CentOS版本:CentOS 7
Nginx版本:1.24.0
两种安装方式:
一、通过 yum 安装,最简单,一键安装,全程无忧。
二、通过编译源码包安装,需具备配置相关操作。
最后附+:设置 Nginx 服务开机启动
一、通过 yum 安装
需要 root 权限,普通用户使用 sudo 进行命令操作
安装参考信息:https://nginx.org/en/linux_packages.html#RHEL
1、安装依赖
sudo yum install yum-utils

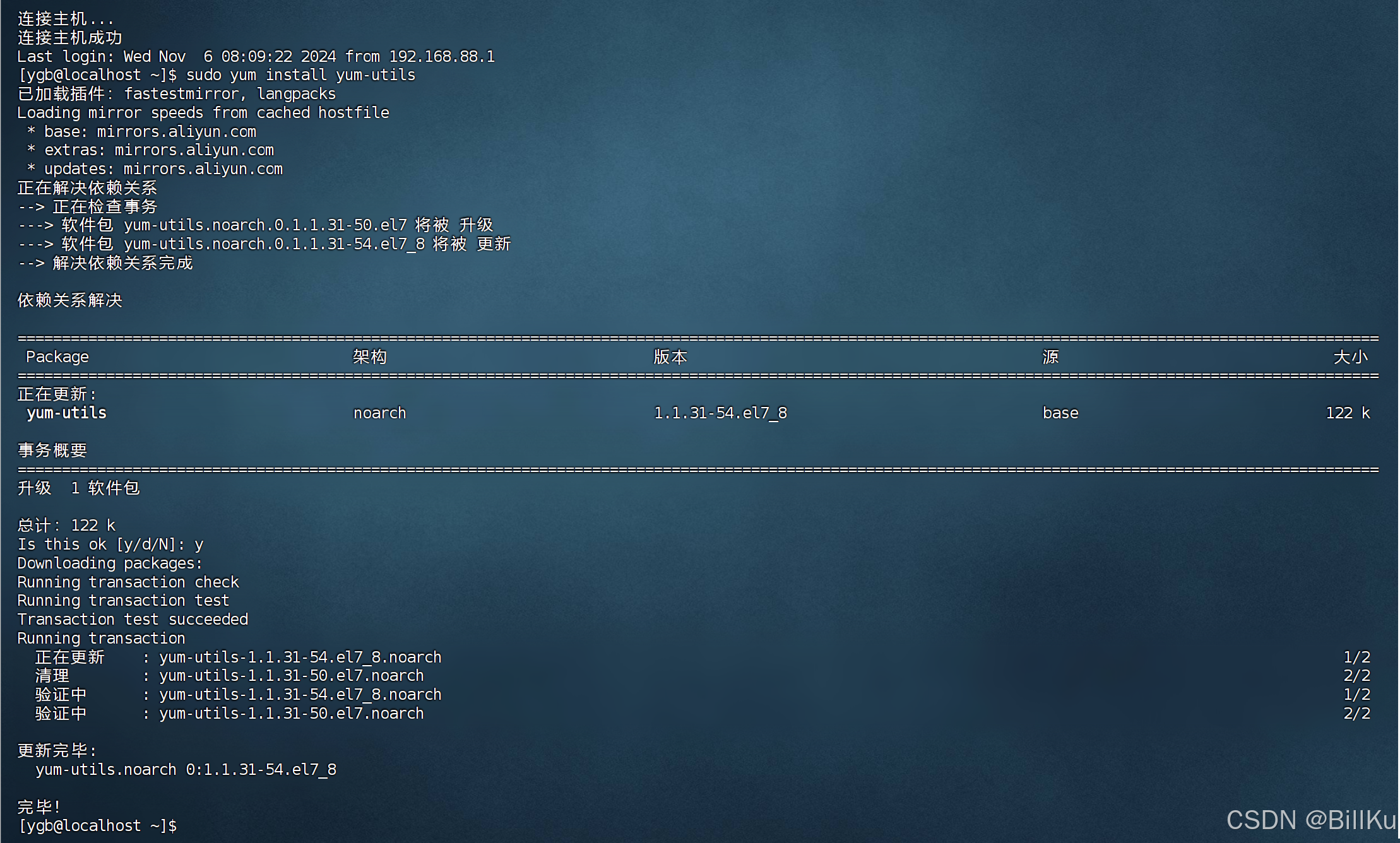
2、创建仓库文件
在 /etc/yum.repos.d 目录下创建仓库文件nginx.repo,并在文件中添加以下内容:
sudo vim /etc/yum.repos.d/nginx.repo
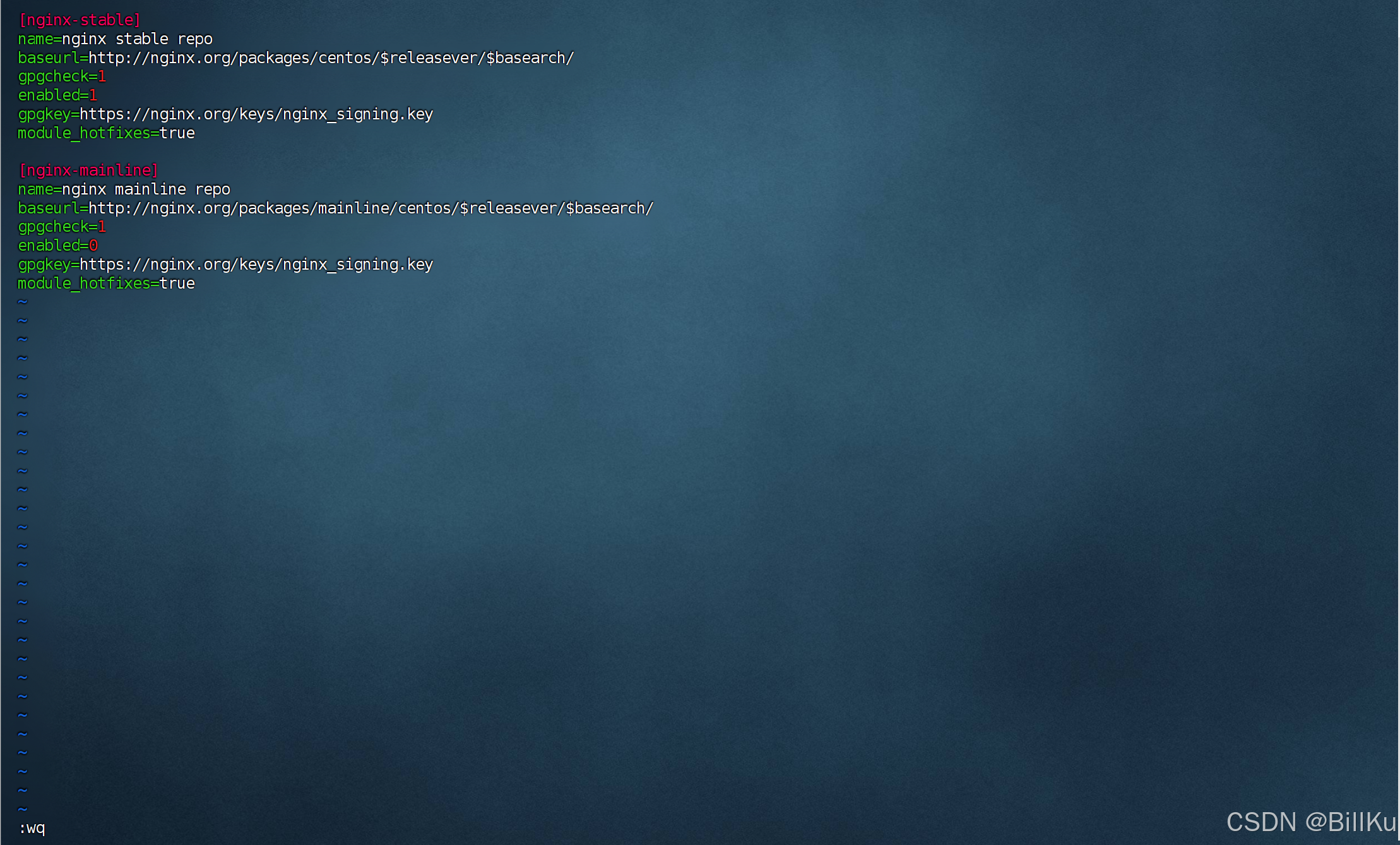
[nginx-stable]
name=nginx stable repo
baseurl=http://nginx.org/packages/centos/$releasever/$basearch/
gpgcheck=1
enabled=1
gpgkey=https://nginx.org/keys/nginx_signing.key
module_hotfixes=true[nginx-mainline]
name=nginx mainline repo
