多个字段共同组成,则最好将这些字段拼接为一个字符串,方便后续关联。
本文思路
CDC --写入-> Phoenix + 定期删除旧版本记录
CDC数据写入略过,此处使用SQL模拟写入。
二、Phoenix旧版记录删除(DEMO)
phoenix doc
bin/sqlline.py www.xx.com:2181
-- 直接创建phoenix表
create table TEST.TEST_VERSION(
ID VARCHAR NOT NULL,
TS TIMESTAMP NOT NULL,
NAME VARCHAR,
CONSTRAINT my_pk PRIMARY KEY (ID,TS)
) VERSIONS=5;
再去hbase shell中查看,hbase 关联表已经有phoenix创建了。
hbase(main):032:0> desc "TEST:TEST_VERSION"
Table TEST:TEST_VERSION is ENABLED
TEST:TEST_VERSION, {TABLE_ATTRIBUTES => {coprocessor$1 => '|org.apache.phoenix.coprocessor.ScanRegionObserver|805306366|', coprocessor$2 => '|org.apache.phoenix.coprocessor.UngroupedAggregateRe
gionObserver|805306366|', coprocessor$3 => '|org.apache.phoenix.coprocessor.GroupedAggregateRegionObserver|805306366|', coprocessor$4 => '|org.apache.phoenix.coprocessor.ServerCachingEndpointImpl|80
5306366|', coprocessor$5 => '|org.apache.phoenix.hbase.index.Indexer|805306366|index.builder=org.apache.phoenix.index.PhoenixIndexBuilder,org.apache.hadoop.hbase.index.codec.class=org.apache.phoenix
.index.PhoenixIndexCodec', METADATA => {'OWNER' => 'dcetl'}}
COLUMN FAMILIES DESCRIPTION
{NAME => '0', VERSIONS => '5', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'FAST_DIFF', T
TL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'NONE', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPE
N => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'}
-- 在phoenix中向表插入数据
UPSERT INTO TEST.TEST_VERSION(ID,TS,NAME) VALUES('rk001',TO_TIMESTAMP('2020-01-01 10:00:00'),'zhangsan');
