文章目录
- (87)切片机制与MapTask并行度决定机制
- (90) 切片源码总结
- (91)FileInputFormat切片机制
- (92)TextInputFormat及其他实现类一览
- (93) CombineTextInputFormat切片机制
- 原理
- 案例讲解
- 参考文献
(87)切片机制与MapTask并行度决定机制
什么是MapTask的并行度?
即在一个MR程序里,需要并行开启多少个MapTask,来处理数据。
并行度是越大越好么,当然不是,这玩意儿当然还得看需要处理的数据量,如果数据量不大,开一堆MapTask的话,既浪费资源,又拖慢整体速度(MapTask初始化也是要时间的)。
那么MapTask的并行度设置多少比较合适,或者说应该参考什么指标来制定?
首先我们复习一下block的概念,即文件块,是HDFS存储数据的单位,一般是128M一个数据块。block属于是在物理磁盘上,切切实实的对数据进行了分割。
再介绍一个新概念,即数据切片,数据切片是在逻辑上对输入的数据进行分片,并不会影响数据在物理上的存储。数据切片是MapReduce中计算输入数据的单位,每一个数据切片会对应启动一个MapTask。
直接总结给出结论:
-
一个job(或者说一个MR程序)的Map阶段并行度,由客户端在提交job时的切片数来决定;
-
每一个切片分配一个MapTask;
-
默认情况下,切片大小等于块大小。(即默认也是128M)
-
切片时不考虑数据整体,而是逐个对每一个所提交文件单独切片,即不可能出现文件A的末尾和文件B的开头出现在同一片里,这种情况。
结论3和结论4其实原因差不多哈,可以理解成是为了尽量避免在不同DataNode之间通信的损耗。
