目录
一、数据集划分
1、交叉验证
2、不平衡数据的处理
代价敏感学习
二、评价指标
三、正则化、偏差和方差
为什么要标准化/归一化?
过拟合的处理——Dropout
过拟合的处理——Early stopping
过拟合的处理——数据增强
偏差和方差
编辑
一、数据集划分
- 训练集(Training Set):帮助我们训练模型,简单的说就是通过训练集的数据让我们确定拟合曲线的参数。
- 验证集(Validation Set):也叫做开发集( Dev Set ),用来做模型选择(model selection),即做模型的最终优化及确定的,用来辅助我们的模型的构建,即训练超参数,可选;
- 测试集(Test Set): 为了测试已经训练好的模型的精确度。

- 三者划分:训练集、验证集、测试集
- 机器学习:60%,20%,20%;70%,10%,20%
- 深度学习:98%,1%,1% (假设百万条数据)
1、交叉验证
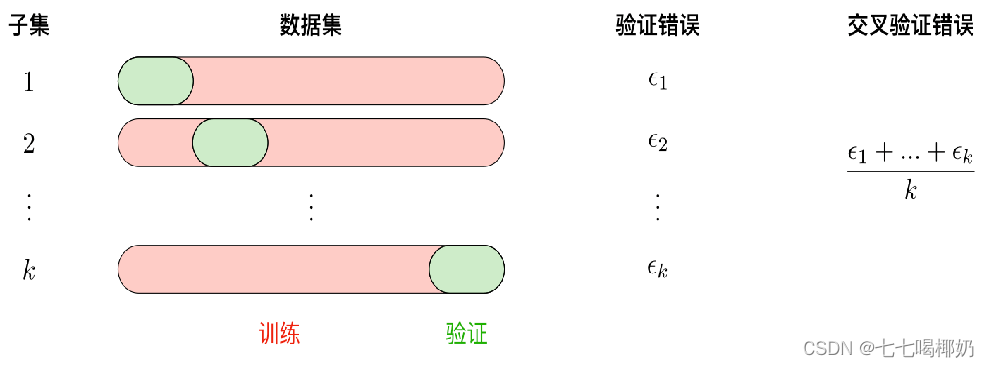
1. 使用训练集训练出k个模型
2. 用k个模型分别对交叉验证集计算得出交叉验证误差(代价函数的值)
3. 选取代价函数值最小的模型
4. 用步骤3中选出的模型对测试集计算得出推广误差(代价函数的值)
2、不平衡数据的处理
数据不平衡是指数据集中各类样本数量不均衡的情况.
常用不平衡处理方法有采样和代价敏感学习
采样有欠采样、过采样和综合采样的方法.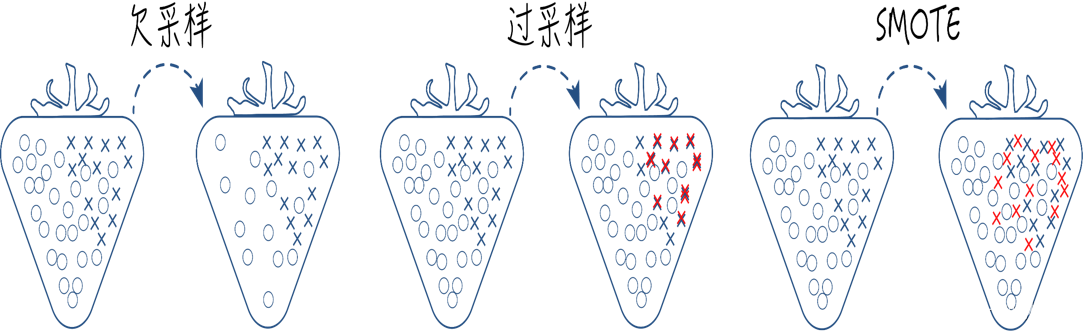
代价敏感学习
代价敏感学习是指为不同类别的样本提供不同的权重,从而让机器学习模型进行学习的一种方法
比如风控或者入侵检测,这两类任务都具有严重的数据不平衡问题,可以在算法学习的时候,为少类样本设置更高的学习权重,从而让算法更加专注于少类样本的分类情况,提高对少类样本分类的查全率,但是也会将很多多类样本分类为少类样本,降低少类样本分类的查准率。
二、评价指标
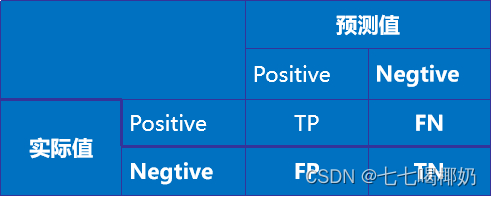
1. 正确肯定(True Positive,TP): 预测为真,实际为真
