目录
- 前言
- 要点
- 阅读对象
- 阅读导航
- 前置知识
- 笔记正文
- 一、ES数据预处理
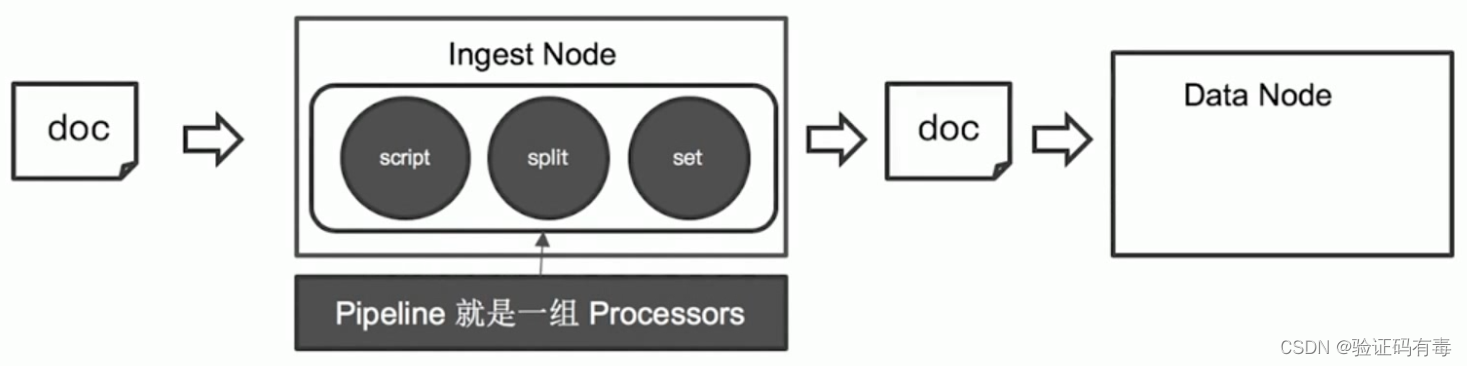
- 1.1 Ingest Node:摄入节点
- 1.2 Ingest Pipeline:摄入管道
- 1.3 Processor:预处理器——简单加工
- 1.4 Painless Script:脚本——复杂加工
- 1.5 简单实用案例
- 二、文档/数据建模
- 2.1 ES中如何处理关联关系
- 2.2 对象类型
- 2.3 嵌套对象(Nested Object)
- 2.4 父子关联关系(Parent : Child )
- 2.5 ElasticSearch数据建模最佳实践
- 2.5.1 关联关系选择
- 2.5.2 避免过多字段
- 2.5.3 避免正则,通配符,前缀查询
- 2.5.4 避免空值引起的聚合不准
- 2.5.5 为索引的Mapping加入Meta 信息
- 三、ES读写性能调优
- 3.1 ES底层读写工作原理分析
- 3.1.1 ES写入数据的流程
- 3.1.2 ES读取数据的过程
- 3.2 如何提升集群的读写性能
- 3.2.1 提升集群读性能
- 3.2.2 提升集群写性能
- 3.2.3 其他一些优化建议
- 学习总结
前言
要点
ES要掌握什么:
- 使用:搜索和聚合操作语法,理解分词,倒排索引,相关性算分(文档匹配度)
- 优化: 数据预处理,文档建模,集群架构优化,读写性能优化
阅读对象
已经掌握了基本ES使用API,了解相关性算分原理的同学
阅读导航
系列上一篇文章:《【ES专题】ElasticSearch集群架构剖析》
前置知识
- 掌握了基本ES使用API
- 了解相关性算分原理
笔记正文
一、ES数据预处理
什么是预处理?其实就是说,在数据进行CRUD之前进行的一系列自定义操作嘛。比如:
- 将某个字段的值转换为另一种类型;
- 将日期格式处理一下
- 新增字段返回
- 某些字段不需要
等等。其实大家伙想象,这些操作是不是很熟悉?无论是Mysql层,还是我们Java业务层,其实都有做过这件事情。所以,ES其实也提供了ES层的一些业务处理,并且提供了不少内置组件给我们。那这些组件是由谁完成的?其实就是我们上节课说到的一个集群角色——Ingest Node节点完成的。
要了解ES数据的预处理,有4个概念需要大家理解一下,分别如下:
1.1 Ingest Node:摄入节点
Ingest Node,直译:摄入节点。很直观了,就是摄入数据的ES进程实例。他ES5.0之后才引入的一种新的节点类型。默认配置下,每个节点都是Ingest Node。Ingest Node节点的功能前面有大概介绍过,不过我估计大伙没怎么注意。这里简述一下:
- 具有预处理数据的能力,可拦截lndex或 Bulk API的请求
- 对数据进行转换,并重新返回给Index或 Bulk APl
举个栗子:
- 为某个字段设置默认值
- 重命名某个字段的字段名
- 对字段值进行Split 操作
- 支持设置
Painless脚本,对数据进行更加复杂的加工
我想大家应该多少有点感觉了吧,关于Ingest node的作用。其实在ES中,还有一个叫做LogStash的组件也能完成这些功能,具体的在下一篇笔记中讲。
1.2 Ingest Pipeline:摄入管道
ES关键词:pipeline
Ingest Pipeline,摄入管道。有什么用呢?有经验的小伙伴估计早已了然了,基本一提到【一系列处理器】肯定就存在【管道】,这已经成为了【一系列处理器】的范式了,无论什么语言都是如此。说白了,【管道】就是【处理器】的【容器】(多提一嘴,【处理器】+【管道】,通常是由【职责链】设计模式完成的)。
官方定义:管道是一系列处理器的定义,这些处理器将按照声明的顺序执行。管道由两个主要字段组成:【描述】和【处理器列表】。
1.3 Processor:预处理器——简单加工
Processor,预处理器,它ES对一些加工行为的抽象包装类。ES本身也预提供了很多内置Processors
帮我们完成数据操作了。当然,也支持通过插件的方式,实现自己的Processor。
这些内置的Processor大致有:
- Split Processor : 将给定字段值分成一个数组
- Remove / Rename Processor :移除一个重命名字段
- Append : 为商品增加一个新的标签
- Convert:将商品价格,从字符串转换成float 类型
- Date / JSON:日期格式转换,字符串转JSON对象
- Date lndex Name Processor︰将通过该处理器的文档,分配到指定时间格式的索引中
- Fail Processor︰一旦出现异常,该Pipeline 指定的错误信息能返回给用户
- Foreach Process︰数组字段,数组的每个元素都会使用到一个相同的处理器
- Grok Processor︰日志的日期格式切割
- Gsub / Join / Split︰字符串替换│数组转字符串/字符串转数组
- Lowercase / upcase︰大小写转换
注意:不知道有没有朋友跟我一样,第一感觉会觉得预处理器不就是前面说的【过滤器】吗?不一样的,前面两篇文章提到的过滤器是【分词器】里面的【过滤器】,针对的是【搜索词】、【词项】,这里是【文档】数据。
1.4 Painless Script:脚本——复杂加工
ES关键字:script