比如说现在我要处理的一个大文件,命名成a.txt吧,它的第一个block位于DataNode_1上,第二个block位于DataNode_2上,第三个block位于DataNode_3上。
如果切片大小不等于block大小的话,且考虑数据整体,那肯定会出现不同DataNode上的数据位于同一个切片的情况。
比如说我把切片大小定为100M,那么第一片就位于DataNode_1上,是0M~100M,然后DataNode_1上只剩下28M数据,需要从DataNode_2上再拿72M数据,才能再凑齐一个切片。
那这就有问题了,在处理第二个切片的时候,需要同时通信DataNode_1和DataNode_2,肯定是不如在单个DataNode上完全处理完要好。
因此,切片大小等于块大小,是比较好的。
结论4的原因也差不多,不同文件的block存放的DataNode那肯定更五花八门了,说不定处理一个切片都得联系五六个DataNode,那太低效了。
(90) 切片源码总结
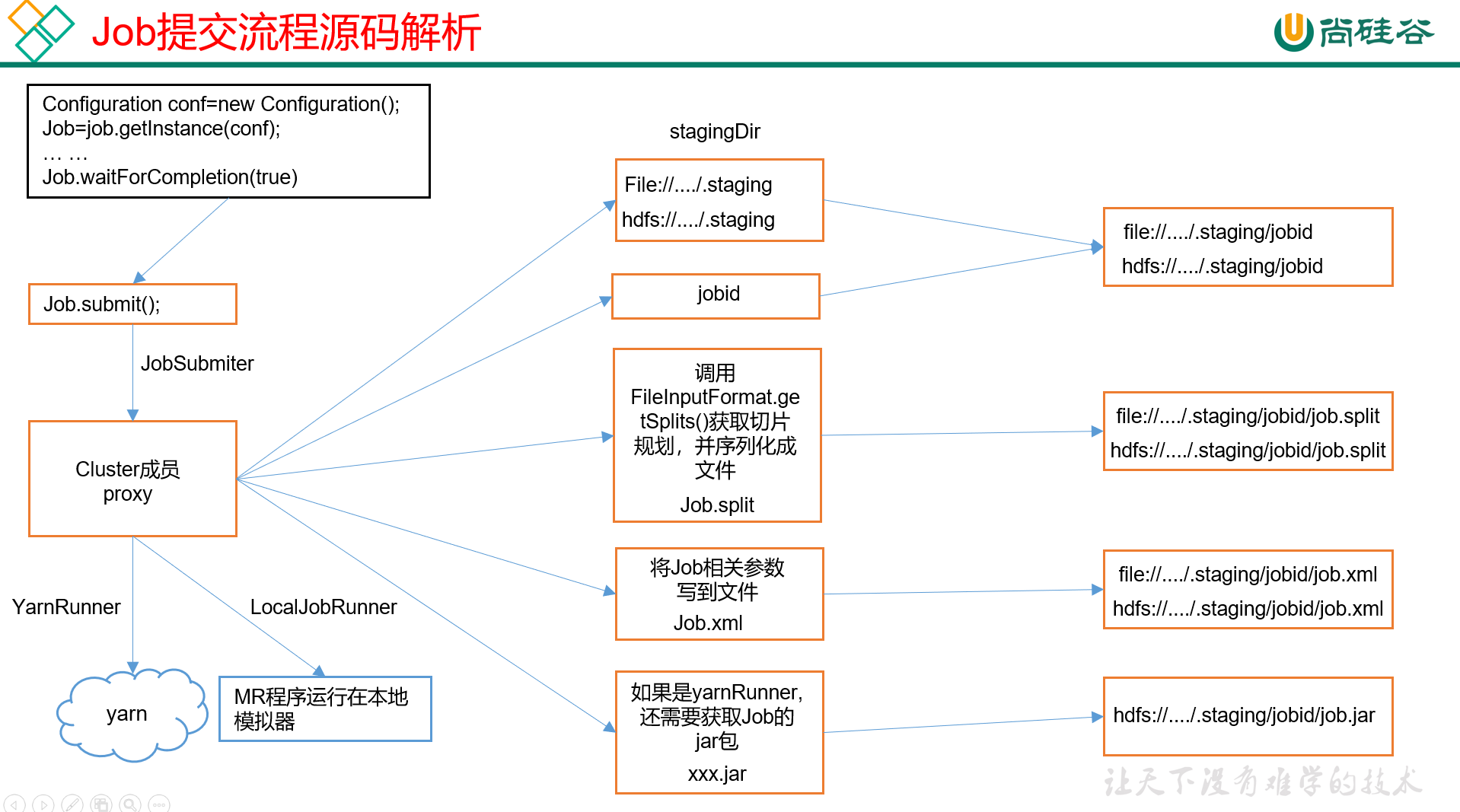
切片这个动作是针对输入数据的,默认是FileInputFormat,主要步骤我们可以文件简单描述一遍。
1) 程序需要先找到你数据存储的目录;
2) 开始遍历(以规划切片)该目录下的每一个文件;
3) 遍历第一个文件a.txt
3.1) 先获取文件的大小;
3.2) 然后计算(或者说获取)切片的大小。这个是有计算公式的:
computeSplitSize = max(minSize, min(maxSize, blocksize))
minSize默认是1M,maxSize默认是Long型的最大值。
因此默认情况下,上面公式会计算出computeSplitSize = blocksize
这里我们发散一下,如果我想改大切片大小,比如说想让它等于256M,我该怎么办?
