文章目录
- 1. Create(创建)
- 1.1 insert
- 1.2 插入否则更新
- 1.3 替换
- 2. Retrieve(查询)
- 2.1 SELECT 列
- 2.2 WHERE 条件
- 2.3 结果排序
- 2.4 筛选分页结果
- 3. Update(更新)
- 4. Delete(删除)
- 4.1 删除数据
- 4.2 截断表
- 5. 插入查询结果
1. Create(创建)
1.1 insert

下面我们用这个表来操作:

单行数据 + 全列插入:

注意:这里在插入的时候,也可以不用指定id(当然,那时候就需要明确插入数据到那些列了),那么mysql会使用默认的值进行自增。
多行数据 + 指定列插入:

这里就没有指定qq的插入。
1.2 插入否则更新
由于 主键 或者 唯一键 对应的值已经存在而导致插入失败,可以选择性的进行同步更新操作语法:

ON DUPLICATE KEY 当发生重复key的时候。
举个例子:
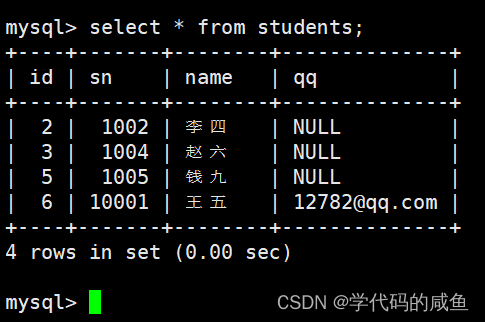
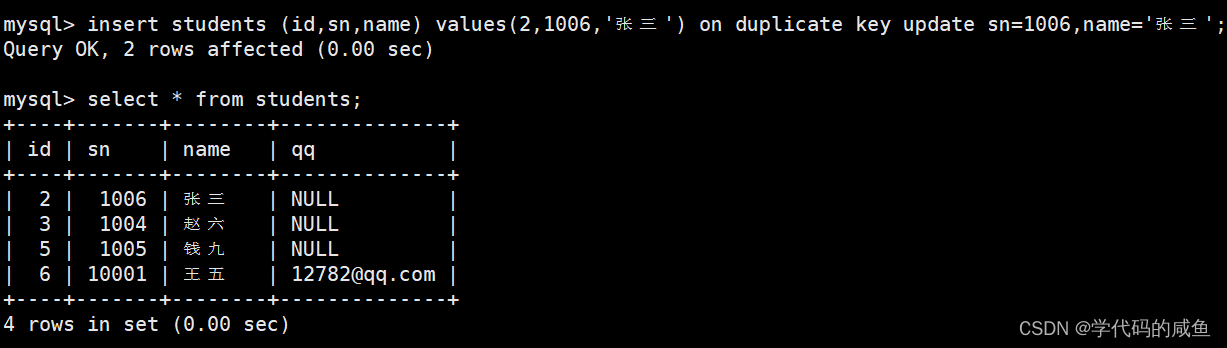
我们可以看到主键为2的字段,被更新成了张三。


1.3 替换
主键 或者 唯一键 没有冲突,则直接插入。主键 或者 唯一键 如果冲突,则删除后再插入。
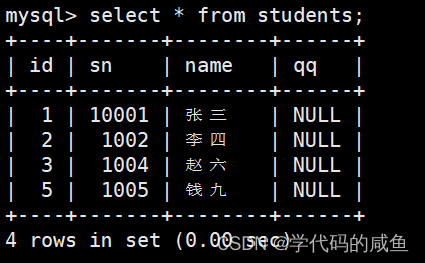
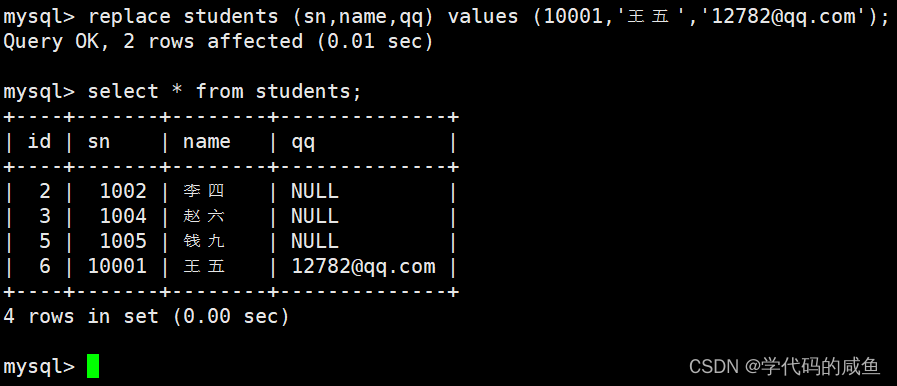
可以看到,我们把张三删除了,然后换成了王五。