baseurl=http://nginx.org/packages/mainline/centos/$releasever/$basearch/
gpgcheck=1
enabled=0
gpgkey=https://nginx.org/keys/nginx_signing.key
module_hotfixes=true
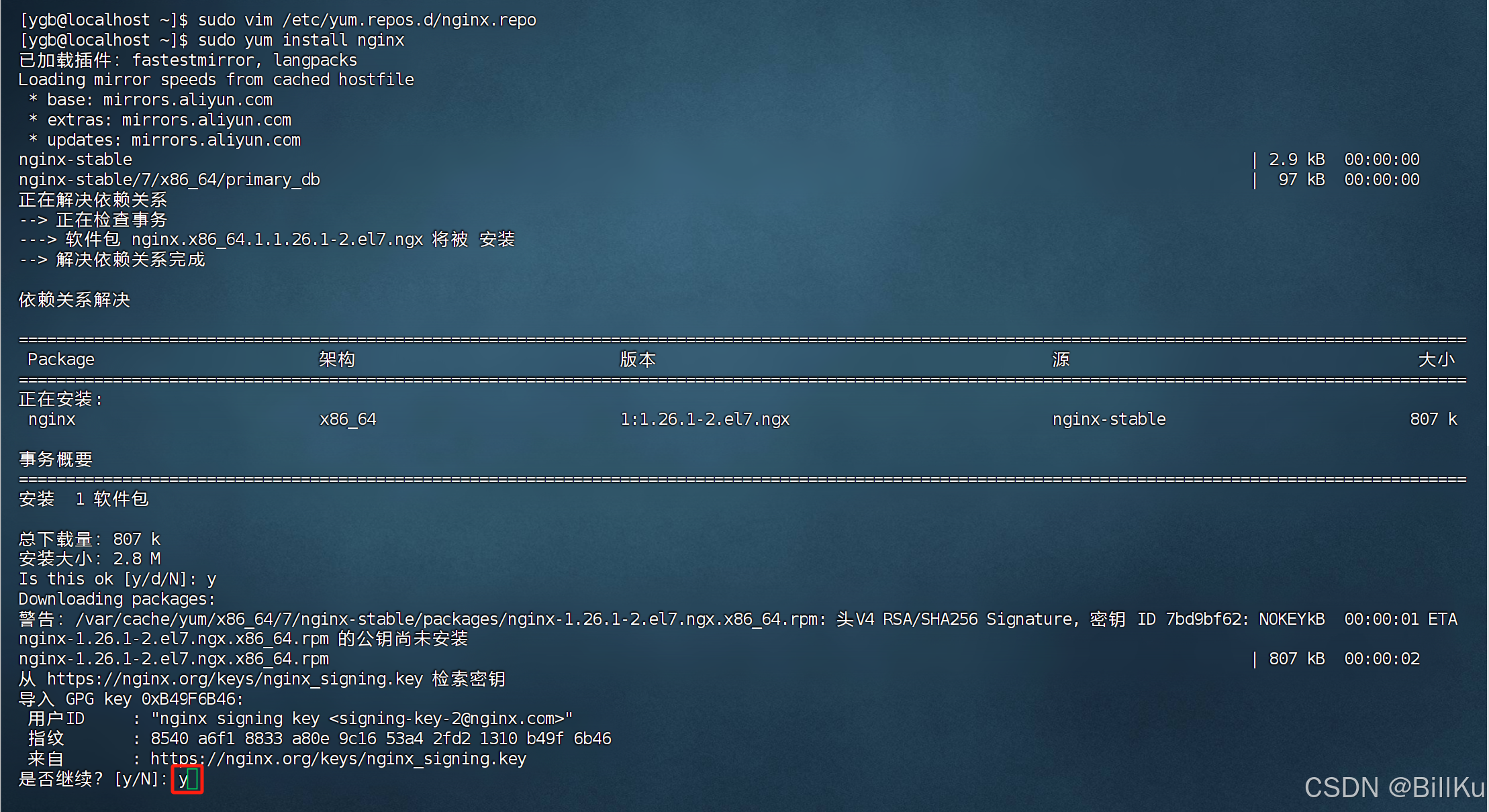
3、安装 Nginx
默认情况下,安装 Stable version当前稳定版本
【sudo yum-config-manager --enable nginx-mainline 不会设置,暂时不会安装指定版本】
sudo yum install nginx




查看 nginx 安装目录
whereis nginx

/usr/sbin 目录存放 nginx 启动程序
/etc/nginx 目录存放 nginx 配置文件
/usr/share/html 目录存放网站项目文件
4、开放端口 80
检查端口是否开放
sudo firewall-cmd --zone=public --query-port=80/tcp
开放端口
sudo firewall-cmd --zone=public --add-port=80/tcp --permanent
重新加载
sudo firewall-cmd --reload
再检查端口是否开放
sudo firewall-cmd --zone=public --query-port=80/tcp

5、启动 Nginx