当然是修改minSize=256,上式可以自己算一下。
同理,如果是想改小切片大小,比如说等于64M,那就修改maxSize=64。
简单的说就是,如果想调小片大小,就修改MaxSize,如果想调大片大小,就修改MinSize。
3.3) 然后开始切片,比如说0~128是第一片,128~256是第二片;
这里也有个需要注意的点,就是每次切片的时候,都会判断切完后,该文件剩下的大小,是否大于blocksize(教程里写的是块大小,但是我感觉这里是不是对比的应该是切片大小,之后看源码来判断吧)的1.1倍,如果小于的话,那就不再切了,剩下的部分作为最后一块切片。反之则继续切。
3.4) 将切片的信息写到一个切片规划文件中;
这里的切片规划InputSplit, 只记录了切片的元数据信息,比如每一片的切片起始位置等,并不是真正的切了。
以上切片的核心过程,都是在FileInputFormat.getSplit()中完成;
4) 最后,Client提交切片规划文件给YARN,YRAN上的MrAPPMaster就会根据规划文件来计算所需的MapTask个数。
附一张教程里的图,可做辅助理解:
(91)FileInputFormat切片机制
默认的FileInputFormat切片机制流程,跟上一小节介绍的基本一样:
- 根据文件的内容长度开始切片;
- 切片大小等于block大小
- 切片时不考虑整体,而是对每一个文件分别切割;
这是默认情况下的一个切片机制, 并不是一成不变的。
举一个例子,假设我要处理20个文件,每个文件大小是1KB,当前blockSize=128M,按照上面的规则,对每一个文件分别切片,那就相当于1个文件一片,一共20片,对应的,我就要启动20个MapTask去执行读。
想象一下,就为了这20KB的数据,我需要耗费大量的时间和空间,去初始化并执行20个MapTask,这是非常不合理的,所以这种时候我们就可以打破默认的限制,将几个文件组合在一起来作为一片。这就是CombineTextInputFormat,这个后面会仔细讲。
教程在这里讲了一个基于FileInputFormat的实例,我也放上来吧。
假设现在有两个输入文件:
- file_1.txt,320M
- file_2.txt,10M
开始切片,形成的切片信息如下:
- file_1.txt.split_1:0~128M;
- file_1.txt.split_2:128~256M;
- file_1.txt.split_3:256~320M;
- file_2.txt.split_1:0~10M;
具体的切片流程,上一小节都讲过了,这里就不展开了,只记录一下,在代码里如何获取切片信息?
// 根据文件类型获取切片信息
FileSplit inputSplit = (FileSplit)context.getInputSplit();
//获取切片的文件名称
String name = inputSplit.getPath().getName();
(92)TextInputFormat及其他实现类一览
严格来讲,FileInputFormat是一个接口类,我们日常开发中常用的,还是它的那些接口实现类,比如说:TextInputFormat、KeyValueTextInputFormat、NLineInputFormat、CombineTextInputFormat和自定义InputFormat等。
其中用的最多的,是TextInputFormat和CombineTextInputFormat,所以教程里重点讲了一下这两种,尤其是后者,我就顺着教程来了。
看了下源码, 切片时还需要先判断文件是否可以切割,一般来讲,压缩文件是不能切割的。但是也不绝对,看你用的哪种压缩算法,有的压缩格式的文件倒是也能切,在后续的(123)压缩概述小节里会详细介绍下这些。
KeyValueTextInputFormat,是需要传入一个分隔符,然后拿着这个分隔符去切割输入的数据,切出来的0号位作为Key,剩下的部分作为value。
NLineInputFormat,是一次性读取多行,而TextInputFormat一次性只读取一行,这个区别很好理解,相当于是加强版,就不赘述了。
相当于对TextInputFormat来讲,一个10行的输入文本,它会对应生成10个KV对,但是对NLineInputFormat来讲,它可能只会生成2个KV对(假设它一次性读取5行),可能效率会高一些。
CombineTextInputFormat,是一次性读取多个文件进行组合,组合在一起进行后续的处理,比如说切片。非常适合小文件多的情况,避免了冗余MapTask。
TextInputFormat,就是一行一行读取文件,形成的输入KV对中,键就是该行在整个文件里的起始字节偏移量(我理解,作用跟行号差不多,但确实不是行号),值就是该行的内容,不包含换行和回车符。
以下是一个示例,比如,一个分片包含了如下4条文本记录。
Rich learning form
