1. 内联函数
1.1 C语言的宏
在C语言中,我们学习了用#define定义的宏函数,例如:
#define Add(x, y) ((x) + (y)) //两数相加
相较于函数,我们知道宏替换具有如下比较明显的优点:
- 性能优势: 宏在预处理阶段进行简单的文本替换,没有函数调用的开销,可以节省栈空间
- 灵活的参数: 宏的参数可以是任意表达式,包括副作用表达式。这使得宏能够以更灵活的方式进行代码替换,可以处理一些复杂的操作。
但是,对应的C语言的宏替换也有这些致命的缺陷:
- 不进行类型检查: 宏在进行文本替换时不进行类型检查,这可能导致一些潜在的类型错误。
- 没有作用域: 宏在预处理阶段进行文本替换,没有作用域的概念。如果宏的名称与其他标识符冲突,可能会导致错误或意外行为
- 不可随意调试: 在调试过程中,很难对宏展开后的代码进行单步调试,因为宏展开发生在预处理阶段,调试器无法直接查看宏的展开结果。
注:如果想对C语言的宏有更深的了解,建议看看👉C语言——预处理
1.2 内联函数
而为了解决C语言#define宏所带来的缺陷,C++有了inline关键字。
- 我们在函数的返回值类型前面加入
inline关键字,这个函数就成为了内联函数。 - 内联函数会在编译时被展开,从而避免了栈帧开销。
- 同时,内联函数又具有函数的特性。因此具有类型检查、作用域且方便调试。相较于宏函数更加安全。
- 可以说内联函数在具有宏函数优点同时也完全解决了宏函数所带来的缺陷。
例如:
inline void Func()
{printf("Hello World\n");
}int main()
{for (int i = 0; i < 100; i++)Func();return 0;
