ByteBuffer是字节缓冲区,主要用户读取和缓存字节数据,多用于网络编程,原生的类,存在不好用,Netty采用自己的ByteBuff,对其进行了改进
1.ByteBuffer的2种创建方式
1.ByteBuffer buf = ByteBuffer.allocate(int size);
方式1的buf缓冲区存储在堆内存中,内存开销在JVM中,受GC影响,会多拷贝一次,因为java程序收到的数据首先被系统内存所获取,然后再拷贝给JVM
2.ByteBuffer buf = ByteBuffer.allocateDirect(int size);
方式2的buf在系统直接内存中创建,内存开销在JVM之外,读写效率高(不受GC影响,0拷贝),但是分配效率低,使用后若不释放,会造成内存泄漏
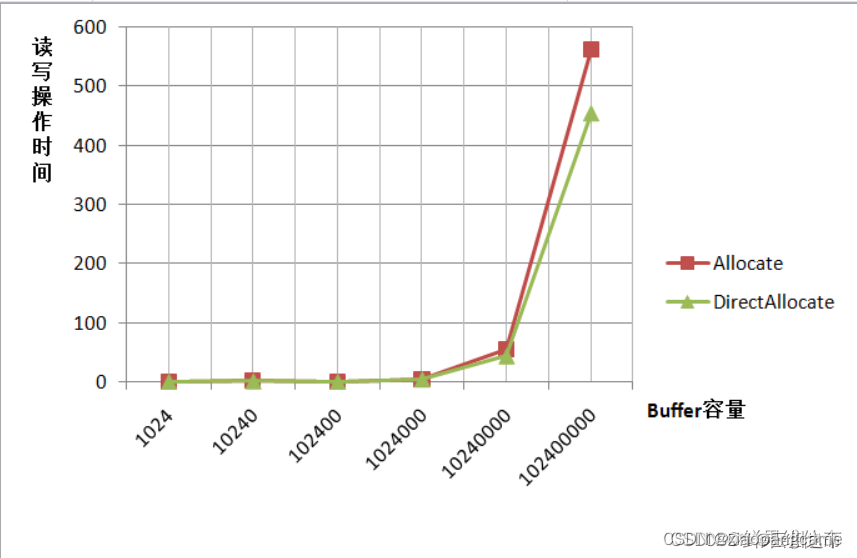
下图是不同容量情况下,两种ByteBuffer的读写效率,根据需求选择创建方式:
2.字符串转成ByteBuffer的3三种方式
方式1: 采用put()方法,读数据时需要调用flip()切换为读模式
ByteBuffer buf = ByteBuffer.allocate(int size);buf.put(msg.getBytes());
方式2:以特定编码格式将String转换为ByteBuffer
ByteBuffer buffer1 = StandardCharsets.UTF_8.encode("hello");
方式3:调用ByteBuffer.wrap()
ByteBuffer buf = ByteBuffer.wrap(msg.getBytes());
3.Bytebuffer的读写底层原理
Bytebuffer的数据读写主要采用三个参数来控制
1.position:起始下标
2.limit:限制下标
3.capacity:buffer的容量
核心思想:Bytebuffer的读写共用position、limit参数,因此需要切换至读模式(调用flip())和写模式(调用)