2. Retrieve(查询)

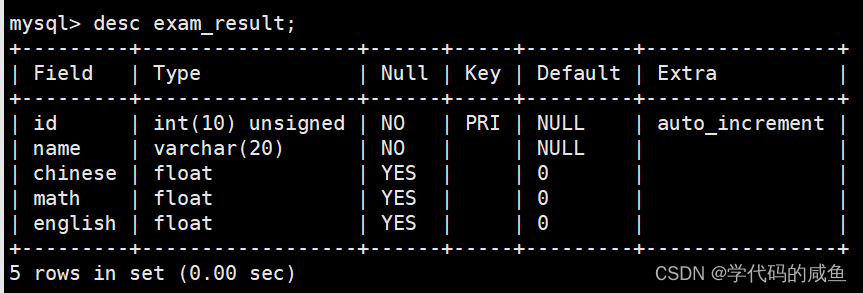
在这里创建了一个学生成绩表。并在里面插入了一些测试数据。
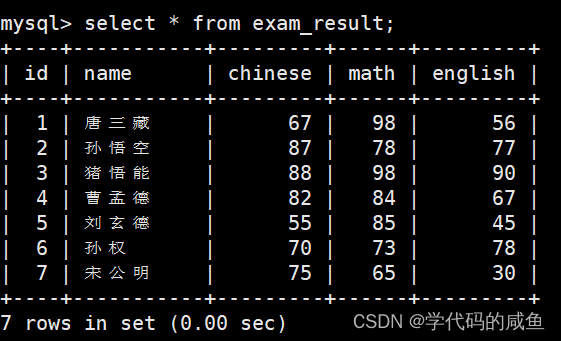
2.1 SELECT 列
全列查询:
上面的方式就是全列查询,通常情况下不建议使用 * 进行全列查询,1. 查询的列越多,意味着需要传输的数据量越大。 2. 可能会影响到索引的使用。
指定列查询:
指定列的顺序不需要按定义表的顺序来。
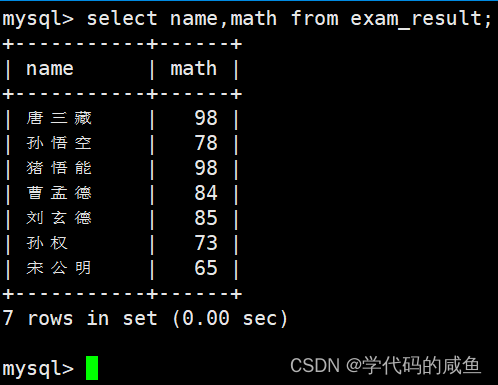
这里的意思是只查询名字和数学的列。
查询字段为表达式:
表达式包含一个字段:
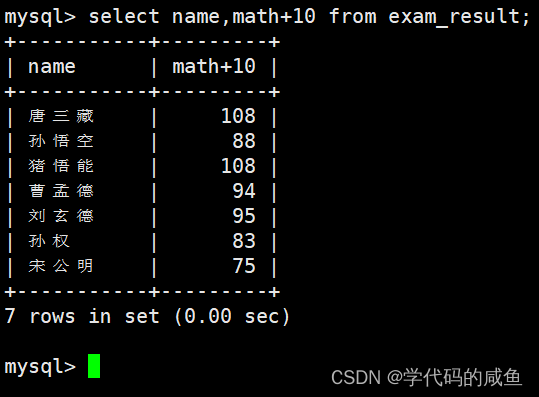
每个人的数学成绩都加上了10。
表达式包含多个字段:
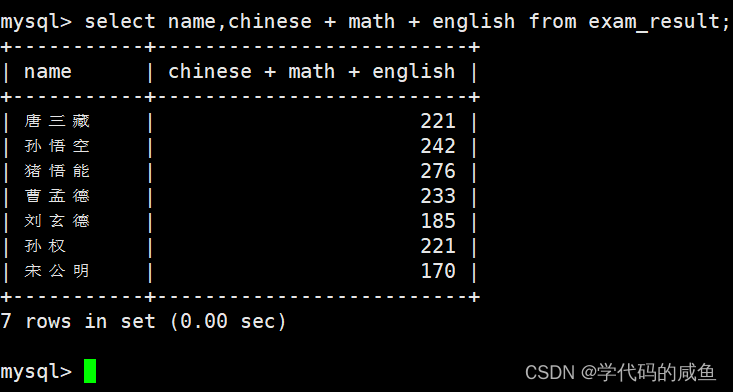
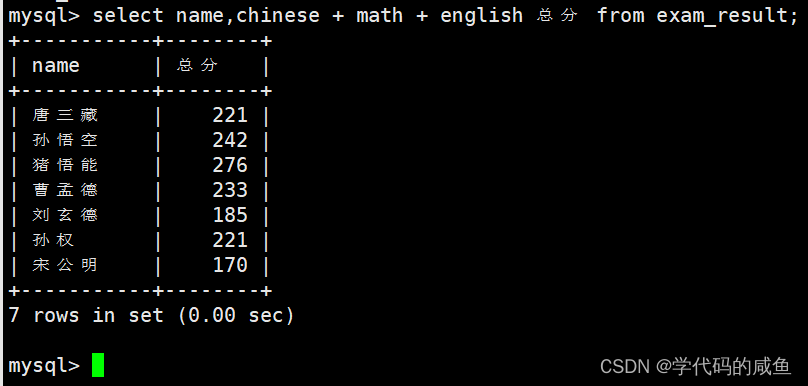
为查询结果指定别名:

结果去重:
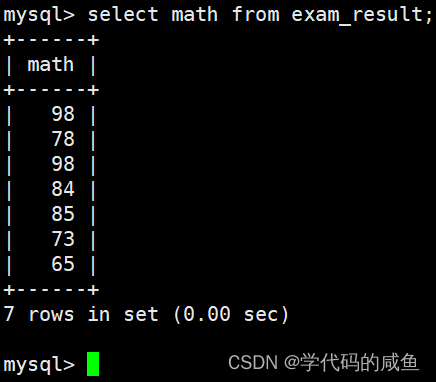
98 分重复了,我们可以在查询的时候进行去重。
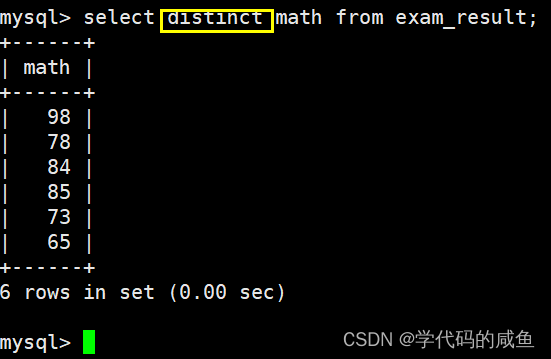
加上一个distinct就可以了。
2.2 WHERE 条件
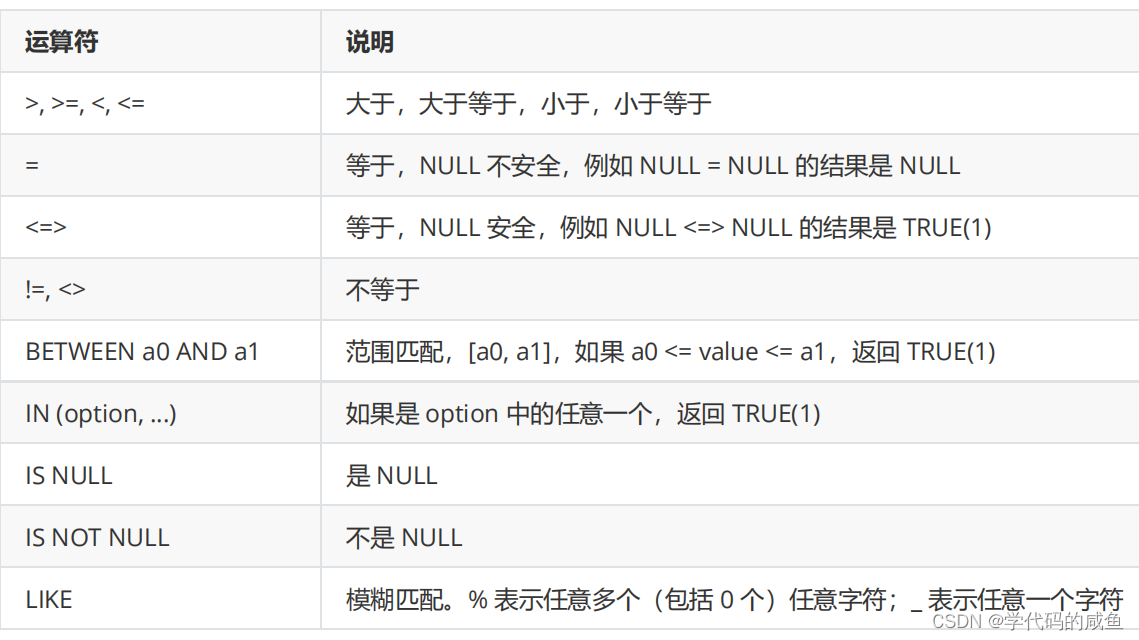
比较运算符:
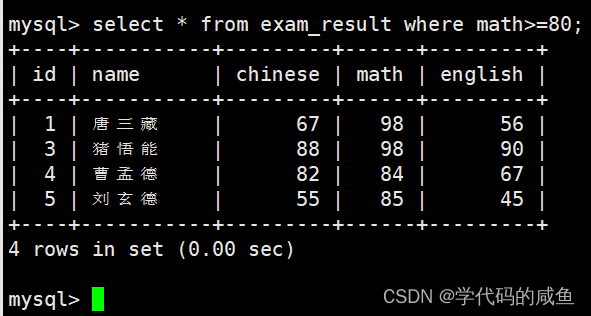
如果我们想要查询数学成绩在80分以上的同学:
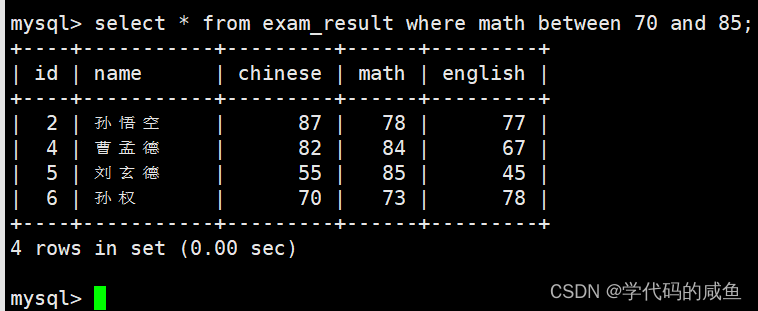
如果我们想要查询数学成绩在70到85之间的同学:
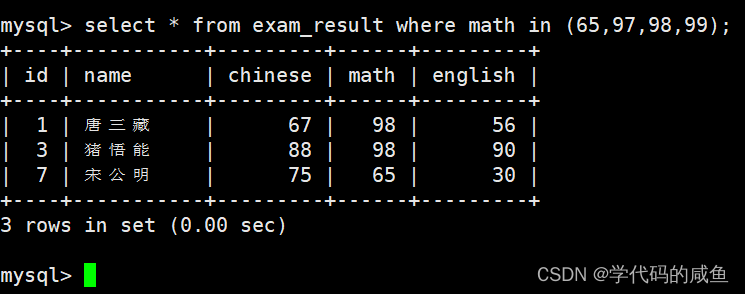
