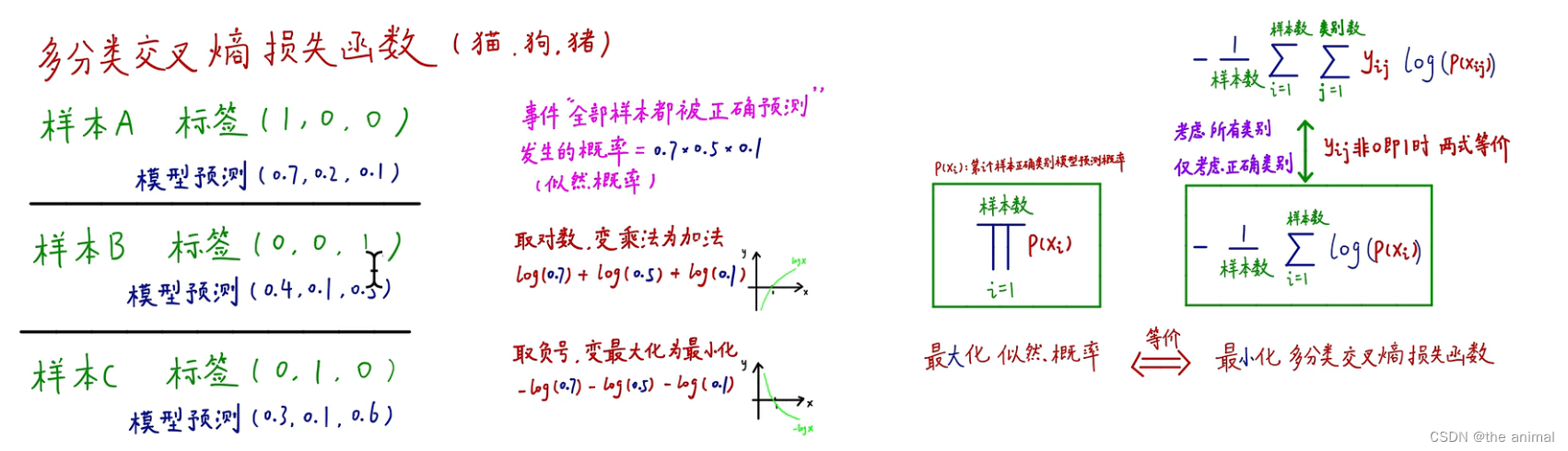
多分类交叉熵损失函数:每个样本的标签已经给出,模型给出在三种动物上的预测概率。将全部样本都被正确预测的概率求得为0.70.50.1,也称为似然概率。优化的目标就是希望似然概率最大化。如果样本很多,概率不断连乘,就会造成概率越来越小。对其取对数,使其最大化。在实际运用中,损失函数都是求最小化,所以取负号,将最大化变为最小化。
教师–学生网络的方法,属于迁移学习的一种。迁移学习也就是将一个模型的性能迁移到另一个模型上,而对于教师–学生网络,教师网络往往是一个更加复杂的网络,具有非常好的性能和泛化能力,可以用这个网络来作为一个soft target来指导另外一个更加简单的学生网络来学习,使得更加简单、参数运算量更少的学生模型也能够具有和教师网络相近的性能,也算是一种模型压缩的方式。将教师网络的知识迁移到学生网络,就是知识蒸馏。
