本文导读:
数智时代的到来使网络安全成为了不可忽视的重要领域。奇安信作为一家领先的网络安全解决方案领军者,致力于为企业提供先进全面的网络安全保护,其日志分析系统在网络安全中发挥着关键作用,通过对运行日志数据的深入分析,能够对漏洞和异常行为生成关键见解,帮助企业建立有效的防御策略。本文将深入探讨奇安信在网络安全与日志分析解决方案的关键优势,了解基于 Apache Doris 构建的全新一体化日志存储分析平台如何实时监测和分析日志事件,加强对可疑活动的追踪与应对,提升系统安全性与快速响应能力。
作者|奇安信 服务端技术专家 舒鹏
奇安信是中国企业级网络安全市场的领军者,专注于为政府和企业用户提供新一代网络安全产品和服务。目前核心产品天擎终端安全系统在国内已有 4000 万政企用户部署、全国部署服务器超过 100 万台、服务超 40 万大型机构。作为网络安全国家队,奇安信立志为国家构建安全的网络空间,在终端安全、云安全、威胁情报、态势感知等领域的技术研发持续领先。
随着现代企业数字化转型的不断深化,大数据、物联网、5G 等创新技术的广泛应用加速了企业的数字化转型步伐,这使得原先的网络边界被打破,多源多样的终端设备成为了新的安全边界。
网络安全系统的防御性能与日志分析密不可分,当网络设备、操作系统以及应用程序在运行时,会产生大量的运行日志,其中蕴涵了丰富的数据价值。最大化地利用运行日志数据能够有效检测内部系统的安全风险、还原攻击路径、回溯攻击入口等,可以进一步提升系统安全性、保障企业网络安全,因此日志分析系统在其中发挥着不可或缺的作用。
本文将介绍奇安信在网络安全场景中,基于 Apache Doris 进行架构升级迭代并建设全新一体化日志存储分析平台的实践经验。
早期架构痛点与需求
安全日志平台的架构如下图所示,原始的设备、系统日志首先经过业务处理环节,包括归一化和扩充维度等操作。这些处理步骤旨在将来自不同设备和系统日志转化为半结构化 JSON 格式的安全日志,并将其写入 Kafka 消息队列中。
最新的日志会被写入实时数仓,安全分析师可以通过分析平台对实时数仓中的最新数据进行交互式查询,从而进行攻击研判和追踪溯源等安全分析工作。另外,离线数仓用于保存历史数据,以支持长周期数据挖掘的离线分析。
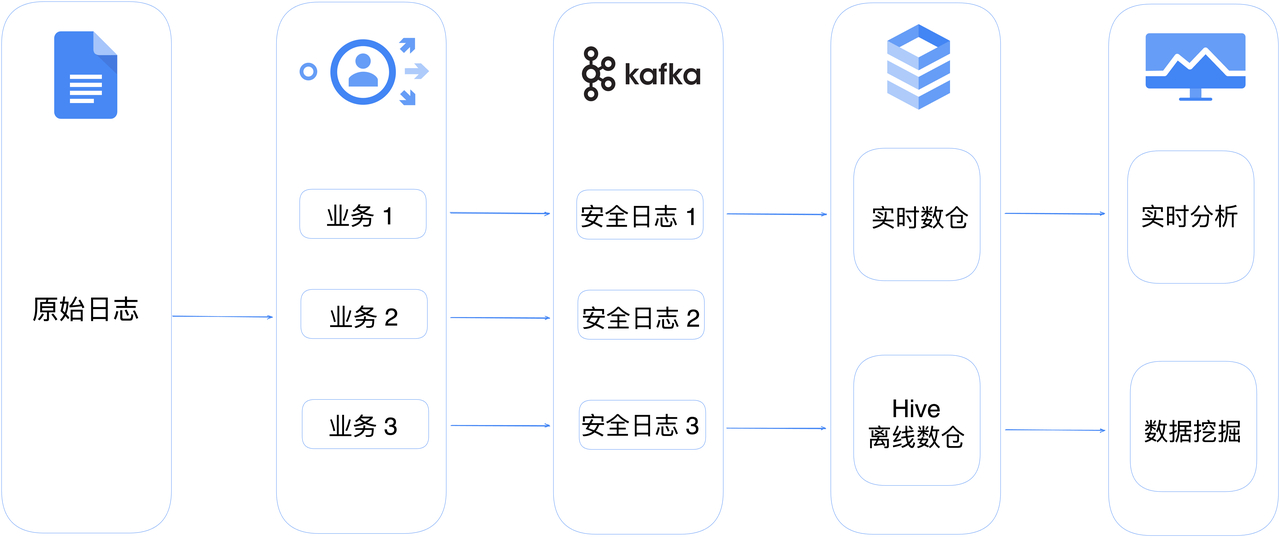
在以上日志数据平台中,日志数据的写入速度与查询分析效率对上层业务人员进行实时安全事件监控和分析至关重要,这也是当前我们所面对的最主要痛点。
一方面,每天所生产的安全日志数据达到千亿级,写入压力很大。最初我们选择使用某 Apache Doris 的 Fork 版本来存储日志数据,但在实际应用中,随着每天新增日志量的不断增长,入库速度逐渐降低、集群写入压力过大、高峰期数据积压严重,对集群稳定性造成很大影响,并且数据压力较高时、查询效率也达不到有效果的保证。随后我们对集群进行多次扩容,从 3 节点逐步扩容到 13 节点,尽管机器成本已经大幅超过预期、但写入效率并没有发生本质的改善。