Painless Script跟Processor一样都是为了做数据加工的。不同于Processor,Painless 通过写入一段脚本执行了更复杂加工过程。Painless Script具备以下特性:
- 高性能 / 安全
- 支持显示类型或者动态定义类型
Painless的用途:
- 可以对文档字段进行加工处理。比如:
- 更新或删除字段,处理数据聚合操作
- Script Field:对返回的字段提前进行计算
- Function Score:对文档的算分进行处理
- 在lngest Pipeline中执行脚本
- 在Reindex APl,Update By Query时,对数据进行处理
在Painless脚本中,想要访问字段,可以通过如下API进行:
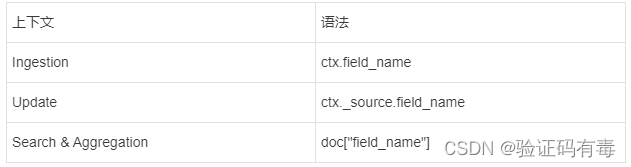
1.5 简单实用案例
Processor使用案例:
需求:索引csdn_blogs中有一字段tags,后期需要对其进行聚合操作。tags字段的值,本应该是数组,只不过存入的时候以,做分隔符拼成字符串存进去。
1)示例数据:
#csdn_blogs数据,包含3个字段,tags用逗号间隔
PUT csdn_blogs/_doc/1
{"title":"Introducing big data......","tags":"hadoop,elasticsearch,spark","content":"You konw, for big data"
}
2)创建pipeline
# 为ES添加一个 Pipeline
PUT _ingest/pipeline/blog_pipeline
{"description": "a blog pipeline","processors": [{"split": {"field": "tags","separator": ","}},{"set":{"field": "views","value": 0}}]
}#查看Pipleline
GET _ingest/pipeline/blog_pipeline
3)使用pipeline新增一条id=2的数据
#使用pipeline更新数据
PUT csdn_blogs/_doc/2?pipeline=blog_pipeline
{"title": "Introducing cloud computering","tags": "openstack,k8s","content": "You konw, for cloud"
}

Painless Script使用案例:
1)示例数据:注意,相比之前的示例,这里新增了字段views表示阅读量,默认为0
DELETE csdn_blogs
PUT csdn_blogs/_doc/1
{"title":"Introducing big data......","tags":"hadoop,elasticsearch,spark","content":"You konw, for big data","views":0
}
2)使用一段脚本更新数据,注意更新的是views字段。另外这边使用了ctx的API来获取上下文中的字段值(前面介绍Painless脚本的时候有介绍过)
POST csdn_blogs/_update/1
{"script": {"source": "ctx._source.views += params.new_views","params": {"new_views":100}}
}# 查看views计数
POST csdn_blogs/_search
查询结果如下:

当然也可以保存脚本到ES中
#保存脚本在 Cluster State
POST _scripts/update_views
{"script":{"lang": "painless","source": "ctx._source.views += params.new_views"}
}
然后使用它们
POST csdn_blogs/_update/1
{"script": {"id": "update_views","params": {"new_views":1000}}
}# 查看views计数
POST csdn_blogs/_search
这边就不看查询结果了,就是使用另一种方式来做脚本处理而已(小声说话…)
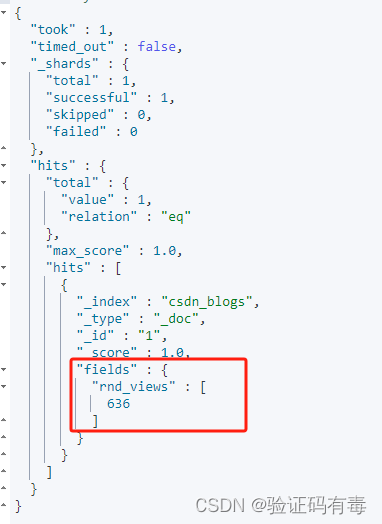
3)查询时使用一段脚本做预处理:下面的脚本使用了script_fields,这个关键字声明的字段是临时的,不会被存入文档中。具体用法见官方文档
GET csdn_blogs/_search
{"script_fields": {"rnd_views": {"script": {"lang": "painless","source": """java.util.Random rnd = new Random();doc['views'].value+rnd.nextInt(1000);"""}}},"query": {"match_all": {}}
}
二、文档/数据建模
什么是文档建模?这个名词多少有点陌生。不过可以简单类比一下,让大家知道啥意思。
不知道大家有没有疑问,那就是:我在Mysql中经常遇到联表的情况,在ES中应该也有这样的需求吧,那,怎么实现呢?是的,所谓文档建模关心的就是这个东西。即文档之间、索引之间的关系,该如何联系。
2.1 ES中如何处理关联关系