一.开始时,position指向0,limit指向capacity
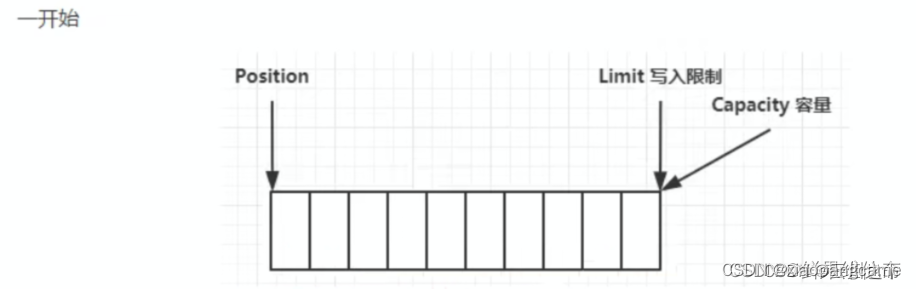
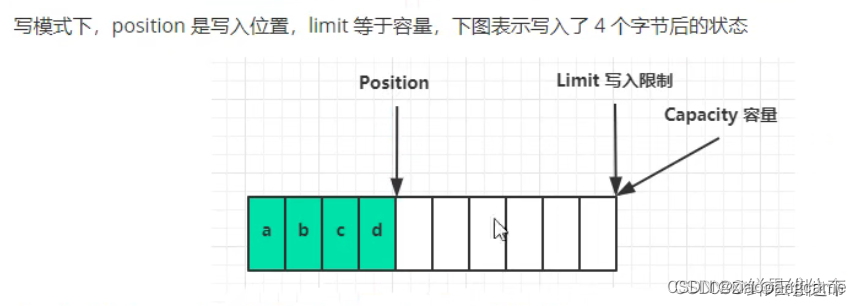
二.写模式下,写数据时,Position会不断前移
三.调用flip()切换为读模式,此时Postion置为已有数据的起始下标,limit置为已有数据的末尾下标
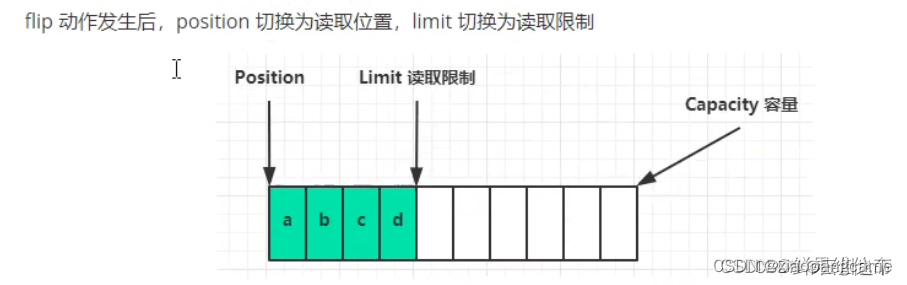
四.调用clear()方法切换为写模式,采用清空缓冲区,将potision置为0,limit置为capacity
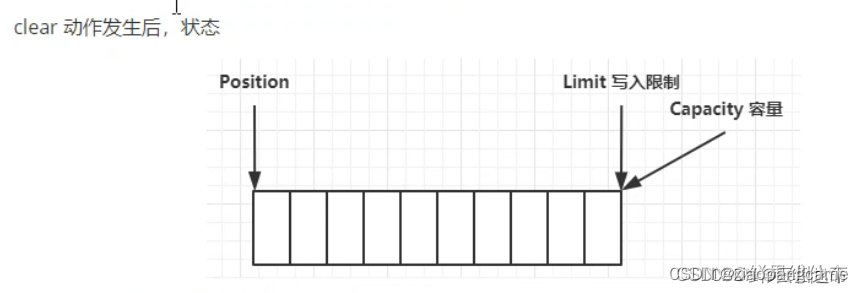
至此,我们知道读写模式由于共用相同的position等参数,因此,需要切换模式,才能正确的读写。
并且在发生一次写读(先写后读)切换后,需要调用clear()方法进行重置,才能进行一轮新的写读
当然,你可以连续写或连续读,读读或写写可以连续执行,不需要额外操作。例如:
ByteBuffer buf = ByteBuffer.allocate(int size);buf.put(msg.getBytes()); //okbuf.put(msg2.getBytes()); //ok
存在的问题:
读操作后,重新写,调用clear()会重置至0的问题,如果没有读完呢?
例如 存在接收到的数据是不完整的,无法进行读操作,那么需要在原来的基础上,继续写数据怎么办?
答案是 Buffer.compact() 切换到写入模式
五. 调用compact方法切换为写模式,在不清空缓冲区的前提下,继续写如信息,将未读取的数据前移,postion指针置为未读取数据的末尾下标,limit置为capacity
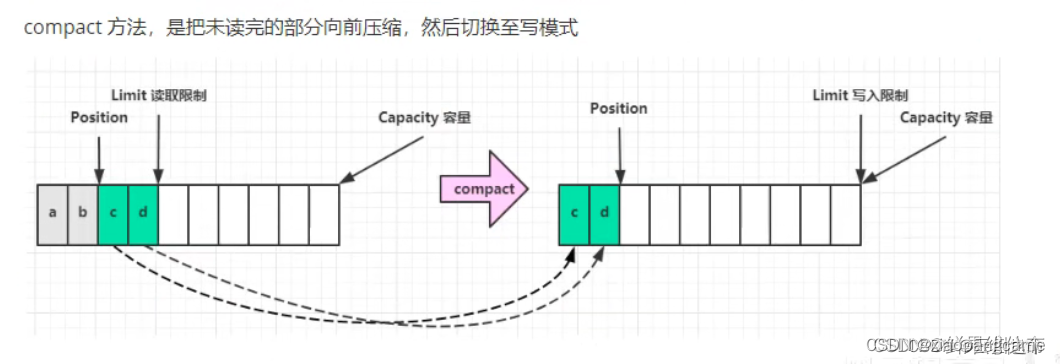
上图左侧灰色是已读部分数据,绿色是未读部分,在此基础上,调用compact继续写,会进行部分清楚操作,同时保留未读部分,这也是推荐的用法。