另一方面,业务人员在进行安全日志分析时,经常需要对文本字段(如 URL,payload 等)进行关键字匹配。在原系统中只能通过 SQL LIKE 进行全量扫描和暴力匹配,整体查询性能不佳,千亿级数量的数据表查询耗时接近分钟级甚至达到数百秒,即便按照时间区间过滤大量数据后、查询耗时仍在数秒到数十秒。一旦遇到并发查询性能还会进一步恶化,很难满足日常安全分析的需求。
除写入和查询效率以外,运维监控也是我们的痛点之一,该厂商提供的可视化运维系统需要商业 License 授权,对于开源社区用户不友好,集群维护处于原始手动状态。
架构选型与升级的思考
为了解决过去版本的痛点、满足更高效实时的日志分析诉求,我们亟需对早期系统升级改造。同时面向安全日志分析场景,我们也对新日志分析平台的架构提出了更高的要求:
-
写入性能:系统一方面需要支持海量病毒查杀事件等数据实时写入与存储,以满足分析时效性的要求,另一方面需要基于日志数据 Schema Free 特点支持丰富数据类型的写入与变更。
-
查询性能:由于日志查询分析会涉及对文本类型、JSON 数据进行全文检索、日期或普通数值的范围查询,系统需要对字符串提供模糊查询的能力,还需要支持能够灵活创建且类型丰富的索引,以加速筛选过滤海量数据,提升查询效率。
-
存储成本:设备每天产生大量的日志数据,为了挖掘这些有价值的日志信息,业务人员还需要从数据中进行筛选和分析,并对异常日志回溯追踪,这使得日志存储的规模很大、存储周期相对较长,因此高性价比的存储成本也是系统构建的目标之一。
-
运维成本:系统自身的运维简易程度以及是否具备合适的管控工具都能帮助我们进一步提效。
在持续关注业界 OLAP 数据库的过程中,我们发现 Apache Doris 最近一年的发展非常迅猛,最新的 2.0 版本也把日志存储和检索分析作为新的发力点,推出了倒排索引、NGram BloomFilter 索引等特性,对关键词检索、LIKE 文本匹配的性能有大幅提升,与我们文本检索慢的痛点需求非常契合,因此开启了新架构的升级之旅。
架构升级之旅
上文中提到,在整体架构选型过程中我们主要关注的地方包括写入性能、查询性能、数据存储成本以及运维成本等方面。在架构升级过程中,我们选择了 Apache Doris 当时最新发布的 2.0 版本,具体升级收益如下。
01 写入性能提升超 200%
为了评估 Apache Doris 写入的极限性能,我们初期使用与线上系统相同配置的 3 台服务器,从 Kafka 接入线上真实写入流量,测试期间当 CPU 写入效率跑满至 100% 时写入吞吐达到了 108 万条/s、1.15 GB/s,写入数据的可见性延迟保持在秒级。