}
上面的代码我们声明了一个内联函数Func,在编译过后循环处的调用就会变成:
for (int i = 0; i < 100; i++)printf("Hello World\n"); //内联函数Func直接被展开成了函数体内的内容
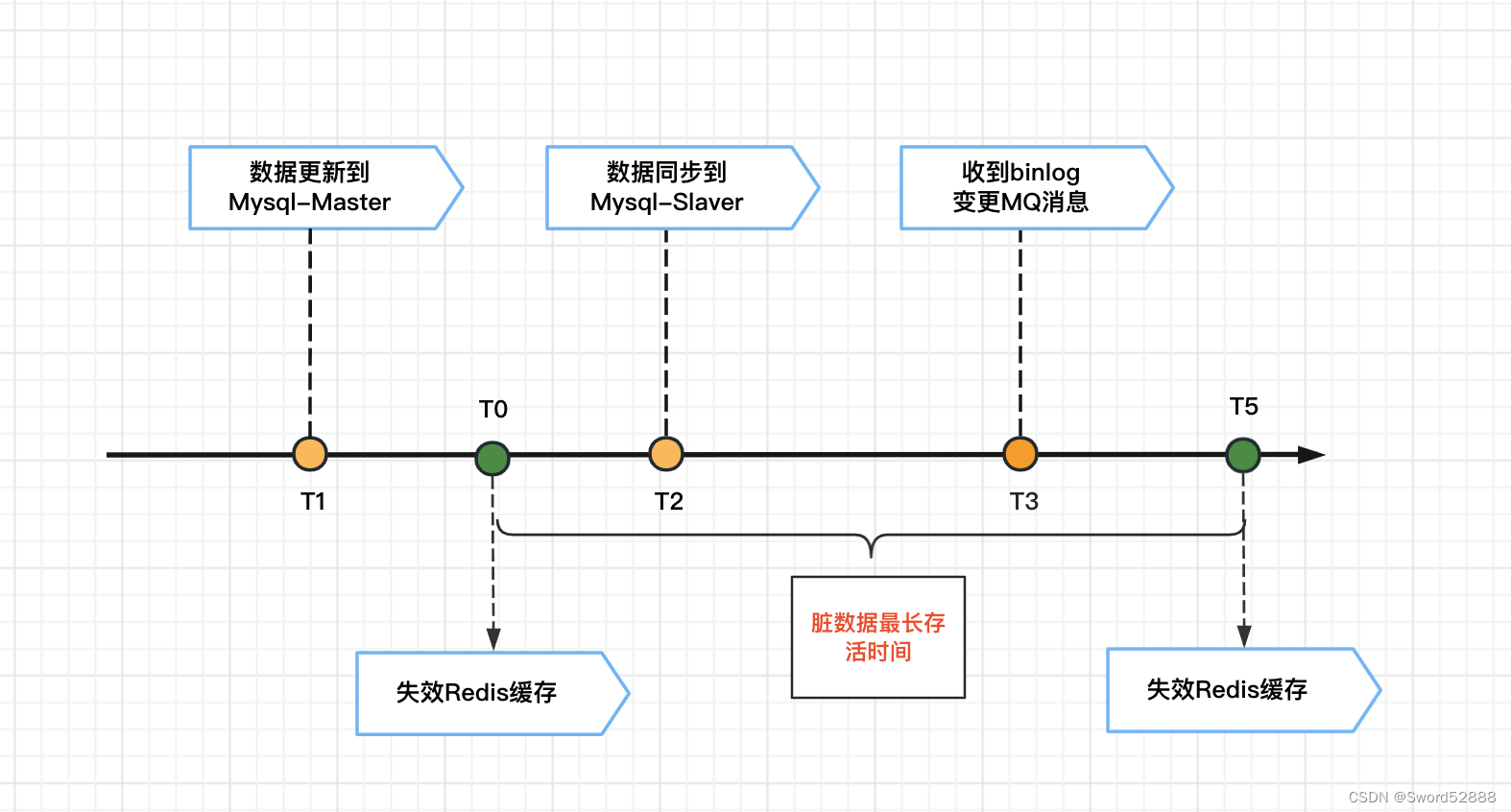
1.2.1 通过反汇编查看内联函数的展开
以VS2019为例:
首先,要用反汇编查看内联函数的展开,首先要对编译器做如下设置:
-
首先,将
Debug模式改为Release模式
-
然后,右击项目名称,点击属性
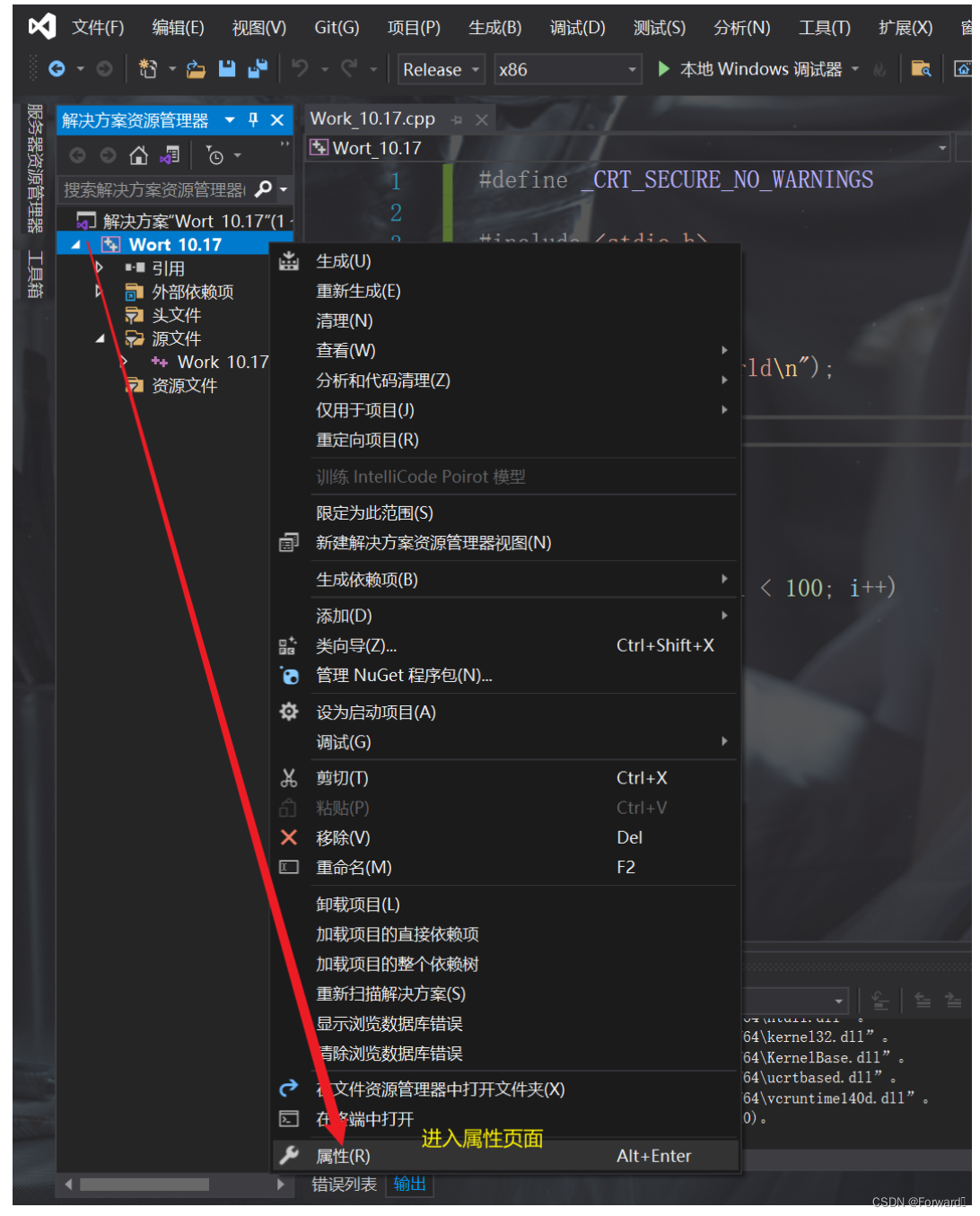
-
接着,配置属性-> C/C++ -> 常规 -> 调试信息格式 ->程序数据库