sudo nginx

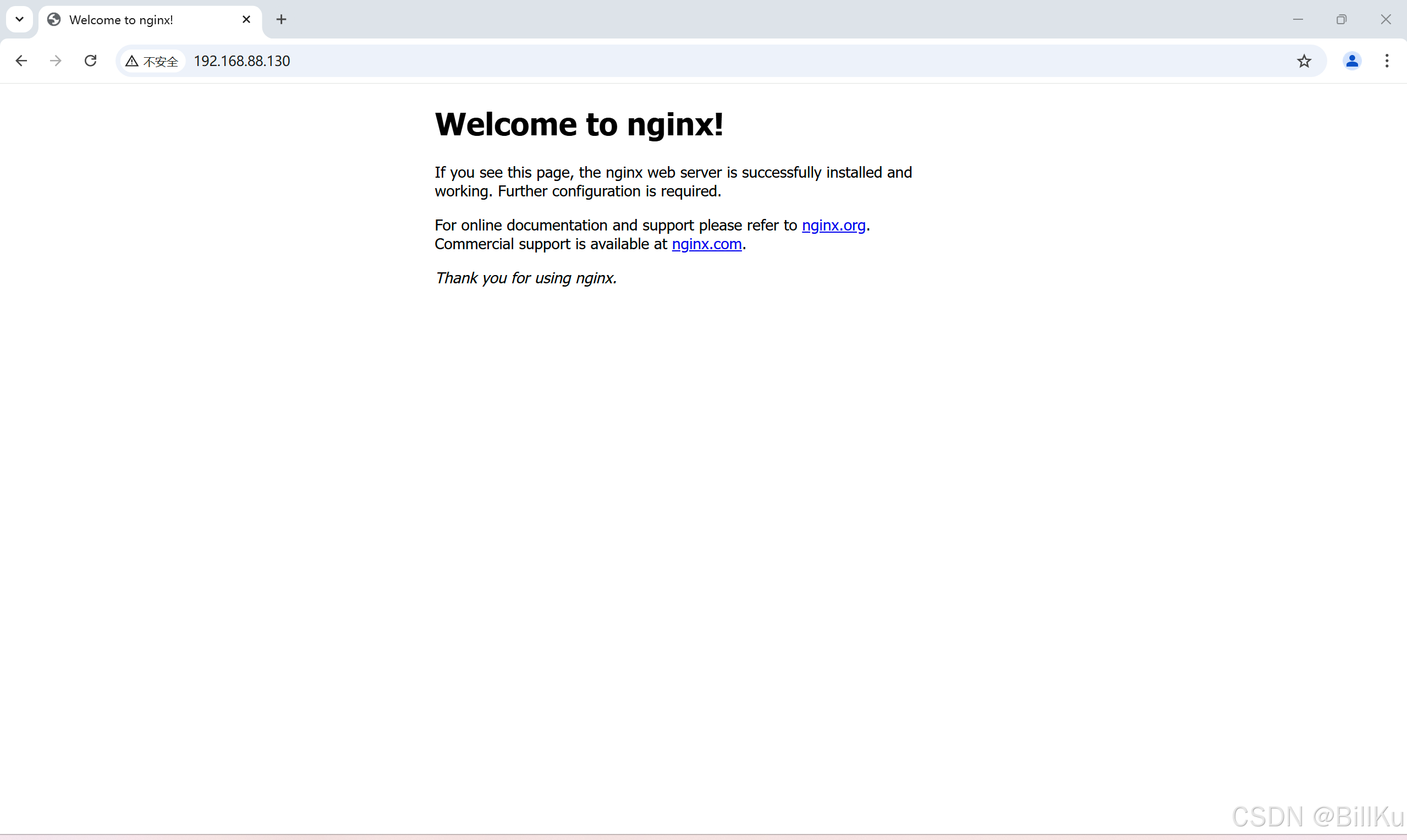
6、验证 Nginx
在远程终端,打开浏览器,输入ip,回车
二、通过编译源码包安装
需要 root 权限,使用 root 用户进行命令操作
编译源码包:.tar.gz 或 .tar 包文件
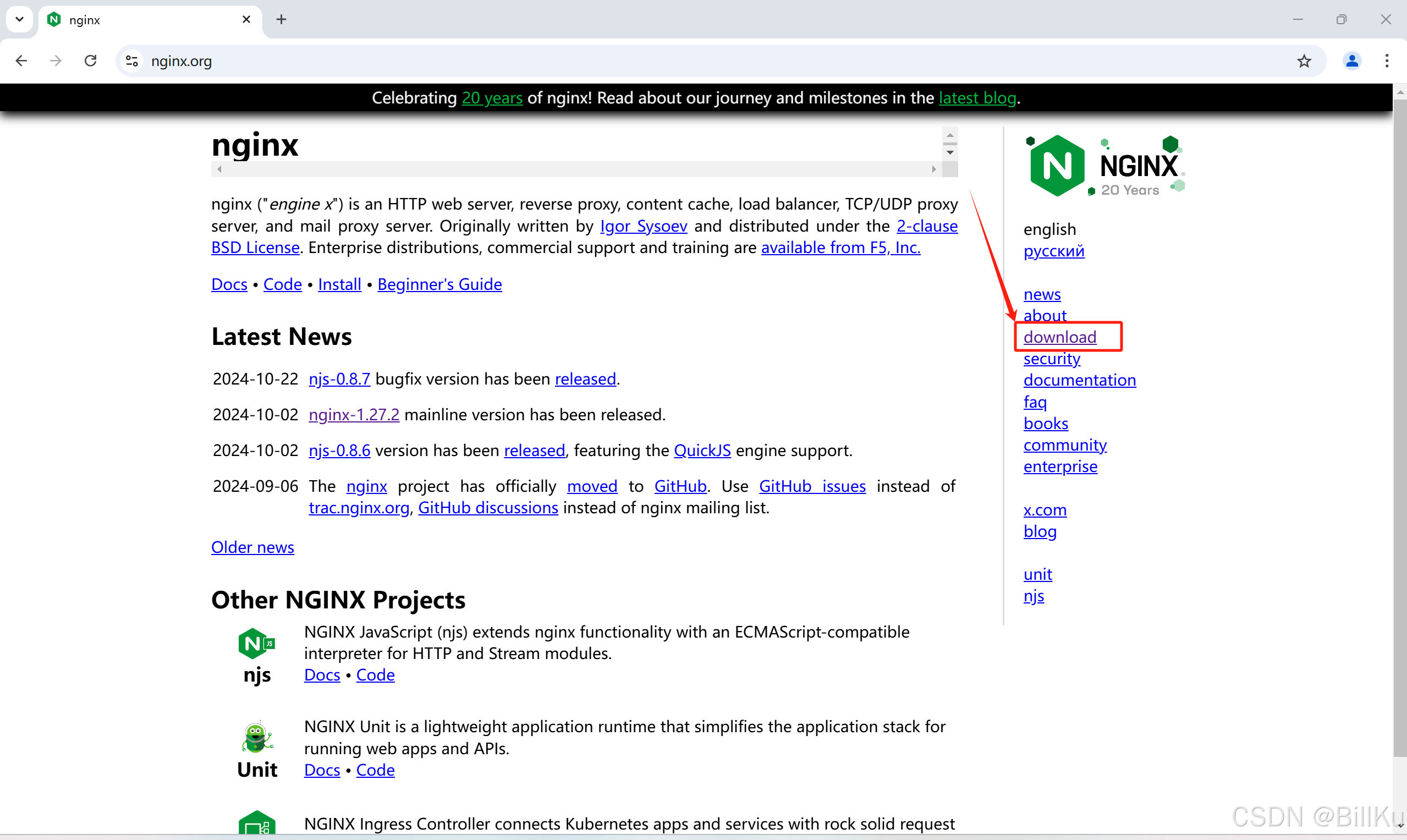
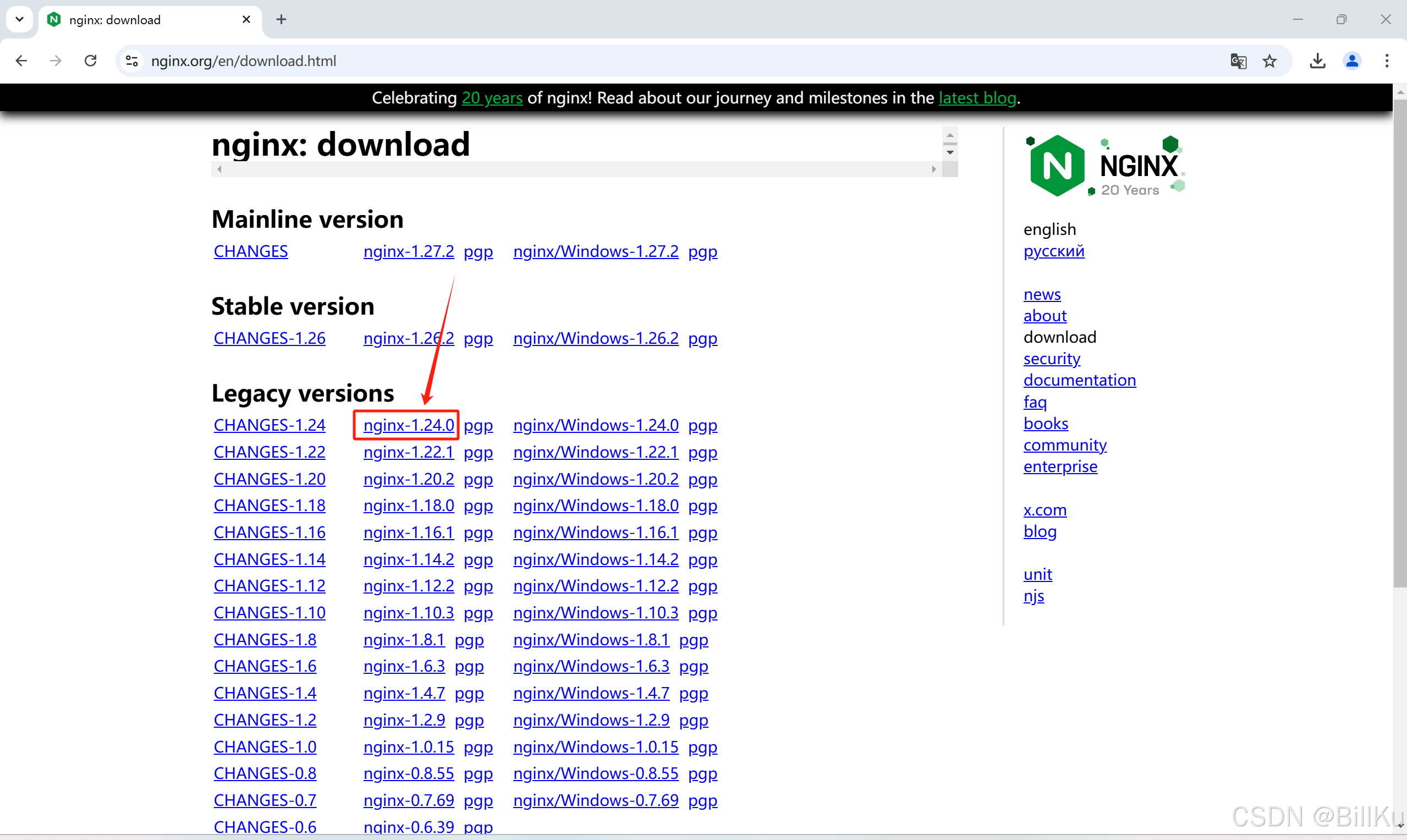
1、下载 Nginx
在远程终端计算机上,打开Nginx官网:https://nginx.org/,下载文件
2、上传 Nginx 文件到 CentOS
使用FinalShell远程登录工具,并且使用 root 用户连接登录(注意这里说的root用户连接登录是指这样的)
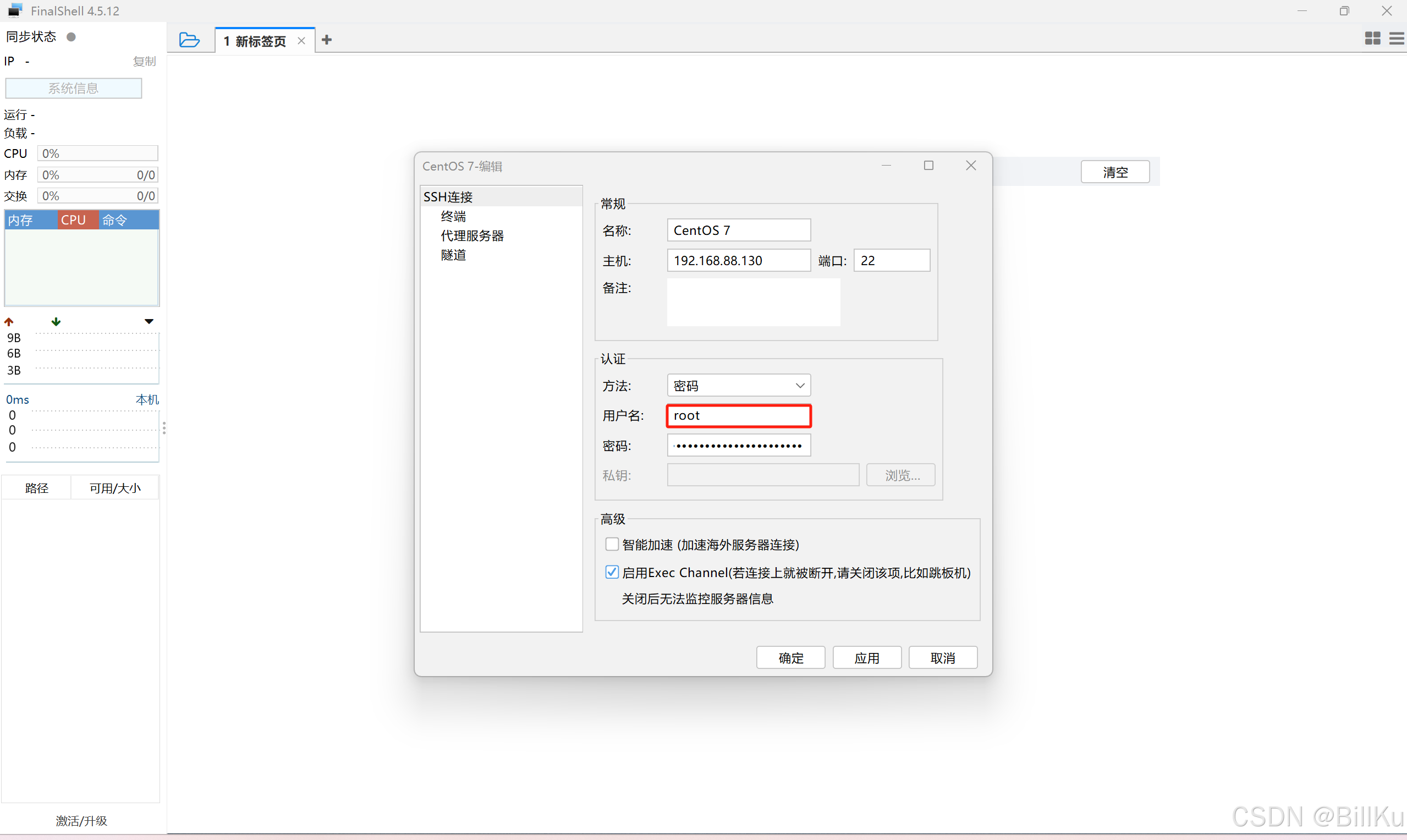


--------------------------------------------------------------------------------------------------------------------------------
也可以使用 wget 命令直接下载到 CentOS,前提需要安装好 wget
获取下载地址:https://nginx.org/download/nginx-1.26.2.tar.gz
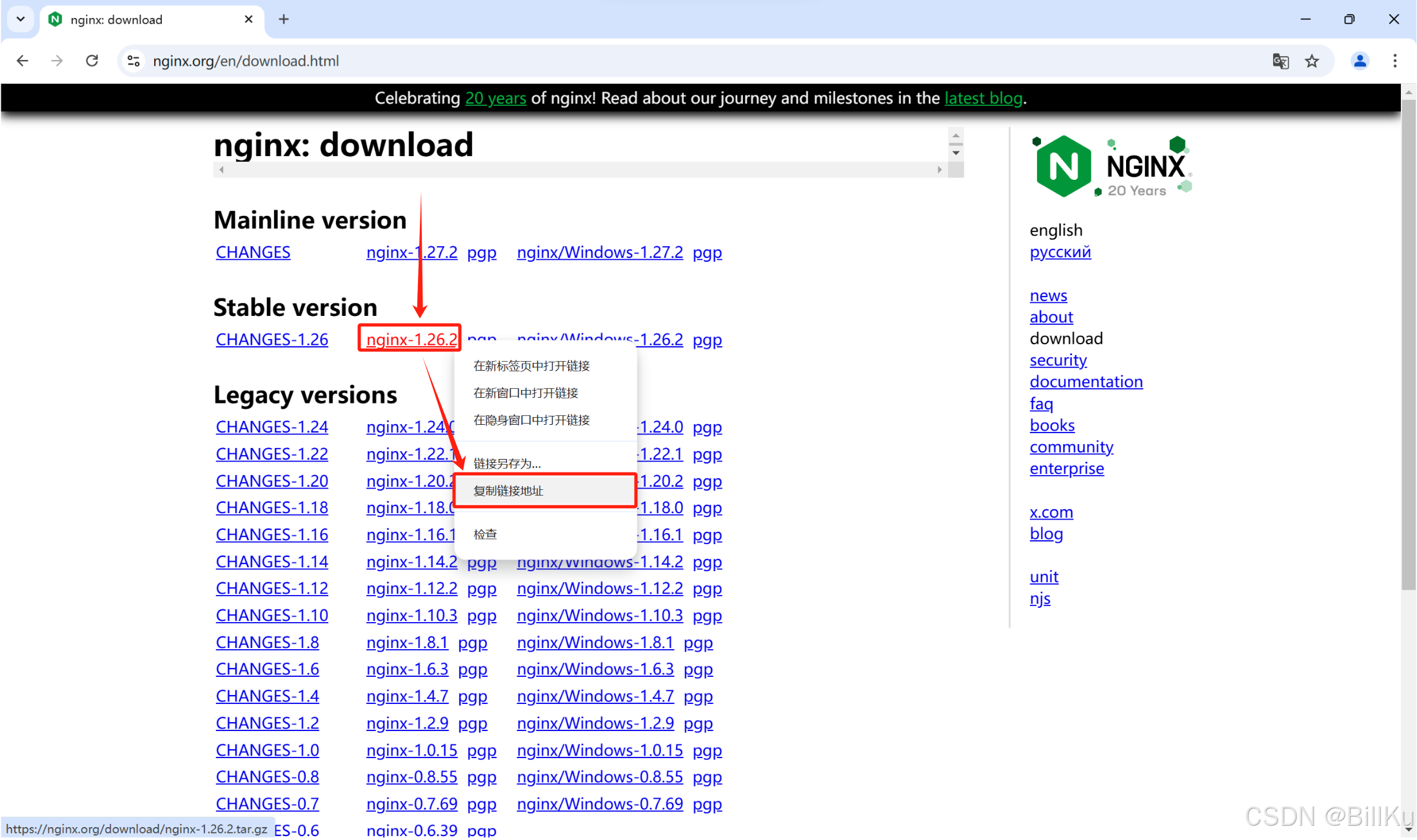
