本章概要
- 测试驱动开发
- 测试驱动 vs 测试优先
- 日志
- 日志信息
- 日志等级
测试驱动开发
之所以可以有测试驱动开发(TDD)这种开发方式,是因为如果你在设计和编写代码时考虑到了测试,那么你不仅可以写出可测试性更好的代码,而且还可以得到更好的代码设计。 一般情况下这个说法都是正确的。 一旦我想到“我将如何测试我的代码?”,这个想法将使我的代码产生变化,并且往往是从“可测试”转变为“可用”。
纯粹的 TDD 主义者会在实现新功能之前就为其编写测试,这称为测试优先的开发。 我们采用一个简易的示例程序来进行说明,它的功能是反转 String 中字符的大小写。 让我们随意添加一些约束:String 必须小于或等于30个字符,并且必须只包含字母,空格,逗号和句号(英文)。
此示例与标准 TDD 不同,因为它的作用在于接收 StringInverter 的不同实现,以便在我们逐步满足测试的过程中来体现类的演变。 为了满足这个要求,将 StringInverter 作为接口:
// validating/StringInverter.java
package validating;interface StringInverter {String invert(String str);
}
现在我们通过可以编写测试来表述我们的要求。 以下所述通常不是你编写测试的方式,但由于我们在此处有一个特殊的约束:我们要对 **StringInverter **多个版本的实现进行测试,为此,我们利用了 JUnit5 中最复杂的新功能之一:动态测试生成。 顾名思义,通过它你可以使你所编写的代码在运行时生成测试,而不需要你对每个测试显式编码。 这带来了许多新的可能性,特别是在明确地需要编写一整套测试而令人望而却步的情况下。
JUnit5 提供了几种动态生成测试的方法,但这里使用的方法可能是最复杂的。 **DynamicTest.stream() **方法采用了:
- 对象集合上的迭代器 (versions) ,这个迭代器在不同组的测试中是不同的。 迭代器生成的对象可以是任何类型,但是只能有一种对象生成,因此对于存在多个不同的对象类型时,必须人为地将它们打包成单个类型。
- Function,它从迭代器获取对象并生成描述测试的 String 。
- Consumer,它从迭代器获取对象并包含基于该对象的测试代码。
在此示例中,所有代码将在 testVersions() 中进行组合以防止代码重复。 迭代器生成的对象是对 DynamicTest 的不同实现,这些对象体现了对接口不同版本的实现:
import org.junit.jupiter.api.*;import java.util.*;
import java.util.function.*;
import java.util.stream.*;import static org.junit.jupiter.api.Assertions.assertEquals;
import static org.junit.jupiter.api.Assertions.assertTrue;class DynamicStringInverterTests {// Combine operations to prevent code duplication:Stream<DynamicTest> testVersions(String id,Function<StringInverter, String> test) {List<StringInverter> versions = Arrays.asList(new Inverter1(), new Inverter2(),new Inverter3(), new Inverter4());return DynamicTest.stream(versions.iterator(),inverter -> inverter.getClass().getSimpleName(),inverter -> {System.out.println(inverter.getClass().getSimpleName() +": " + id);try {if (test.apply(inverter) != "fail")System.out.println("Success");} catch (Exception | Error e) {System.out.println("Exception: " + e.getMessage());}});}String isEqual(String lval, String rval) {if (lval.equals(rval))return "success";System.out.println("FAIL: " + lval + " != " + rval);return "fail";}@BeforeAllstatic void startMsg() {System.out.println(">>> Starting DynamicStringInverterTests <<<");}@AfterAllstatic void endMsg() {System.out.println(">>> Finished DynamicStringInverterTests <<<");}@TestFactoryStream<DynamicTest> basicInversion1() {String in = "Exit, Pursued by a Bear.";String out = "eXIT, pURSUED BY A bEAR.";return testVersions("Basic inversion (should succeed)",inverter -> isEqual(inverter.invert(in), out));}@TestFactoryStream<DynamicTest> basicInversion2() {return testVersions("Basic inversion (should fail)",inverter -> isEqual(inverter.invert("X"), "X"));}@TestFactoryStream<DynamicTest> disallowedCharacters() {String disallowed = ";-_()*&^%$#@!~`0123456789";return testVersions("Disallowed characters",inverter -> {String result = disallowed.chars().mapToObj(c -> {String cc = Character.toString((char) c);try {inverter.invert(cc);return "";} catch (RuntimeException e) {return cc;}}).collect(Collectors.joining(""));if (result.length() == 0)return "success";System.out.println("Bad characters: " + result);return "fail";});}@TestFactoryStream<DynamicTest> allowedCharacters() {String lowcase = "abcdefghijklmnopqrstuvwxyz ,.";String upcase = "ABCDEFGHIJKLMNOPQRSTUVWXYZ ,.";return testVersions("Allowed characters (should succeed)",inverter -> {assertEquals(inverter.invert(lowcase), upcase);assertEquals(inverter.invert(upcase), lowcase);return "success";});}@TestFactoryStream<DynamicTest> lengthNoGreaterThan30() {String str = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx";assertTrue(str.length() > 30);return testVersions("Length must be less than 31 (throws exception)",inverter -> inverter.invert(str));}@TestFactoryStream<DynamicTest> lengthLessThan31() {String str = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx";assertTrue(str.length() < 31);return testVersions("Length must be less than 31 (should succeed)",inverter -> inverter.invert(str));}
}
在一般的测试中,你可能认为在进行一个结果为失败的测试时应该停止代码构建。 但是在这里,我们只希望系统报告问题,但仍然继续运行,以便你可以看到不同版本的 StringInverter 的效果。