查询在集合里的数据:
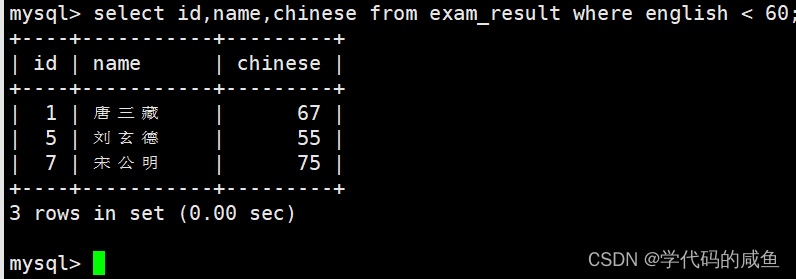
我们也可以查询英语不及格的同学的语文成绩如何:
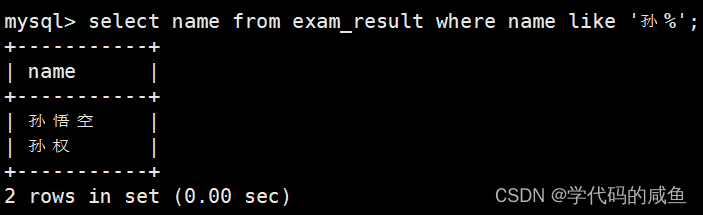
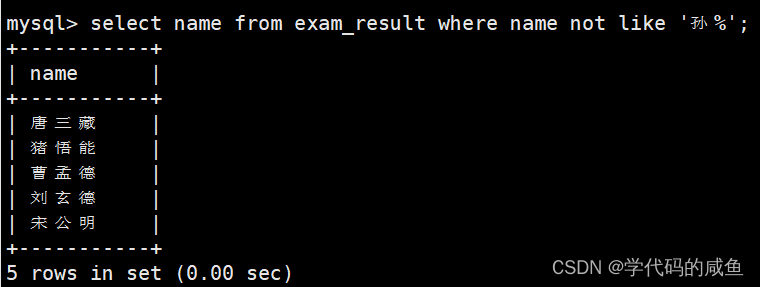
姓孙的同学 及 孙某同学:
% 匹配任意多个(包括 0 个)任意字符
如果我们查询除了姓孙的:
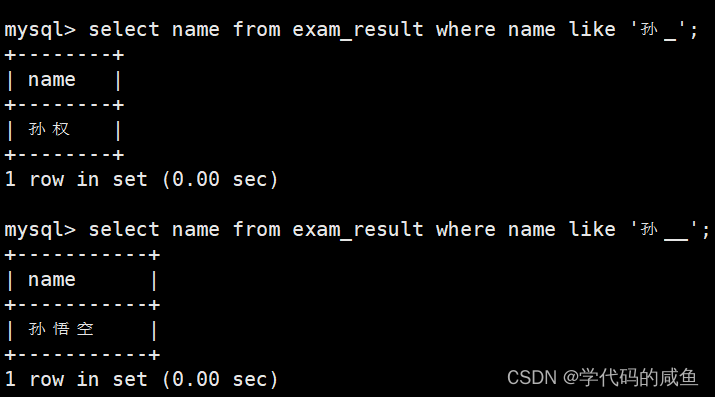
_ 匹配严格的一个任意字符,__匹配严格的二个任意字符
语文成绩好于英语成绩的同学:
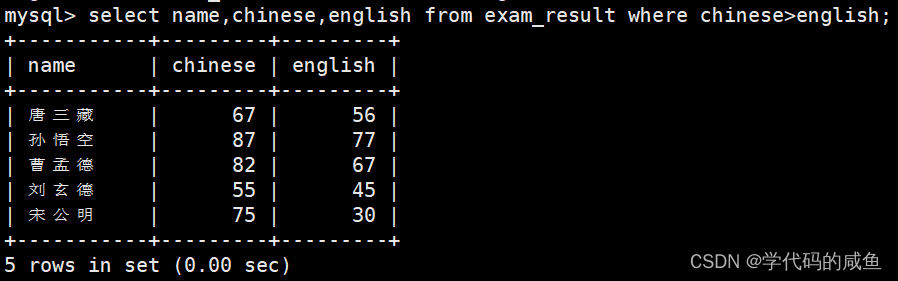
条件中比较运算符两侧都是字段。
总分在 200 分以下的同学:

那么我们该如何去筛选一个NULL的字段和空字符串呢?
筛选空字符串,我们可以使用=符号,但是筛选NULL,不能使用=号,可以采用<=>和IS来筛选。
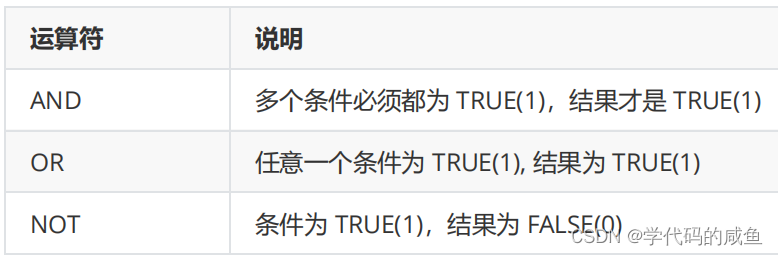
逻辑运算符:
语文成绩 > 80 并且不姓孙的同学:

2.3 结果排序

注意:没有 ORDER BY 子句的查询,返回的顺序是未定义的,永远不要依赖这个顺序。
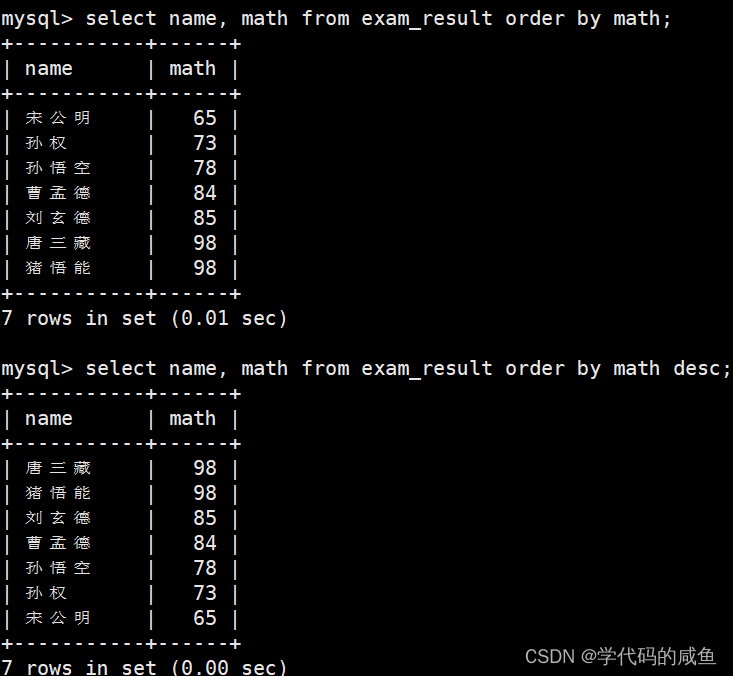
按数学成绩升序和降序显示:
查询同学各门成绩,依次按 数学降序,英语升序,语文升序的方式显示:
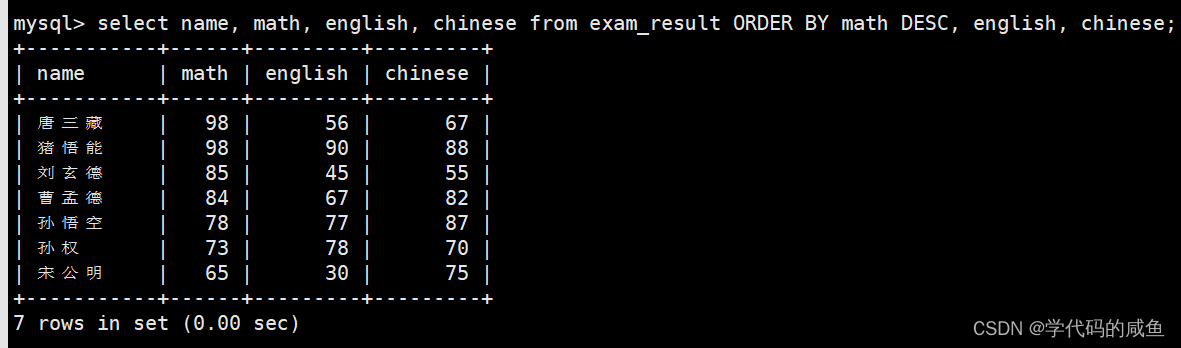
多字段排序,排序优先级随书写顺序。
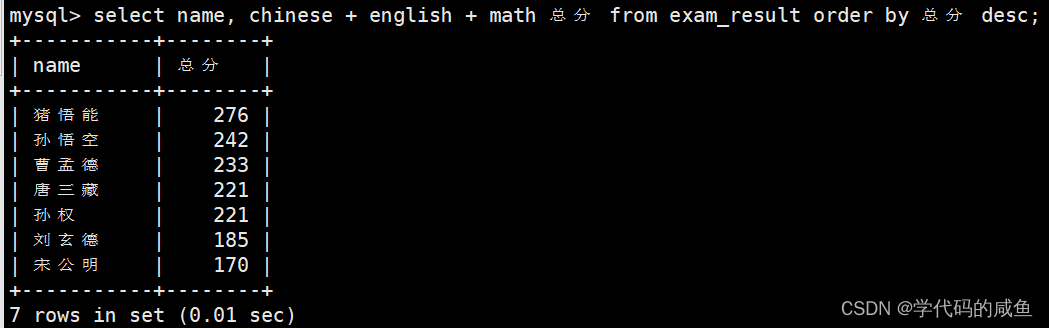
查询同学及总分,由高到低,ORDER BY 子句中可以使用列别名:
2.4 筛选分页结果
语法:起始下标为 0
从 0 开始,筛选 n 条结果。SELECT … FROM table_name [WHERE …] [ORDER BY …] LIMIT n;
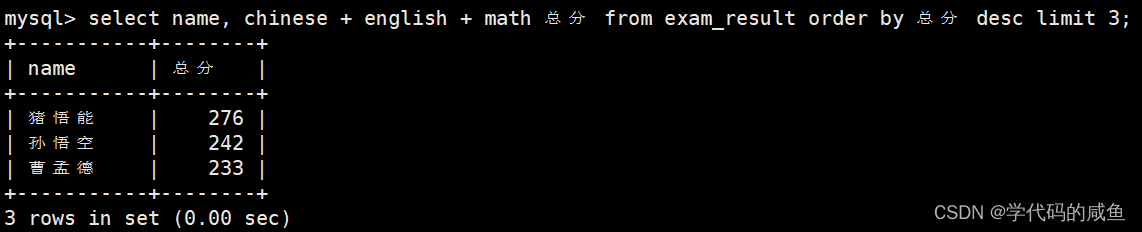
假设我们要筛选总分前3名的:
从 s 开始,筛选 n 条结果。SELECT … FROM table_name [WHERE …] [ORDER BY …] LIMIT s, n;
从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用。SELECT … FROM table_name [WHERE …] [ORDER BY …] LIMIT n OFFSET s;