wget https://nginx.org/download/nginx-1.26.2.tar.gz


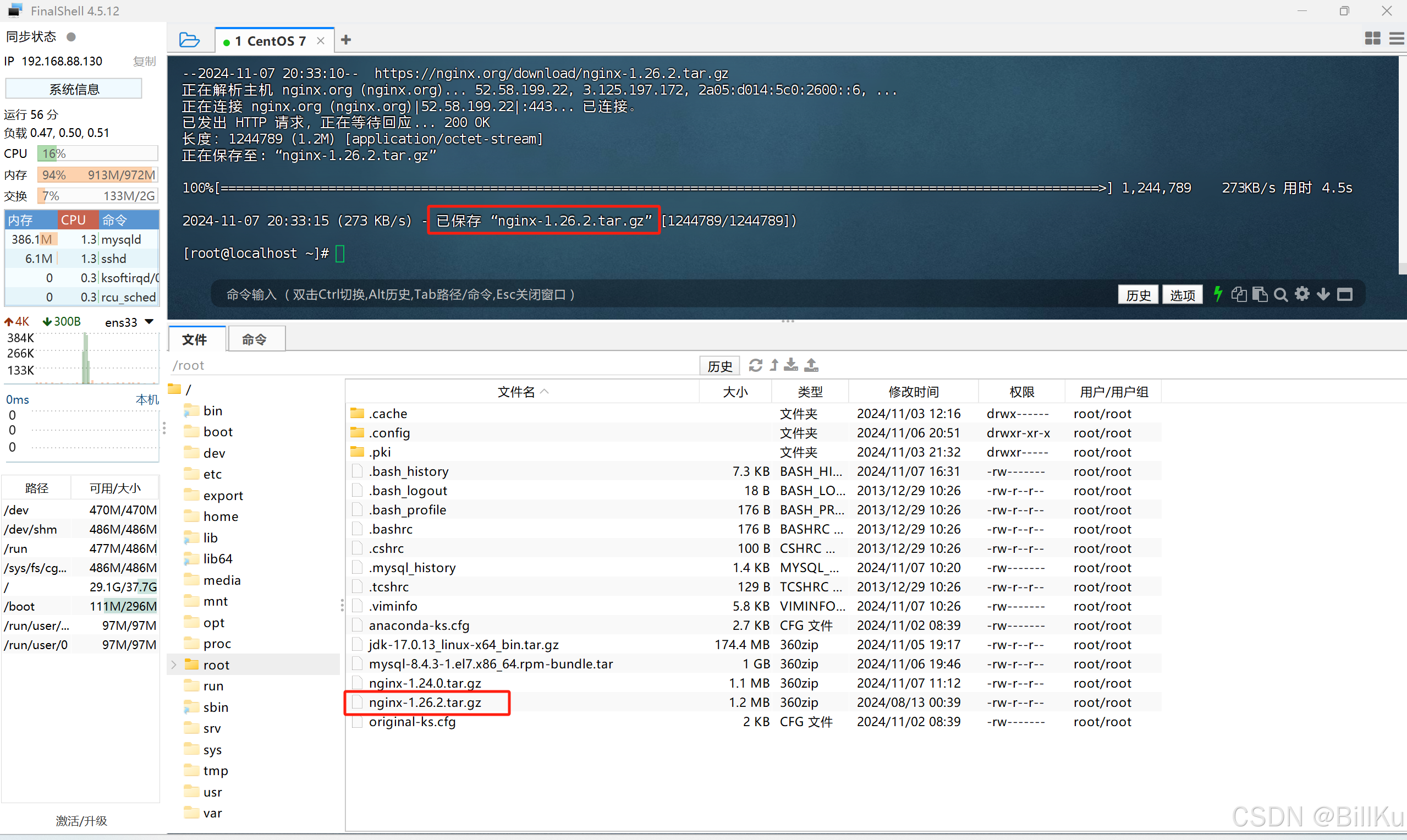
--------------------------------------------------------------------------------------------------------------------------------
3、解压 Nginx
创建目录/export/server
mkdir -p /export/server
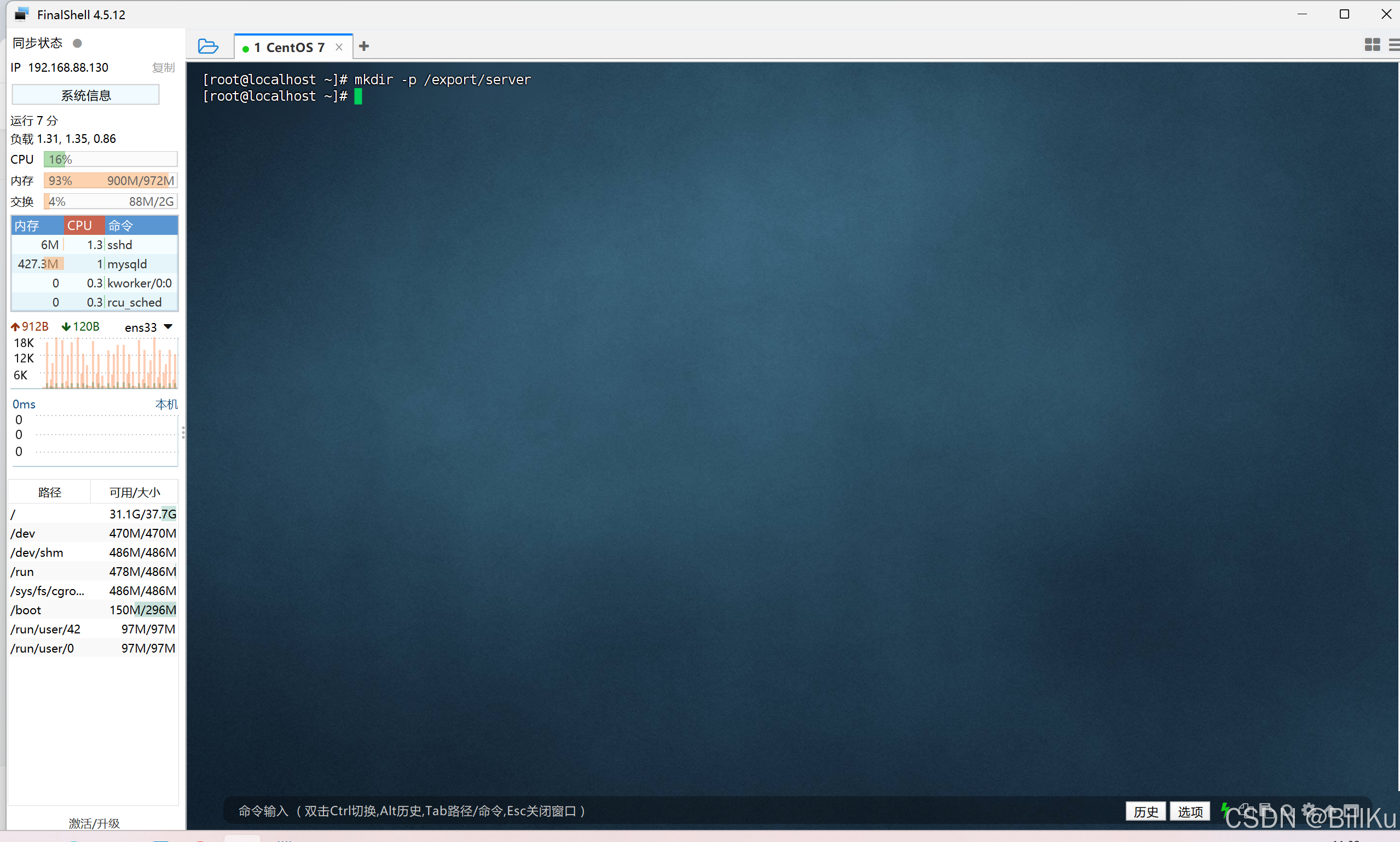
解压到目录/export/server
.tar.gz 格式的为打包压缩,使用 tar -zxvf,解压后是一个与文件名同名的目录。
.tar 格式的为打包不压缩,使用 tar -xvf,解压后是相关的文件,不是目录。
tar -zxvf nginx-1.24.0.tar.gz -C /export/server
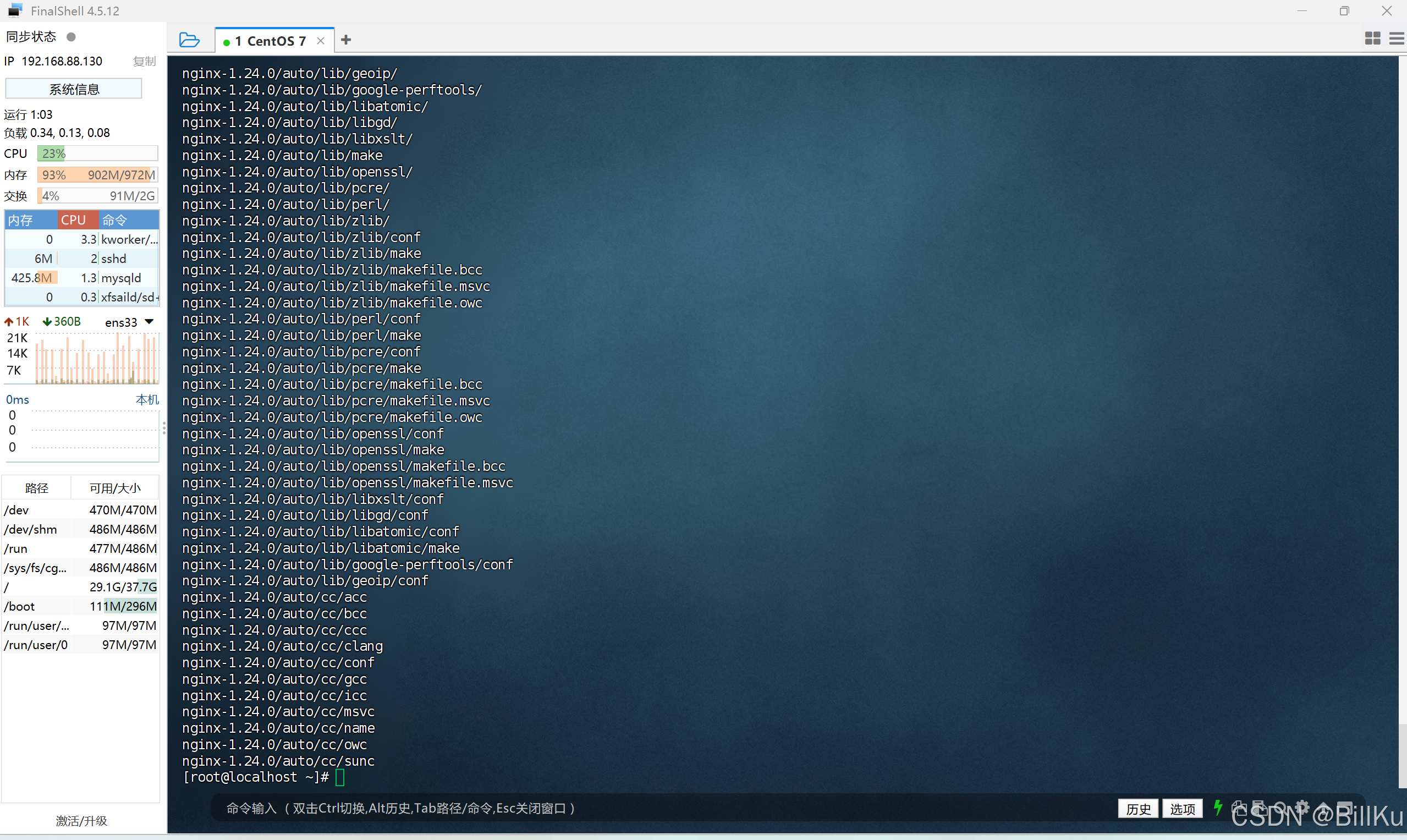
查看解压后情况
ls -l /export/server

4、安装编译环境和依赖
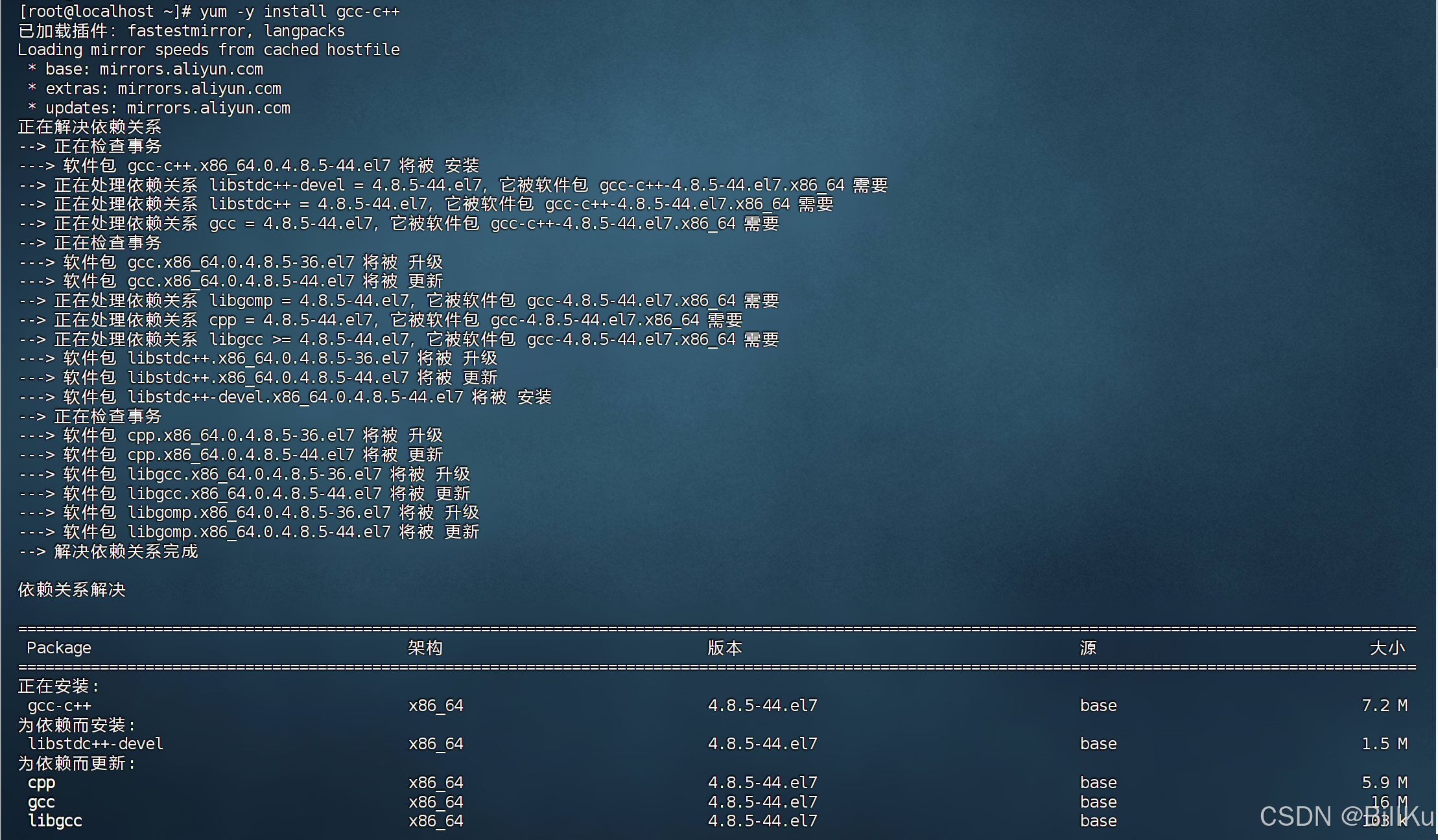
安装 gcc-c++ 编译器
因为 nginx 是使用C语言开发的,所以需要安装相关的编译环境来对其进行编译安装
