文章目录
- 环境配置
- 页面
- 爬取流程
- 税案通报爬取
- code
- 税务新闻爬取
- 政策解读爬取
环境配置
python:3.7
requests:发出请求,返回页面
beautifulsoup:解析页面
time:及时
warnings:忽视警告
页面
网址:https://www.chinatax.gov.cn/n810346/n3504626/n3504648/index.html
本文的需求在于爬取“新闻发布”和“政策法规”下的页面
具体页面结构为
- 首页——新闻发布——税案通报
- 首页——新闻发布——税务新闻
- 首页——政策法规——政策解读
爬取流程
税案通报爬取
目标网址:https://www.chinatax.gov.cn/chinatax/n810219/c102025/common_listwyc.html
- 分析网页页面
属于典型的两段式爬取,每个页面有20篇文件,一共38页,分析页面url发现规律之后,只需要改变page={i},通过i的变化获取总url - 在网页源代码中发现每篇文件单独的
url都可以获取,任务相对比较简单。

- 编写代码获取每篇文件的url,之后提取文字内容即可。
code
import requests
import warnings
import time
from bs4 import BeautifulSoup
warnings.filterwarnings("ignore")def get_page(page):url = f"https://www.chinatax.gov.cn/chinatax/manuscriptList/n810724?_isAgg=0&_pageSize=20&_template=index&_channelName=%E7%A8%8E%E5%8A%A1%E6%96%B0%E9%97%BB&_keyWH=wenhao&page={page}"try: res = requests.get(url,verify = False)except:print(url)time.sleep(2)soup=BeautifulSoup(res.text,'html.parser') #BeautifulSoup中的方法#print(soup.find_all(name='div',attrs={"class":"title"})) #按照字典的形式给attrs参数赋值links = []for link in soup.find_all('a'): #遍历网页中所有的超链接(a标签)href = link.get('href') # 打印出所有包含href的元素的链接。'''if "http://www.chinatax.gov.cn/chinatax/n810219/n810724/c" in href:links.append(href)print(links)return links
for page in range(151,165):links = get_page(page)for id,li in enumerate(links):try:res = requests.get(li,verify = False)time.sleep(1)res.encoding = res.apparent_encodingsoup=BeautifulSoup(res.text,'html.parser') #BeautifulSoup中的方法title = soup.title.text.strip('\r\n ')print(title)with open(title +'.txt','w',encoding='utf-8') as f:for link in soup.find_all('p'):f.write(link.get_text()+'\n')except:print(li)
