到目前为止,在本课程中,从选择模型到微调模型,再到将其与人类偏好对齐,这一切都将在您部署应用程序之前发生。为了帮助您规划生成式AI项目生命周期的各个阶段,这个速查表提供了每个工作阶段所需的时间和精力的一些指示。正如您之前所见,预训练大型语言模型可能是一个巨大的工作。由于模型架构决策、所需的大量训练数据和所需的专业知识,这个阶段是您将面临的最复杂的阶段。

不过请记住,通常情况下,您将以现有的基础模型为基础开始开发工作。您可能能够跳过这个阶段。
如果您正在使用基础模型,您可能会通过提示工程来开始评估模型的性能,这需要较少的技术专业知识,也不需要对模型进行额外的训练。

如果您的模型没有达到您的需求,接下来您将考虑提示调整和微调。根据您的用例、性能目标和计算预算,您将尝试的方法可能从全面微调到参数高效微调技术,如laura或提示调整不等。这项工作需要一定程度的技术专业知识。但由于微调在相对较小的训练数据集上可能非常成功,因此这个阶段可能在一天内完成。

使用来自人类反馈的强化学习来对齐您的模型可以很快完成,一旦您有了训练的奖励模型。您可能会尝试看是否可以使用现有的奖励模型来进行这项工作,就像您在本周的实验中看到的那样。
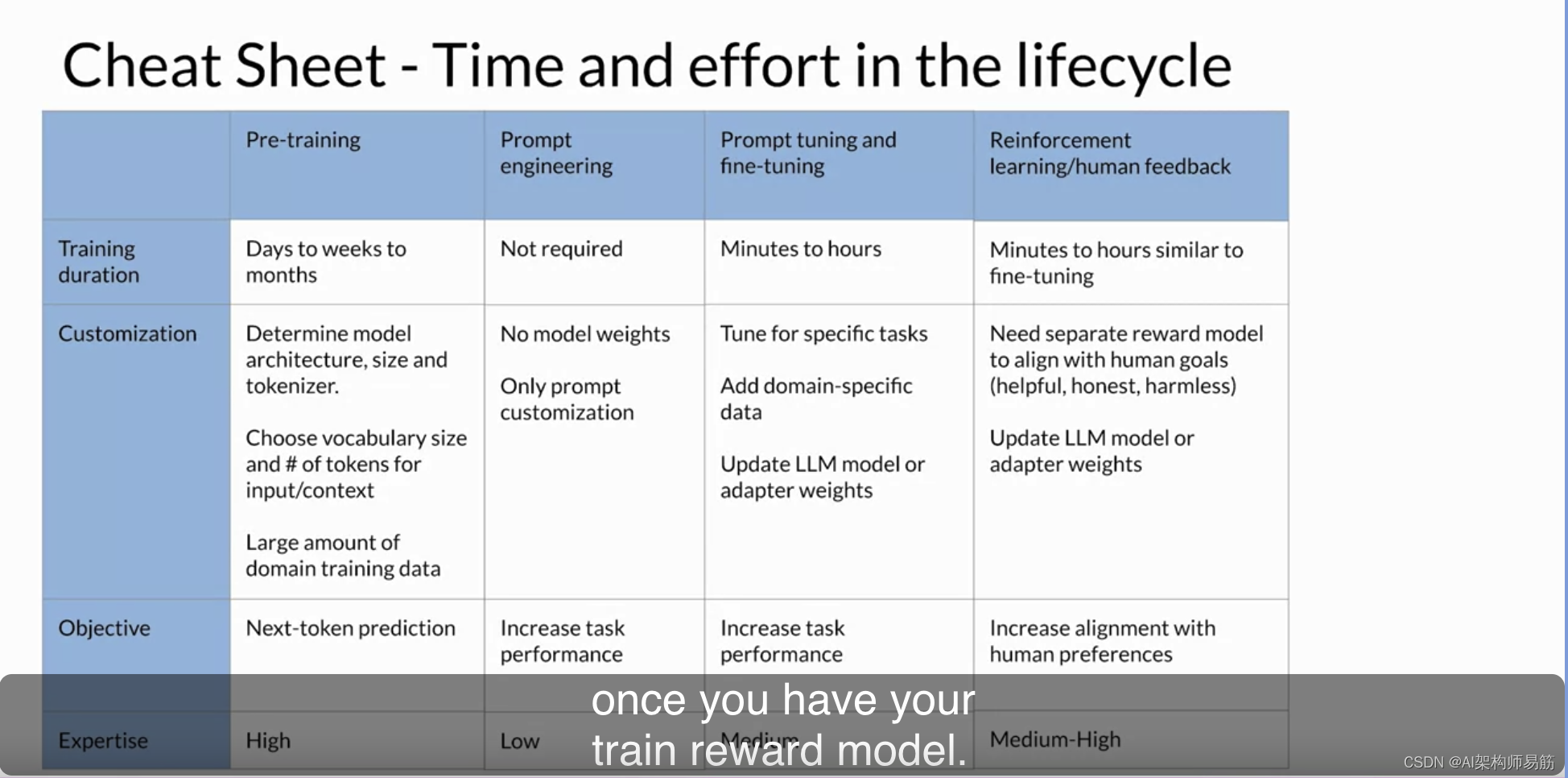
然而,如果您必须从头开始训练奖励模型,由于收集人类反馈所需的工作量,可能需要很长时间。
最后,在上一个视频中学到的优化技术通常在复杂性和工作量方面处于中间位置,但假设对模型的更改不会太大地影响性能,可以迅速进行。

经过所有这些步骤后,您希望已经培训和微调了一个适用于您特定用例的优化部署的LLM。祝贺您!在本课程的最后一系列视频中,您将探讨LLM性能的其余问题,您可能需要在启动应用程序之前解决,以及可以克服这些问题的技术。让我们继续前进,看看接下来的内容。
Reference
https://www.coursera.org/learn/generative-ai-with-llms/lecture/VaOBV/generative-ai-project-lifecycle-cheat-sheet









![2023年中国烹饪机器人市场发展概况分析:整体规模较小,市场仍处于培育期[图]](https://img-blog.csdnimg.cn/img_convert/a53112d922a5cda06a4ce0edd20cae4b.png)