yum -y install gcc-c++


yum install -y openssl openssl-devel





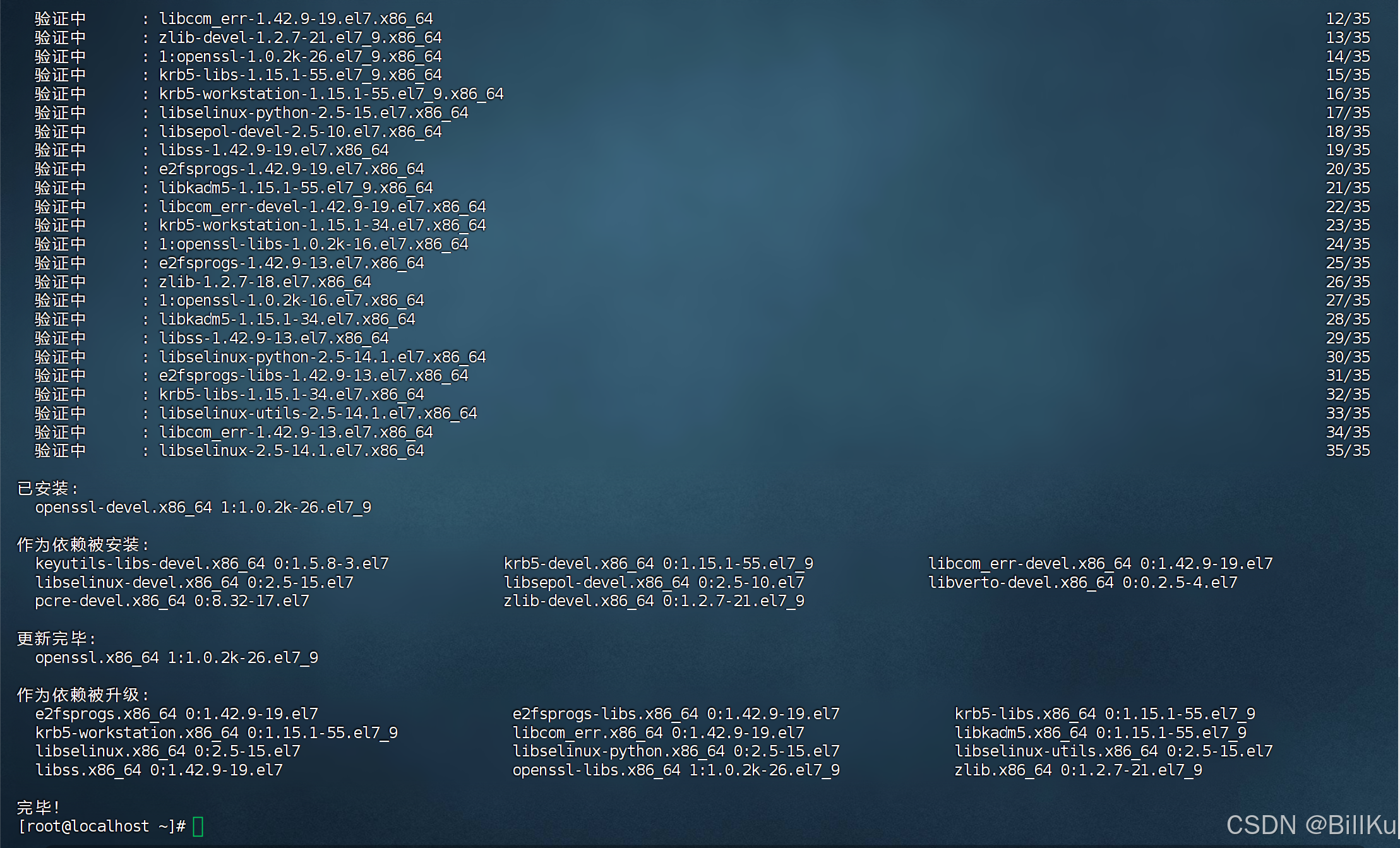
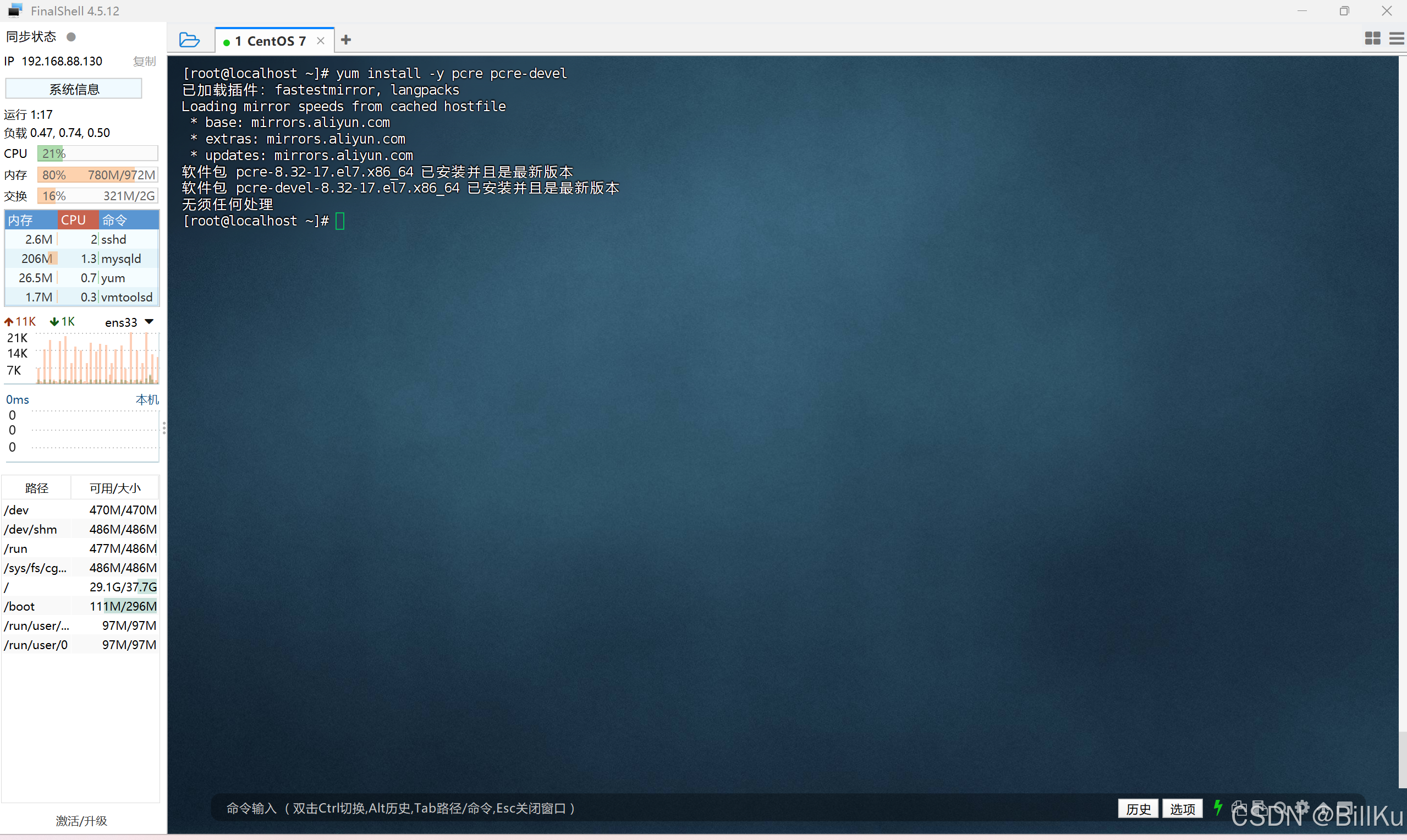
安装 pcre
PCRE(Perl Compatible Regular Expressions)是一个用C语言编写的正则表达式函数库,nginx 对其有依赖
yum install -y pcre pcre-devel
安装 zlib
zlib 是一个提供数据压缩的函数库,nginx 对其有依赖
yum install -y zlib zlib-devel
5、安装 Nginx
进入到解压后的 nginx 目录下/export/server/nginx-1.24.0
cd /export/server/nginx-1.24.0
查看目录内容
ls -l
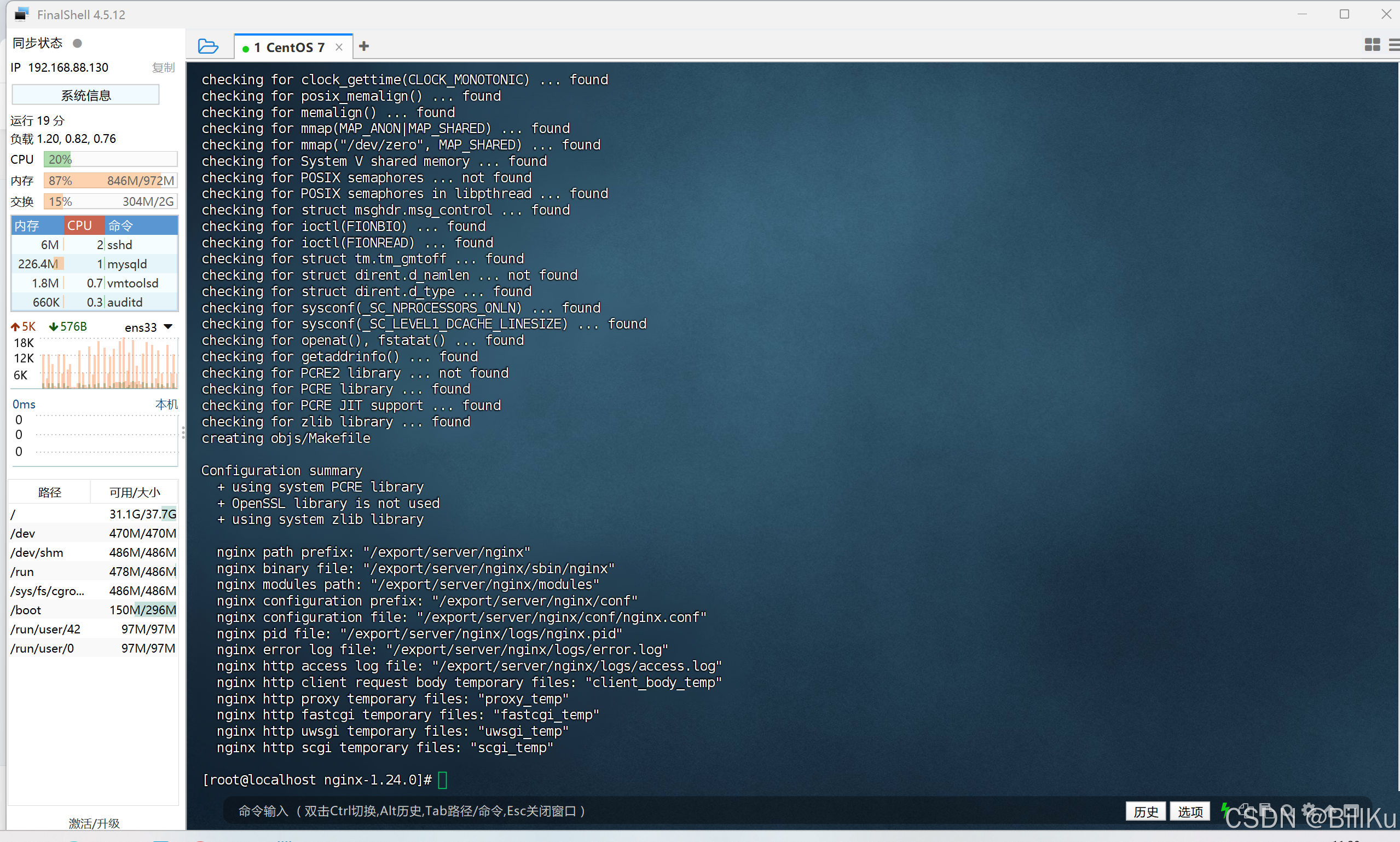
配置安装目录,将安装到/export/server/nginx 这个目录下
./configure --prefix=/export/server/nginx
执行 make 和 make install 命令进行编译安装
编译
make
安装
make install
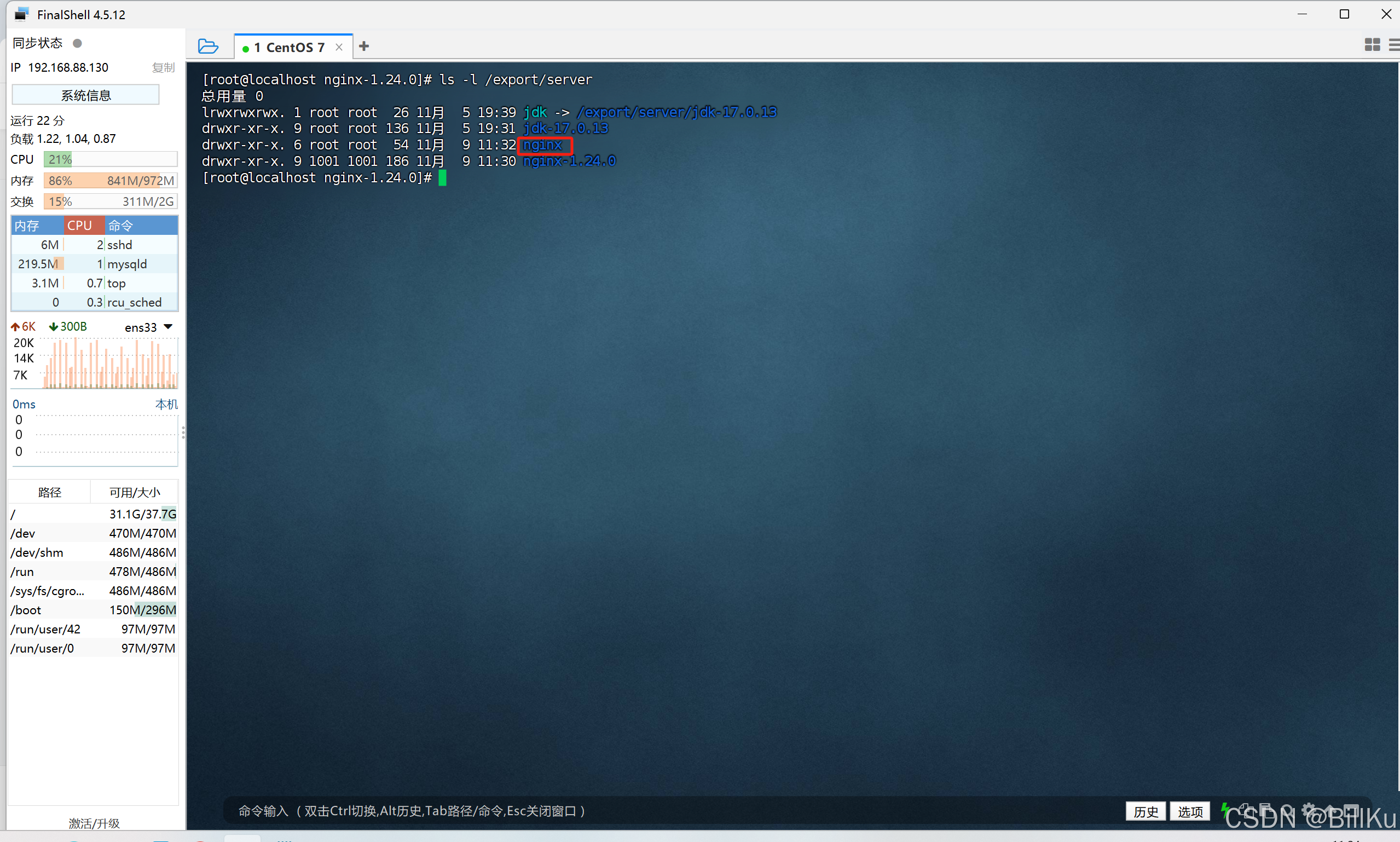
查看安装后的情况,目录/export/server 中多了 nginx 目录