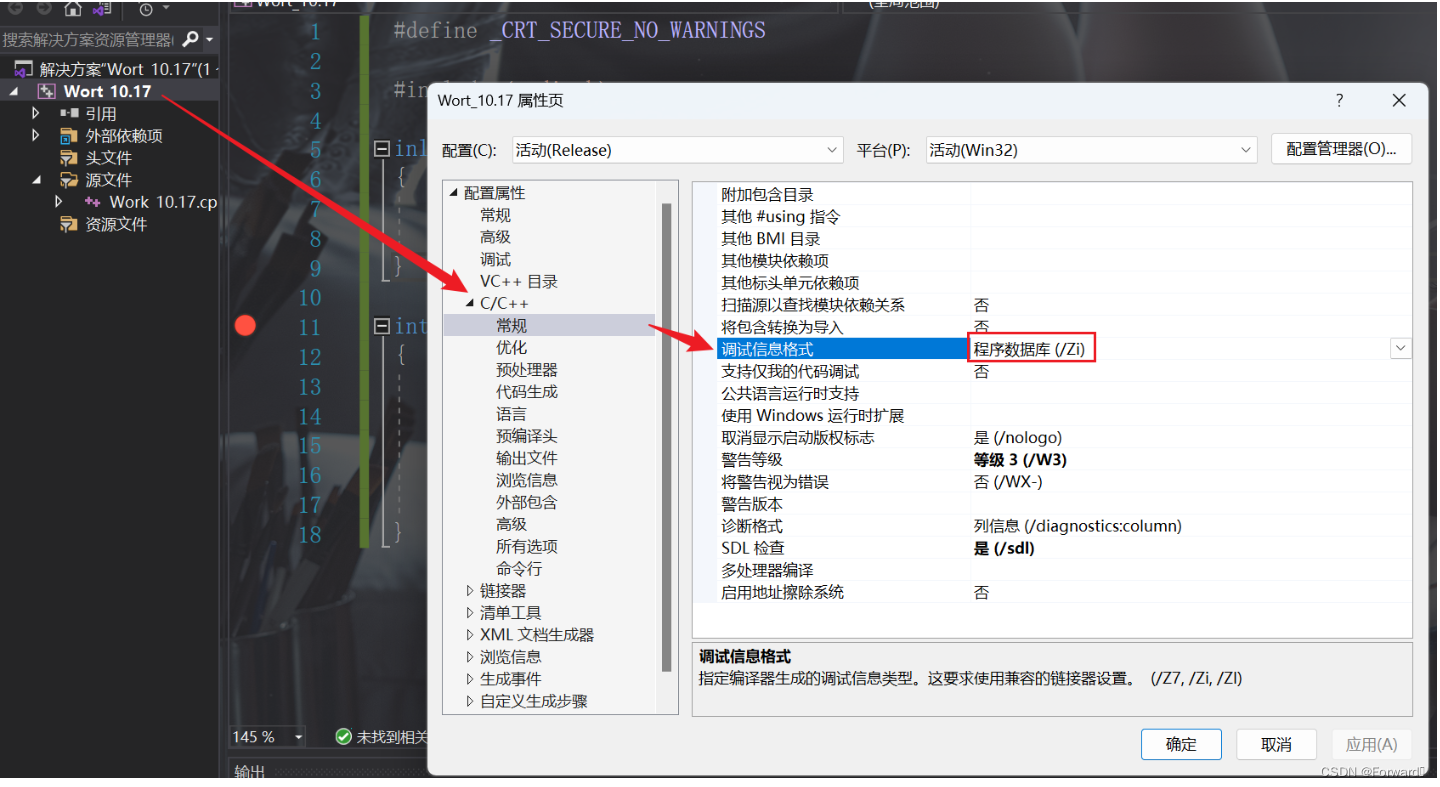
- 最后,配置属性-> C/C++ -> 优化 -> 内联函数扩展 -> 只适用于
_inline

设置完成过后,我们就可以通过返汇编查看内联函数的展开了。
-
我们先来看看没有加入
inline关键字的普通函数: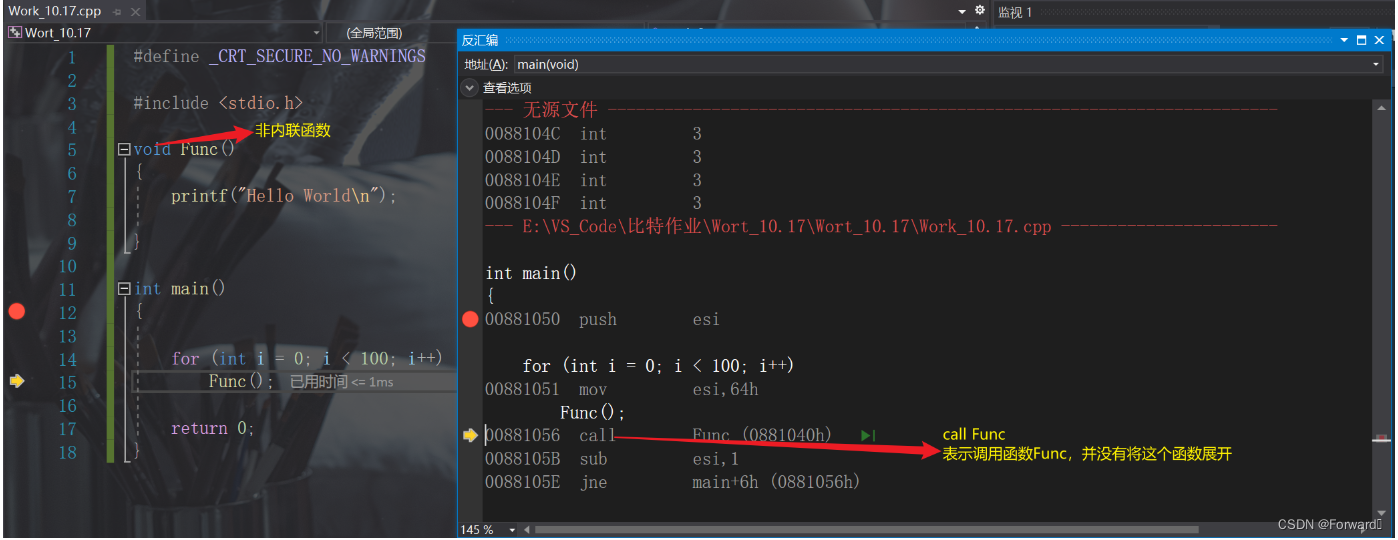
-
再来看看加入
inline关键字的内联函数: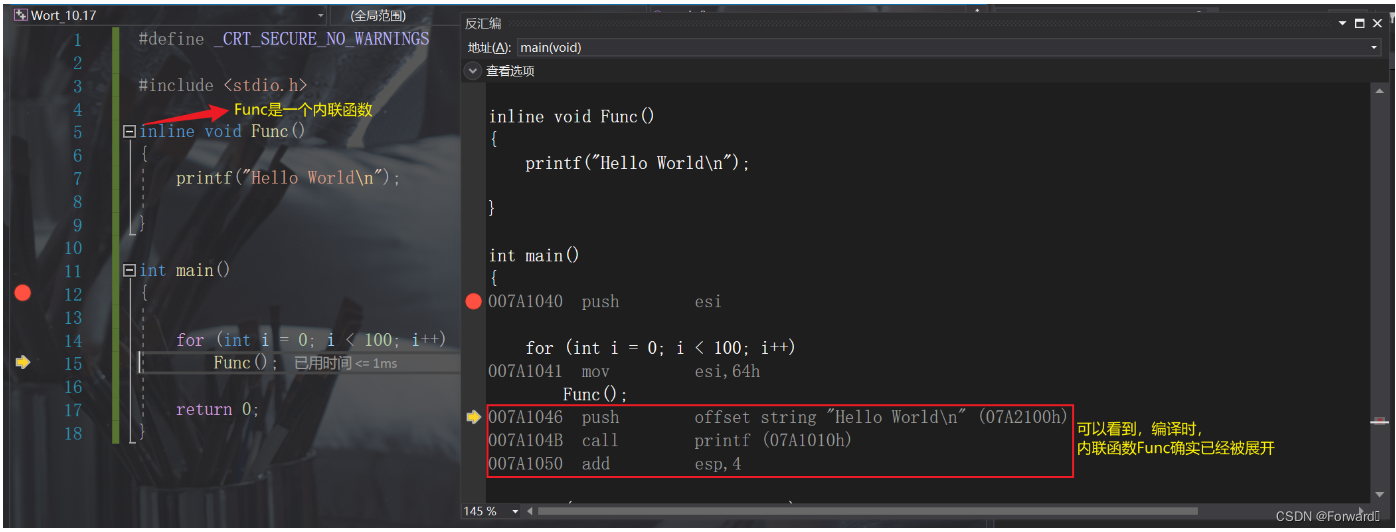
1.2.2 内联函数的局限性
既然内联函数可以避免栈帧开销而且安全性也有保证,那是不是可以说以后我们可以将所有的函数都定义成内联函数呢?
当然不可以!!!
首先我们来看一组对比:
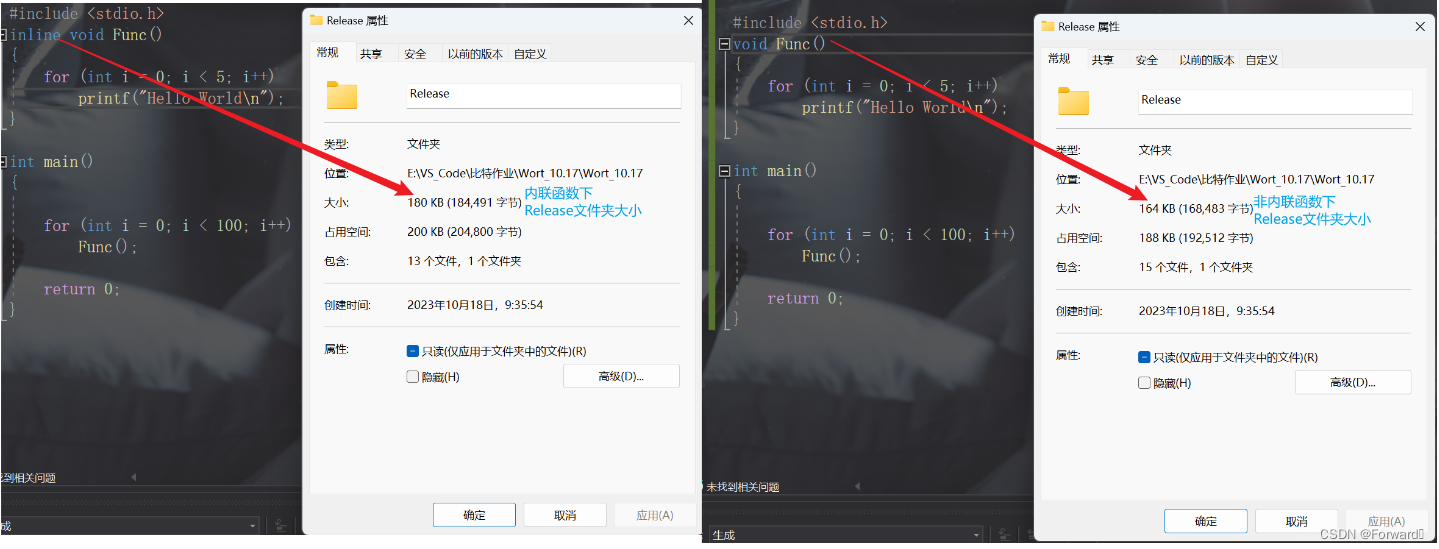
- 可以发现,不是内联函数的文件空间比是内联函数的文件空间小了16KB
- 有小伙伴就会问了:不就十几KB嘛,磁盘空间这么大不差这点。但是如果我将一个几百行的函数也写成一个内联函数,那这二者之间占用空间的差距就不会这么小了。
所以我们有必要清楚内联函数的局限,知道什么时候可以用,什么时候不可以用;
- 通过上面的分析和比较可以知道,
inline内联函数实际上是一种空间换时间的做法:通过代码的展开来减少函数调用的开销,但也因此导致了代码膨胀的问题。 - 因此内联函数一般用作代码简短(不超过10行),经常使用的函数。
- 而对于递归函数、存在大量循环的函数、存在
switch case语句的函数,一般不用inline处理
1.2.3 内联函数的特性
如果有人不听劝,将一个递归函数定义成内联函数,会出现什么情况呢?
