1 HDF5文件
- HDF5 是 Hierarchical Data Format version 5 的缩写,是一种用于存储和管理大量数据的文件格式
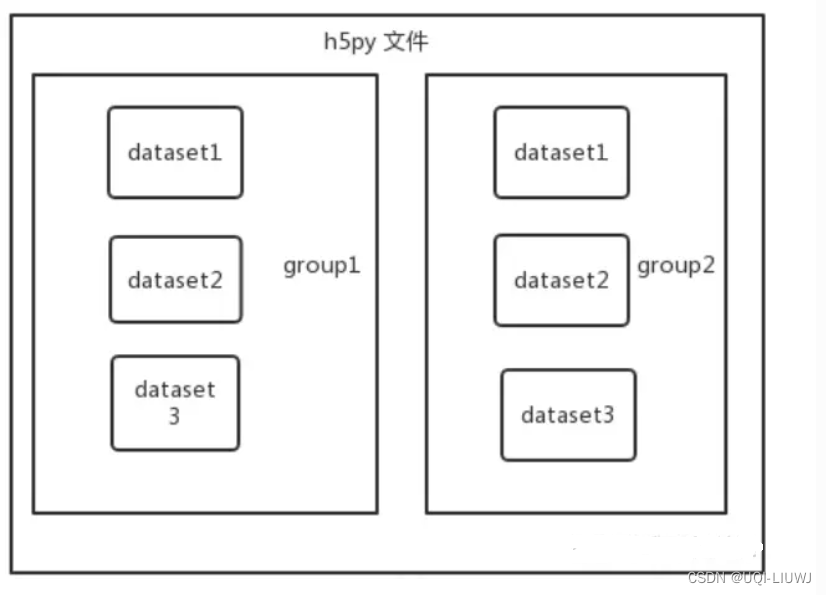
- 一个h5py文件可以看作是 “dataset” 和 “group” 二合一的容器
- dataset : 数据集,像 numpy 数组一样工作
- group : 包含了其它 dataset 和 其它 group
2 读取文件
以t2vec的 data/porto-vocab-dist-cell100.h5 为例
import h5py
import numpy as npdata_dir='/home/ruizhichai/t2vec/data/porto-vocab-dist-cell100.h5'file=h5py.File(data_dir,'r')
#打开文件2.1 keys:获取h5文件中所有组和数据集的名称
file.keys()
#<KeysViewHDF5 ['D', 'V']>2.2 visit:根据指定的函数来遍历.h5文件的组和数据集
file.visit(lambda x: print(x))
'''
D
V
'''2.3 读取每个数据集的内容
file['D'][:].shape,file['D'][:]
'''
((18866, 10),array([[ 0. , 0. , 0. , ..., 0. ,0. , 0. ],[ 0. , 0. , 0. , ..., 0. ,0. , 0. ],[ 0. , 0. , 0. , ..., 0. ,0. , 0. ],...,[ 412.31056256, 400. , 316.22776602, ..., 223.60679775,141.42135624, 200. ],[1486.60687473, 1389.24439894, 1476.48230602, ..., 447.2135955 ,100. , 0. ],[ 761.57731059, 707.10678119, 670.82039325, ..., 100. ,0. , 200. ]]))
'''3 写HDF5文件
data_dir='tst.h5'file=h5py.File(data_dir,'w')
3.1 创建组
grp_1=file.create_group('group_1')
grp_2=file.create_group('group_2')3.2 向组/file根目录写文件
lst1=np.arange(10)
lst2=np.arange(5,8)
lst3=np.arange(6,10,2)grp_1.create_dataset("lst1",data=lst1)
grp_2.create_dataset("lst2",data=lst2)
file.create_dataset("lst3",data=lst3)file.keys()
#<KeysViewHDF5 ['group_1', 'group_2', 'lst3']>file['group_1'].keys()
#<KeysViewHDF5 ['lst1']>file['group_1']['lst1'][:]
#array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])

![SHCTF 山河CTF Reverse方向[Week1]全WP 详解](https://img-blog.csdnimg.cn/2d40c31e10b54238b566420c750bb564.png)