接上文 Mysql分库分表
1.分布式序列简介

在分布式系统下,怎么保证ID的生成满足以上需求?

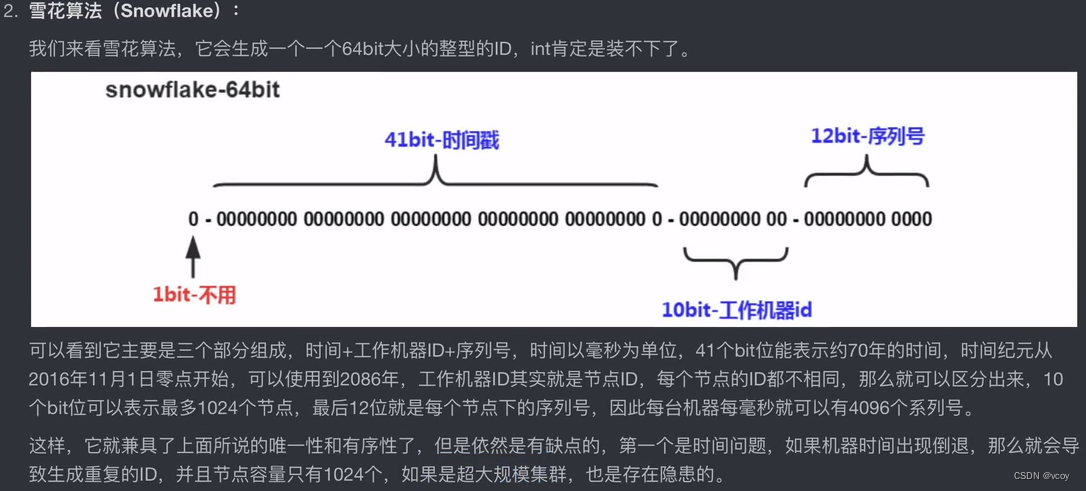
ShardingJDBC支持以上两种算法自动生成ID。这里,使用ShardingJDBC让主键ID以雪花算法进行生成,首先配置数据库,因为默认的注解id是int类型,装不下64位,需要进行修改:
# 在本地和远端服务器数据库都要运行
ALTER TABLE `yyds`.`test` MODIFY COLUMN `id` bigint(128) NOT NULL FIRST;
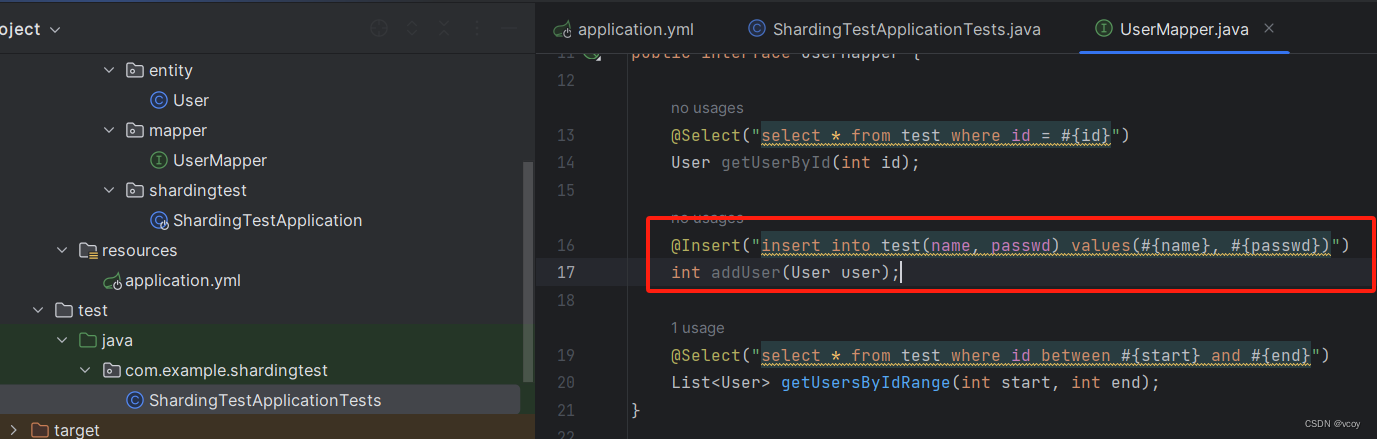
然后修改mybatis的插入语句,因为现在id是ShardingJDBC自动生成,不需要自己加了:
