一、可变参数模板
1.基本概念
想要了解C语言的可变参数列表的原理可见:可变参数列表
这个跟C语言的可变参数列表有一定的关系,常用的printf与scanf的参数就包含可变参数列表。
那么可变参数模板是什么呢?举个例子便一目了然。
template<class...Arg>
void ShowList(Arg... arg)
{//...
}
int main()
{ShowList();ShowList(1, 2, 3);ShowList('a', 'b', 'c');return 0;
}
这就是可变参数模板,可以传多个参数,这里的Arg称为模板的可变参数包,这里的arg称为形参的可变参数包(包括0-N个参数)。
但是这里有一个问题即如何用这个参数包呢?
- 递归展开
void _ShowList()
{cout<< endl;
}template<class T,class...Arg>
void _ShowList(T val, Arg... arg)
{cout << val << " ";_ShowList(arg...);
}template<class...Arg>
void ShowList( Arg... arg)
{_ShowList(arg...);
}
int main()
{ShowList();ShowList(1, 2, 3);ShowList('a', 'b', 'c');return 0;
}
- 编译器以类似递归的方式(调用的不是同一个函数,是来自一个模板实例化出的函数)自动推导出参数包的类型然后进行打印。
运行结果:

- 逗号表达式
template<class T>
int PrintArg(T val)
{cout << val << " ";return 0;
}void ShowList()
{cout << endl;
}template<class... Arg>
void ShowList(Arg... arg)
{int arr[] = { PrintArg(arg)... };//处理成类似与int arr[] = { PrintArg(arg), PrintArg(arg),PrintArg(arg)};这样的形式。//这是编译链接阶段处理的结果。cout << endl;
}int main()
{ShowList();ShowList(1, 2, 3);ShowList('a', 'b', 'c');return 0;
}
运行结果:

2.应用场景
1.提升传参的灵活性
例:
class Date
{
public:Date(int year = 0, int month = 0, int day = 0):_year(year),_month(month),_day(day){}
public:int _year;int _month;int _day;
};template<class ...Args>
Date* CreatDate(Args... args)
{Date* ret = new Date(args...);return ret;
}int main()
{Date* date1 = CreatDate(1);Date* date2 = CreatDate(1,2);Date* date3 = CreatDate(1,2,3);Date* date4 = CreatDate(Date(1,2,3));return 0;
}- 不仅可以调用构造函数,也可调用默认的拷贝构造函数,进而提高了灵活性。
2.接口——emplace_back
参数:

- 说明:这里在可变参数模板的基础上添加了万能引用。
int main()
{list<pair<int, MY_STL::string>>lt;//先调用pair的构造函数再调用右值的移动拷贝构造。lt.push_back(make_pair(1, "张三"));cout << endl;lt.push_back({ 2, "李四" });cout << endl << endl;//作为参数包(引用)传递下去,直接调用list的构造函数进行构造lt.emplace_back(3, "王五");cout << endl;lt.emplace_back(make_pair(4, "赵六"));//这里编译器进行了优化,也是直接调用构造函数进行初始化。return 0;
}
-
可见push_back虽然多调用了两次构造但好在是移动构造消耗不大,emplace_back直接将参数包传下去,直接调用构造函数进行初始化,总而言之与push_back有区别但性能上相差不大。
-
举例 : list的emplace_back
//list里面的实现接口template <class... Args>void push_back(Args&&... args){insert(end(), args...);}template <class... Args>void emplace_back(Args&&... args){push_back(args...);}template <class... Args>void insert(iterator pos, Args&&... args){Node* newnode = new Node(args...);Node* cur = pos._node;Node* prev = cur->_prev;newnode->_next = cur;newnode->_prev = prev;cur->_prev = newnode;prev->_next = newnode;_size++;}
//Node的实现接口template<class ...Args>list_node(Args&& ...arg):_val(arg...), _next(nullptr), _prev(nullptr){}
//实现逻辑——不断传参数包,将参数包传给构造函数进行初始化。
二、包装器
1. 简单实现
如何用外界控制某段执行逻辑?
- C语言阶段我们可以通过传函数指针
- C++阶段我们可以通过传仿函数或者lambda(底层是仿函数)
这三者有没有什么共同的特性呢?就是可以像函数一样进行使用。如果实现的功能一样那么参数和返回值是一样的。
根据这两个性质,我们可以将这三者抽象成一个模板,以实现减法举例:
template<class T1,class T2,class T3>
double fun(T1 f, const T2& x, const T3& y)
{return f(x, y);
}
double sub(int x, int y)
{return x - y;
}
struct Sub
{double operator()(int x, int y){return x - y;}
};
int main()
{auto x = [](int x, int y)->double {return x - y;};//lambda表达式。cout << fun(x, 1, 2) << endl;cout << fun(sub, 4, 2) << endl;Sub s;cout << fun(s, 9, 2) << endl;return 0;
}
这样的一个模板就将这三者进行泛化,都可以通过模板实例化使用,也就是实现了包装的作用,当然这只是最简单的用法,下面我们就进入库里面的包装器的使用。
2. 基本语法与使用