ls -l /export/server
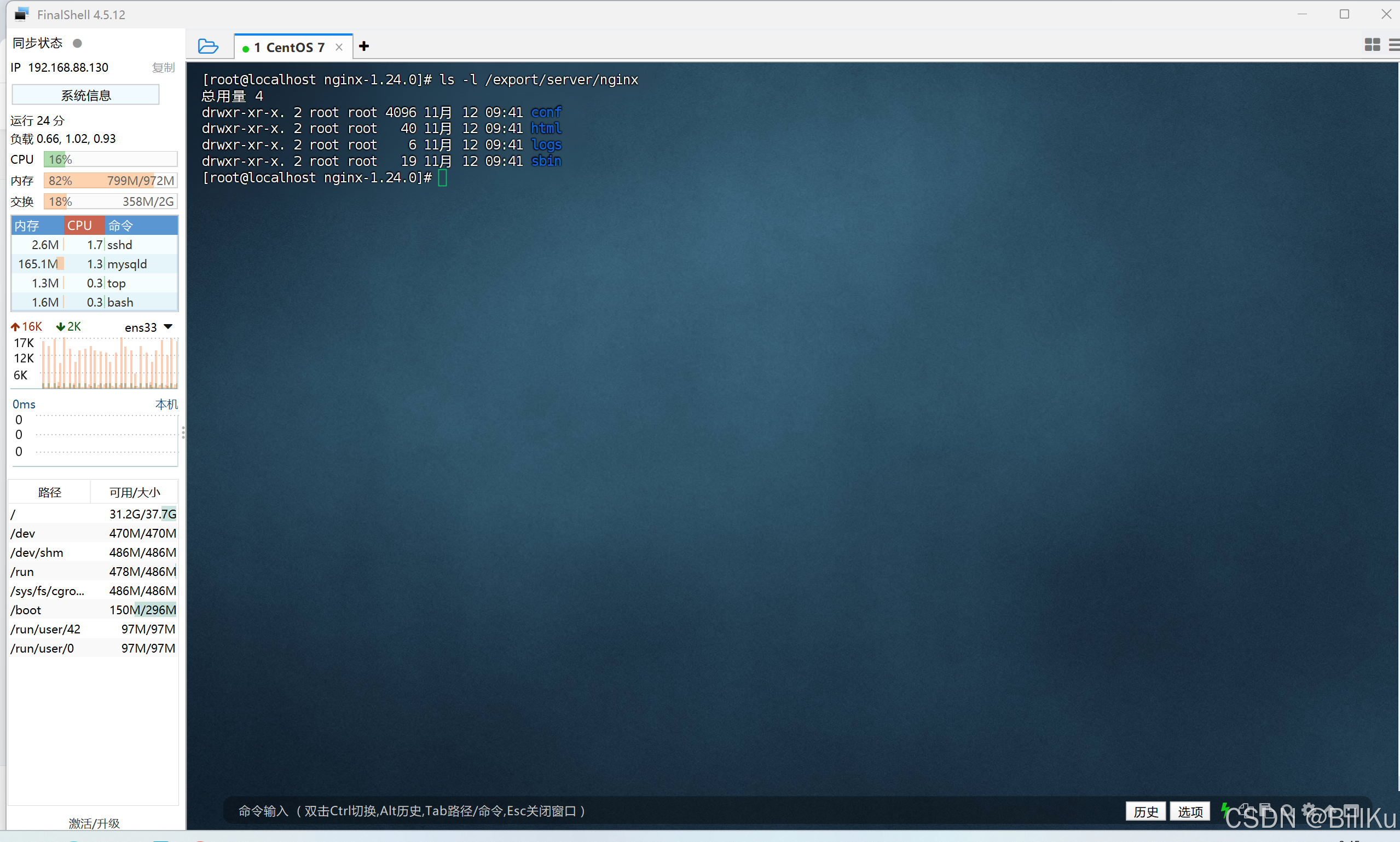
查看目录 /export/server/nginx 的内容
ls -l /export/server/nginx
6、开放端口 80
检查端口是否开放
firewall-cmd --zone=public --query-port=80/tcp
开放端口
firewall-cmd --zone=public --add-port=80/tcp --permanent
重新加载
firewall-cmd --reload
再检查端口是否开放
firewall-cmd --zone=public --query-port=80/tcp
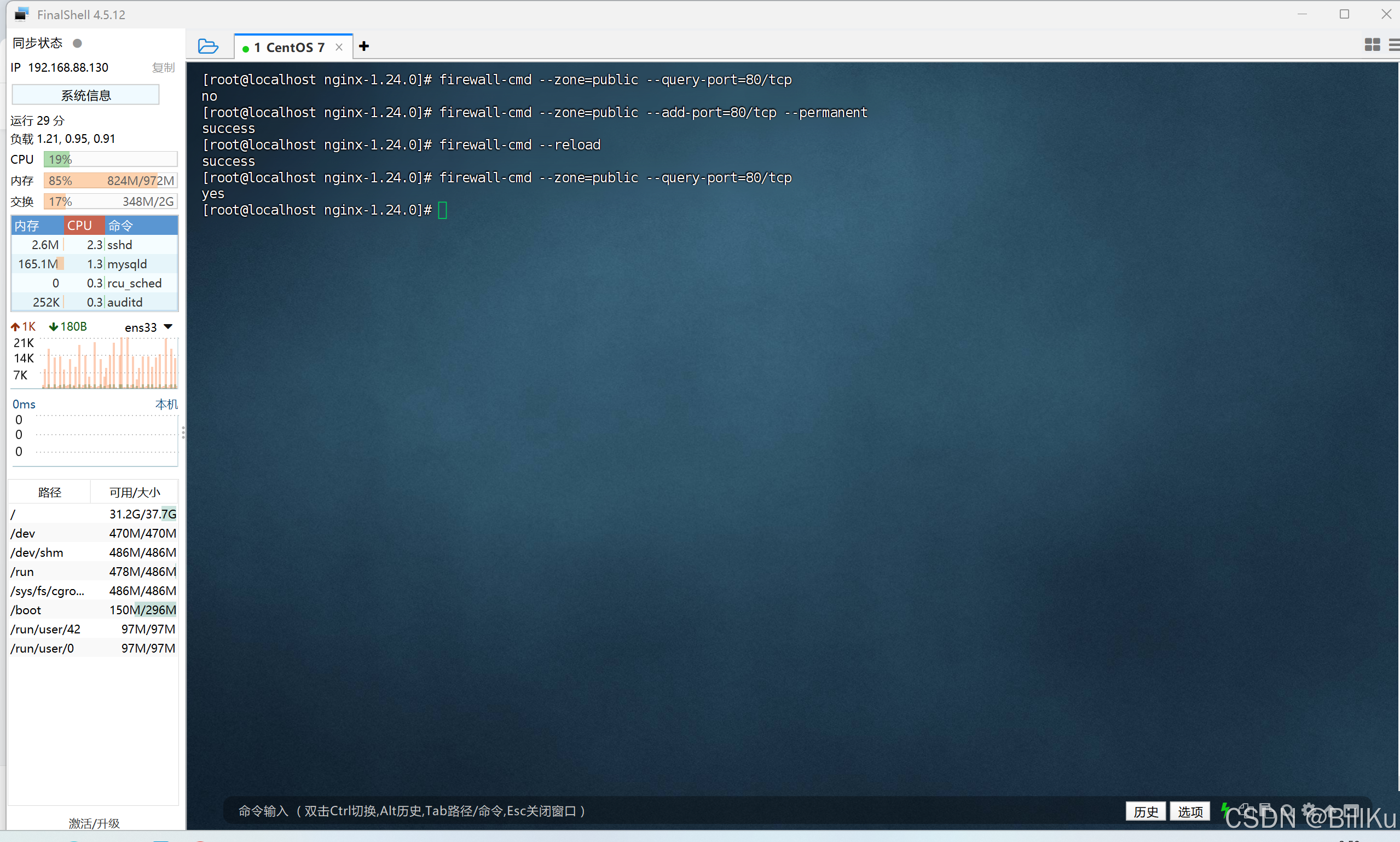
7、启动 Nginx
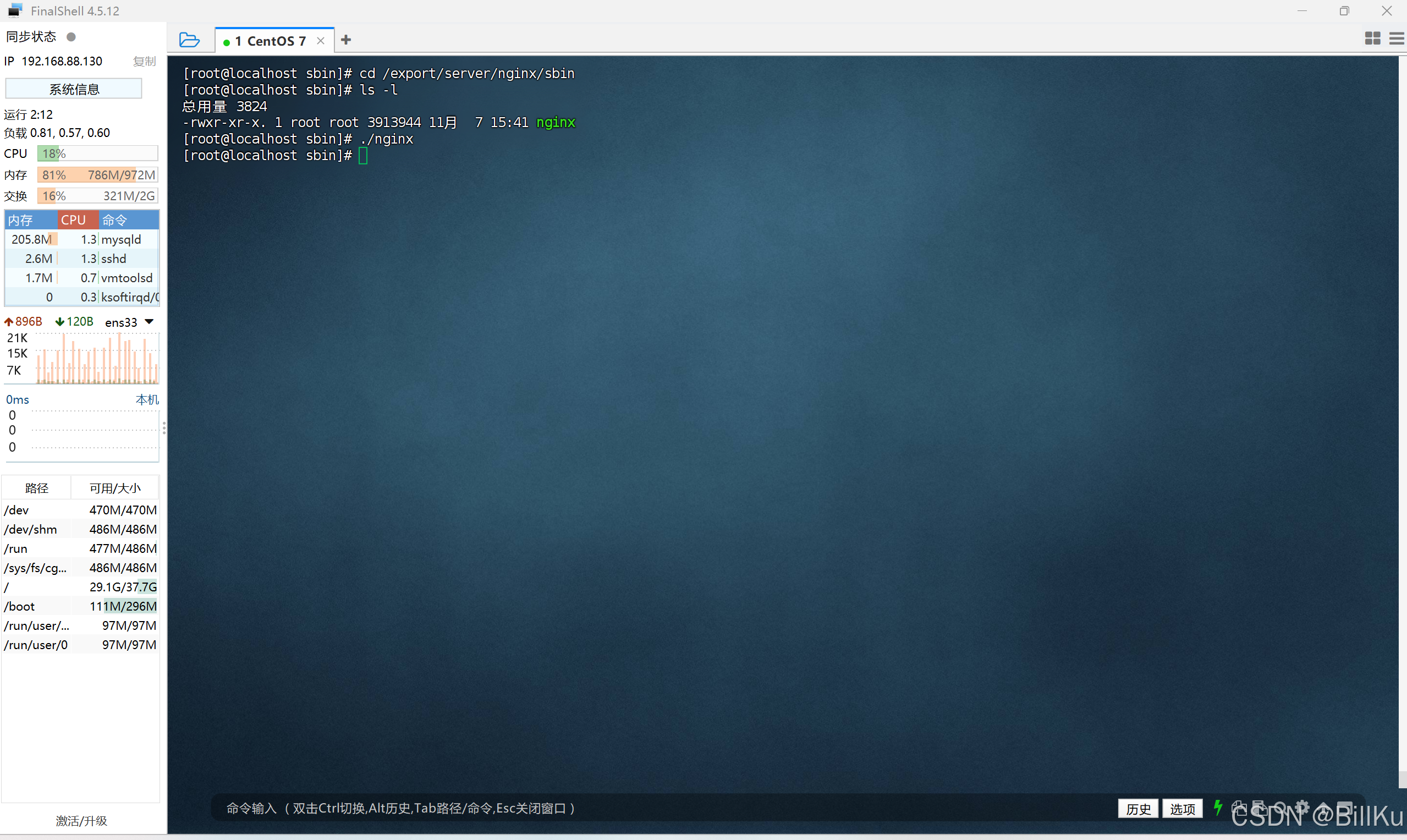
进入到 nginx 安装目录下的 sbin,即是目录 /export/server/nginx/sbin,查看目录内容
cd /export/server/nginx/sbinls -l

启动 nginx
./nginx
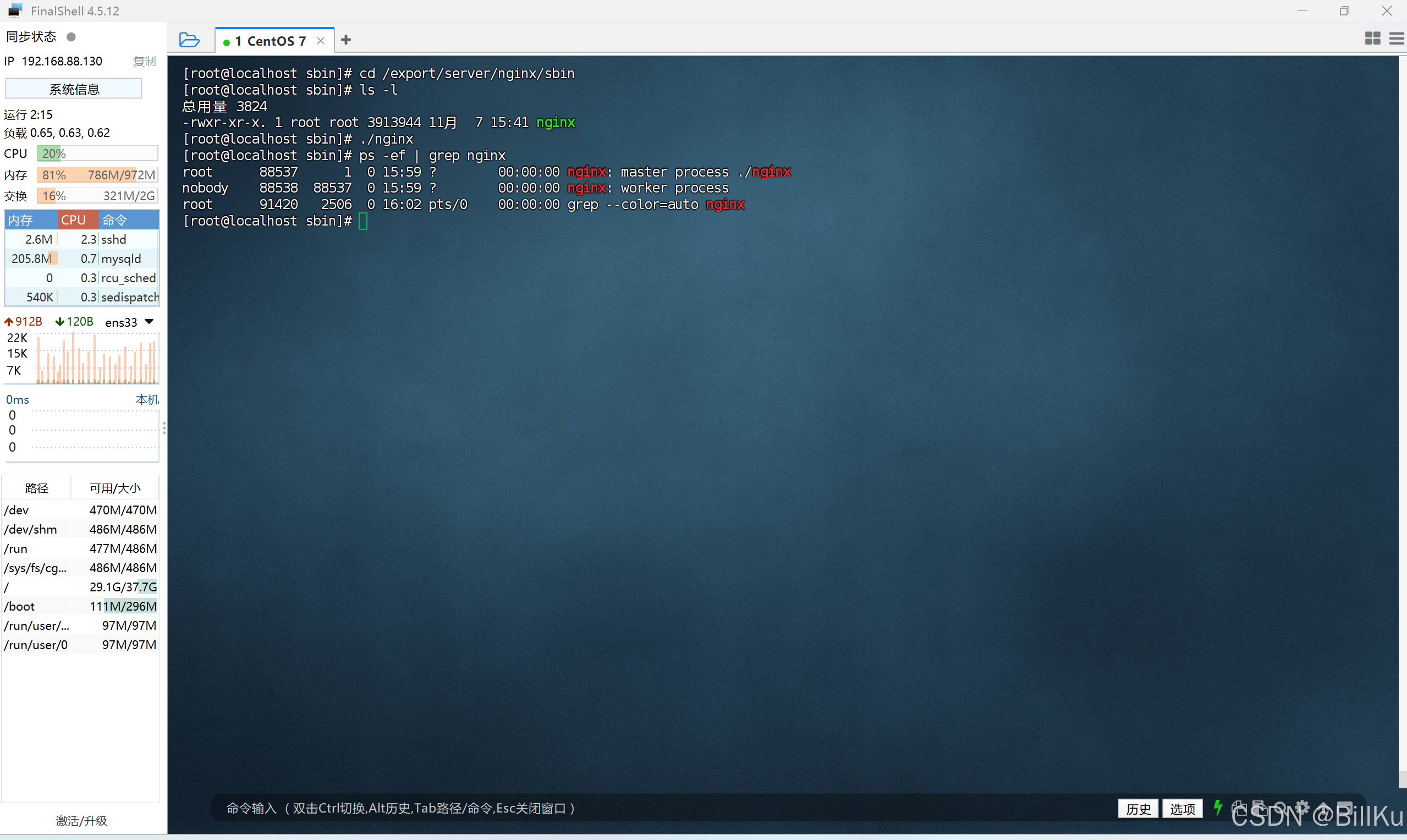
查看 nginx 相关的进程
ps -ef | grep nginx
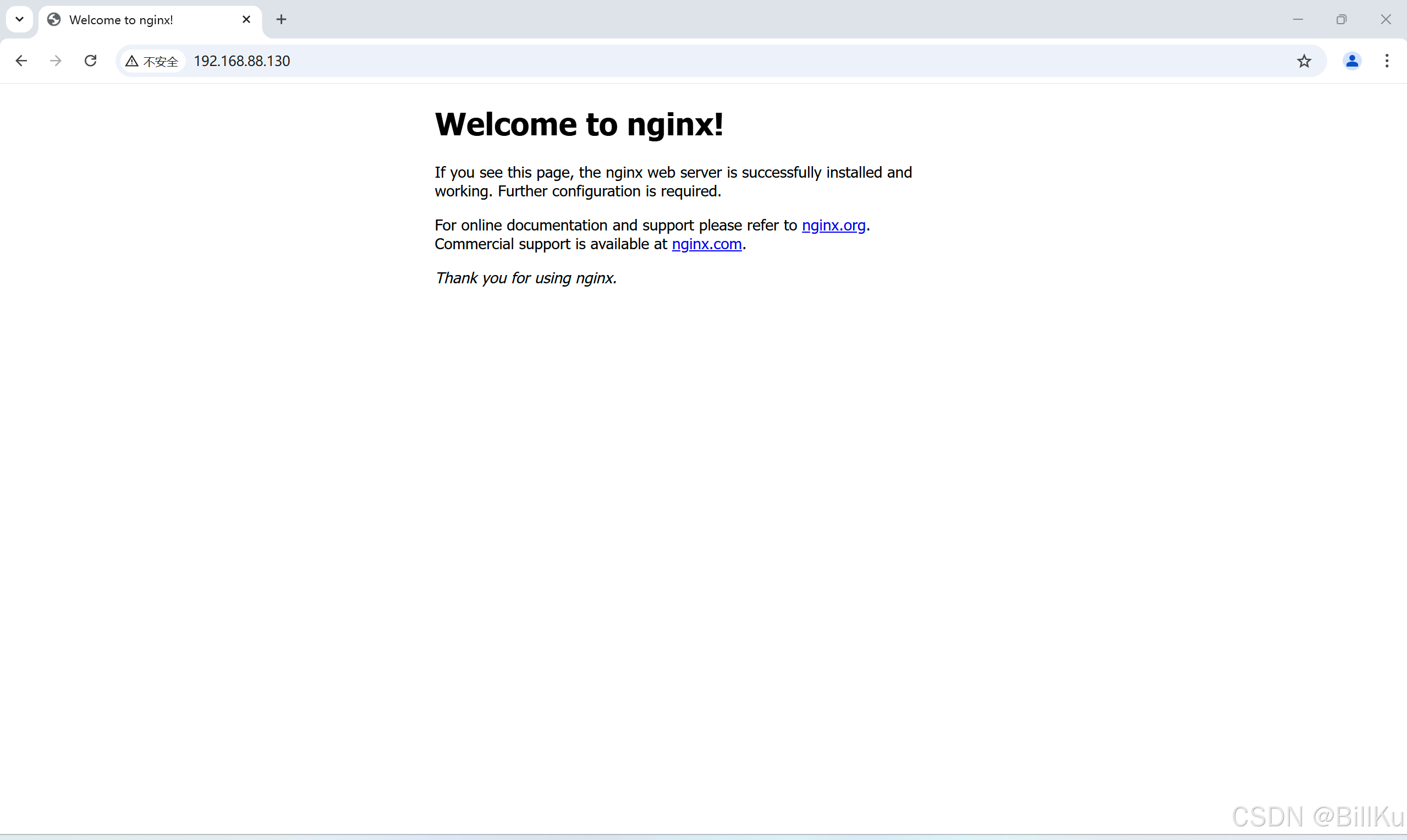