2. 正确否定(True Negative,TN):预测为假,实际为假
3. 错误肯定(False Positive,FP): 预测为真,实际为假
4. 错误否定(False Negative,FN):预测为假,实际为真

混淆矩阵(confusion_matrix)
有100张照片,其中,猫的照片有60张,狗的照片是40张。
输入这100张照片进行二分类识别,找出这100张照片中的所有的猫。
- 正例(Positives):猫
- 负例(Negatives):狗
识别结果的混淆矩阵
1、正确率(Accuracy)=(TP+ TN)/S
TP+ TN =70,S= 100,则正确率为: Accuracy =70/100=0.7
2、精度(Precision)=TP/(TP+ FP)
TP=40,TP+ FP=50。 Precision =40/50=0.8
3、召回率(Recall)=TP/(TP+ FN)
TP=40,TP+FN =60。则召回率为: Recall =40/60=0.67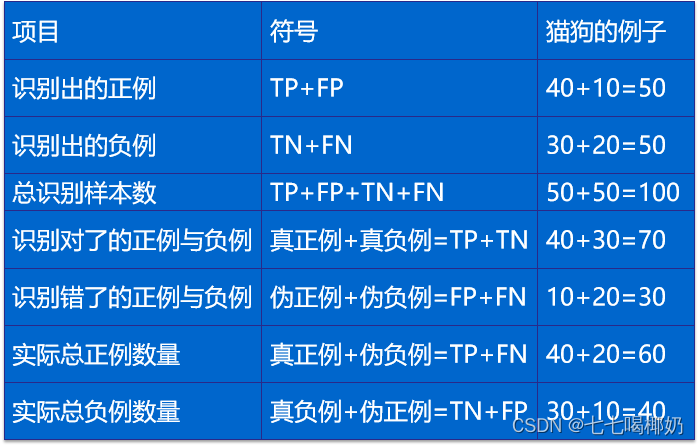
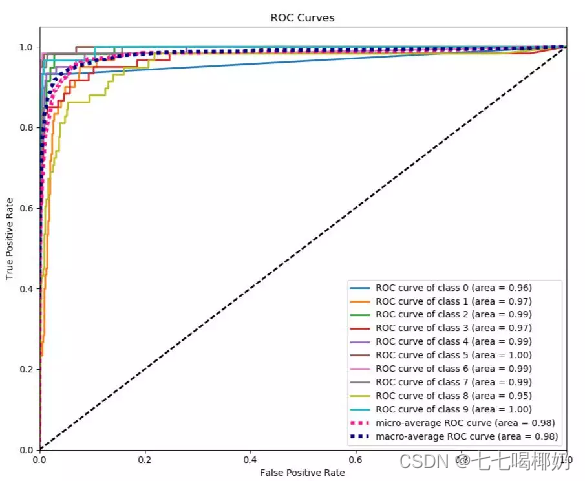
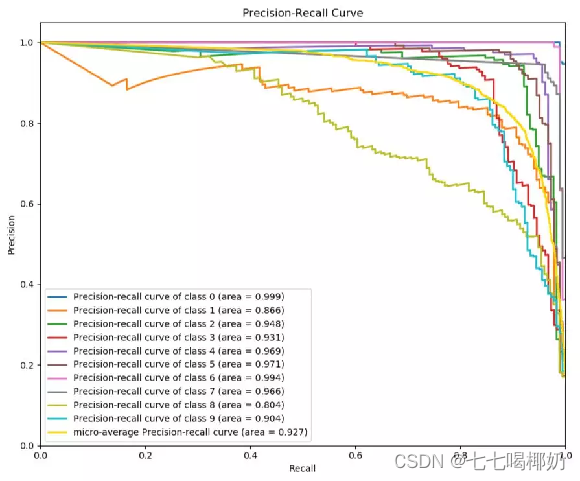
ROC和PR曲线
三、正则化、偏差和方差
为什么要标准化/归一化?
提升模型精度:不同维度之间的特征在数值上有一定比较性,可以大大提高分类器的准确性。
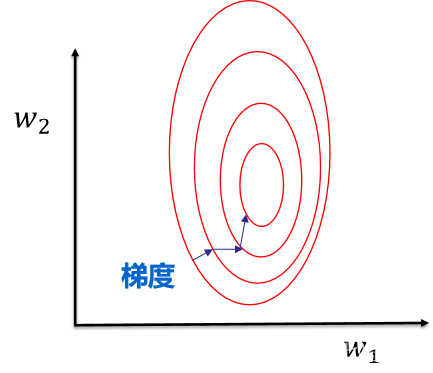
加速模型收敛:最优解的寻优过程明显会变得平缓,更容易正确的收敛到最优解。


之前介绍过,过拟合可以通过正则化来处理,这里我们介绍另外几种方法
过拟合的处理——Dropout
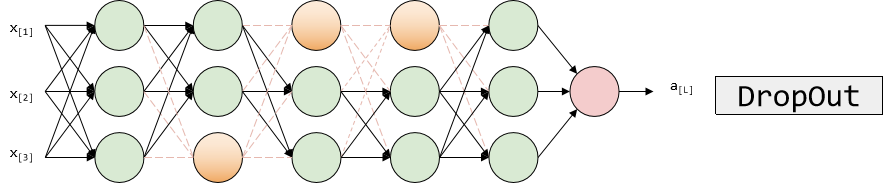
Dropout的功能类似于L2正则化,与L2正则化不同的是,被应用的方式不同,dropout也会有所不同,甚至更适用于不同的输入范围
keep-prob=1(没有dropout) keep-prob=0.5(常用取值,保留一半神经元)
在训练阶段使用,在测试阶段不使用!