关系型数据库通过【三范式】去约束、设计表之间的关系,其主要目标是减少不必要的更新,但我们作为开发都知道,有时候过于遵循所谓的【三范式】往往会有负面效果 (甚至很多我们的小伙伴还不知道所谓【三范式】)。比如:
- 一个完全范式化设计的数据库会经常面临查询缓慢的问题。数据库越范式化,需要
join的表就越多 - 范式化节省了存储空间,但是存储空间已经变得越来越便宜
- 范式化简化了更新,但是数据读取操作可能更多
既然【范式】会有很多副作用,那么【反范式化(Denormalize)】的设计就被提倡出来:不使用关联关系,而是宁愿在文档中保存冗余的数据拷贝。
- 优点:无需处理Join操作,数据读取性能好。Elasticsearch可以通过压缩_source字段,减少磁盘空间的开销
- 缺点:不适合在数据频繁修改的场景。 一条数据的改动,可能会引起很多数据的更新
关系型数据库,一般会考虑【范式】数据;在Elasticsearch,往往考虑【反范式】数据。
Elasticsearch并不擅长处理关联关系,一般会采用以下四种方法处理关联:
- 对象类型
- 嵌套对象(Nested Object)
- 父子关联关系(Parent / Child )
- 应用端关联
2.2 对象类型
ES关键字:properties,mapping属性的子属性。用于在新建索引、更新索引的mapping时,指定对象类型的属性
用一个简单的案例来给大家伙示范一下,什么是对象类型。
案例1:CSDN博客作者信息
在ES中,通常会在每一篇博文中保留作者的信息。这种情况下,如果作者信息发生变化,需要修改相关博文的文档
上述就是【反范式化】的做法。正常我们在Mysql中,是在博文表中新增一个【作者id】,需要使用的时候才去联表查询出来作者名字。
1)定义一个博文的索引
DELETE csdn_blogs
# 设置csdn_blogs的 Mapping
PUT /csdn_blogs
{"mappings": {"properties": {"content": {"type": "text"},"time": {"type": "date"},"user": {"properties": {"city": {"type": "text"},"userid": {"type": "long"},"username": {"type": "keyword"}}}}}
}
2)插入一条示例数据
PUT /blog/_doc/1
{"content":"I like Elasticsearch","time":"2022-01-01T00:00:00","user":{"userid":1,"username":"Fox","city":"Changsha"}
}
3)查询一下博文信息
# 查询 blog信息
POST /blog/_search
{"query": {"bool": {"must": [{"match": {"content": "Elasticsearch"}},{"match": {"user.username": "Fox"}}]}}
}
查询结果省略
案例2:包含对象数组的文档
我们知道,电影通常会有多个演员,多个导演,甚至多个电影名字。然后人名在中外不同国家排列方式是不同的。我们是【姓+名】,国外不少是【名+姓】的,所以,会拆分成【first name + last name】的方式存储。在ES中,【电影】可能会通过下面这样的方式存储:
数据结构伪代码:
public class Movie {String movieName;List<Actor> actors;
}public class Actor {String firstName;String lastName;
}
1)定义一个电影索引
PUT /my_movies
{"mappings" : {"properties" : {"actors" : {"properties" : {"first_name" : {"type" : "keyword"},"last_name" : {"type" : "keyword"}}},"title" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}}}}
}
2)写入一条记录
POST /my_movies/_doc/1
{"title":"Speed","actors":[{"first_name":"Keanu","last_name":"Reeves"},{"first_name":"Dennis","last_name":"Hopper"}]
}
注意:actors字段有多个值,是一个数组
3)查询记录:注意下面的bool-must,我原本的设想是:查询first-name跟last-name都匹配的电影。但我们知道,下面这个搜索在我们设想中是不存在的。因为没有演员的名字叫做Keanu Hopper
# 查询电影信息
POST /my_movies/_search
{"query": {"bool": {"must": [{"match": {"actors.first_name": "Keanu"}},{"match": {"actors.last_name": "Hopper"}}]}}
}
但事实上,搜索结果如下:
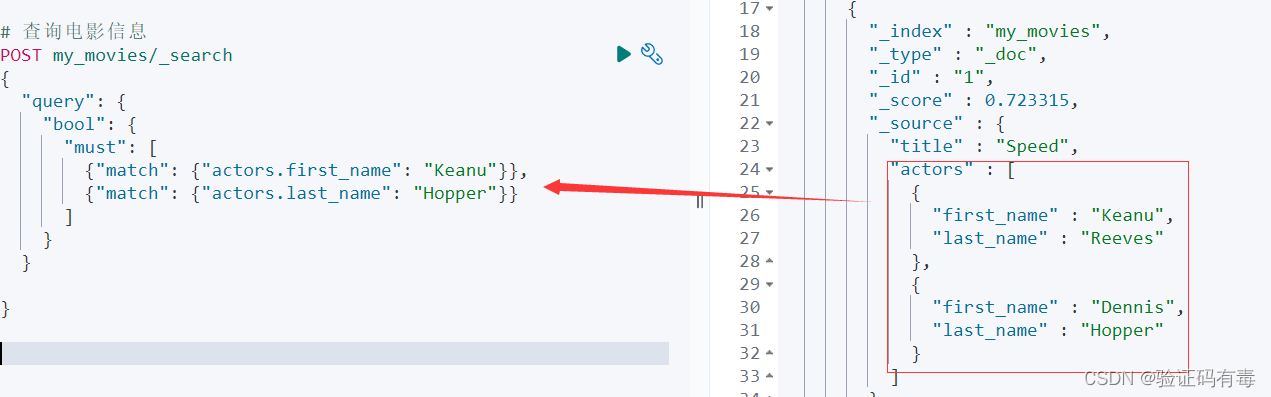
竟然有结果出来!!我明明用的是must,但是效果上看起来跟should一样啊。点解?