每个使用 **@TestFactory ** 注释的方法都会生成一个 DynamicTest 对象的 Stream(通过 testVersions() ),每个 JUnit 都像常规的 **@Test ** 方法一样执行。
现在测试都已经准备好了,我们就可以开始实现 **StringInverter **了。 我们从一个仅返回其参数的假的实现类开始:
// validating/Inverter1.java
package validating;
public class Inverter1 implements StringInverter {public String invert(String str) { return str; }
}
接下来我们实现反转操作:
// validating/Inverter2.java
package validating;
import static java.lang.Character.*;
public class Inverter2 implements StringInverter {public String invert(String str) {String result = "";for(int i = 0; i < str.length(); i++) {char c = str.charAt(i);result += isUpperCase(c) ?toLowerCase(c) :toUpperCase(c);}return result;}
}
现在添加代码以确保输入不超过30个字符:
// validating/Inverter3.java
package validating;
import static java.lang.Character.*;
public class Inverter3 implements StringInverter {public String invert(String str) {if(str.length() > 30)throw new RuntimeException("argument too long!");String result = "";for(int i = 0; i < str.length(); i++) {char c = str.charAt(i);result += isUpperCase(c) ?toLowerCase(c) :toUpperCase(c);}return result;}
}
最后,我们排除了不允许的字符:
// validating/Inverter4.java
package validating;
import static java.lang.Character.*;
public class Inverter4 implements StringInverter {static final String ALLOWED ="abcdefghijklmnopqrstuvwxyz ,." +"ABCDEFGHIJKLMNOPQRSTUVWXYZ";public String invert(String str) {if(str.length() > 30)throw new RuntimeException("argument too long!");String result = "";for(int i = 0; i < str.length(); i++) {char c = str.charAt(i);if(ALLOWED.indexOf(c) == -1)throw new RuntimeException(c + " Not allowed");result += isUpperCase(c) ?toLowerCase(c) :toUpperCase(c);}return result;}
}
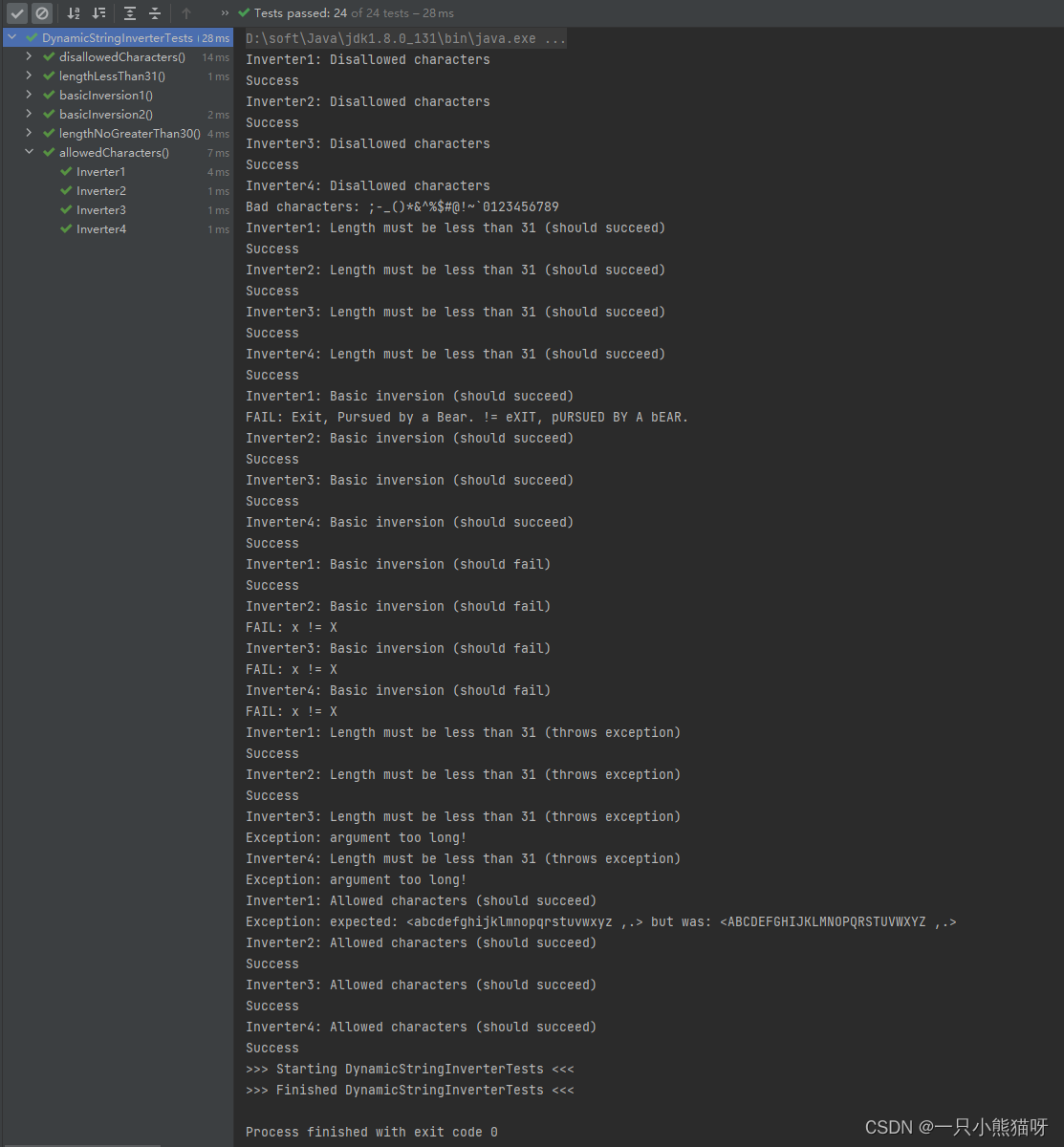
你将从测试输出中看到,每个版本的 Inverter 都几乎能通过所有测试。 当你在进行测试优先的开发时会有相同的体验。
DynamicStringInverterTests.java 仅是为了显示 TDD 过程中不同 StringInverter 实现的开发。 通常,你只需编写一组如下所示的测试,并修改单个 StringInverter 类直到它满足所有测试:
// validating/tests/StringInverterTests.java
package validating;
import java.util.*;
import java.util.stream.*;
import org.junit.jupiter.api.*;