过拟合的处理——Early stopping
Early stopping代表提早停止训练神经网络
Early stopping的优点是,无需尝试L2正则化超参数λ的很多值。
过拟合的处理——数据增强
数据增强:随意翻转和裁剪、扭曲变形图片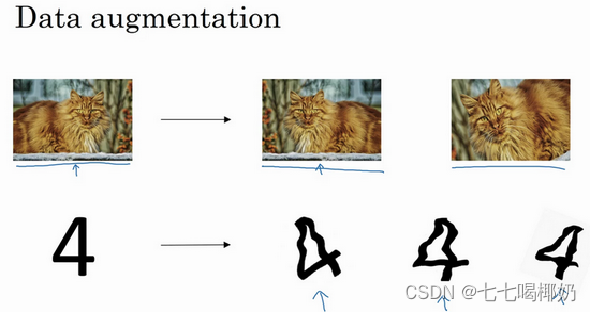
偏差和方差
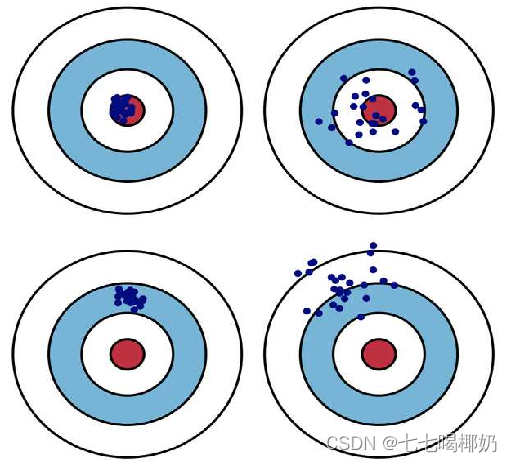
偏差Bias:描述的是预测值(估计值)的期望与真实值之间的差距。偏差越大,越偏离真实数据,如上图第二行所示。
方差Variance: 描述的是预测值的变化范围,离散程度,也就是离其期望值的距离。方差越大,数据的分布越分散,如上图右列所示。
方差、偏差和模型复杂度
下图是模型复杂度与误差的关系,一般来说,随着模型复杂度的增加,方差会逐渐增大,偏差会逐渐减小,在虚线处,差不多是模型复杂度的最恰当的选择,其“偏差”和“方差”也都适度,才能“适度拟合”。
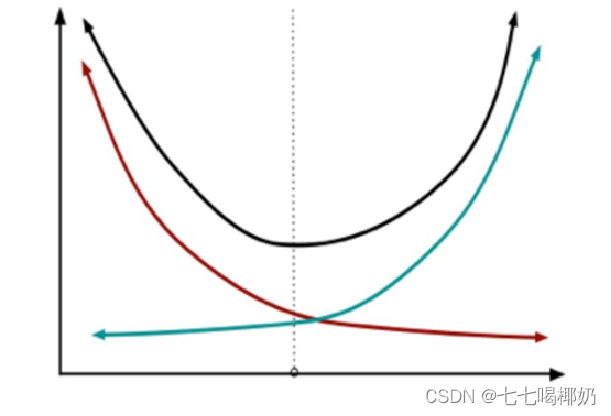
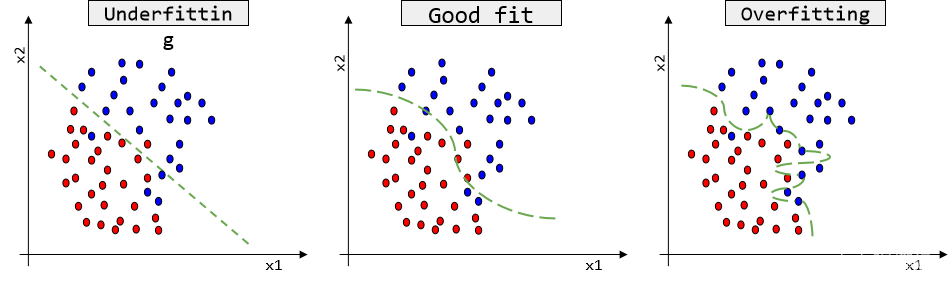
1. 获得更多的训练实例——解决高方差
2. 尝试减少特征的数量——解决高方差
3. 尝试获得更多的特征——解决高偏差
4. 尝试增加多项式特征——解决高偏差
5. 尝试减少正则化程度λ——解决高偏差
6. 尝试增加正则化程度λ——解决高方差