这就不得不说一下,ES【对象类型】建模底层数据结构了。在【对象类型】建模中,上述2)插入的记录,在文档中,会以key-value这样的结构存在:(这个操作在ES中被称为数据扁平化,据说很重要的一种特性,但是我还没理解出来重要在哪,哈)
"title":"Speed"
"actors.first_name": ["Keanu","Dennis"]
"actors.last_name": ["Reeves","Hopper"]
假设actors数组只有一个值,即如下:
POST /my_movies/_doc/1
{"title":"Speed","actors":[{"first_name":"Keanu","last_name":"Reeves"}]
}
那他在文档中记录是这样的:
"title":"Speed"
"actors.first_name": "Keanu"
"actors.last_name": "Reeves"
也正是由于这个原因,这条记录在倒排索引中的记录如下:
| 索引词项 | 文档id |
|---|---|
| Keanu | 1 |
| Dennis | 1 |
| Reeves | 1 |
| Hopper | 1 |
所以最终索引到了我们不想要的记录。怎么办呢?使用另一种对象:内嵌对象。
2.3 嵌套对象(Nested Object)
ES关键字:nested、properties
什么是Nested Data Type?官方是这么定义的:
如果需要索引对象数组并维护数组中每个对象的独立性,则应该使用嵌套数据类型而不是对象数据类型。在内部,嵌套对象将数组中的每个对象索引为一个单独的隐藏文档,这意味着每个嵌套对象可以独立于其他对象进行查询,使用嵌套查询:
Nested数据类型,允许对象数组中的对象被独立索引。在其内部,Nested文档会被保存在两个Lucene文档中,被嵌套的对象当作隐藏文档,但是依然寄存在Nested文档上。在查询时做Join处理。
这一点很重要,保存在两个文档
还是拿上面的【电影】例子给大家演示一下:
1)定义一个电影索引,注意actors字段的type
# 先删除之前创建的
DELETE /my_movies
# 创建 Nested 对象 Mapping
PUT /my_movies
{"mappings" : {"properties" : {"actors" : {"type": "nested","properties" : {"first_name" : {"type" : "keyword"},"last_name" : {"type" : "keyword"}}},"title" : {"type" : "text","fields" : {"keyword":{"type":"keyword","ignore_above":256}}}}}
}
2)写入一条记录
POST /my_movies/_doc/1
{"title":"Speed","actors":[{"first_name":"Keanu","last_name":"Reeves"},{"first_name":"Dennis","last_name":"Hopper"}]
}
3)nested查询:注意关键词nested,为什么要这么来做,见下面的分析
# Nested 查询
POST /my_movies/_search
{"query": {"bool": {"must": [{"match": {"title": "Speed"}},{"nested": {"path": "actors","query": {"bool": {"must": [{"match": {"actors.first_name": "Keanu"}},{"match": {"actors.last_name": "Hopper"}}]}}}}]}}
}
上面这条记录,实际上会被这样保存:
doc
{"title":"Speed"
}
doc_1
{"actors.first_name": "Keanu""actors.last_name": "Reeves"
}
doc_2
{"actors.first_name": "Dennis""actors.last_name": "Hopper"
}
要特别注意这个【隐藏的单独文档】的准确意义啊!正是因为是一个独立的文档,所以不能够在查询中对象.属性,而是使用专门为nested设计的nested查询;因为是隐藏的,所以我们没办法直接查询到,只能通过原文档获取到隐藏子文档。
