爬虫练手
把豆瓣的书评list页爬取下来,并获取其书名,和detail的连接地址
豆瓣的书评list的url地址, start=1,2,3,4…是其地址页
https://book.douban.com/top250?start=1
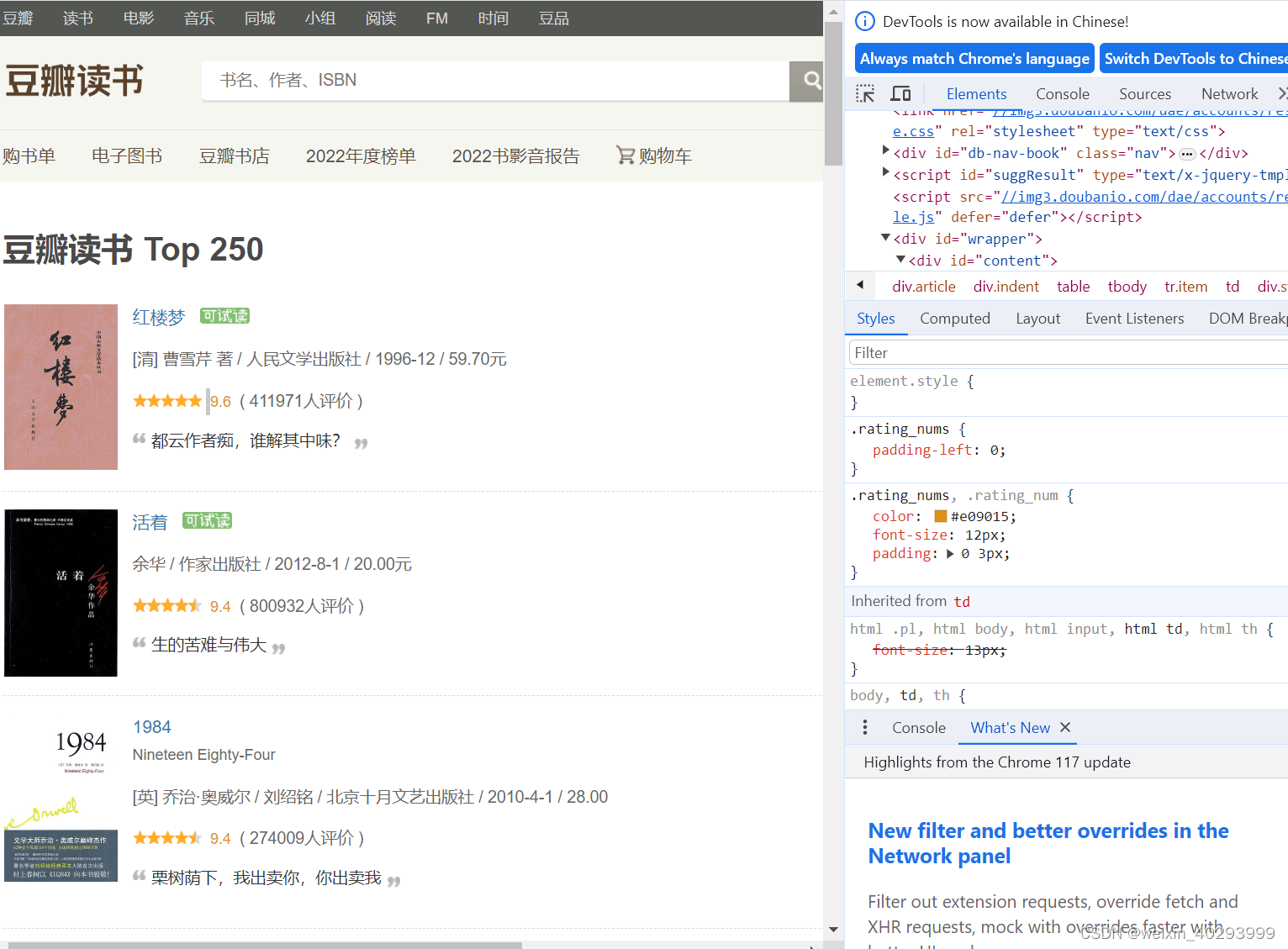
f12 观察其html结构
思路
按照找到的list的页面地址:
1.获取list页的html内容,
2. 解析html内容,
3. 获取title 和 detail页的href
简化问题
先搞第一页 https://book.douban.com/top250?start=1
user_agent 是告诉豆瓣的服务器,我就是浏览器啊
import requests
from bs4 import BeautifulSoup as bs
# 以上是添加必要的库header = {}
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36"
header["user-agent"] = user_agent
url = "https://book.douban.com/top250?start=1"
response = requests.get(url,headers=header)
# 以上是发送http的get请求,此时网页地址在 response对象里面
对返回的字符串进行解析,再次简化问题,只需要看返回列表的第一个
bs_info = bs(response.text,"html.parser")
# 返回所有的带class=pl2属性的div,返回一个列表,但只需要看第一个
abc =bs_info.find_all("div",attrs={"class":"pl2"})[0]
print(abc)
# 解析a,理解的 href 和title
atag = abc.find_all('a',)[0]
print("我是连接:",atag.get("href"))
print("我是题目:"+atag.get('title'))
pf =bs_info.find_all("span",attrs={"class":"rating_nums"})[0]
print("评分:",pf.getText())
pl =bs_info.find_all("span",attrs={"class":"pl"})[0]
# 评价人数
print("评价人数:",pl.getText())
<div class="pl2">
<a href="https://book.douban.com/subject/4913064/" onclick=""moreurl(this,{i:'0'})"" title="活着">活着</a><img alt="可试读" src="/pics/read.gif" title="可试读"/>
</div>
我是连接: https://book.douban.com/subject/4913064/
我是题目:活着
评分: 9.4
评价人数: (800932人评价)
拓展
同学们自己写个对page 的循环, 已经对每页的list的循环,自己拼接完成吧,很好做的。
爬虫以外
做api调用的时候,可以在http头中携带信息,追加调用链:
在请求发起侧增加了 A-Bbb的信息, server端就收到了。
import requests
header = {"A-Bbb":"aaa"}
url= "http://httpbin.org/get"
url = 'http://127.0.0.1:5000/'
r = requests.get(url,headers = header)
r.headers
(base) D:\code\python_project\01-jk-yhs-python>C:/ProgramData/Anaconda3/python.exe d:/code/python_project/01-jk-yhs-python/aa.py* Serving Flask app "aa" (lazy loading)* Environment: productionWARNING: This is a development server. Do not use it in a production deployment.Use a production WSGI server instead.* Debug mode: off* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
Host: 127.0.0.1:5000
User-Agent: python-requests/2.27.1
Accept-Encoding: gzip, deflate, br
Accept: */*
Connection: keep-alive
A-Bbb: aaa







![[C国演义] 第十六章](https://img-blog.csdnimg.cn/407d2b427b824416adf77fbe1aa97e21.png)

![[Leetcode] 0035. 搜索插入位置](https://img-blog.csdnimg.cn/img_convert/7252a9407bf17cafdc3d9d1c92dcaadb.png)