而线上运行的原系统集群规模达 13 台,在同样的数据写入情况下,CPU 利用率 30% 左右、写入吞吐仅 30 万条/s,并且存在高峰期 CPU Load 高、系统响应慢的问题。
根据测试结果,我们预估架构替换为 Apache Doris 后保持同样 30% 的 CPU 占用,只需要 3 台服务器即可满足写入需求,机器资源成本至少节约 70%。值得注意的是,在测试中对 Apache Doris 表中一半字段开启了倒排索引,如果不开启倒排索引的话,写入性能在之前基础上还能够再提升 50% 左右。
02 存储成本降低近 40%
在看到写入性能的大幅提升后,Apache Doris 存储空间占用也给我们带来了惊喜。在开启倒排索引的前提下,存储空间比原系统不具备倒排索引还要略低,压缩比从 1 : 4.3 提高至 1 : 5.7。
通过对比 Apache Doris 在磁盘上存储的文件大小,同一份数据的索引文件(.idx)与数据文件(.dat) 大小相差无几。换言而之,增加索引后 Doris 数据膨胀率大约在 1 倍左右,与许多数据库和检索引擎 3-5 倍的膨胀率相比,Doris 的数据存储空间占用相对较低。经过研究发现,Apache Doris 采用了列式存储和 ZSTD 压缩算法来优化存储空间占用。Doris 将原始数据和倒排索引都以列的形式存储,使同一列的数据被存储在相邻位置,从而实现了更高的压缩率。
ZSTD 是一个优秀的新型压缩算法,使用了智能优化算法,相较于常见的 GZIP 算法, ZSTD 具有更高的压缩率和更快的解压速度,尤其在处理日志场景时表现非常出色。
03 查询性能平均提升 690%
对于业务最关注的查询性能,我们从线上查询日志进行去重后分析出 79 条 SQL,在同一天总数据(1000 亿条)、同样规模的集群(10 BE 节点)上对比测试 Apache Doris 与原系统的查询耗时。
我们发现,与原系统相比,所有的查询语句均有明显提升,整体查询性能提升近 7 倍,有 26 条 SQL 查询语句性能提升 10 倍以上,其中 8 条 SQL 查询提升 10-20 倍、14 条 SQL 查询提升 20-50 倍、还有 4 条 SQL 查询提升 50 倍以上。最大差异的一条 SQL 查询语句为 Q43,在原系统中执行时间接近一分钟,在 Apache Doris 中仅需不到 1 秒,其性能差异高达到 88 倍。

针对性能提升幅度高的查询,我们进行了对比分析并发现了其中几个共同点:
倒排索引对关键词查找的加速:Q23、Q24、Q30、Q31、Q42、Q43、Q50 等
1 -- 例如q43 提升88.2倍
2
3 SELECT count() from table2
4 WHERE ( event_time >= 1693065600000 and event_time < 1693152000000)
