redis查看耗时久的命令主要有两招:latency和slow log
【latency】
在Redis中,latency命令用于监视和测量Redis实例的延迟。
先进入redis:
redis-cli -h 127.0.0.1 -p 24000
[查看延迟监视器阈值]
CONFIG GET latency-monitor-threshold
这个值返回0,代表没有开启延迟监控。
[开启/设置延迟监视的阈值]
启动延迟监控的第一步是以毫秒为单位设置延迟阀值(latency threshold)。仅当事件耗时超过指定的延迟阀值才会记录延迟毛刺。用户可根据需要来设置延迟阀值。
例如,如果基于Redis的应用能接受的最大延迟是100毫秒,则延迟阀值应当设置为大于或等于100毫秒,以便记录所有阻塞Redis服务器的事件。
CONFIG SET latency-monitor-threshold 100 (这里的单位是毫秒)
[技巧]
模拟耗时任务,1代表这个命令耗时1秒:
debug sleep 1
[latency 具体用法]
latency help:查看用法
latency docker:显示一份人类可读的延迟分析报告
latency latest:返回所有事件的最新延迟样本
latency history command:返回给定事件的延迟时间序列,能提供更多统计数据,如延迟毛刺间的平均时间间隔,中值偏差和易懂的事件分析。
latency reset:重置一个或多个事件的延迟时间序列数据。
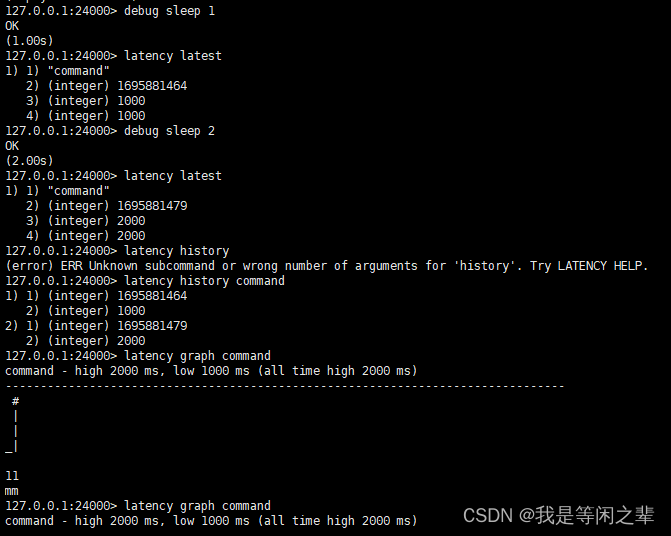
latency graph command:返回事件类的ASCII延迟图。graph子命令非常有用,能快速判断指定事件的延迟趋势。图形对最小值和最大值的图例进行了规范化定义,即0表示最小值(即最低一行的下划线),最高一行的#表示最大值。
字符画每列下面的垂直标签表示事件是多久之前发生的,可用秒、分钟、小时或天来表示时间单位。例如,"1m"表示下图中第1个图形化的事件发生在1m之前。

参考文章:
https://redis.com.cn/topics/latency-monitor.html
https://redis.io/docs/management/optimization/latency-monitor/
【slow log】
latency可以查看到哪些时刻有出现耗时比较久的命令,但是无法查看到是哪些具体的命令。使用slow log便可以看到具体是哪些命令耗时比较久。
Redis Slow Log 是一个记录超过指定执行时间的查询的系统。执行时间不包括与客户端对话、发送回复等 I/O 操作,而只包括实际执行命令所需的时间(这是执行命令的唯一阶段,在此期间线程会被阻塞,无法为其他请求提供服务)。
慢日志有两个参数:slowlog-max-len和slowlog-log-slower-than。
每当一条命令的执行时间超过 slowlog-log-slower-than 配置指令所定义的阈值时,就会在慢日志中添加一个新条目。慢日志的最大条目数由 slowlog-max-len 配置指令决定。
配置可以通过编辑redis.conf文件来完成,或者在服务器运行期间通过使用CONFIG GET和CONFIG SET命令来完成。
[查看这两个参数]
config get slowlog-max-len (默认是10000,单位是微妙,即10毫秒)
config get slowlog-log-slower-than (默认128)
[slow log具体用法]
slowlog help:查看用法
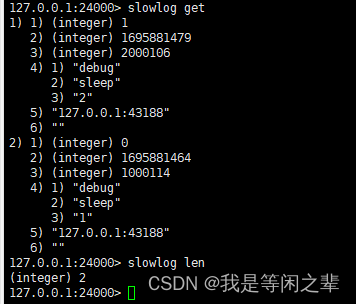
slowlog get [count]:按时间顺序返回慢速日志中的条目。默认情况下,命令会返回日志中最近的十个条目。可选的 count 参数限制了返回条目的数量,因此命令最多返回 count 条目,特殊数字 -1 表示返回所有条目。
slowlog len:返回慢速日志中的当前条目数。
slowlog reset:此命令重置慢速日志,清除其中的所有条目。一旦删除,信息将永远丢失。
参考文章:
https://redis.io/commands/slowlog-get/