文章目录
- 🎀前言:
- 🏅先在开头总结一下,二叉树解题的思维模式分两类:
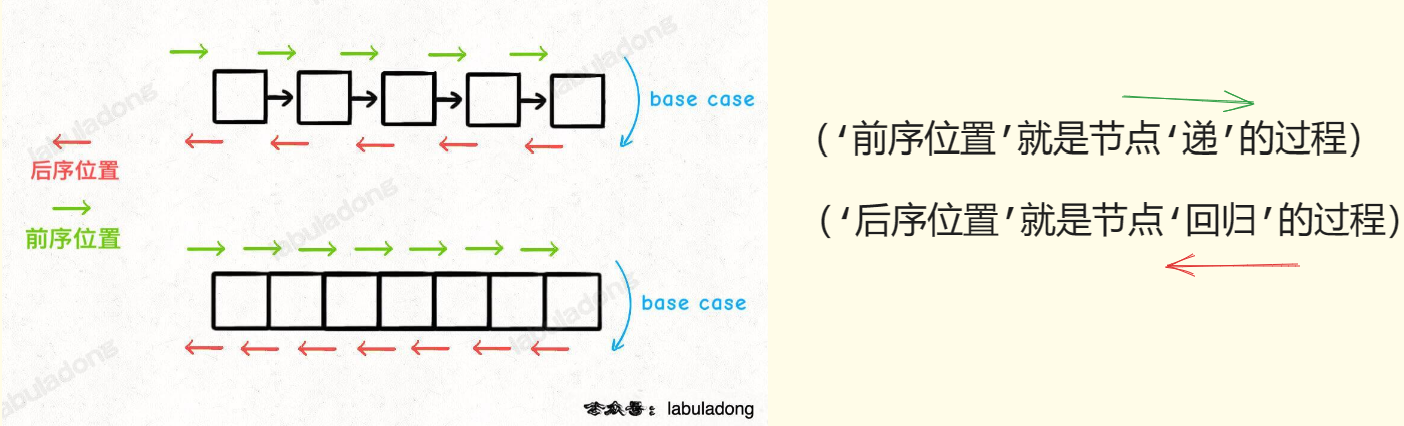
- 🎇先解释一下“前序位置”,“后序位置”的意思
- 🏨举一个简单的例子:
- 🪀下面通过两道例题,让你更加清晰的认识一下:
- 示例一:求二叉树的最大高度
- 示例二:翻转二叉树
🎀前言:
本篇博客目的是为了培养面对二叉树题型解题思维及去让你充分理解每个结点在递归之前、递归之后的位置的不同作用
🏅先在开头总结一下,二叉树解题的思维模式分两类:

🎇先解释一下“前序位置”,“后序位置”的意思

你也注意到了,只要是递归形式的遍历,都可以有前序位置和后序位置,
分别在递归之前和递归之后。
前序位置:就是刚进入一个节点(元素)的时候,
后序位置:就是即将离开一个节点(元素)的时候,那么进一步,
你把代码写在不同位置,代码执行的时机也不同:
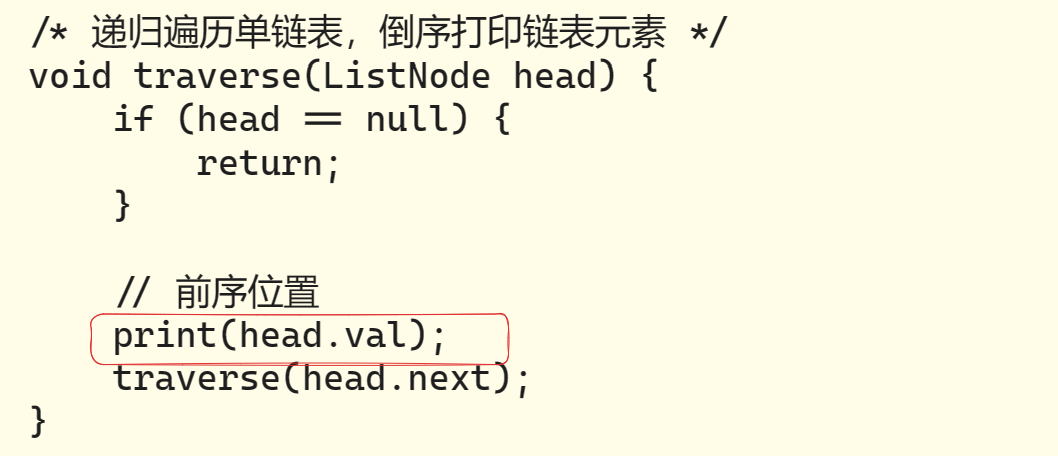
🏨举一个简单的例子:
比如说,如果让你倒序打印一条单链表上所有节点的值,你怎么搞?