不过虽然nested对象确实解决了多值的问题,但是大家有没有发现,因为反范式化的设计,隐藏子文档需要更新的时候,会把父文档也一起更新的,这种更新粒度是否太大了呢?
2.4 父子关联关系(Parent : Child )
ES关键字:join、relations
Object对象和Nested对象它是有一些局限性的,那就是每次更新,可能需要重新索引整个对象(包括根对象和嵌套对象),毕竟【反范式化】了。所以ES为了兼容Join查询这种需求,设计了另一种关联关系:父子关联关系。父子关联关系有如下特征:
- 父文档和子文档是同一个索引上的两个独立的文档。注意:独立的,显式的文档。跟嵌套的【隐藏子文档】不一样
- 更新父文档无需重新索引子文档。子文档被添加,更新或者删除也不会影响到父文档和其他的子文档
接下来用一个简单的示例演示一下。
1)还是创建一个博客索引
DELETE /my_blogs# 设定 Parent/Child Mapping
PUT /my_blogs
{"settings": {"number_of_shards": 2},"mappings": {"properties": {"blog_comments_relation": {"type": "join","relations": {"blog": "comment"}},"content": {"type": "text"},"title": {"type": "keyword"}}}
}

2)插入两条父文档数据
#索引父文档
PUT /my_blogs/_doc/blog1
{"title":"Learning Elasticsearch","content":"learning ELK ","blog_comments_relation":{"name":"blog"}
}#索引父文档
PUT /my_blogs/_doc/blog2
{"title":"Learning Hadoop","content":"learning Hadoop","blog_comments_relation":{"name":"blog"}
}
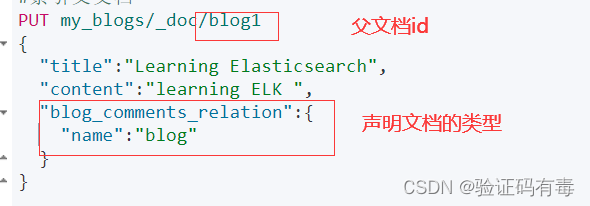
注意,文档的id不再是以前默认的数字(当然是表面上这样),而是我们前面声明的父子关联关系字段的名称 + id
3)插入子文档数据:路由到指定的父文档所在分片上
#索引子文档
PUT /my_blogs/_doc/comment1?routing=blog1
{"comment":"I am learning ELK","username":"Jack","blog_comments_relation":{"name":"comment","parent":"blog1"}
}#索引子文档
PUT /my_blogs/_doc/comment2?routing=blog2
{"comment":"I like Hadoop!!!!!","username":"Jack","blog_comments_relation":{"name":"comment","parent":"blog2"}
}#索引子文档
PUT /my_blogs/_doc/comment3?routing=blog2
{"comment":"Hello Hadoop","username":"Bob","blog_comments_relation":{"name":"comment","parent":"blog2"}
}
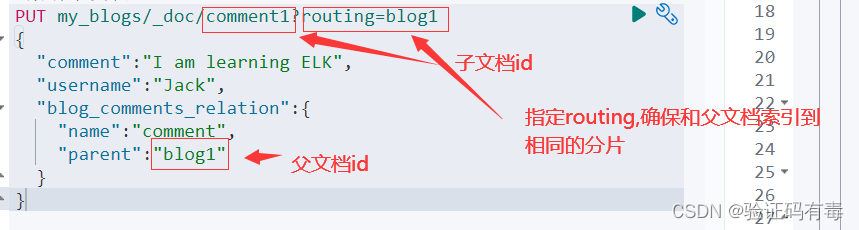
注意:
- 不知道大家有没有留意到,父子文档是在同一个【索引】上的,即这里的
my_blogs - 父文档和子文档必须存在相同的分片上,能够确保查询join 的性能
- 当指定子文档时候,必须指定它的父文档ld。使用routing参数来保证,分配到相同的分片
4)查询示例
ES关键字:parent_id、has_child、has_parent
查询所有:所有文档都显示出来了
# 查询所有文档
POST /my_blogs/_search
结果返回:(截取了部分)
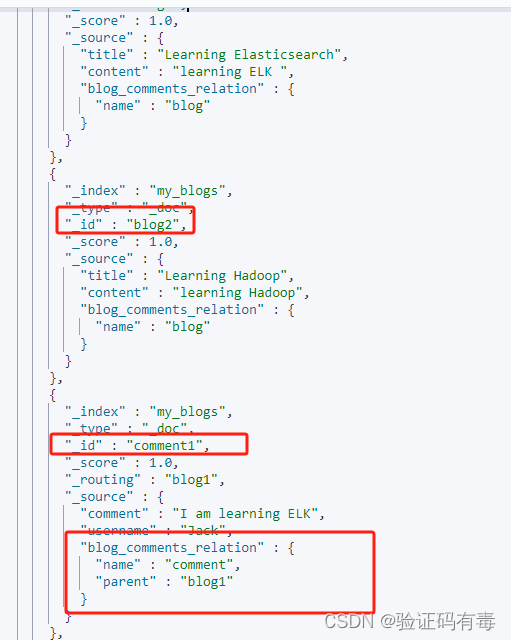
分别查询父、子文档:只显示出来父文档信息,子文档同理
#根据父文档ID查看
GET /my_blogs/_doc/blog2#通过ID ,访问子文档
GET /my_blogs/_doc/comment3
下图是父文档结果,子文档就不截图了。

子文档的查询还可以通过父文档id来路由:
#通过ID和routing ,访问子文档
GET /my_blogs/_doc/comment3?routing=blog2