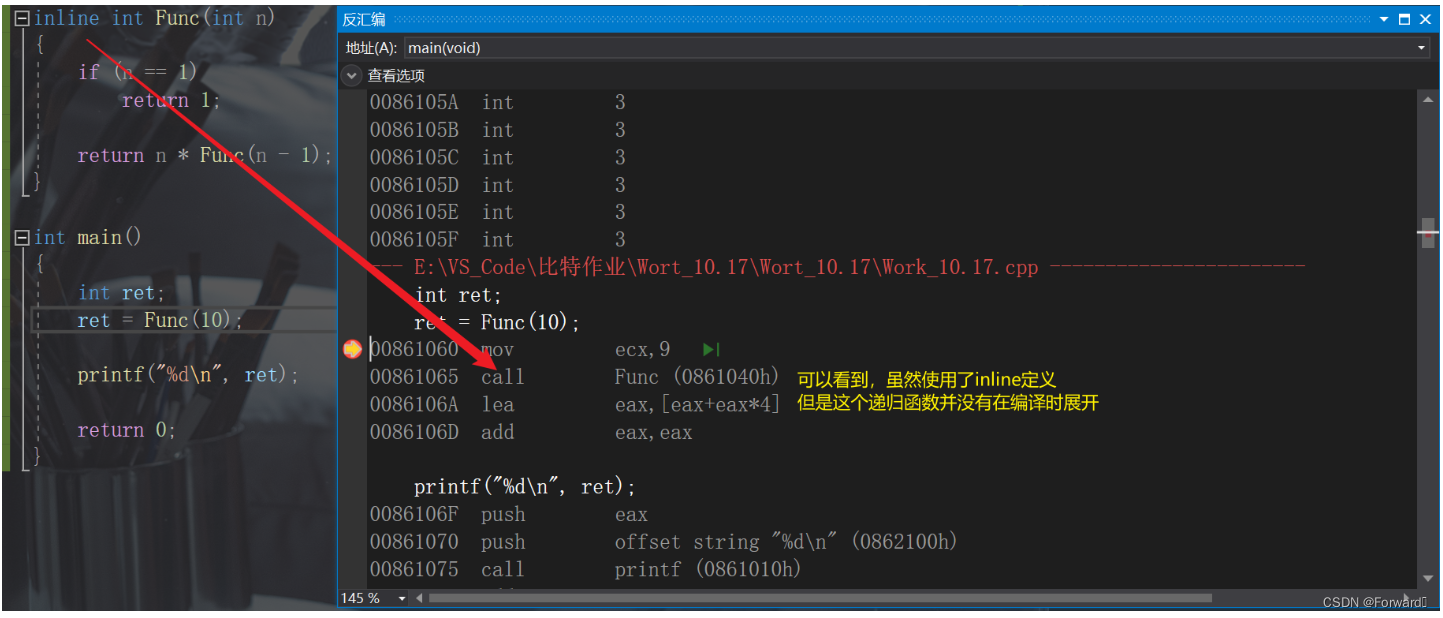
- 特性1:inline对于编译器而言只是一个建议,不同编译器关于inline实现机制可能不同,如果被定义的函数较为复杂,编译器会
忽略inline特性。 - 特性2:内联函数的声明和定义最好不要分离,否则就只能在定义内联函数的文件中使用该内联函数
1.3 总结
inline内联函数是C++专门针对C语言宏函数的缺陷而设计的。- 其既具有宏函数没有函数调用开销,所耗时间少的优点;同时也基本上解决了宏函数不安全、难以调试的缺点。其功能不可谓不强。
- 然而内联函数也有较大的局限性:其只适用于代码简单、且频繁调用的函数。而对于递归、有大量循环的函数则不适用。
- 内联函数只是对编译器的一个建议,到底才不采用取决于编译器。
- 内联函数的声明和定义最好放在一起。