UPSERT INTO TEST.TEST_VERSION(ID,TS,NAME) VALUES('rk001',TO_TIMESTAMP('2020-01-01 11:00:00'),'lisi');
UPSERT INTO TEST.TEST_VERSION(ID,TS,NAME) VALUES('rk001',TO_TIMESTAMP('2020-01-01 12:00:00'),'wangwu');
UPSERT INTO TEST.TEST_VERSION(ID,TS,NAME) VALUES('rk001',TO_TIMESTAMP('2020-01-01 13:00:00'),'zhaoliu');
UPSERT INTO TEST.TEST_VERSION(ID,TS,NAME) VALUES('rk001',TO_TIMESTAMP('2020-01-01 14:00:00'),'liuqi');
UPSERT INTO TEST.TEST_VERSION(ID,TS,NAME) VALUES('rk001',TO_TIMESTAMP('2020-01-01 15:00:00'),'sunba');
UPSERT INTO TEST.TEST_VERSION(ID,TS,NAME) VALUES('rk002',TO_TIMESTAMP('2020-01-01 07:00:00'),'sunyang');
UPSERT INTO TEST.TEST_VERSION(ID,TS,NAME) VALUES('rk002',TO_TIMESTAMP('2020-01-01 08:00:00'),'chaoyang');
UPSERT INTO TEST.TEST_VERSION(ID,TS,NAME) VALUES('rk002',TO_TIMESTAMP('2020-01-01 09:00:00'),'xuri');
UPSERT INTO TEST.TEST_VERSION(ID,TS,NAME) VALUES('rk002',TO_TIMESTAMP('2020-01-01 09:30:00'),'chenxi');
-- OK再查询一下数据插入情况
SELECT * FROM TEST.TEST_VERSION;
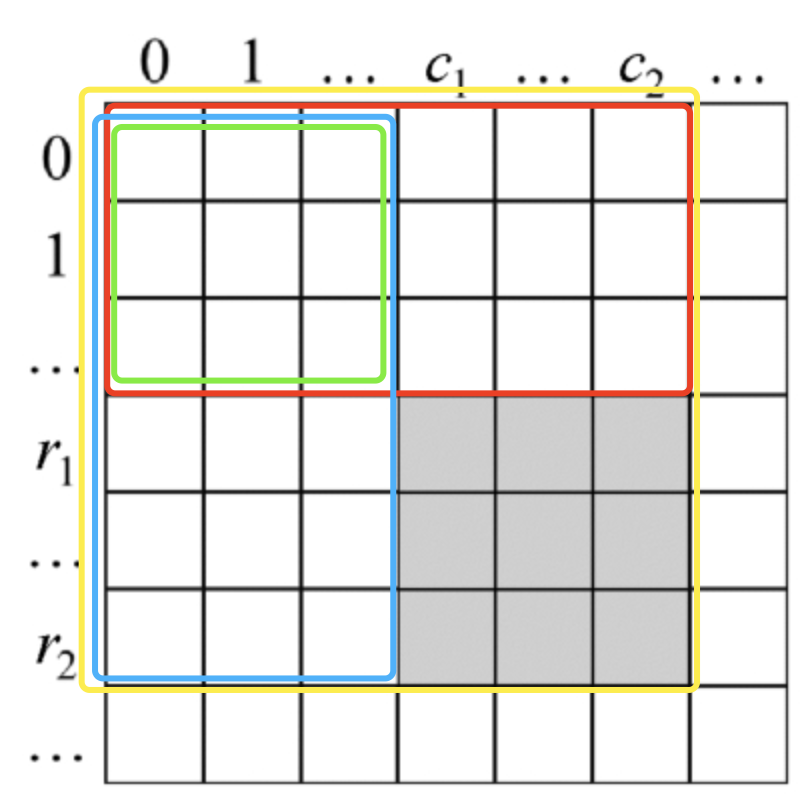
以下假设每个PrimaryKey需要保留最新的3版本数据。所以红色框内是需要删除的数据。
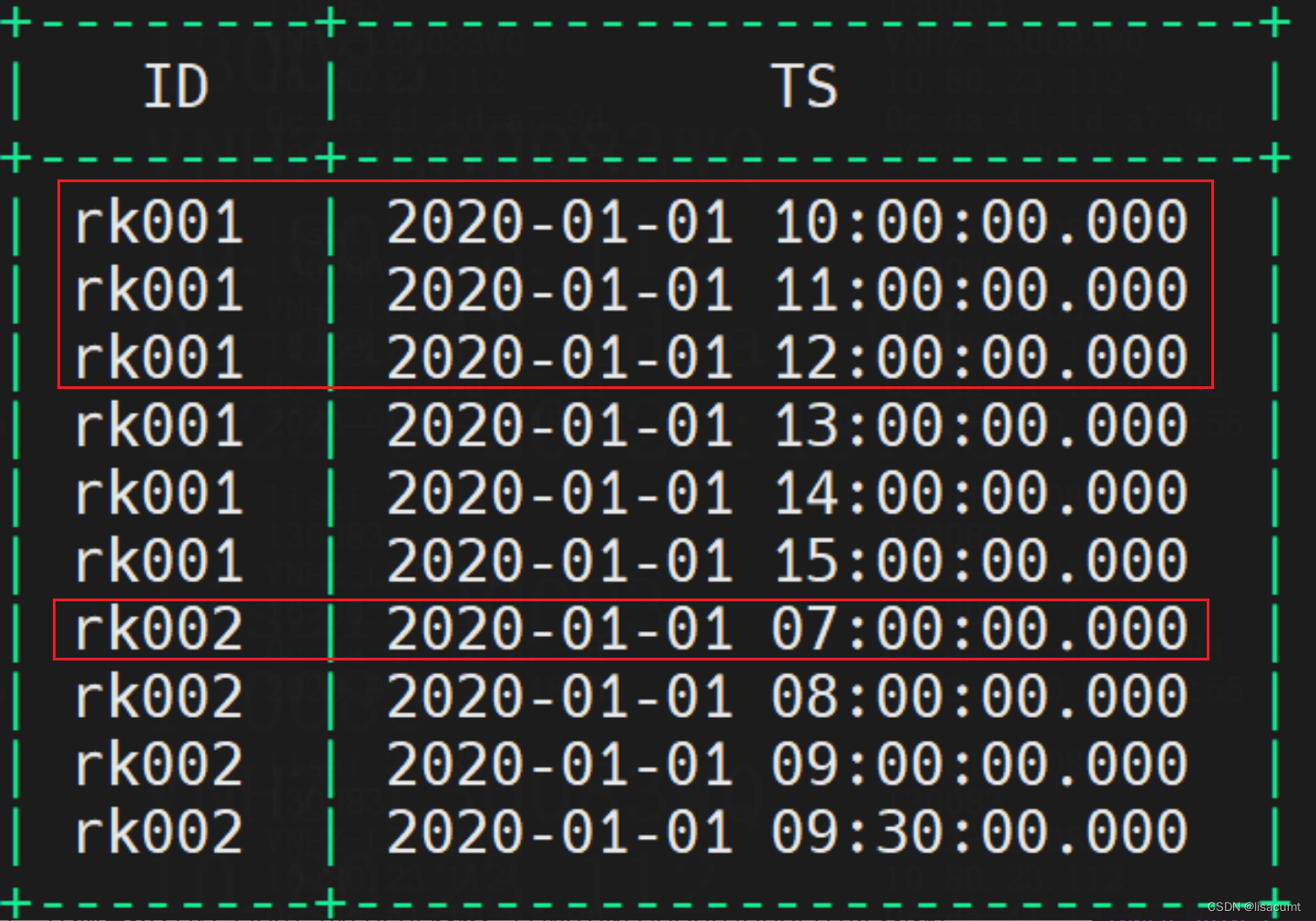
现在需要使用row_number的函数给每个primarykey的不通version数据标识。但是phoenix并没有开窗函数。只有agg聚合函数。
phoenix对SQL的限制还是比较多的如:
(1)join 非等值连接不支持,如on a.id>s.id 是不支持的,也不支持数组比较连接,如on a.id = ARRAY[1,2,3]。 会报错:Error: Does not support non-standard or non-equi correlated-subquery conditions. (state=,code=0)