import static org.junit.jupiter.api.Assertions.*;public class StringInverterTests {StringInverter inverter = new Inverter4();@BeforeAllstatic void startMsg() {System.out.println(">>> StringInverterTests <<<");}@Testvoid basicInversion1() {String in = "Exit, Pursued by a Bear.";String out = "eXIT, pURSUED BY A bEAR.";assertEquals(inverter.invert(in), out);}@Testvoid basicInversion2() {expectThrows(Error.class, () -> {assertEquals(inverter.invert("X"), "X");});}@Testvoid disallowedCharacters() {String disallowed = ";-_()*&^%$#@!~`0123456789";String result = disallowed.chars().mapToObj(c -> {String cc = Character.toString((char)c);try {inverter.invert(cc);return "";} catch(RuntimeException e) {return cc;}}).collect(Collectors.joining(""));assertEquals(result, disallowed);}@Testvoid allowedCharacters() {String lowcase = "abcdefghijklmnopqrstuvwxyz ,.";String upcase = "ABCDEFGHIJKLMNOPQRSTUVWXYZ ,.";assertEquals(inverter.invert(lowcase), upcase);assertEquals(inverter.invert(upcase), lowcase);}@Testvoid lengthNoGreaterThan30() {String str = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx";assertTrue(str.length() > 30);expectThrows(RuntimeException.class, () -> {inverter.invert(str);});}@Testvoid lengthLessThan31() {String str = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx";assertTrue(str.length() < 31);inverter.invert(str);}
}
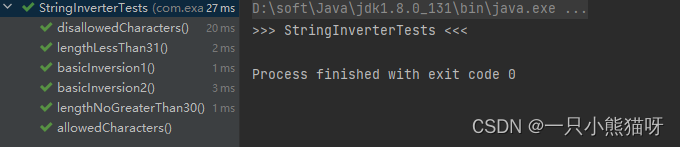
你可以通过这种方式进行开发:一开始在测试中建立你期望程序应有的所有特性,然后你就能在实现中一步步添加功能,直到所有测试通过。 完成后,你还可以在将来通过这些测试来得知(或让其他任何人得知)当修复错误或添加功能时,代码是否被破坏了。 TDD的目标是产生更好,更周全的测试,因为在完全实现之后尝试实现完整的测试覆盖通常会产生匆忙或无意义的测试。
测试驱动 vs 测试优先
虽然我自己还没有达到测试优先的意识水平,但我最感兴趣的是来自测试优先中的“测试失败的书签”这一概念。 当你离开你的工作一段时间后,重新回到工作进展中,甚至找到你离开时工作到的地方有时会很有挑战性。 然而,以失败的测试为书签能让你找到之前停止的地方。 这似乎让你能更轻松地暂时离开你的工作,因为不用担心找不到工作进展的位置。
纯粹的测试优先编程的主要问题是它假设你事先了解了你正在解决的问题。 根据我自己的经验,我通常是从实验开始,而只有当我处理问题一段时间后,我对它的理解才会达到能给它编写测试的程度。 当然,偶尔会有一些问题在你开始之前就已经完全定义,但我个人并不常遇到这些问题。 实际上,可能用“面向测试的开发 ( Test-Oriented Development )”这个短语来描述编写测试良好的代码或许更好。
日志
日志信息
在调试程序中,日志可以是普通状态数据,用于显示程序运行过程(例如,安装程序可能会记录安装过程中采取的步骤,存储文件的目录,程序的启动值等)。
在调试期间,日志也能带来好处。 如果没有日志,你可能会尝试通过插入 println() 语句来打印出程序的行为。 本书中的一些例子使用了这种技术,并且在没有调试器的情况下(下文中很快就会介绍这样一个主题),它就是你唯一的工具。 但是,一旦你确定程序正常运行,你可能会将 println() 语句注释或者删除。 然而,如果你遇到更多错误,你可能又需要运行它们。因此,如果能够只在需要时轻松启用输出程序状态就好多了。