5 AND (rule_hit_big MATCH 'xxxx');这种基于倒排索引进行关键词检索的技术,相较于基本的暴力扫描后进行文本匹配具有显著的优势,一方面极大地减少了需要读取的数据量;另一方面,在查询过程中无需进行文本匹配操作,因此查询效率往往提升一个数量级甚至更高。
NGram BloomFilter索引对 LIKE 的加速:Q75、Q76、Q77、Q78 等
1 -- 例如q75 提升44.4倍
2
3 SELECT * FROM table1
4 WHERE ent_id = 'xxxxx'
5 AND event_date = '2023-08-27'
6 AND file_level = 70
7 AND rule_group_id LIKE 'adid:%'
8 ORDER BY event_time LIMIT 100;对于要查找的非一个完整关键词的场景,LIKE 仍然是有用的查询方式,Apache Doris 的 NGram BloomFilter 索引能对常规的 LIKE 进行加速。
NGram BloomFilter 索引与普通 BloomFilter 索引不同,它不是将整个文本放入 BloomFilter ,而是将文本分成连续的子串,每个子串长度为 n ,并将他们放入 NGram BloomFilter 中。对于 cola LIKE '%pattern%' 的查询,将'pattern'按照同样的方式分成长度为 n 的子串,判断每个子串在 BloomFilter 中是否存在,如果有一个子串不存在,则说明 BloomFilter 对应的数据块中没有跟'pattern'匹配的数据块,因此通过跳过数据块扫描的步骤,达到加速查询的效果。
满足条件的最新 TopN 条日志明细查询优化:Q19-Q29 等
1 -- 例如q22,提升50.3倍
2
3 SELECT * FROM table1
4 where event_date = '2023-08-27' and file_level = 70
5 and ent_id = 'nnnnnnn' and file_name = 'xxx.exe'
6 order by event_time limit 100;这种SELECT * FROM t WHERE xxx ORDER BY xx LIMIT n 的查询,在查找满足某种条件的最新 n 条日志时使用频率非常高,Apache Doris 针对这种 SQL 查询模式进行了专门的优化,根据查询的中间状态确定排序字段的动态范围,并利用自动动态谓词下推的方式,避免读全部数据进行排序取 TopN,从而减少需要读取的数据量(有时甚至可以减少一个数量级),进而提升了查询效率。
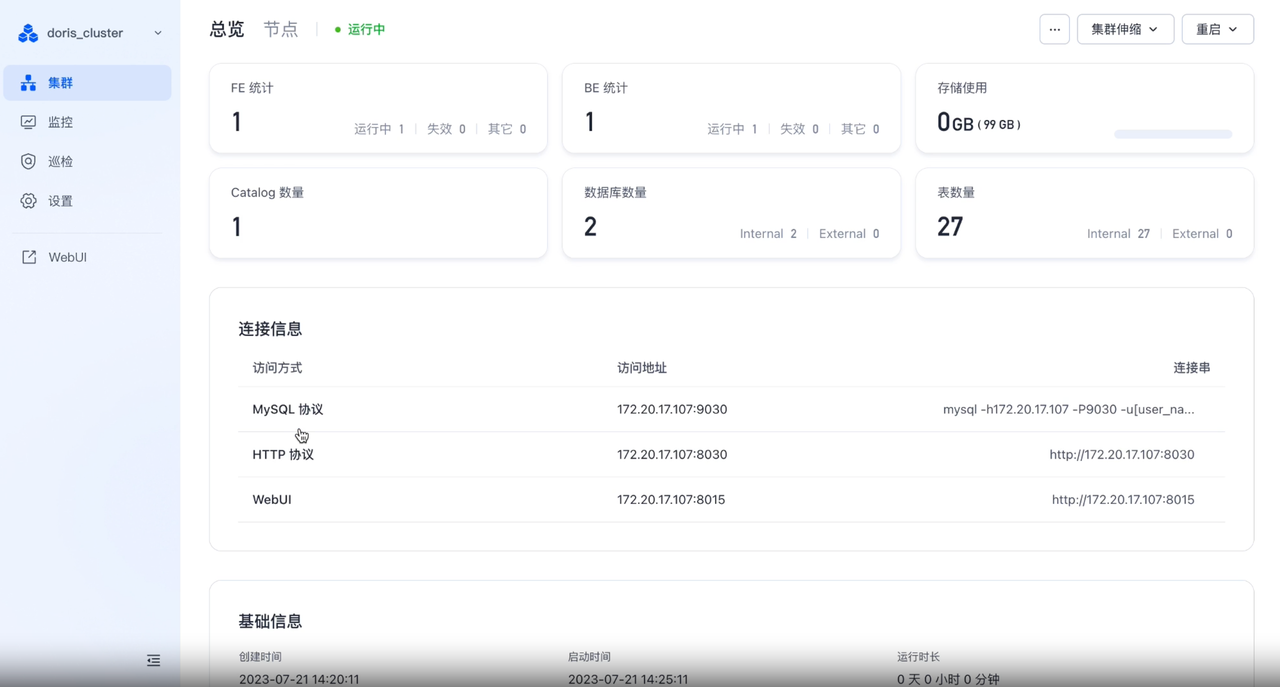
04 可视化运维管控和可视化查询 WebUI,最大化减少运维和探索分析成本