(2)where exists 格式的非等值连接不支持。select ... from A where exists (select 1 from B where A.id>B.id) 是不支持的。会报错:Error: Does not support non-standard or non-equi correlated-subquery conditions. (state=,code=0)
(2)没有开窗window函数
(3)DELETE FROM不支持JOIN
最终发下有一下函数可用
(1)NTH_VALUE 获取分组排序的第N个值。 返回原值的类型。
(2)FIRST_VALUES 和 LAST_VALUES 获取分区排序后的前、后的N个值,返回ARRAY类型。
此三个函数官网doc中,案例是这样的 FIRST_VALUES( name, 3 ) WITHIN GROUP (ORDER BY salary DESC) 是全局分组,而实际使用中是需要搭配 GROUP BY 使用的。
所以可以获取到
-- 方案一:使用NTH_VALUE获取阈值
SELECT A.ID,A.TS FROM TEST.TEST_VERSION A
INNER JOIN (
SELECT ID,NTH_VALUE(TS,3) WITHIN GROUP (ORDER BY TS DESC) THRES FROM TEST.TEST_VERSION GROUP BY ID) Z ON A.ID=Z.ID
WHERE A.TS < Z.THRES-- 方案二:使用FIRST_VALUES获取到一个ARRAY
SELECT A.ID,A.TS FROM TEST.TEST_VERSION A
INNER JOIN (
SELECT ID,FIRST_VALUES(TS,3) WITHIN GROUP (ORDER BY TS DESC) TSS FROM TEST.TEST_VERSION GROUP BY ID) Z ON A.ID=Z.ID
WHERE A.TS < ALL(Z.TSS);
由于phoenix支持行子查询,以下是官方案例。这样就能绕过不使用DELETE … JOIN了。
Row subqueries
A subquery can return multiple fields in one row, which is considered returning a row constructor. The row constructor on both sides of the operator (IN/NOT IN, EXISTS/NOT EXISTS or comparison operator) must contain the same number of values, like in the below example:
SELECT column1, column2
FROM t1
WHERE (column1, column2) IN(SELECT column3, column4FROM t2WHERE column5 = ‘nowhere’);
This query returns all pairs of (column1, column2) that can match any pair of (column3, column4) in the second table after being filtered by condition: column5 = ‘nowhere’.