建议:对未知表进行查询时,最好加一条 LIMIT 1,避免因为表中数据过大,查询全表数据导致数据库卡死。
3. Update(更新)
语法:
UPDATE table_name SET column = expr [, column = expr ...]
[WHERE ...] [ORDER BY ...] [LIMIT ...]
将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分:
查看原数据:
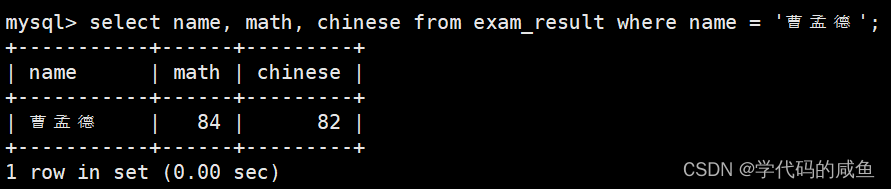
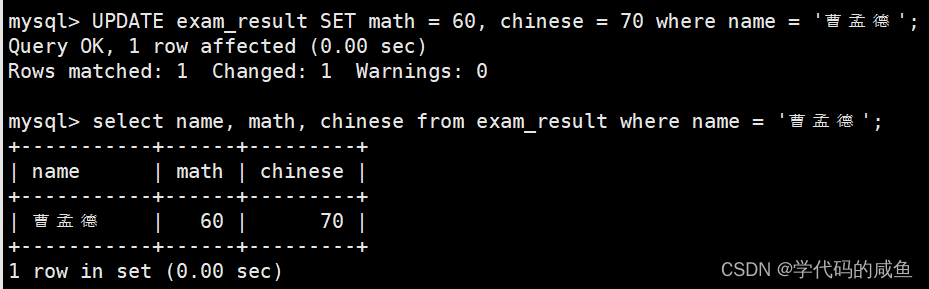
我们一定要加上where条件筛选,不然所有的成绩都会被修改。
将总成绩倒数前三的 3 位同学的数学成绩加上 30 分:
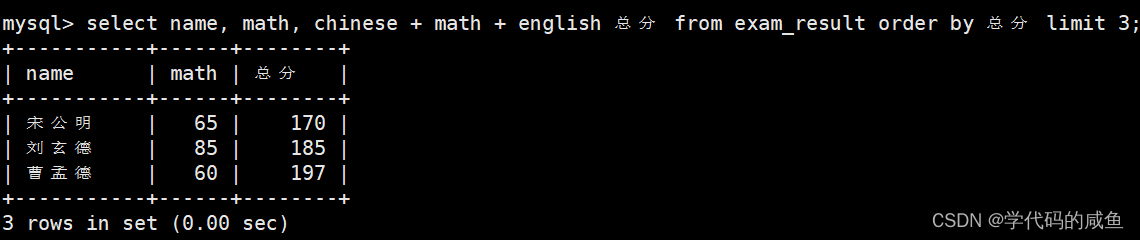
数据更新,不支持 math += 30 这种语法。