更丰富的查询示例:(不截图了)
# 通过Parent Id 查询子文档
POST /my_blogs/_search
{"query": {"parent_id": {"type": "comment","id": "blog2"}}
}# Has Child 查询,返回父文档
POST /my_blogs/_search
{"query": {"has_child": {"type": "comment","query" : {"match": {"username" : "Jack"}}}}
}# Has Parent 查询,返回相关的子文档
POST /my_blogs/_search
{"query": {"has_parent": {"parent_type": "blog","query" : {"match": {"title" : "Learning Hadoop"}}}}
}#更新子文档
PUT /my_blogs/_doc/comment3?routing=blog2
{"comment": "Hello Hadoop??","blog_comments_relation": {"name": "comment","parent": "blog2"}
}
查询所有文档的结果:
嵌套文档、父子文档横向对比
| Nested Object | Parent / Child | |
|---|---|---|
| 优点 | 文档存储在一起,读取性能高 | 父子文档可以独立更新 |
| 缺点 | 更新嵌套的子文档时,需要更新整个文档 | 需要额外的内存维护关系。读取性能相对差 |
| 适用场景 | 子文档偶尔更新,以查询为主 | 子文档更新频繁 |
2.5 ElasticSearch数据建模最佳实践
2.5.1 关联关系选择
- Object: 适合优先考虑反范式(典型的报表那种就需要反范式化)
- Nested:当数据包含多数值对象,同时有查询需求
- Child/Parent:关联文档更新非常频繁时
2.5.2 避免过多字段
一个文档中,最好避免大量的字段。字段过多往往会有如下问题:
- 过多的字段数不容易维护
- Mapping 信息保存在Cluster State 中,数据量过大,对集群性能会有影响
- 删除或者修改数据需要reindex
生产环境中,尽量不要打开 Dynamic,可以使用Strict控制新增字段的加入。
- true :未知字段会被自动加入
- false :新字段不会被索引,但是会保存在_source
- strict :新增字段不会被索引,文档写入失败
ES默认最大字段数是1000,可以设置index.mapping.total_fields.limit限定最大字段数。·
2.5.3 避免正则,通配符,前缀查询
正则,通配符查询,前缀查询属于Term查询,但是性能不够好。特别是将通配符放在开头,会导致性能的灾难
案例:针对版本号的搜索
# 将字符串转对象
PUT softwares/
{"mappings": {"properties": {"version": {"properties": {"display_name": {"type": "keyword"},"hot_fix": {"type": "byte"},"marjor": {"type": "byte"},"minor": {"type": "byte"}}}}}
}#通过 Inner Object 写入多个文档
PUT softwares/_doc/1
{"version":{"display_name":"7.1.0","marjor":7,"minor":1,"hot_fix":0 }}PUT softwares/_doc/2
{"version":{"display_name":"7.2.0","marjor":7,"minor":2,"hot_fix":0 }
}PUT softwares/_doc/3
{"version":{"display_name":"7.2.1","marjor":7,"minor":2,"hot_fix":1 }
}# 通过 bool 查询,
POST softwares/_search
{"query": {"bool": {"filter": [{"match":{"version.marjor":7}},{"match":{"version.minor":2}}]}}
}
2.5.4 避免空值引起的聚合不准
ES关键字:mappings下的null_value
# Not Null 解决聚合的问题
DELETE /scores