最终实现删除 除N个较新的以外的所有旧版本数据, SQL如下:
-- NTH_VALUE方式
DELETE FROM TEST.TEST_VERSION
WHERE (ID,TS) IN (
SELECT A.ID,A.TS FROM TEST.TEST_VERSION A
INNER JOIN (
SELECT ID,NTH_VALUE(TS,3) WITHIN GROUP (ORDER BY TS DESC) THRES FROM TEST.TEST_VERSION GROUP BY ID) Z ON A.ID=Z.ID
WHERE A.TS < Z.THRES
);-- FIRST_VALUES方式
DELETE FROM TEST.TEST_VERSION
WHERE (ID,TS) IN (
SELECT A.ID,A.TS FROM TEST.TEST_VERSION A
INNER JOIN (
SELECT ID,FIRST_VALUES(TS,3) WITHIN GROUP (ORDER BY TS DESC) TSS FROM TEST.TEST_VERSION GROUP BY ID) Z ON A.ID=Z.ID
WHERE A.TS < ALL(Z.TSS)
);
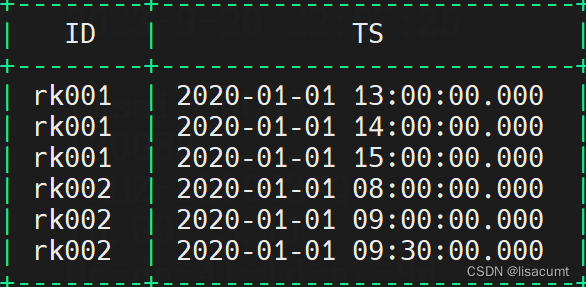
删除后效果:
三、探索
3.1 Phoenix的Row Timestamp 探索
Phoenix的Row Timestamp是为了在meta中更快检索数据而设置的。不能实现hbase 中的versions 数据在phoenix中展现。
如下测试案例:
phoenix建表,并插入数据:
create table TEST.TEST_ROW_TIMESTAMP(
ID VARCHAR NOT NULL,
TS TIMESTAMP NOT NULL,
NAME VARCHAR,
CONSTRAINT my_pk PRIMARY KEY (ID,TS ROW_TIMESTAMP)
) VERSIONS=5;UPSERT INTO TEST.TEST_ROW_TIMESTAMP(ID,TS,NAME) VALUES('rk001',TO_TIMESTAMP('2020-01-01 09:30:00'),'windows');
UPSERT INTO TEST.TEST_ROW_TIMESTAMP(ID,TS,NAME) VALUES('rk001',TO_TIMESTAMP('2020-01-01 10:30:00'),'mac');
UPSERT INTO TEST.TEST_ROW_TIMESTAMP(ID,TS,NAME) VALUES('rk001',TO_TIMESTAMP('2020-01-01 11:30:00'),'linux');
在hbase中查询表:
hbase(main):050:0> desc 'TEST:TEST_ROW_TIMESTAMP'
Table TEST:TEST_ROW_TIMESTAMP is ENABLED
TEST:TEST_ROW_TIMESTAMP, {TABLE_ATTRIBUTES => {coprocessor$1 => '|org.apache.phoenix.coprocessor.ScanRegionObserver|805306366|', coprocessor$2 => '|org.apache.phoenix.coprocessor.UngroupedAggregateRegionObserver|805306366|', coprocessor$3
=> '|org.apache.phoenix.coprocessor.GroupedAggregateRegionObserver|805306366|', coprocessor$4 => '|org.apache.phoenix.coprocessor.ServerCachingEndpointImpl|805306366|', coprocessor$5 => '|org.apache.phoenix.hbase.index.Indexer|805306366|index.b
uilder=org.apache.phoenix.index.PhoenixIndexBuilder,org.apache.hadoop.hbase.index.codec.class=org.apache.phoenix.index.PhoenixIndexCodec', METADATA => {'OWNER' => 'dcetl'}}
COLUMN FAMILIES DESCRIPTION
{NAME => '0', VERSIONS => '5', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'FAST_DIFF', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICAT
ION_SCOPE => '0', BLOOMFILTER => 'NONE', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'}
1 row(s)
Took 0.0235 secondshbase(main):049:0> scan 'TEST:TEST_ROW_TIMESTAMP'