程序员在日志包可供使用之前,都只能依赖 Java 编译器移除未调用的代码。 如果 debug 是一个 **static final boolean **,你就可以这么写:
if(debug) {System.out.println("Debug info");
}
然后,当 **debug **为 **false **时,编译器将移除大括号内的代码。 因此,未调用的代码不会对运行时产生影响。 使用这种方法,你可以在整个程序中放置跟踪代码,并轻松启用和关闭它。 但是,该技术的一个缺点是你必须重新编译代码才能启用和关闭跟踪语句。因此,通过更改配置文件来修改日志属性,从而起到启用跟踪语句但不用重新编译程序会更方便。
业内普遍认为标准 Java 发行版本中的日志包 (java.util.logging) 的设计相当糟糕。 大多数人会选择其他的替代日志包。如 Simple Logging Facade for Java(SLF4J) ,它为多个日志框架提供了一个封装好的调用方式,这些日志框架包括 java.util.logging , logback 和 **log4j **。 SLF4J 允许用户在部署时插入所需的日志框架。
SLF4J 提供了一个复杂的工具来报告程序的信息,它的效率与前面示例中的技术几乎相同。 对于非常简单的信息日志记录,你可以执行以下操作:
import org.slf4j.*;public class SLF4JLogging {private static Logger log = LoggerFactory.getLogger(SLF4JLogging.class);public static void main(String[] args) {log.info("hello logging");}
}

日志输出中的格式和信息,甚至输出是否正常或“错误”都取决于 SLF4J 所连接的后端程序包是怎样实现的。 在上面的示例中,它连接到的是 logback 库(通过本书的 build.gradle 文件),并显示为标准输出。
日志系统会检测日志消息处所在的类名和方法名。 但它不能保证这些名称是正确的,所以不要纠结于其准确性。
日志等级
SLF4J 提供了多个等级的日志消息。下面这个例子以“严重性”的递增顺序对它们作出演示:
import org.slf4j.*;public class SLF4JLevels {private static Logger log =LoggerFactory.getLogger(SLF4JLevels.class);public static void main(String[] args) {log.trace("Hello");log.debug("Logging");log.info("Using");log.warn("the SLF4J");log.error("Facade");}
}
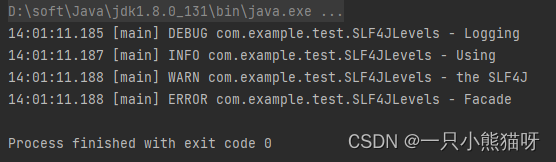
你可以按等级来查找消息。 级别通常设置在单独的配置文件中,因此你可以重新配置而无需重新编译。 配置文件格式取决于你使用的后端日志包实现。 如 logback 使用 XML :
<!-- validating/logback.xml -->
<?xml version="1.0" encoding="UTF-8"?>
<configuration><appender name="STDOUT"class="ch.qos.logback.core.ConsoleAppender"><encoder><pattern>
%d{yyyy-MM-dd'T'HH:mm:ss.SSS}
[%thread] %-5level %logger - %msg%n</pattern></encoder></appender><root level="TRACE"><appender-ref ref="STDOUT" /></root>
</configuration>
你可以尝试将 **<root level =“TRACE"> **行更改为其他级别,然后重新运行该程序查看日志输出的更改情况。 如果你没有写 logback.xml 文件,日志系统将采取默认配置。
这只是 SLF4J 最简单的介绍和一般的日志消息,但也足以作为使用日志的基础 - 你可以沿着这个进行更长久的学习和实践。你可以查阅 SLF4J 文档来获得更深入的信息。
![[Python]黑色背景白色块滑动视频](https://img-blog.csdnimg.cn/b604defed3734368849960d962c145a3.png)