重点:class function<Ret()Args...>;
1. Ret 返回值
2. Args... 函数参数
简单使用:
double sub(int x, int y)
{return x - y;
}
struct Sub
{double operator()(int x, int y){return x - y;}
};
int main()
{auto x = [](int x, int y)->double {return x - y;};function<double(int, int)> f1 = x;function<double(int, int)> f2 = s;function<double(int, int)> f3 = sub;cout << f1(2 , 3) << endl;cout << f2(2, 9) << endl;cout << f3(9, 9) << endl;return 0;
}
更为实际的使用:
比如:逆波兰表达式的求值
class Solution {
public:int evalRPN(vector<string>& tokens) {map<string,function<int(int,int)>> s = {{"+",[](int x,int y){return x + y;}},{"-",[](int x,int y){return x - y;}},{"*",[](int x,int y){return x * y;}},{"/",[](int x,int y){return x / y;}}};stack<int> st;int size = tokens.size();for(int i = 0; i < size; i++){if(tokens[i] == "+" || tokens[i] == "-"|| tokens[i] == "*" || tokens[i] == "/"){int right = st.top();st.pop();int left = st.top();st.pop(); st.push(s[tokens[i]](left,right));}else{st.push(stoi(tokens[i]));}}return st.top();}
};
仔细品味这段代码,就会发现包装器的好用之处,其原因在于直接将一类功能类似的函数进行泛化,可以通过具体的反应进行直接调用,还有我们所写的一类代码统一的出现在一个地方这样便于维护。
三、bind
bind也是函数的封装,类似与包装器,不过更详细的是对参数的个数和传参顺序的封装,下面我们来看看如何具体使用。
1.基本语法

- 将参数1(函数指针/ 仿函数/lambda),剩余函数参数传进去即可,具体要进行分类进讨论。
2.常见用法
1.函数指针
- 改变参数顺序
double sub(int x, int y)
{return x - y;
}
int main()
{function<double(int, int)> f1 = bind(sub, placeholders::_1,\placeholders::_2);cout << f1(1, 2) << endl;function<double(int, int)> f2 = bind(sub, placeholders::_2,\placeholders::_1);cout << f2(1, 2) << endl;return 0;
}
逻辑图解:

- 改变参数个数
double sub1(int x, double rate, int y)
{return (x - y) * rate;
}
int main()
{function<double(int, int)> ff1 = bind(sub1, placeholders::_1,\1.5, placeholders::_2);//在定义期间固定参数,类似与缺省值的效果。cout << ff1(2, 1) << endl;auto ff2 = bind(sub1, placeholders::_1, 1, placeholders::_2);cout << ff2(3, 1) << endl;
}
逻辑图解:

- 说明:lambda与函数指针的用法相同。
2.仿函数
struct SubType
{static double sub(int x, int y)//没有this指针,不用进行传参{return x - y;}double ssub(int x, int y){return x - y;}
};
int main()
{function<double(int, int)> pf1 = bind(SubType::sub,\placeholders::_1, placeholders::_2);//sub为static函数,没有this指针,只需指定作用域即可。SubType st; //语法规定普通成员函数传参需加&auto pf3 = bind(&SubType::ssub, &st, placeholders::_1,\placeholders::_2);//ssub为普通成员函数,有this指针,因此需要指定作用域外加传this指针。auto pf2 = bind(&SubType::ssub, SubType(), placeholders::_1,\placeholders::_2);//也可用对象进行调用。return 0;
}
总之,bind可以改变参数的个数和顺序,改变参数的个数可以固定参数值和减少传参,改变参数顺序,可以更加符合函数使用者的习惯(比如在strcpy一般第一个参数是dest,第二个参数为source,如果实现接口的程序员将参数写反了,我们可以通过包装更加符合我们的代码编写习惯。) 。
四、智能指针
为了解决异常的执行流乱跳而导致内存泄漏的问题:
void func()
{//假设new int 可能会抛出bad_alloc的异常。int* ptr1 = new int(1);//当运行到此处ptr1出错时,我们只需抛出异常即可int* ptr2 = new int(2);//当运行到此处出ptr2错时,我们需要释放ptr1,然后抛出异常。int* ptr3 = new int(3);//当运行到此处ptr3出错时,我们需要释放ptr2,然后向外层抛出异常。delete ptr1;delete ptr2;delete ptr3;
}
第一种方式我们可以通过try catch进行解决:
void func1()
{//假设new int 也可能会抛出异常。//根据异常的捕获与处理,我们可以这样解决。try{int* ptr1 = new int(1);//...try{int* ptr2 = new int(2);//...try{int* ptr3 = new int(3);//...delete ptr3;}catch (...){//当运行到此处ptr3出错时,我们需要释放ptr2,然后向外层抛出异常。delete ptr2;throw;}delete ptr2;}catch (...){//当运行到此处出ptr2错时,我们需要释放ptr1,然后抛出异常。delete ptr1;throw;}delete ptr1;}catch (...){//当运行到此处ptr1出错时,我们只需抛出异常即可throw;}
}
int main()
{try{func1();}catch (const exception& e){cout << e.what() << endl;}catch (...){//...未知异常;}return 0;
}
-
很明显,每开辟一次我们需要进行try catch进行手动对异常进行捕获,很麻烦,那有没有简单的方式呢?很明显是有的。
-
RAII思想,资源获取即初始化,也就是用局部对象对资源进行管理,出作用域时会自动调用析构函数对资源进行释放。
就像这样:
template<class T>
class smart_ptr
{
public:smart_ptr(T* ptr):_ptr(ptr){}~smart_ptr(){if (_ptr)delete _ptr;}
private:T* _ptr;
};
void func()
{//假设new int 可能会抛出bad_alloc的异常。smart_ptr<int> ptr1 (new int(1));//当运行到此处ptr1出错时,我们只需抛出异常即可smart_ptr<int> ptr2(new int(2));//当运行到此处ptr2出错时,出作用域自动释放ptr1,然后抛出异常。smart_ptr<int> ptr3(new int(3));//当运行到此处ptr3出错时,出作用域自动释放ptr1,ptr2,然后向外层抛出异常。
}
这样就简单的使用了RAII思想解决问题,但是如果是赋值问题与拷贝该如何解决呢?在使用默认的成员函数的情况下,可能会出现内存泄漏和重复释放的风险。下面就让我们看看库里面是如何实现的吧!
1.auto_ptr
1.1基本使用
class A
{
public:A(int a):_a(a){}~A(){cout << "~A()" << endl;}
private:int _a = 0;
};
int main()
{auto_ptr<A> ap1(new A(1));auto_ptr<A> ap2(new A(2));auto_ptr<A> ap3(ap1);//资源管理权的转移。ap1 = ap2;//调用析构函数先释放ap1的资源,再将ap2的资源转移给ap1。return 0;
}
监视逻辑:从ap3的初始化开始。

- 赋值与拷贝的实现方式是对资源的管理权进行转移。
1.2基本实现
namespace MY_SMART_PTR
{template<class T>class auto_ptr{public:auto_ptr(T* ptr = nullptr):_ptr(ptr){}~auto_ptr(){if (_ptr)delete _ptr;}//既然是指针就得像指针一样进行访问。T& operator *(){return *_ptr;}T* operator ->(){return _ptr;}auto_ptr( auto_ptr<T>& ptr):_ptr(ptr._ptr){ptr._ptr = nullptr;}auto_ptr<T>& operator = (auto_ptr& ptr){if(_ptr)delete _ptr;_ptr = ptr._ptr;ptr._ptr = nullptr;return *this;}private:T* _ptr;};
}
2.unique_ptr
1.1基本使用
- 对资源的使用权进行转移。
class A
{
public:A(int a):_a(a){}~A(){cout << "~A()" << endl;}
private:int _a = 0;
};
int main()
{unique_ptr<A> up1(new A(1));unique_ptr<A> up2(new A(2));unique_ptr<A> up3(new A(3));up1 = up2;//直接禁掉了。unique_ptr<A> up3(up1);//也是被删除了return 0;
}
会直接进行报错:

1.2基本实现
- 不可进行共享资源
namespace MY_SMART_PTR
{template<class T>class unique_ptr{public:unique_ptr(T* ptr):_ptr(ptr){}~unique_ptr(){if (_ptr)delete _ptr;}T& operator *(){return *_ptr;}T* operator ->(){return _ptr;}//两种方式://1.C++98之前构造函数私有+声明进行实现。//2.C++11沿用之前的default与纯虚函数 == 0的写法,设为delete进行删除。unique_ptr(const unique_ptr<T>& ptr) = delete;unique_ptr<T>& operator = (unique_ptr<T>& ptr) = delete;private:T* _ptr;};
}
3.shared_ptr
1.1基本使用
- 可以进行共享资源。
class A
{
public:A(int a):_a(a){}~A(){cout << "~A()" << endl;}
private:int _a = 0;
};
int main()
{shared_ptr<A> sp1(new A(1));shared_ptr<A> sp2(new A(2));shared_ptr<A> sp3 = sp1;//采取引用计数sp3与sp1共享资源,析构采取引用计数。sp1 = sp2;//实现需注意与自身的赋值return 0;
}
实现图解:

- 当对象进行拷贝构造时,将对象进行浅拷贝,并进行引用计数。
- 当对象进行赋值时,对被赋值的对象的引用计数进行检查,对引用计数减减,如果引用计数为0。则进行资源的清理。
1.2基本实现
- 开辟一个count的资源对指向资源的对象进行计数。
namespace MY_SMART_PTR
{template<class T>class shared_ptr{public:shared_ptr(T* ptr ):_ptr(ptr),_pcount(new int(1)){}~shared_ptr(){if (--(*_pcount) == 0){delete _ptr;delete _pcount;}}T& operator *(){return *_ptr;}T* operator ->(){return _ptr;}shared_ptr(shared_ptr<T>& ptr):_ptr(ptr._ptr),_pcount(ptr._pcount){if(_pcount)(*_pcount)++;}shared_ptr<T>& operator = (shared_ptr<T>& ptr){//判断是否相等,包括资源指向空的情况if (ptr._pcount == _pcount)return *this;//*this的_pcount的内容进行减减,判断是否为0if (_pcount && --(*_pcount) == 0){delete _ptr;delete _pcount;}//对ptr指向的pcount加加_ptr = ptr._ptr;_pcount = ptr._pcount;if(_pcount)++(*_pcount);return *this;}T* get()const{return _ptr;}private:T* _ptr;int* _pcount;};
}
shared_ptr看起来是完美的,那么有没有什么缺陷呢?
思考下面一段代码:
struct Node
{
public:~Node(){cout << "~Node()" << endl;}shared_ptr<Node> _prev;shared_ptr<Node> _next;
};
int main()
{//循环引用——关键与难点//画图分析shared_ptr<Node> sp1(new Node);shared_ptr<Node> sp2(new Node);sp1->_next = sp2;sp2->_prev = sp1;return 0;
}
- 运行分析程序的结果:

运行结果看似正确,其实隐含了内存泄漏,因为sp1和sp2的资源没有被释放,这是为什么呢?
我们画图进行分析:

- 关键在于对象析构时sp1和sp2分别只调用了一次析构函数,使引用计数减为1,最后对资源没有进行释放,那么如何解决这个问题呢?就引出了weak_ptr。
- 这种现象我们称之为循环引用。
4.weak_ptr
1.1基本使用
{
public:~Node(){cout << "~Node()" << endl;}weak_ptr<Node> _prev;weak_ptr<Node> _next;
};
int main()
{//循环引用——关键与难点//画图分析shared_ptr<Node> sp1(new Node);shared_ptr<Node> sp2(new Node);sp1->_next = sp2;sp2->_prev = sp1;return 0;
}
- 其实现原理也很简单,就是weak_ptr中没有引用计数,且不参与资源的析构。
图解:
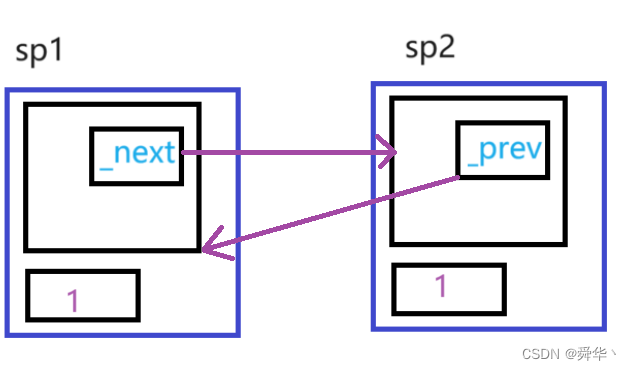
- 在析构时调用两次即可对资源进行释放。
1.2基本实现
- 实现shared_ptr转weak_ptr的赋值与拷贝构造。
- 没有引用计数且不需要写析构函数。
namespace MY_SMART_PTR
{template<class T>class weak_ptr{public:weak_ptr(){}T& operator *(){return *_ptr;}T* operator ->(){return _ptr;}weak_ptr(shared_ptr<T>& ptr):_ptr(ptr.get()){}weak_ptr<T>& operator = (shared_ptr<T>& ptr){_ptr = ptr.get();return *this;}private:T* _ptr = nullptr;};
}
- 1.weak_ptr不是
RAII的智能指针,是专门用来解决循环引用的问题。
2.weak_ptr不增加引用计数,只参与资源使用,不参与资源的释放。
总结
今天的分享就到这里了,如果有所帮助,不妨点个赞鼓励一下,我们下篇文章再见~
![[天翼杯 2021]esay_eval - RCE(disabled_function绕过||AS_Redis绕过)+反序列化(大小写wakeup绕过)](https://img-blog.csdnimg.cn/5bb974fa9f004da98079e22d539c53c5.png#pic_center)