ROW COLUMN+CELLrk001\x00\x80\x00\x01o`p\xC1\xC0\x00\x00\x00\x00 column=0:\x00\x00\x00\x00, timestamp=1577871000000, value=xrk001\x00\x80\x00\x01o`p\xC1\xC0\x00\x00\x00\x00 column=0:\x80\x0B, timestamp=1577871000000, value=windowsrk001\x00\x80\x00\x01o`\xA7\xB0@\x00\x00\x00\x00 column=0:\x00\x00\x00\x00, timestamp=1577874600000, value=xrk001\x00\x80\x00\x01o`\xA7\xB0@\x00\x00\x00\x00 column=0:\x80\x0B, timestamp=1577874600000, value=macrk001\x00\x80\x00\x01o`\xDE\x9E\xC0\x00\x00\x00\x00 column=0:\x00\x00\x00\x00, timestamp=1577878200000, value=xrk001\x00\x80\x00\x01o`\xDE\x9E\xC0\x00\x00\x00\x00 column=0:\x80\x0B, timestamp=1577878200000, value=linux
3 row(s)
Took 0.0072 seconds
如上查询结果,我们希望在hbase中只有一行数据,并保存为对多个版本,但实际查询到了多条数据,timestamp做为hbase表的rowkey的一部分了。phoenix在创建表时候没有使用hbase多版本保存机制。
3.2 phoenix 和 hbase表结构不一致
先创建hbase Table
create 'TEST:TEST_DIF_TS',{NAME => 'COLS', VERSIONS => 3}
put 'TEST:TEST_DIF_TS','001', 'COLS:NAME','zhangsan'
put 'TEST:TEST_DIF_TS','001', 'COLS:TS', 1695189085000
put 'TEST:TEST_DIF_TS','001', 'COLS:NAME','lisi'
put 'TEST:TEST_DIF_TS','001', 'COLS:TS', 1695189090000
put 'TEST:TEST_DIF_TS','001', 'COLS:NAME','wangwu'
put 'TEST:TEST_DIF_TS','001', 'COLS:TS', 1695189095000
put 'TEST:TEST_DIF_TS','001', 'COLS:NAME','zhaoliu'
put 'TEST:TEST_DIF_TS','001', 'COLS:TS', 1695189105000get 'TEST:TEST_DIF_TS','001',{COLUMN=>'COLS:NAME',VERSIONS=>3}
# 结果:
COLUMN CELLCOLS:NAME timestamp=1695784642879, value=zhaoliuCOLS:NAME timestamp=1695784642857, value=wangwuCOLS:NAME timestamp=1695784642830, value=lisi
创建Phoenix Table
create table TEST.TEST_DIF_TS(
ID VARCHAR NOT NULL,
TS TIMESTAMP NOT NULL,
NAME VARCHAR,
CONSTRAINT my_pk PRIMARY KEY (ID,TS)
);
UPSERT INTO TEST.TEST_DIF_TS(ID,TS,NAME) VALUES('rk001',TO_TIMESTAMP('2020-01-01 11:30:00'),'XXX');0: jdbc:phoenix:...> select * from TEST.TEST_DIF_TS;
+--------+--------------------------+-------+
| ID | TS | NAME |
+--------+--------------------------+-------+
| rk001 | 2020-01-01 11:30:00.000 | XXX |
+--------+--------------------------+-------+
再翻查hbase Table数据
hbase(main):004:0> scan 'TEST:TEST_DIF_TS'
ROW COLUMN+CELL001 column=COLS:NAME, timestamp=1695784642879, value=zhaoliu001 column=COLS:TS, timestamp=1695784643741, value=1695189105000rk001\x00\x80\x00\x01o`\xDE\x9E\xC0\x00\x00\x00\x column=0:\x00\x00\x00\x00, timestamp=1695786568345, value=x00rk001\x00\x80\x00\x01o`\xDE\x9E\xC0\x00\x00\x00\x column=0:\x80\x0B, timestamp=1695786568345, value=XXX
可以看到Phoenix只能查询到自己插入的数据,但是hbase可以查询到phoenix,所以phoenix会把不符合自己表结构的数据过滤掉。phoenix的会将自己所有的primary key字段拼接后作为hbase 的rowkey存入hbase。
参考文章:
Phoenix实践 —— Phoenix SQL常用基本语法总结小记
Phoenix 对 Hbase 中表的映射
phoenix使用详解
Phoenix 简介及使用方式
phoenix创建映射表和创建索引、删除索引、重建索引