结合上面那张图,你应该知道为什么这段代码能够倒序打印单链表了吧。
那如果让你正序打印呢?
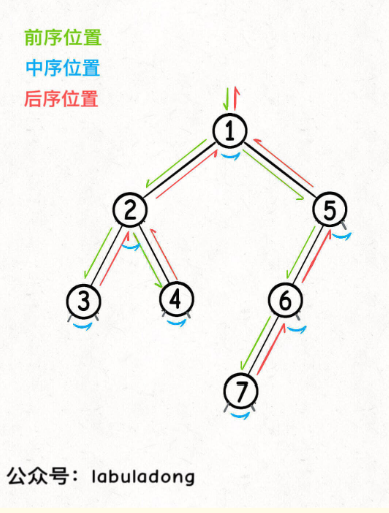
如过你理解了,那么恭喜你,你已经理解真谛了。那么二叉树也是一样的,它就只是多了一个叉而已

讲了这么多,这就是所有的核心内容了。,接下来就是如何来用,如何将这个知识带入做题思维里边去,就行了。
🪀下面通过两道例题,让你更加清晰的认识一下:
示例一:求二叉树的最大高度
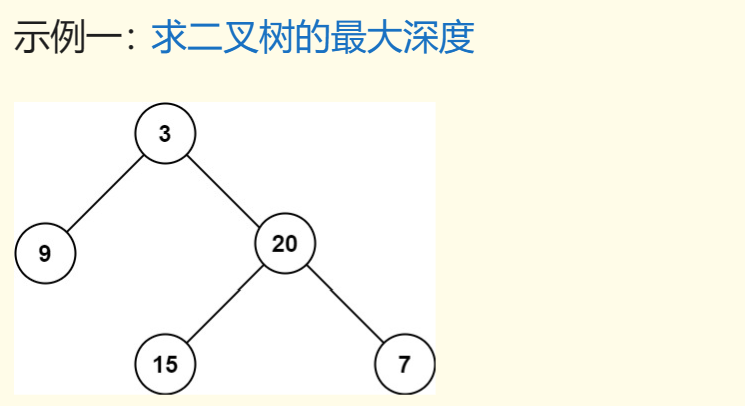
你做这题的思路是什么?