更新后数据,不可以按总分升序排序取前 3 个了。

4. Delete(删除)
4.1 删除数据

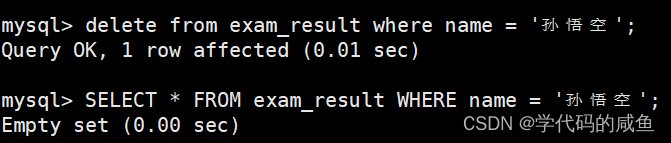
删除整张表数据:
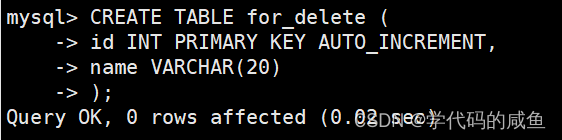
我们在这准备测试表来删除数据。
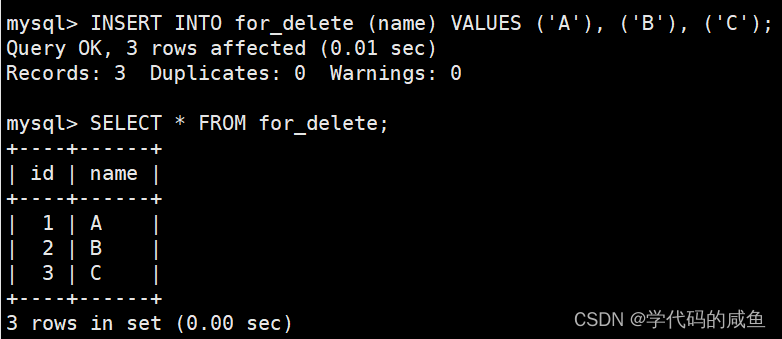
插入数据之后,我们就可以删除这个表了。
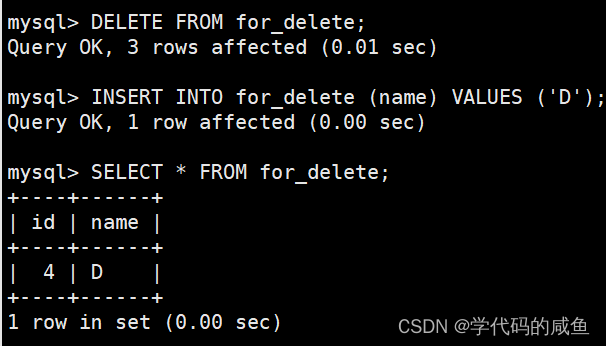
删除表之后,我们再插入一条数据,可以看到它的id还是会自增的。
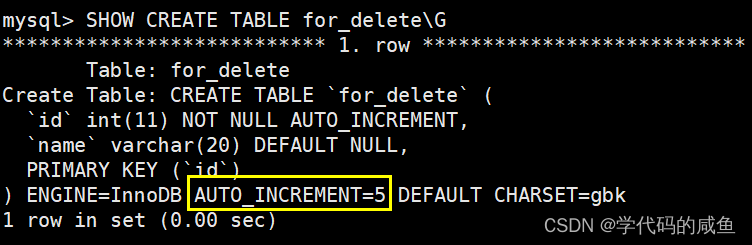
查看表结构,AUTO_INCREMENT项一直记录。
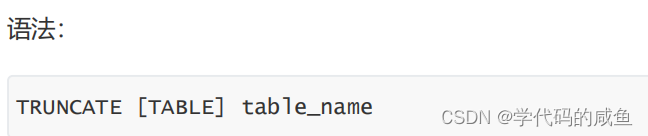
4.2 截断表
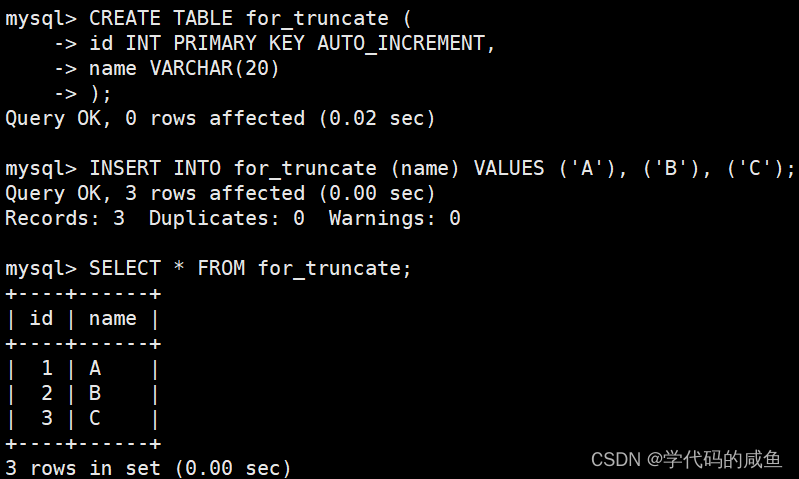
然后我们还按照上面的操作:
然后我们截断表:
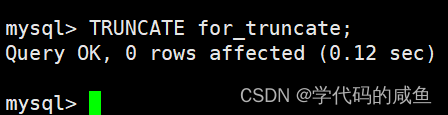
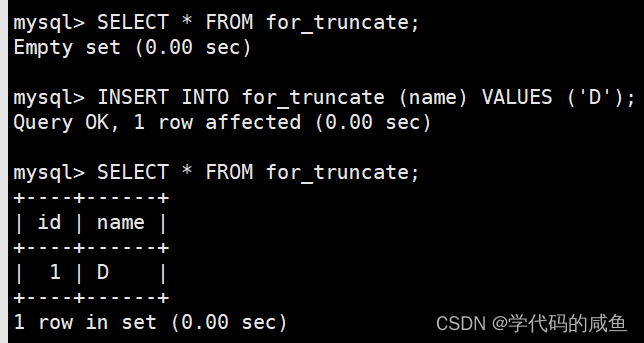
截断整表数据,注意影响行数是 0,所以实际上没有对数据真正操作。