为了提高日常集群维护的效率,我们使用了飞轮科技免费开放的可视化集群管理工具 Cluster Manager for Apache Doris (以下简称 Doris Manager )。Doris Manager 提供的功能可以满足日常运维中集群监控、巡检、修改配置、扩缩容、升级等操作,降低登陆机器手动操作的麻烦和误操作风险。
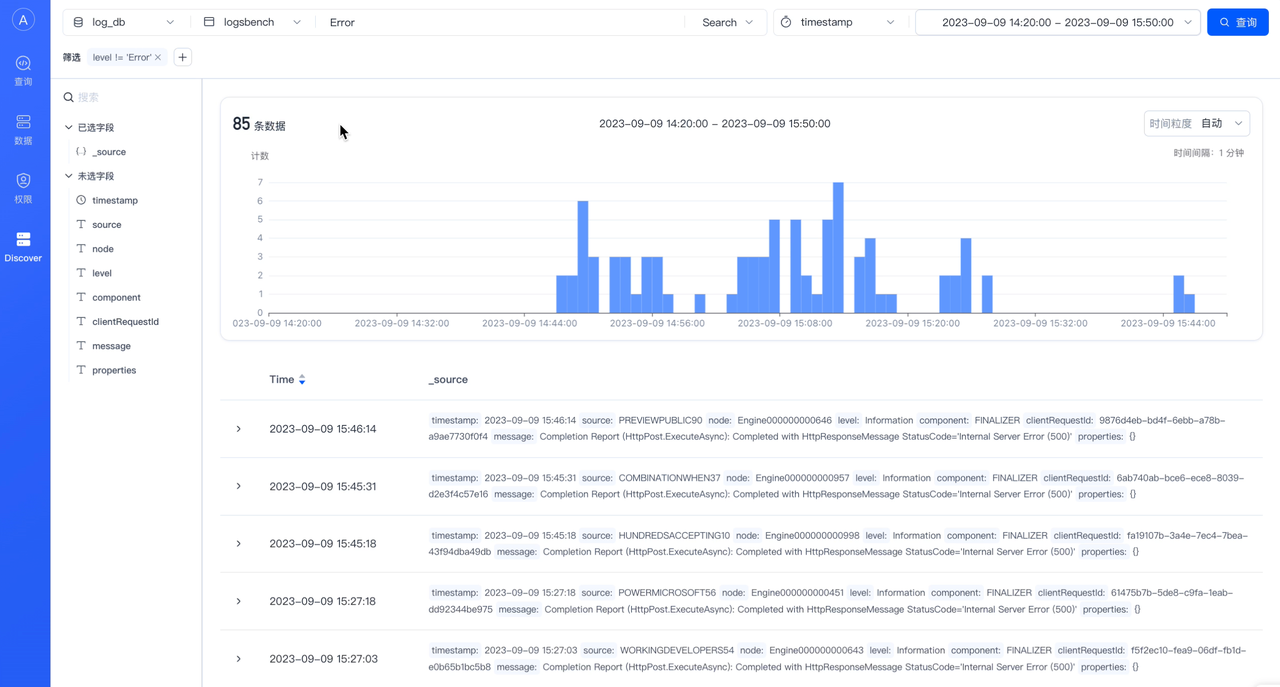
除了管控 Apache Doris 集群之后,Doris Manager 还集成了类似 Kibana 的可视化日志探索分析 WebUI,对于习惯 ELK 日志分析的用户非常友好,支持关键词检索、趋势图展示、趋势图拖拽日期范围、明细日志平铺和折叠展示、字段值过滤等交互方便的探索式分析,跟日志场景探索下钻的分析需求很契合。
总结与规划
在跟随 Apache Doris 2.0-alpha,2.0-beta,2.0 正式版本发布的节奏,我们根据业务场景进行了详细的评测,也为社区反馈了不少优化建议,得到社区的积极响应和解决。系统经历试运行一个月之后,我们将 2.0.1 版本正式用于生产环境,替换了原系统集群,完成架构升级改造,实现了写入性能、查询性能、存储成本、运维成本等多方面收益:
-
写入性能提升 3 倍以上:目前,奇安信的日志分析平台每日平均有数千亿的新增安全日志数据,通过 Doris 的 Routine Load 能够将数据实时稳定写入库,保障数据低延迟高吞吐写入。
-
查询性能平均提升 7 倍:查询响应时间大幅减少,与之前的查询效率相比达到平均 7 倍提升,其中业务特别关注的全文检索速度达到 20 倍以上的提升,助力日志分析与网络安全运营效率。
-
高效便捷的可视化管理:Cluster Manager for Apache Doris 工具提供了可视化集群监控告警平台,满足日常集群监控等一系列操作,同时 WebUI 多种功能为分析人员提供了操作简单、使用便捷的交互式分析。总而言之,Doris 的易用性、灵活性大幅降低了开发、运维、分析人员的学习与使用成本。
后续我们还将在日志分析场景下探索更多 Apache Doris 的能力。我们将扩大 JSON 数据类型的相关应用,加强系统对于半结构化数据深度分析的能力。同时,我们也非常期待 Apache Doris 2.1 版本中新增的 Variant 可变数据类型,支持存储任意结构的 JSON 数据,支持字段个数与类型的变化,让业务人员灵活定义特殊字符,以更好地实现半结构数据 Schema Free 的分析需求。
非常感谢 SelectDB 团队一直以来对我们的技术支持,助力奇安信走向“体系化防御、数字化运营”的网络日志安全管理,帮助客户准确识别、保护和监管网络设备与各类系统,确保业务人员在任何时候都能够安全、可信、稳定地访问数据与业务。
最后,我们也将持续参与到 Apache Doris 社区建设中,将相关成果贡献回馈社区,希望 Apache Doris 飞速发展,越来越好!