显然遍历一遍二叉树,用一个外部变量记录每个节点所在的深度,
取最大值就可以得到最大深度了,这就是遍历二叉树计算答案的思路。
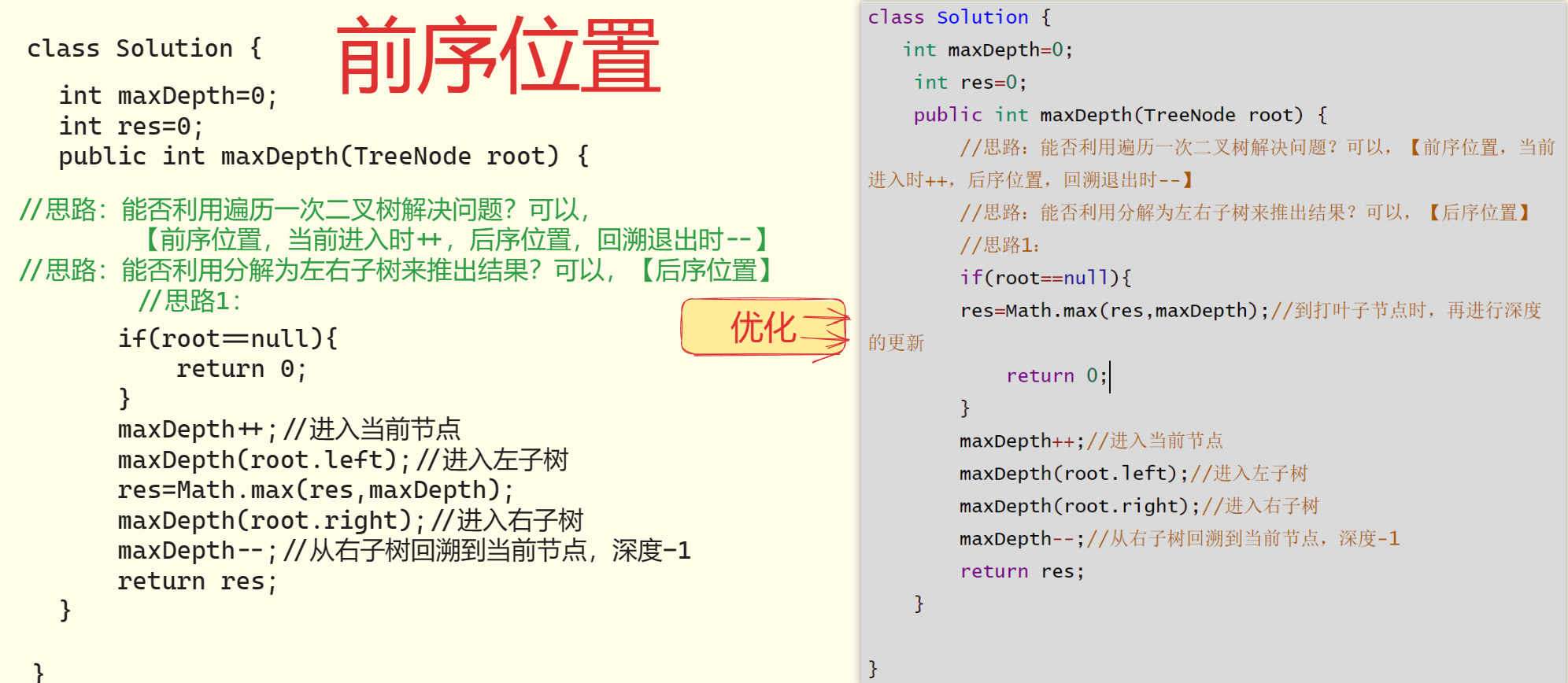
这个解法应该很好理解,但为什么需要在前序位置增加 depth,在后序位置减小 depth?