知识蒸馏:用教师网络的“soft target”作为学生网络的label。使用一个额外的数据集,将数据集先送入教师网络中,获得soft target。 将数据集和label送入学生网络。如果 soft target的熵很高,也就是不同类别的概率差异非常小,那么这就提供了非常多的信息。假如使用hard target作为训练label,比如猫的label为(1,0,0),那么网络只能学习到猫的梯度,而在soft target,可以得出猫和狗更像,和汽车不像。

流程:
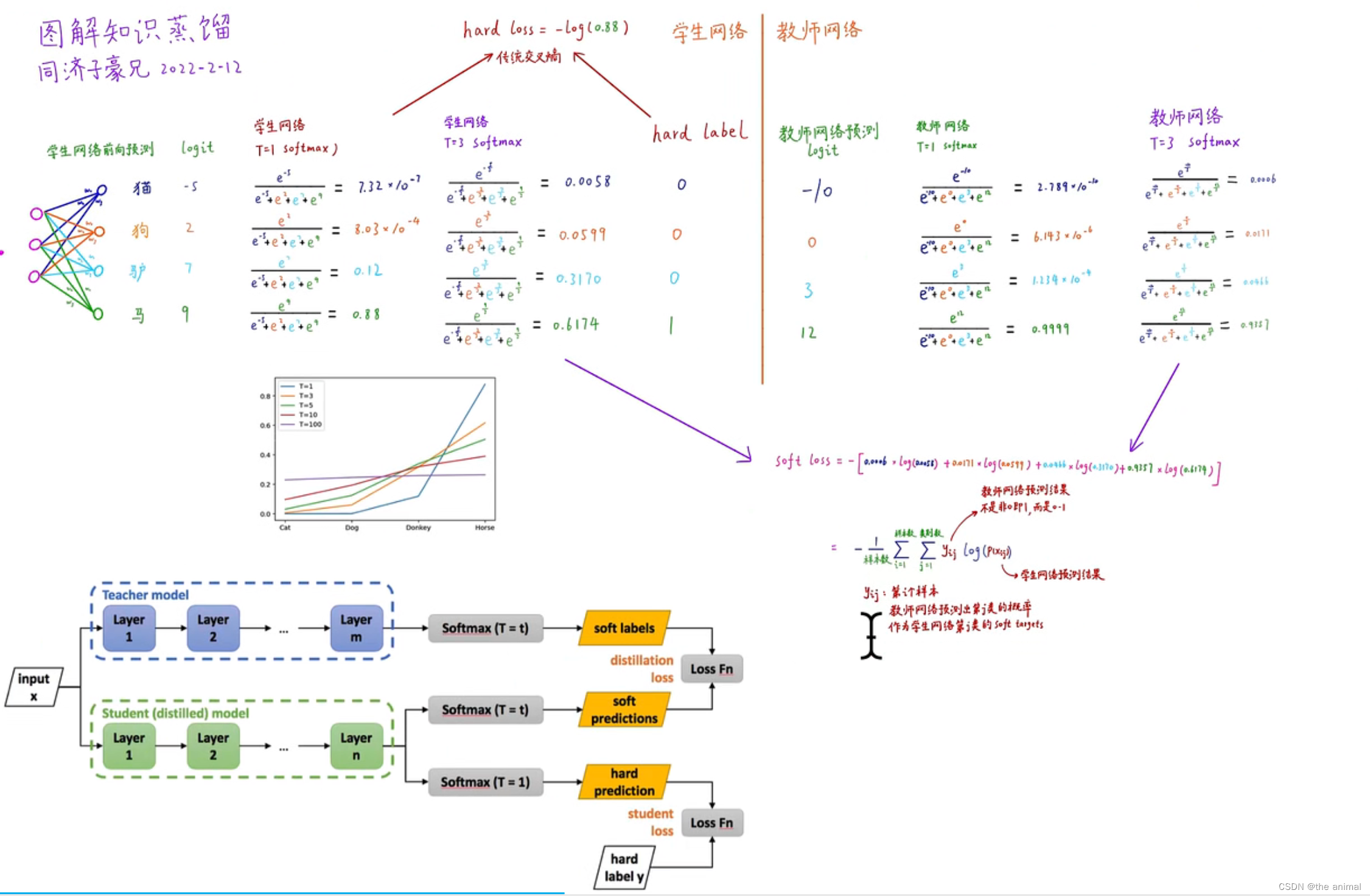
T越大,输入的结果越soft,包含的知识也就越多。在训练的时候,教师网络和学生网络的T相同,在预测的时候,T为1。





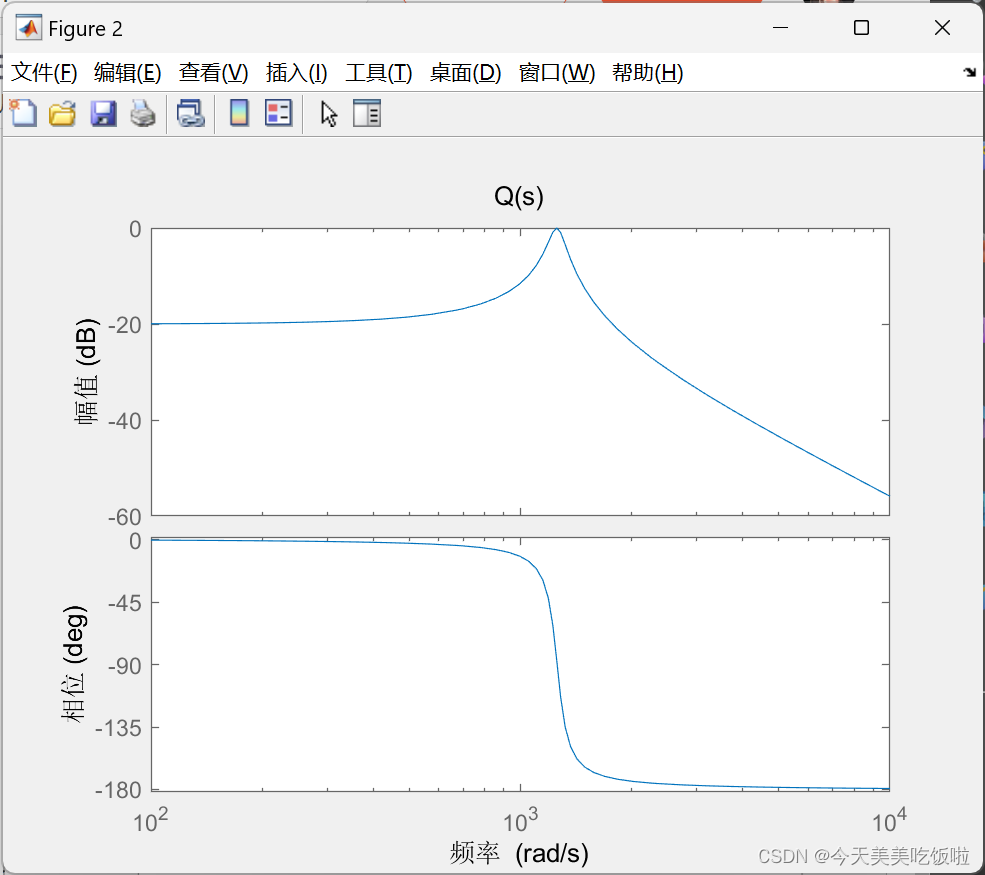
![[论文笔记]UNILM](https://img-blog.csdnimg.cn/img_convert/2d1261c204cbcbe50002d7933098b7ce.png)