税务新闻爬取
目标网址:https://www.chinatax.gov.cn/chinatax/n810219/n810724/common_list_swxw.html
-
分析网页页面
属于典型的两段式爬取,每个页面有20篇文件,一共167页,分析页面url发现规律之后,只需要改变page={i},通过i的变化获取总url -
在网页源代码中发现每篇文件单独的
url都可以获取,任务相对比较简单。 -
编写代码获取每篇文件的
url,之后提取文字内容即可。和税案通报的爬取方式类似,更改初始url即可。 -
爬取结果
共爬取3188篇税务新闻文件,604篇税案通报文件。

政策解读爬取
目标网址:https://fgk.chinatax.gov.cn/zcfgk/c100015/list_zcjd.html
-
分析网页页面
属于典型的两段式爬取,每个页面有10篇文件,一共57页,分析页面url发现规律之后,只需要改变page={i},通过i的变化获取总url -
在网页源代码中发现无法观察到每篇文件单独的
url。
-
右键点击“检查”进入开发者模式,继续点击
Network——Fetch/XHR,之后刷新页面,发现右下角区域出现新文件,进行点击。
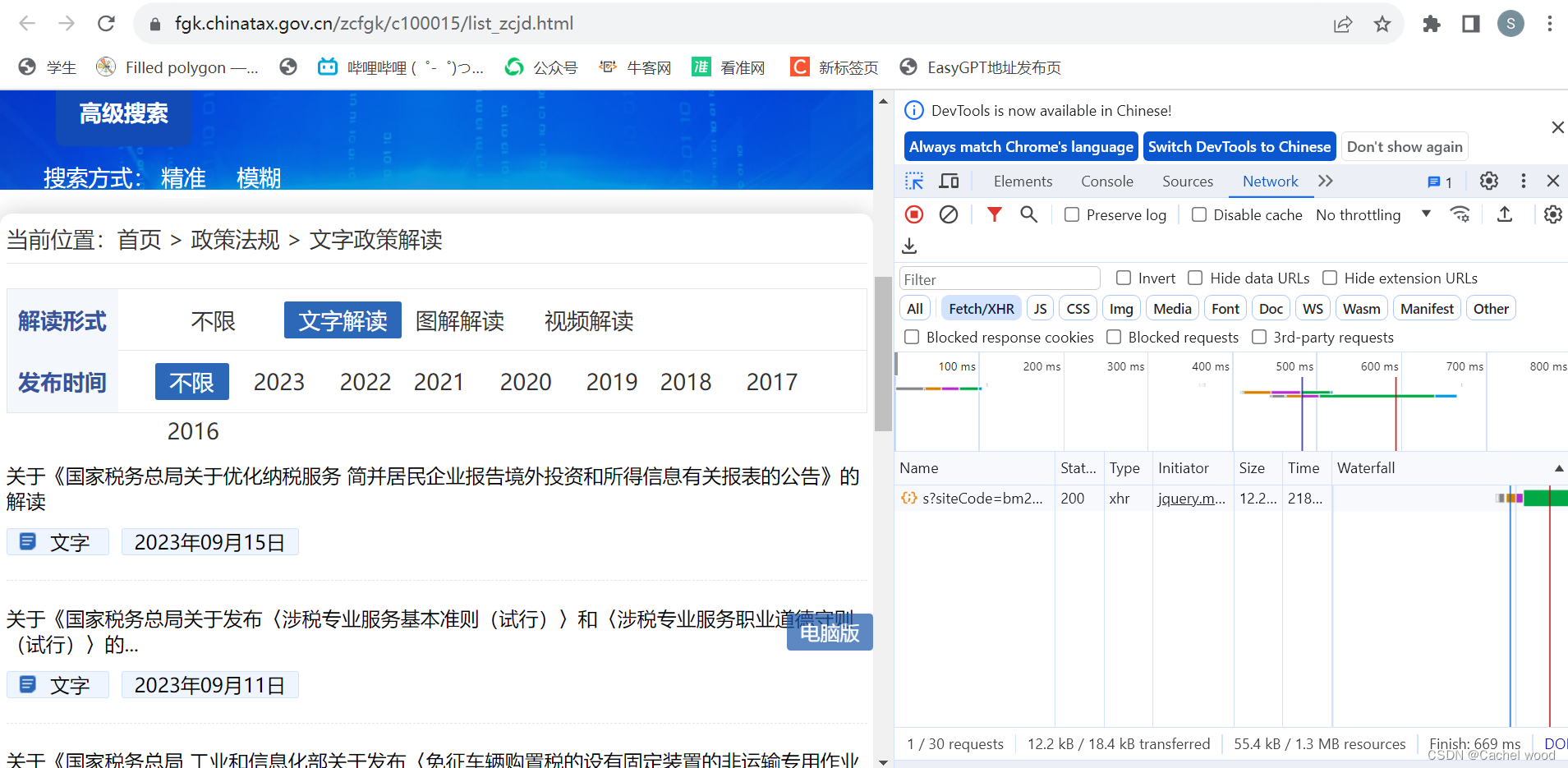
-
headers是页面基本信息,包括Request URL、Request Method、Status Code等等。
Preview是json格式的页面信息,Response是HTML格式的页面信息,可以发现单独文件的url在这里面都可以发现。
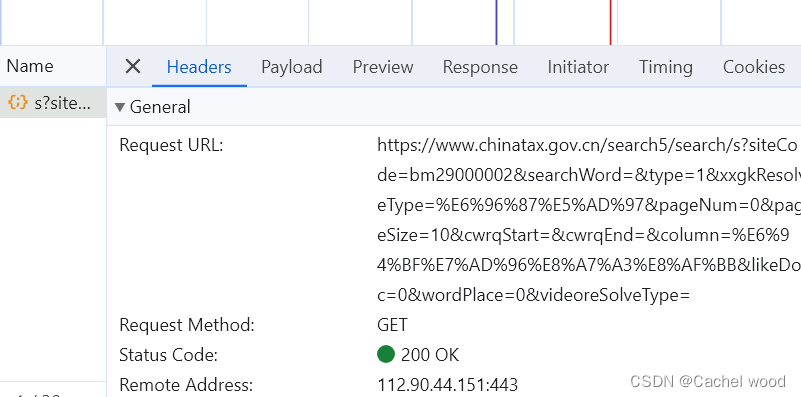
-
通过
Request URL请求网页信息,获取单独的文件url。- 将请求通过
json形式进行解析,可以获取文件网址url、标题title、内容content等许多信息。 - 但直接提取
content发现内容显示不全,因此还是需要两段式继续提取具体的文件信息。 - 将
url和content作为字典保存。
- 将请求通过
import requests
import warnings
import time
from bs4 import BeautifulSoup
warnings.filterwarnings("ignore")def get_page(page):url = f"https://www.chinatax.gov.cn/search5/search/s?siteCode=bm29000002&searchWord=&type=1&xxgkResolveType=%E6%96%87%E5%AD%97&pageNum={page}&pageSize=10&cwrqStart=&cwrqEnd=&column=%E6%94%BF%E7%AD%96%E8%A7%A3%E8%AF%BB&likeDoc=0&wordPlace=0&videoreSolveType="res = requests.get(url,verify = False)res.encoding = res.apparent_encodingtime.sleep(1)dic = {}for i in range(len(res.json()["searchResultAll"]["searchTotal"])):url = res.json()["searchResultAll"]["searchTotal"][i]["url"] #,sort_keys=True, indent=4, separators=(',', ': '))title = res.json()["searchResultAll"]["searchTotal"][i]["title"]#title = title.encode("utf-8").decode("unicode_escape")#url = json.dumps(content)["url"]#title = content["title"].encode("utf-8").decode("unicode_escape")#content = content.encode("utf-8").decode("unicode_escape")dic[url] = titleprint(dic)return dic
- 使用得到的
url提取,分析新文件的文本内容的分布位置,使用find_all进行爬取,将title作为文件标题
for page in range(1,57):dic = get_page(page)for key in dic:print(dic[key])print()res = requests.get(key,verify = False)res.encoding = res.apparent_encodingtime.sleep(1)soup=BeautifulSoup(res.text,'html.parser') #BeautifulSoup中的方法title = dic[key]with open(title +'.txt','w',encoding='utf-8') as f:for link in soup.find_all('p',style=True):styles = link.get('style', '').split(';') # 将style属性值拆分为一个列表 if ('display: none' not in styles) and ('display: inline-block' not in styles):print(link.get_text())f.write(link.get_text()+'\n')
- 发现可以提取文件,但有很多空文件。查看网页源代码发现不同文件的文本内容分布方式不同。根据发现的新分布更新find_all函数内容,继续爬取。
for page in range(1,57):dic = get_page(page)for key in dic:print(dic[key])print()res = requests.get(key,verify = False)res.encoding = res.apparent_encodingtime.sleep(1)soup=BeautifulSoup(res.text,'html.parser') #BeautifulSoup中的方法title = dic[key]with open('test/'+title+'.txt','w',encoding='utf-8') as f:for link in soup.find_all('p', attrs={'class': None}):#styles = link.get('style', '').split(';') # 将style属性值拆分为一个列表 #if ('display: none' not in styles) and ('display: inline-block' not in styles):print(link.get_text())f.write(link.get_text()+'\n')
- 爬取结果
共爬取558篇政策解读文件。