因为前面说了,前序位置是进入一个节点的时候,后序位置是离开一个节点的时候,
depth 记录当前递归到的节点深度,你把 traverse 理解成在二叉树上游走的一个指针,
所以当然要这样维护。
至于对 res 的更新,你放到前中后序位置都可以,只要保证在进入节点之后,
离开节点之前(即 depth 自增之后,自减之前)就行了。(优化部分,是考虑到每次递归都需要更新res的值,而树的最大高度是根到叶子节点中最深的)
🐕当然,你也很容易发现一棵二叉树的最大深度可以通过子树的最大深度推导出来,
这就是分解问题计算答案的思路

因为这个思路正确的核心在于,你确实可以通过子树的最大深度推导出原树的深度,
所以当然要首先利用递归函数的定义算出左右子树的最大深度,然后推出原树的最大深度,
主要逻辑自然放在后序位置

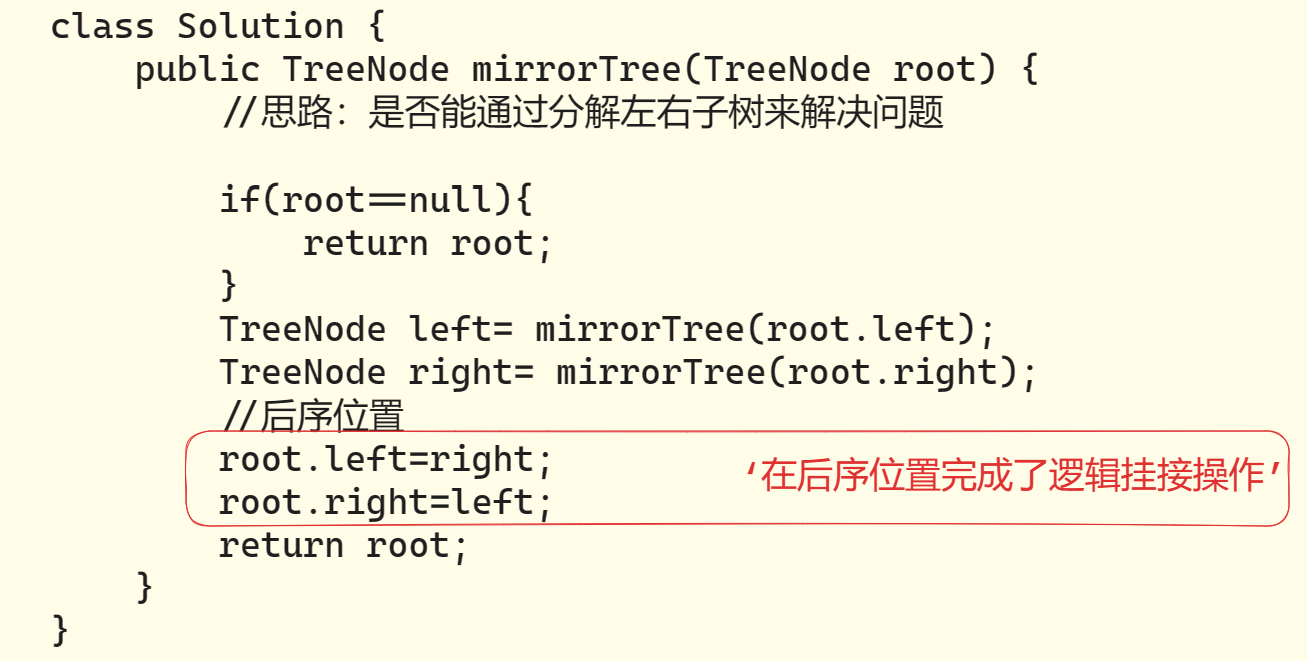
示例二:翻转二叉树
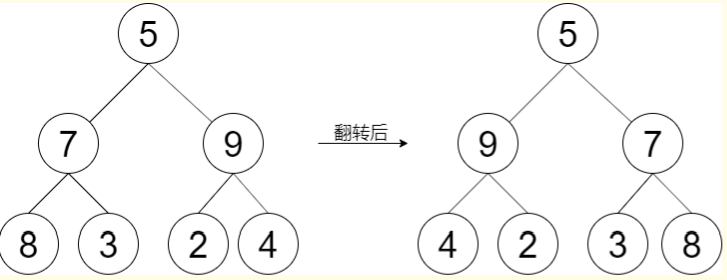
不难发现,只要把二叉树上的每一个节点的左右子节点进行交换,最后的结果就是完全翻转之后的二叉树。
那么现在开始在心中默念二叉树解题总纲:
1、这题能不能用「遍历」的思维模式解决?