PUT /scores
{"mappings": {"properties": {"score": {"type": "float","null_value": 0}}}
}PUT /scores/_doc/1
{"score": 100
}
PUT /scores/_doc/2
{"score": null
}POST /scores/_search
{"size": 0,"aggs": {"avg": {"avg": {"field": "score"}}}
}
2.5.5 为索引的Mapping加入Meta 信息
- Mappings设置非常重要,需要从两个维度进行考虑
- 功能︰搜索,聚合,排序
- 性能︰存储的开销;内存的开销;搜索的性能
- Mappings设置是一个迭代的过程
- 加入新的字段很容易(必要时需要update_by_query)
- 更新删除字段不允许(需要Reindex重建数据)
- 最好能对Mappings 加入Meta 信息,更好的进行版本管理
- 可以考虑将Mapping文件上传git进行管理
PUT /my_index
{"mappings": {"_meta": {"index_version_mapping": "1.1"}}
}
三、ES读写性能调优
3.1 ES底层读写工作原理分析
3.1.1 ES写入数据的流程
- 客户端选择一个node发送请求,通常这个node扮演协调节点的角色
- 协调节点对索引文档进行路由,并将请求转发到对应的节点
- 节点上的主分片处理请求,如果写入成功,则接着将数据同步到副本分片上,等待副本分片都报告成功,节点向协调节点报告成功
- 协调节点收到报告之后,再将请求结果返回到客户端
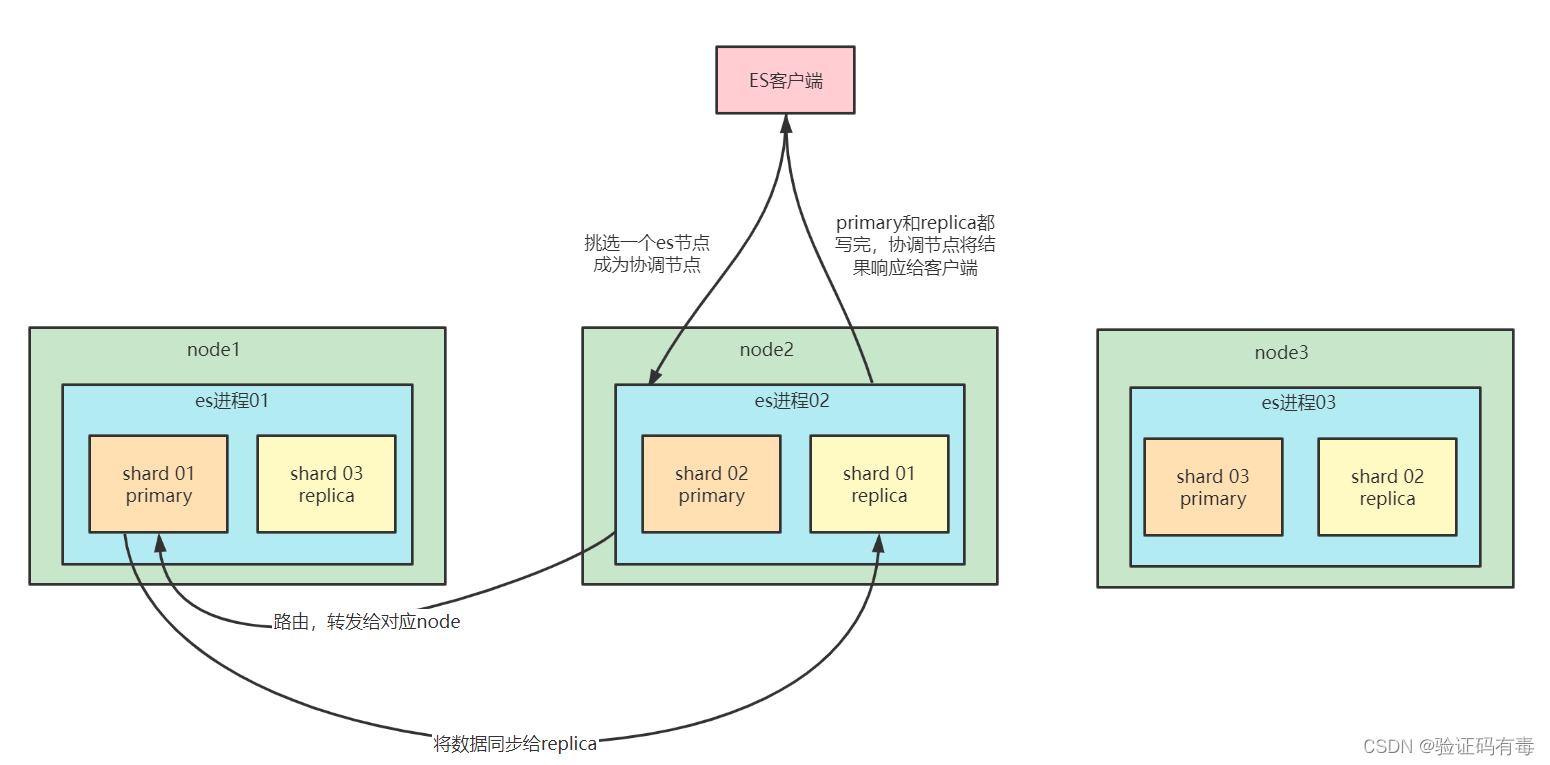
它的底层原理如下图所示:
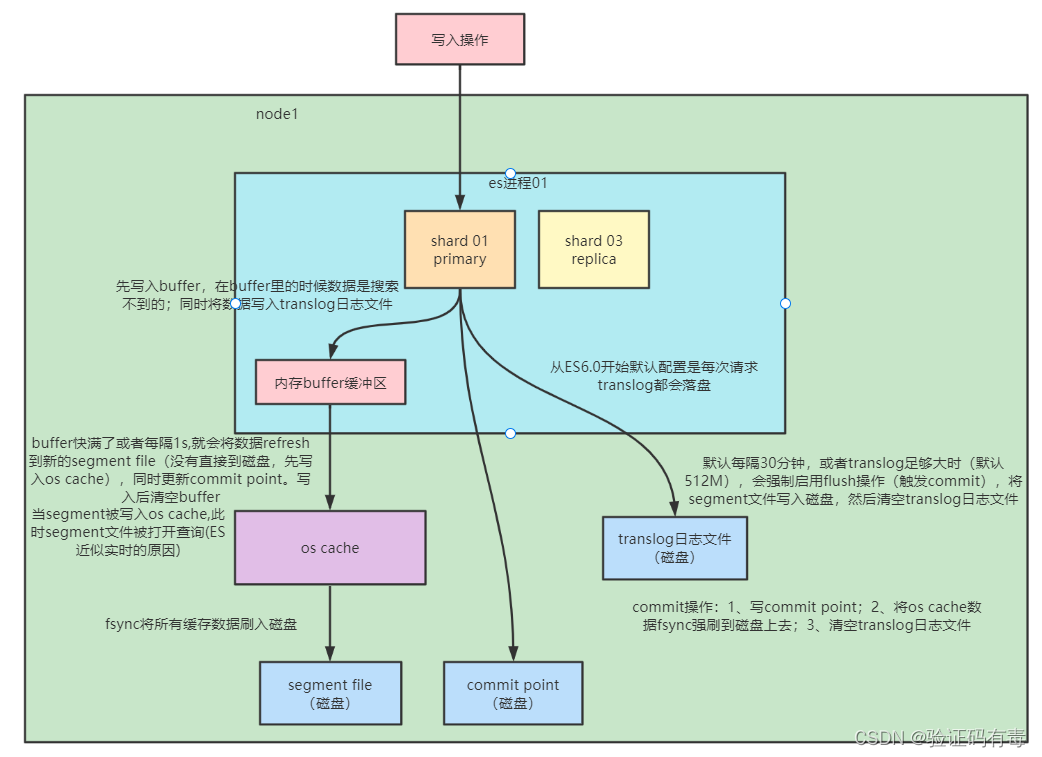
上图涉及到一些核心概念:
segment file: 存储倒排索引的文件,每个segment本质上就是一个倒排索引,每秒都会生成一个segment文件,当文件过多时es会自动进行segment merge(合并文件),合并时会同时将已经标注删除的文档物理删除
commit point:记录当前所有可用的segment,每个commit point都会维护一个.del文件(es删除数据本质上不是物理删除),当es做删改操作时首先会在.del文件中声明某个document已经被删除,文件内记录了在某个segment内某个文档已经被删除,当查询请求过来时在segment中被删除的文件是能够查出来的,但是当返回结果时会根据commit point维护的那个.del文件把已经删除的文档过滤掉
translog日志文件: 为了防止elasticsearch宕机造成数据丢失保证可靠存储,es会将每次写入数据同时写到translog日志中
os cache:操作系统里面,磁盘文件其实都有一个东西,叫做os cache,操作系统缓存,就是说数据写入磁盘文件之前,会先进入os cache,先进入操作系统级别的一个内存缓存中去
refresh操作:将文档先保存在Index buffer中,以refresh_interval为间隔时间,定期清空buffer,生成 segment,借助文件系统缓存的特性,先将segment放在文件系统缓存中,并开放查询,以提升搜索的实时性
flush操作:刷盘操作。删除旧的translog 文件;生成Segment并写入磁盘;更新commit point并写入磁盘。ES自动完成,可优化点不多
底层原理过程解析:
1.1)数据到达主分片之后,并不是直接写入磁盘的,而是先写入到buffer中,此时,这条新的数据是不能搜索到的;同时,在这一步,也会将数据写到translog当中
为什么要这么做?这么说,几乎所有的中间件、应用等【写磁盘】之前都会先写缓存,再由缓存写入磁盘。主要是因为缓存通常位于内存中,相比磁盘,内存的读写速度要快得多。因此,将数据先写入缓存可以减少等待时间,并提高整体的处理速度
1.2)从ES6开始,新增的一步操作。一边写数据到前面说的缓存,一边写数据到translog磁盘文件里面。这个在ES6之前,默认是每30分钟,或者达到一定大小的时候才flush刷盘(发出一个commit命令),接着将segment file文件写入磁盘,清空translog。但是ES6之后,改为每次请求都直接刷盘了
什么是刷盘?刷盘,即直接写入磁盘中。为什么会有这个操作呢?因为操作系统中,也有一个缓存,是作用于系统跟硬盘之间的,道理跟上面说的一样。处处是缓存啊!!!