5. 插入查询结果

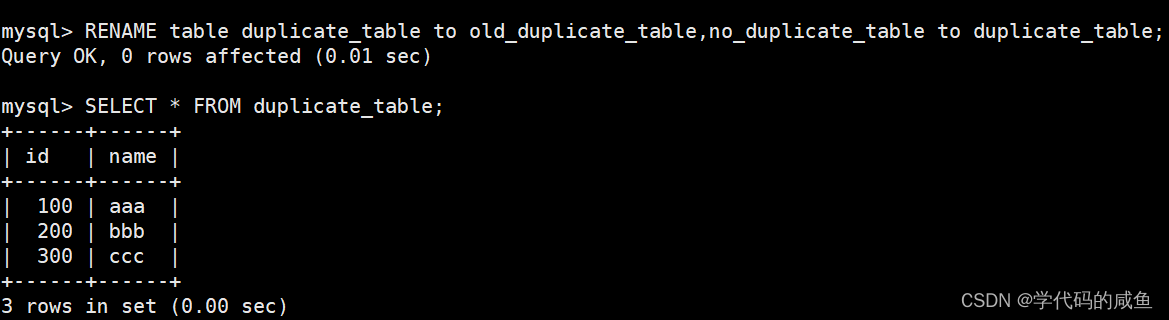
删除表中的的重复记录,重复的数据只能有一份:
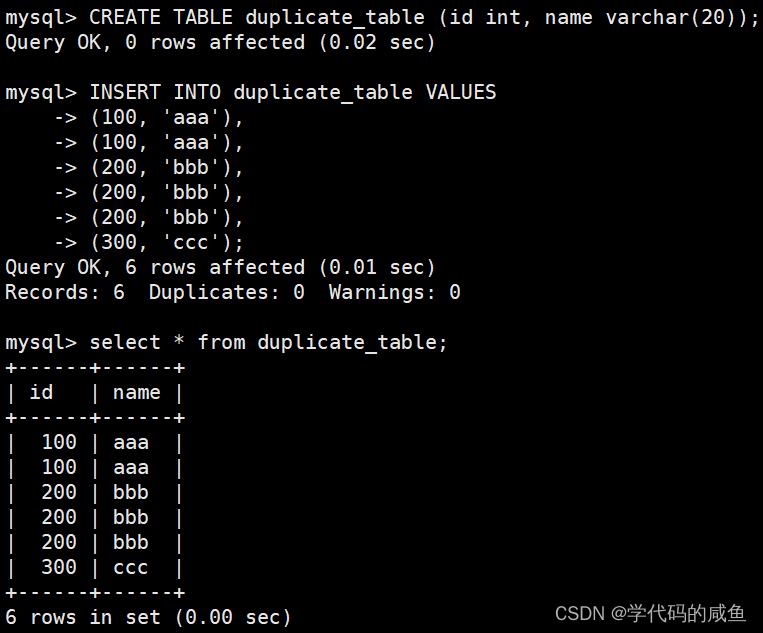
思路:创建一张空表 no_duplicate_table,结构和 duplicate_table 一样。
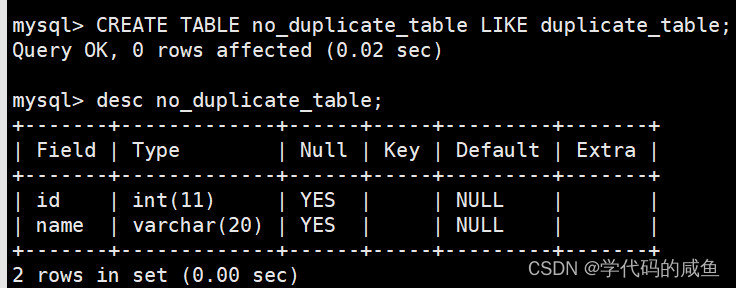
只能拷贝表的结构,不能把数据也拷贝过来。
将 duplicate_table 的去重数据插入到 no_duplicate_table
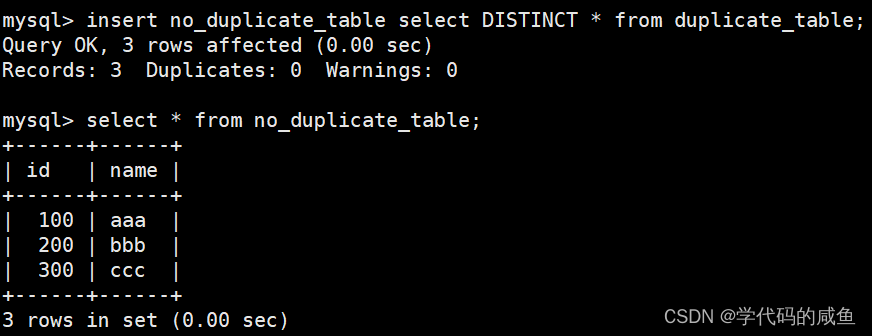
DISTINCT这个是查询时可以去重。
通过重命名表,实现原子的去重操作。