可以,我写一个 traverse 函数遍历每个节点,让每个节点的左右子节点相互交换过来就行了
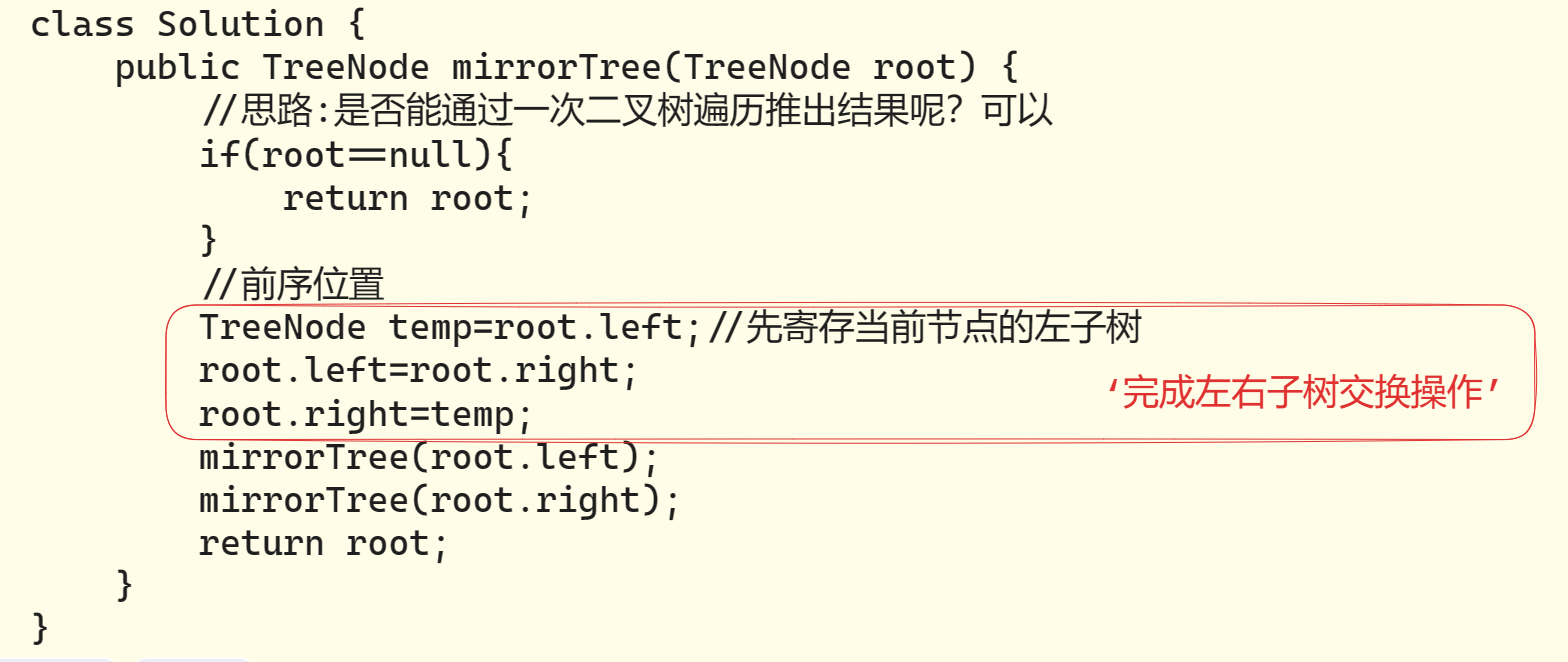
2、这题能不能用「分解问题」的思维模式解决?
可以,从叶子节点入手,先交换叶子节点的左右子树,
再进行倒数第二层父节点处理操作(这里假设它是棵满二叉树),
交换左右子树的叶子节点,再进行倒数第三层父节点处理操作,交换它的左右子树,…
直到根节点,交换它的左右子树
至此,我们在面对二叉树的所有问题时,都能够有思路了。
甚至你一眼就能看出别人用的是遍历二叉树的思路还是分解成左右子树来推出结果的思路
(主要看它的逻辑操作在‘前序位置’还是‘后序位置’写了,它就是哪种思路)
能够看到这里的朋友,谢谢你能够坚持看完,如果这个思维框架对你有所启发,
推荐你看一下《labuladong的算法笔记》(或者直接在哔站上看他讲的网课(讲的挺好的))