2) 步骤1.1)的缓存快满了,或者每隔1秒,就会将数据通过refresh操作写到新的的segment file(注意,并不会直接写入到磁盘文件中,还是跟上面一样,先写入属于系统的os cache缓存,再由缓存写入到文件)。同时更新conmmit point。写入后清空buffer
3)当segment被写到os cache的时候,此时segment可以接收外部的搜索了(据说这就是为什么说ES是【近实时】的原因,因为1秒后就能查询到)。最后os cache等待系统命令,即步骤1.2)提到的commit来调用系统函数的fsync同步数据到磁盘中,即真正写入到segment file了
3.1.2 ES读取数据的过程
ES读取数据的过程分两种情况:
1)根据id查询数据的过程
- 根据
doc id进行 hash,判断出来当时把doc id分配到了哪个 shard 上面去,从那个 shard 去查询 - 客户端发送请求到任意一个 node,成为 coordinate node协调节点
- coordinate node协调节点 对
doc id进行哈希路由hash(_id) % shards_size,将请求转发到对应的节点,此时会使用round-robin随机轮询算法,在【主分片】以及其所有【副本分片】中随机选择一个,让读请求负载均衡 - 接收请求的
node返回 文档给coordinate node协调节点 - coordinate node协调节点返回文档数据给客户端
2)根据关键词查询数据的过程:多分片合并
- 客户端发送请求到一个 coordinate node协调节点
- 协调节点将搜索请求转发到所有的
shard对应的primary shard或replica shard,两者都可以 query phase阶段:每个shard将自己的搜索结果返回给协调节点,由协调节点进行数据的合并、排序、分页等操作,产出最终结果fetch phase阶段:接着由协调节点根据doc id去各个节点上拉取实际的文档数据,最终返回给客户端。
写请求是写入 primary shard,然后同步给所有的 replica shard;读请求可以从 primary shard 或 replica shard 读取,采用的是随机轮询算法
3.2 如何提升集群的读写性能
3.2.1 提升集群读性能
想要提升集群读取性能,通常有以下方法:
- 做好数据建模
- 尽量将数据先行计算,然后保存到Elasticsearch 中,以避免查询时的 Script计算
- 尽量使用Filter Context,利用缓存机制,减少不必要的算分
- 结合profile,explain API分析慢查询的问题,持续优化数据模型
- 避免使用*开头的通配符查询
- 优化分片
- 避免Over Sharing。很多时候一个查询需要访问每一个分片,分片过多,会导致不必要的查询开销
- 结合应用场景,控制单个分片的大小
Force-merge Read-only索引。使用基于时间序列的索引,将只读的索引进行force merge,减少segment数量
#手动force merge
POST /my_index/_forcemerge
3.2.2 提升集群写性能
想要提升集群的写性能,首先得知道优化的本质,其实是:增大写吞吐量,越高越好。
按照这个目标,结合我们ES的情况,其实可以分为【客户端写】和【服务端写】来进行优化。
客户端写:
无非就是使用多线程,或者批量写
大家应该知道批量写,bulk的作用吧?其实跟redis的管道一样的道理。不止是redis,事实上很多中间件都会用到这个思想。 【批量写】是为了节省每次跟服务之间的网络IO开销。
甚至,如果大家学过Netty的话,就会发现:连底层网络通信为了节省带宽,也可能等待数据到达一定量,或者达到一段时间后才将数据一起发送出去。这么做的目的就是为了提升网络IO效率
服务端写:注意参考前面3.1说的写原理
服务器端优化写入性能可以通过如下途径:
- 降低IO操作,即:尽量少写东西。比如:使用ES自动生成的文档ld;调整配置参数,如
refresh interval - 降低 CPU 和存储开销。比如:减少不必要分词;避免不需要的
doc_values;文档的字段尽量保证相同的顺序,这样可以提高文档的压缩率 - 尽可能做到写入和分片的均衡负载,实现水平扩展。
Shard Filtering / Write Load Balancer - 调整Bulk 线程池和队列
如果需要追求极致的写入速度,可以牺牲数据可靠性及搜索实时性以换取性能:
- 牺牲可靠性:将副本分片设置为0,写入完毕再调整回去
- 牺牲搜索实时性:增加Refresh Interval的时间
- 牺牲可靠性:修改
Translog的配置
注意:ES 的默认设置,已经综合考虑了数据可靠性,搜索的实时性,写入速度,一般不要盲目修改。一切优化,都要基于高质量的数据建模
3.2.3 其他一些优化建议
1)建模时的优化
- 只需要聚合不需要搜索,index设置成false
- 不要对字符串使用默认的dynamic mapping。字段数量过多,会对性能产生比较大的影响
- Index_options控制在创建倒排索引时,哪些内容会被添加到倒排索引中
2)降低 Refresh的频率
refresh_interval的数值,默认为1s 。如果设置成-1,会禁止自动refresh。这样做有如下作用:- 避免过于频繁的refresh,而生成过多的segment 文件
- 但是会降低搜索的实时性
- 增大静态配置参数
indices.memory.index_buffer_size- 默认是10%,会导致自动触发refresh
3)降低Translog写磁盘的频率,但是会降低容灾能力
Index.translog.durability:默认是request,每个请求都落盘。设置成async,异步写入lndex.translog.sync_interval:设置为60s,每分钟执行一次Index.translog.flush_threshod_size:默认512 m,可以适当调大。当translog 超过该值,会触发flush
4)分片设定
- 副本在写入时设为0,完成后再增加
- 合理设置主分片数,确保均匀分配在所有数据节点上
Index.routing.allocation.total_share_per_node:限定每个索引在每个节点上可分配的主分片数
5)调整Bulk 线程池和队列
- 客户端
- 单个bulk请求体的数据量不要太大,官方建议大约5-15m
- 写入端的 bulk请求超时需要足够长,建议60s 以上
- 写入端尽量将数据轮询打到不同节点
- 服务器端
- 索引创建属于计算密集型任务,应该使用固定大小的线程池来配置。来不及处理的放入队列,线程数应该配置成CPU核心数+1,避免过多的上下文切换
- 队列大小可以适当增加,不要过大,否则占用的内存会成为GC的负担
DELETE myindex
PUT myindex
{"settings": {"index": {"refresh_interval": "30s", #30s一次refresh"number_of_shards": "2"},"routing": {"allocation": {"total_shards_per_node": "3" #控制分片,避免数据热点}},"translog": {"sync_interval": "30s","durability": "async" #降低translog落盘频率},"number_of_replicas": 0},"mappings": {"dynamic": false, #避免不必要的字段索引,必要时可以通过update by query索引必要的字段"properties": {}}
}
学习总结
- 学习了ES的预处理器
- 弄明白了ES的读写流程,以及ES写原理