8、验证 Nginx
在其他终端,打开浏览器,输入ip,回车
9、删除编译源码包和安装解压目录
删除编译源码包 nginx-1.24.0.tar.gz
rm /root/nginx-1.24.0.tar.gz
删除安装解压目录 /export/server/nginx-1.24.0
rm -rf /export/server/nginx-1.24.0
附+:设置 Nginx 服务开机启动
需要 root 权限,使用 root 用户进行命令操作
原理:利用 systemctl 管理服务
1、新建服务
在/usr/lib/systemd/system 目录下,新建 nginx.service 文件,配置内容
vim /usr/lib/systemd/system/nginx.service
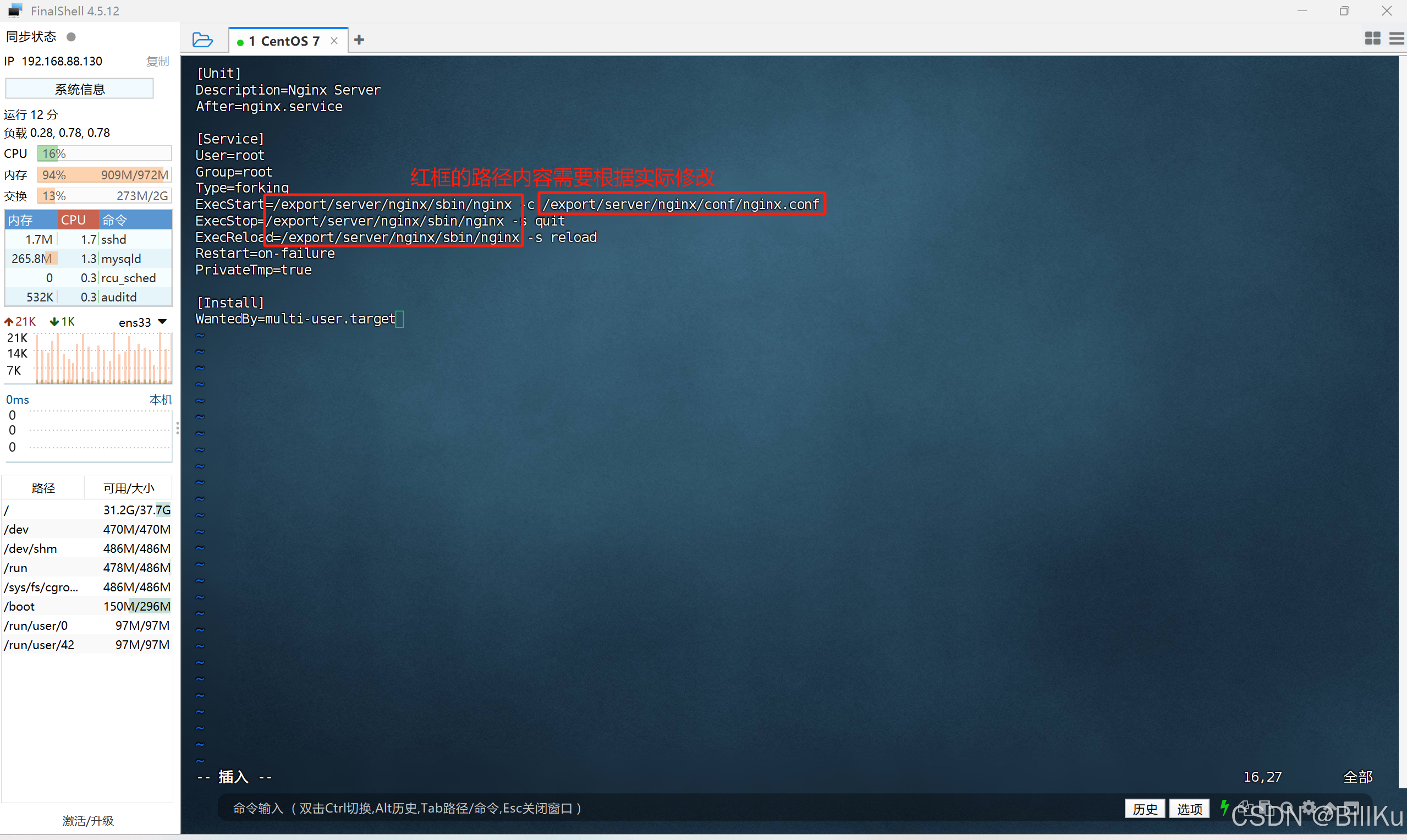
配置内容如下:
[Unit]
Description=Nginx Server
After=nginx.service[Service]
User=root
Group=root
Type=forking
ExecStart=/export/server/nginx/sbin/nginx -c /export/server/nginx/conf/nginx.conf
ExecStop=/export/server/nginx/sbin/nginx -s quit
ExecReload=/export/server/nginx/sbin/nginx -s reload