@Insert("insert into test(name, passwd) values(#{name}, #{passwd})")
int addUser(User user);
修改测试用例
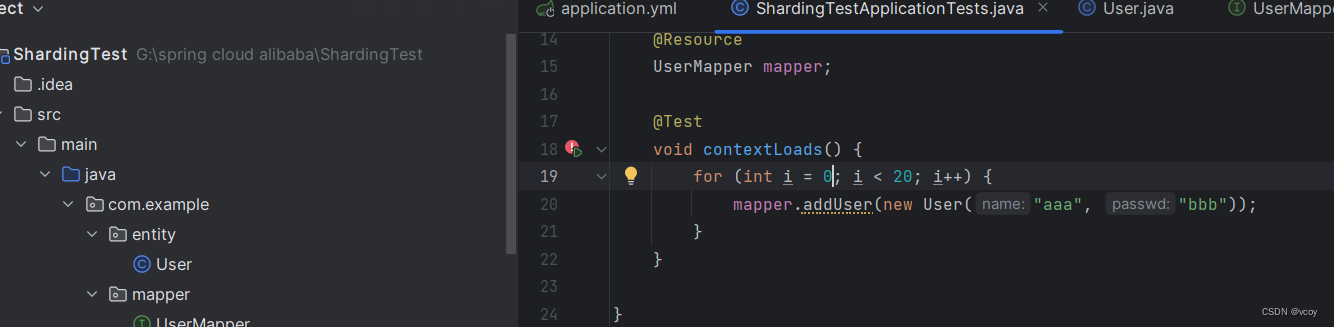
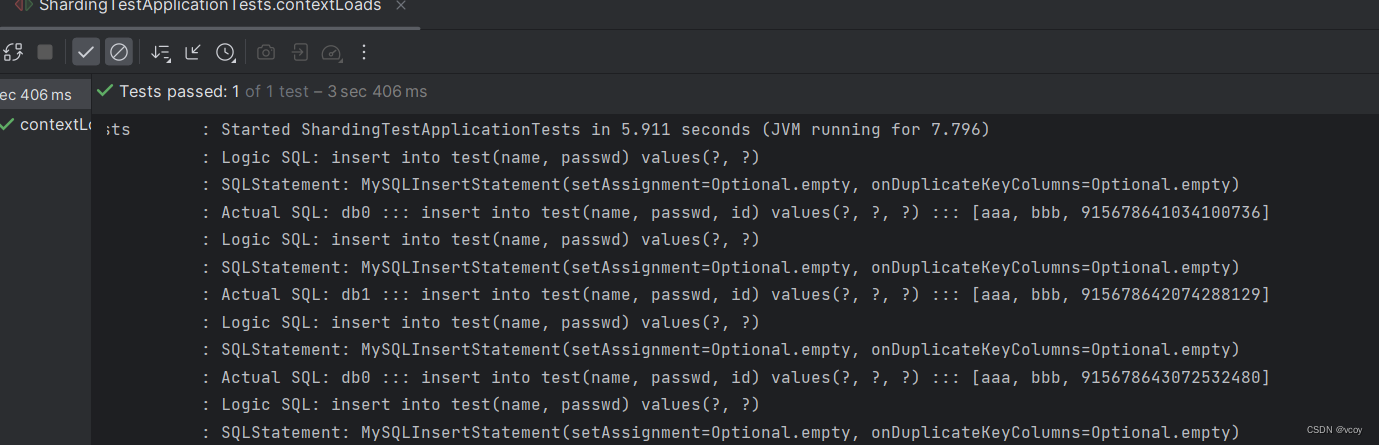
@Testvoid contextLoads() {for (int i = 0; i < 20; i++) {mapper.addUser(new User("aaa", "bbb"));}}
修改配置文件
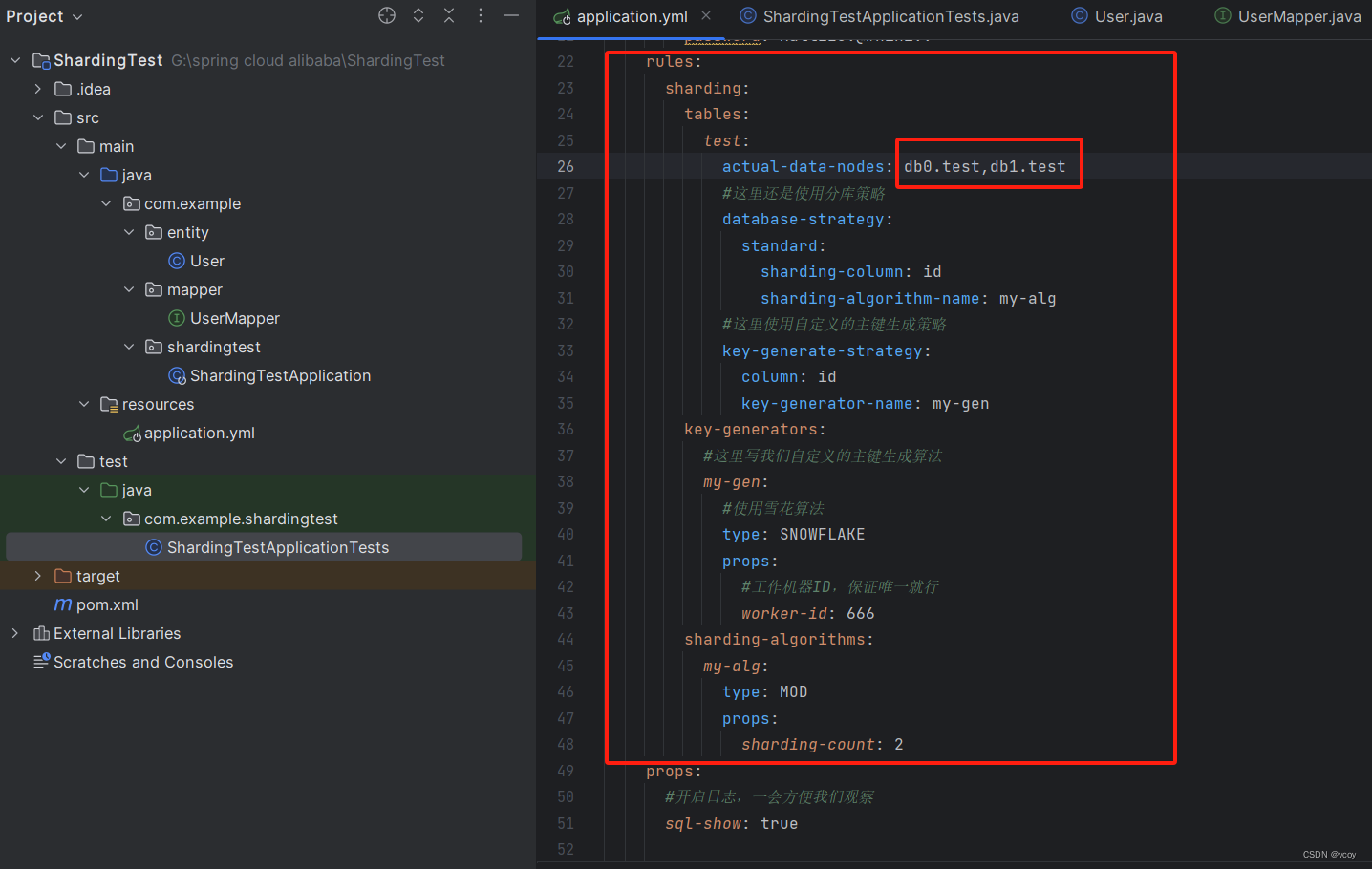
spring:shardingsphere:datasource:sharding:tables:test:actual-data-nodes: db0.test,db1.test#这里还是使用分库策略database-strategy:standard:sharding-column: idsharding-algorithm-name: my-alg#这里使用自定义的主键生成策略key-generate-strategy:column: idkey-generator-name: my-genkey-generators:#这里写我们自定义的主键生成算法my-gen:#使用雪花算法type: SNOWFLAKEprops:#工作机器ID,保证唯一就行worker-id: 666sharding-algorithms:my-alg:type: MODprops:sharding-count: 2
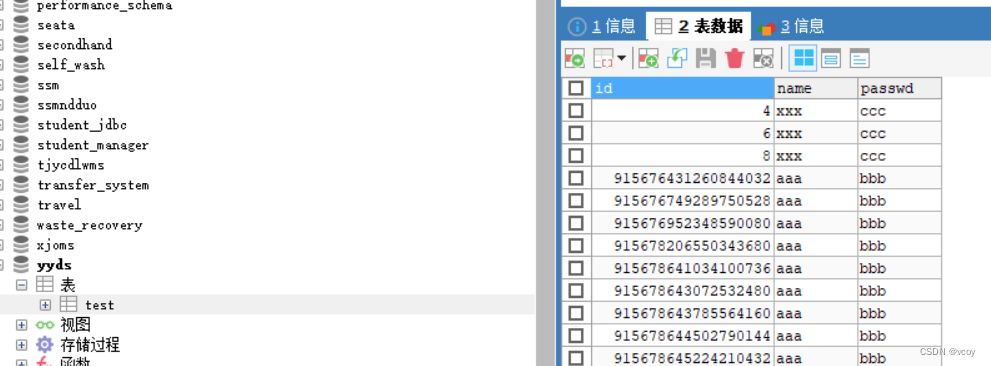
此时不再需要test_01,test_02表了,数据库中可删除。
运行测试用例