Intelligent learning engine
Learning more convenient
From the real demand for more close to the enterprise
每条记录在读取后,会表示为以下键值对:
(0,Rich learning form)
(20,Intelligent learning engine)
(49,Learning more convenient)
(74,From the real demand for more close to the enterprise)
(93) CombineTextInputFormat切片机制
原理
1)CombineTextInputFormat是用来解决小文件过多的问题。
上一小节提过,TextInputFormat是按照文件做切片的,一个文件,即使只有1KB,也会切成一片,从而开启一个单独的MapTask。在小文件过多的时候,这种对资源的浪费简直是不可想象的。
于是提出了CombineTextInputFormat,它可以把几个小文件在逻辑上分进同一个切片,这样子启动一个MapTask就可以了。
2) CombineTextInputFormat中,切片大小比较难理解,这个涉及到一个虚拟存储的概念。
CombineTextInputFormat.setMaxInputSplitSize(job, 默认大小);
CombineTextInputFormat生成切片的过程,也跟其他实现类不太一样,它是分为两个步骤:
- 虚拟存储过程
- 正式切片过程
案例讲解
接下来上一个实例来讲解,比如说要将文件按照字典数据排序。
假设,现在定义的CombineTextInputFormat的MaxInputSplitSize=4M,然后我们的输入数据是四个文件,分别是:
- a.txt,1.7M;
- b.txt,5.1M;
- c.txt,3.4M;
- d.txt,6.8M;
1) 首先会将文件,按照字典数据做排序,就是abcd,然后再开始切片, 这个排序直接影响了哪些文件会合在一起。
2) 接下来是虚拟存储过程:
- 对a.txt,由于1.7M < 4M ,即
MaxInputSplitSize,因此逻辑上划分为1块; - b.txt,由于4M < 5.1M < 2 * 4M,因此逻辑上均分为两块,第一块是2.55M,第二块也是2.55M;
- c.txt,由于3.4M < 4M,因此逻辑上划分为1块;
- d.txt,4M < 6.8M < 2 * 4M,因此逻辑上均分为两块,块1=3.4M,块2=3.4M;
然后虚拟存储结束,我们得到了以下虚拟分块:
1.7M
2.55M
2.55M
3.4M
3.4M
3.4M
3) 再接着,我们就可以开始规划切片了,这里切片的基本规则: 判断虚拟存储的文件大小是否大于MaxInputSplitSize,如果大于则单独成片,小于则组合下一个虚拟存储文件,直到大于MaxInputSplitSize,组合成片。
按照这个规则,我们可以得到以下三个切片:
片一:1.7M + 2.55M
片二:2.55M + 3.4M
片三:3.4M + 3.4M
弹幕里提了一个问题,假设我有一个10M的文件,那么按照上面的规则,是会划分成几个多大的虚拟存储文件?
确实是好问题,4M < 2 * 4M < 10M,我个人感觉是划分成 4M + 3M + 3M,即划分出第一块后,剩下6M重新开始判断,并最终均分为3M + 3M;
也有人说是划分成4M + 4M + 2M,感觉也有点道理,但还是更支持前面那种,先暂存一下,后来再查。
2023-10-15 12:08:08 后来忘记查了,我刚把这个问题问了下文心一言,它告诉我都行。。。两种方式都行。。。。
2023-10-15 12:11:13 查阅了下相关资料,应该是前者,先划分一块4M的出来,剩下的再跟MaxInputSplitSize去比较。合理。
MR代码在编写的时候,需要在Driver里定义以下代码:
// 如果不设置InputFormat,默认使用的是TextInputFormat.class
job.setInputFormatClass(CombineTextInputFormat.class);// 虚拟存储切片最大值设置4m
CombineTextInputFormat.setMaxInputSplitSize(job, 419304);
如果用以上代码来处理上一小节说的4个文件,从打印的日志里可以看到有3个切片:
number of split:3
就说明是3个切片。
参考文献
- 【尚硅谷大数据Hadoop教程,hadoop3.x搭建到集群调优,百万播放】
- 他来了他来了,Hadoop序列化和切片机制了解一下?







![[opencv]图像和特征点旋转](https://img-blog.csdnimg.cn/8e0a5d11a0b445929395d73ae74b3a8d.png)