Restart=on-failure
PrivateTmp=true[Install]
WantedBy=multi-user.target
2、重新加载systemctl
systemctl daemon-reload
3、启动Nginx
systemctl start nginx.service;ps -ef | grep nginx
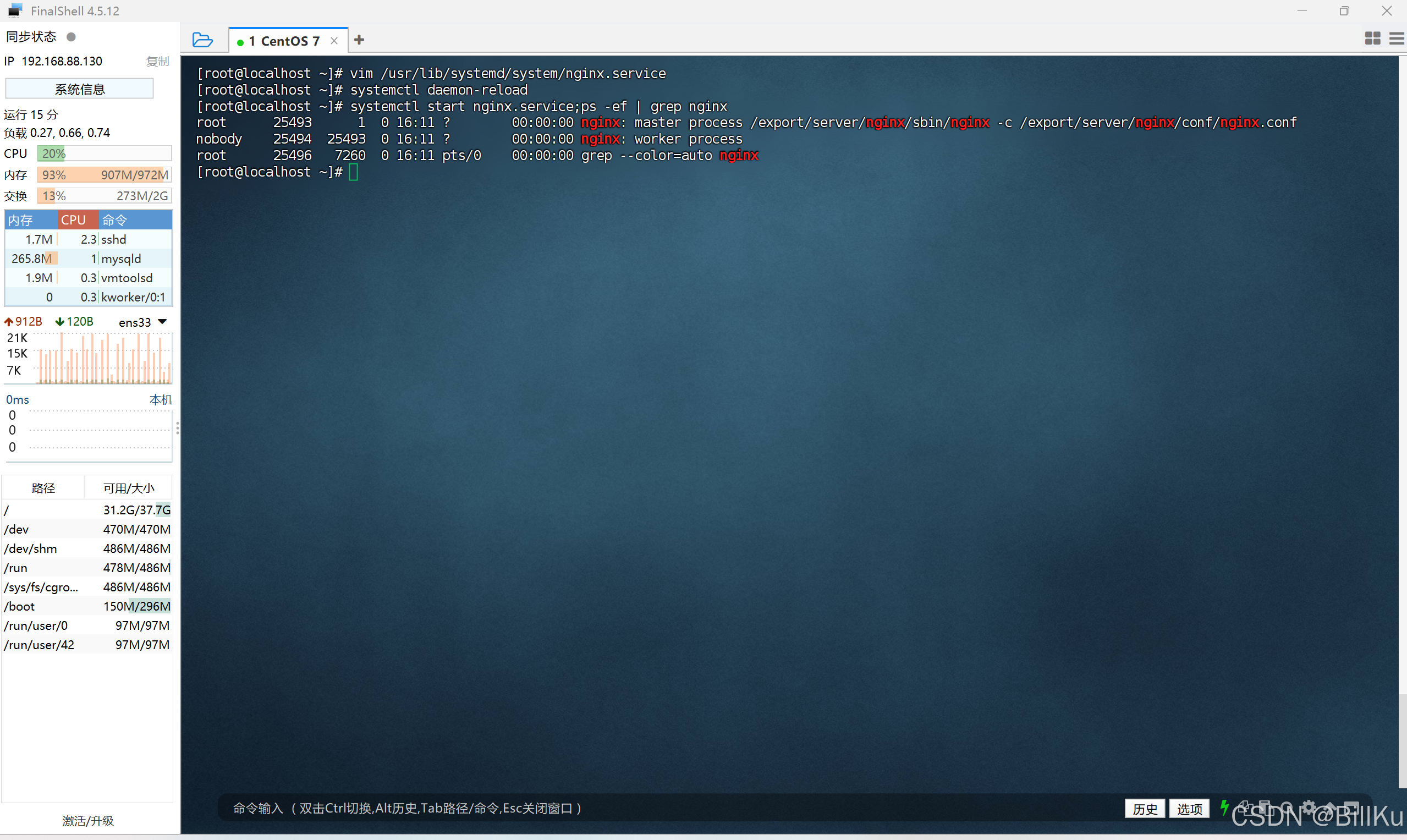
4、设置 Nginx 开机启动
设置开机启动
systemctl enable nginx.service
查看设置情况
systemctl is-enabled nginx
5、重启计算机
reboot
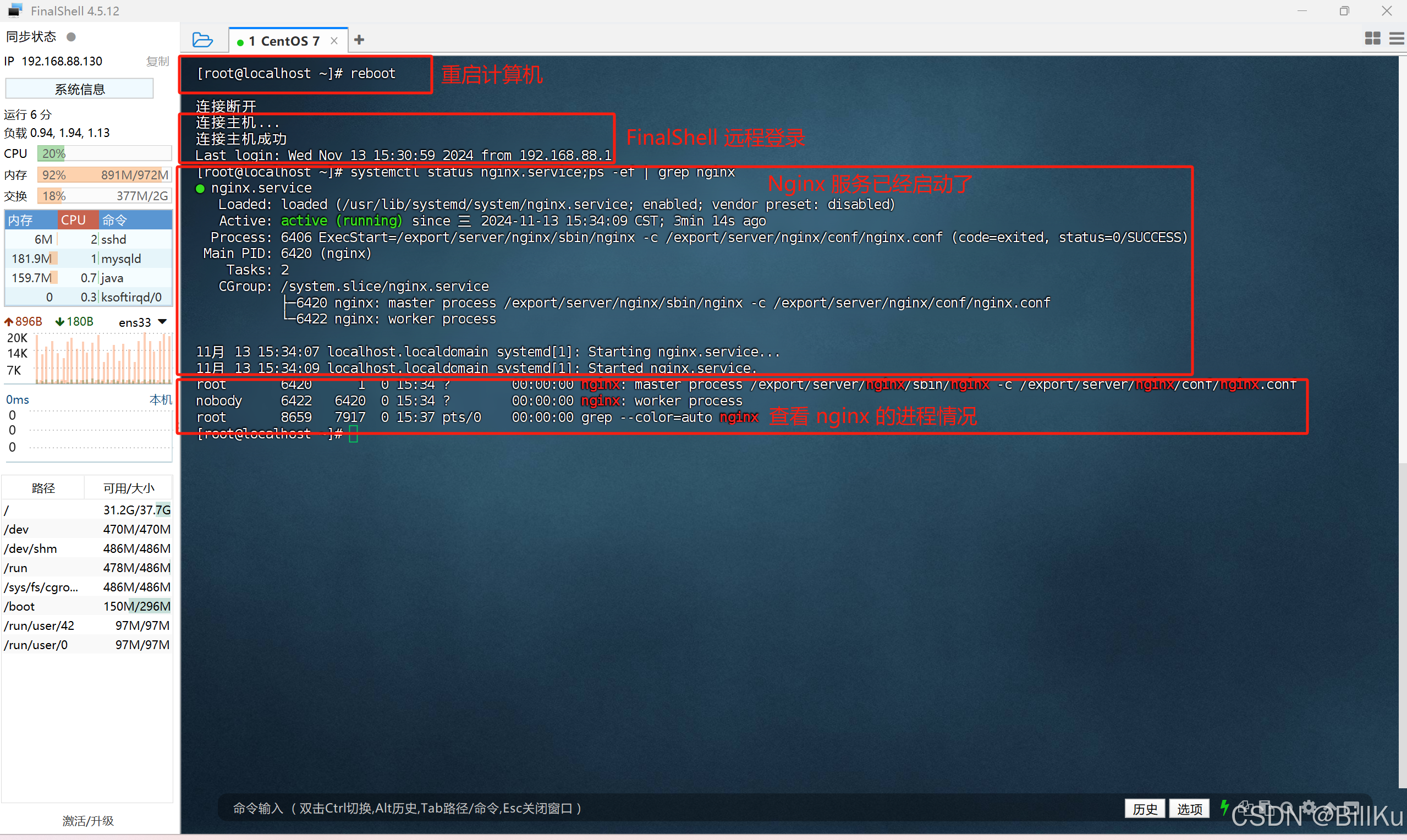
6、验证Nginx 开机启动
systemctl status nginx.service;ps -ef | grep nginx
附+:Nginx 的其他命令
1、取消 Nginx 开机启动
systemctl disable nginx.service
2、重启 Nginx
当前 Nginx 运行或停止状态都可以 restart
systemctl restart nginx.service
只能在当前 Nginx 运行状态 reload
systemctl reload nginx.service
3、停止 Nginx
systemctl stop nginx.service



















