经验总结
1. 如果总的CPU占用率偏高,且基本都被业务线程占用时,CPU占用率过高的原因跟JVM参数大小没有直接关系,而跟具体的业务逻辑有关。
2. 当设置JVM堆内存偏小时,GC频繁会导致业务线程停顿增多,TPS下降,最后CPU占用率也低了;
3. 当设置JVM堆内存偏大时,GC次数下降,TPS上升,CPU占用率立刻上升。
4. Dom4J 这个xml解析工具性能很强大,但在处理节点和层级都较多的xml文本时,整体解析效率依然会成为业务处理瓶颈。
一、背景说明
最近新项目上线,需要对项目中的一个HTTP接口进行压力测试,以保证接口性能稳定性。该接口涉及到的主要业务是接收HTTP请求,获取请求中的xml报文参数,并将xml报文解析后存入MySQL数据库。接口业务流程如下:

该业务接口部署的服务器配置和部署MySQL组件的服务器配置一致,都是4核8G,50G普通硬盘,并且处于同一个内网网段,我们预估的性能指标要达到200并发,500TPS。
在压力测试过程中,我们重点关注TPS、GC次数、CPU占用率和接口响应时间等指标。
二、测试过程
完成项目部署后,我们开始编辑jemeter测试脚本,设置压力测试的标准为200个并发线程,在10秒内全部启动,持续压测时间15分钟,接着开始启动jemeter脚本进行测试。
1、第一次压力测试
(1)JVM配置
垃圾收集策略包括:老年代启用CMS垃圾收集算法,新生代启用ParNew垃圾收集算法,新生代最大存活周期为15次minorGC,FullGC时使用CMS算法,并开启CMS中的并行标记。
JVM内存分配:最大/最小堆内存为512MB,Eden和Survivor比例为8:2,永久代初始化64MB,最大128MB。
JVM配置参数如下:
-XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:MaxTenuringThreshold=15 -XX:+ExplicitGCInvokesConcurrent
-XX:+CMSParallelRemarkEnabled -Xms512m -Xmx512m -XX:SurvivorRatio=8 -XX:PermSize=64m -XX:MaxPermSize=128m
(2)性能指标监控
top命令观察java线程的CPU占用率(us表示用户进程,sy表示系统进程):

jemeter工具输出的TPS和接口响应时间:

jstat -gcutil {pid} {period_time} 输出GC情况

我们根据上述指标监控的情况可以看出,目前CPU占用率很高,每个CPU上的业务线程都占用了90%以上的CPU时间,年轻代GC次数频繁,平均每秒钟有8次左右,但TPS目前只有400左右。
一开始看到这个情况,我们以为是JVM堆内存分配的不足,导致GC频繁,从而引起CPU的高占用率。所以我们调大了堆内存参数,并进行第二次压力测试。
现在我也找了很多测试的朋友,做了一个分享技术的交流群,共享了很多我们收集的技术文档和视频教程。
如果你不想再体验自学时找不到资源,没人解答问题,坚持几天便放弃的感受
可以加入我们一起交流。而且还有很多在自动化,性能,安全,测试开发等等方面有一定建树的技术大牛
分享他们的经验,还会分享很多直播讲座和技术沙龙
可以免费学习!划重点!开源的!!!
qq群号:110685036
2、第二次压力测试
(1)JVM配置
JVM内存分配:最大/最小堆内存为2048MB,Eden和Survivor比例为8:2,永久代初始化512MB,最大512MB。
JVM配置参数如下:
-XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:MaxTenuringThreshold=15 -XX:+ExplicitGCInvokesConcurrent
-XX:+CMSParallelRemarkEnabled -Xmx2048m -Xms2048m -Xmn1024m -XX:NewSize=640m -XX:MaxNewSize=640m
-XX:SurvivorRatio=8 -XX:PermSize=512m -XX:MaxPermSize=512m
(2)性能指标监控
top命令观察java线程的CPU占用率(us表示用户进程,sy表示系统进程):

jemeter工具输出的TPS和接口响应时间:

jstat -gcutil {pid} {period_time} 输出GC情况:

根据上述指标监控的情况可以看出,这次JVM参数调整后,随着堆内存扩大,年轻代GC次数降低了,平均每秒有2次左右,TPS提高到600左右。但是CPU占用率依然很高,且都为业务进程占用。
从这个性能结果来看,堆内存的增大,可以降低GC频率,提高TPS。但CPU占用率几乎没有变化,可能的原因预计有两个:
第一、业务逻辑中存在耗CPU的计算操作;
第二、业务代码存在锁,导致大量线程在等待锁。
根据这个猜测,我们决定打印出JVM线程快照,看下能否找到线程等待锁的相关信息。
jstack -l {pid} > /log_dir/stack_log.txt 命令输出线程快照信息到指定的目录文件。
在线程快照文件里查找状态为BLOCKED的线程记录,发现出现较多BLOCKED状态的线程是:
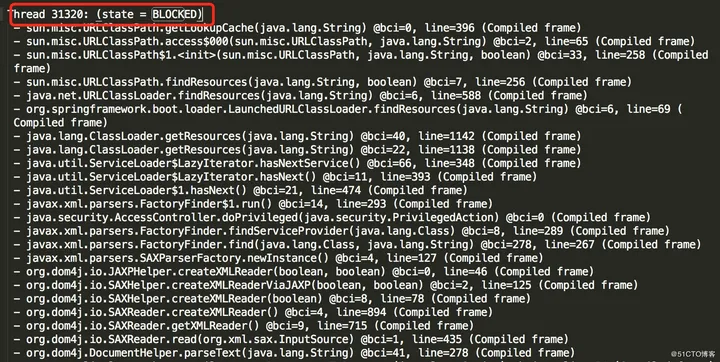
从线程快照来看,大量xml解析线程处于BLOCKED状态,xml解析的业务处于阻塞状态,降低了接口处理效率。
接着我们把接口代码中其他逻辑代码屏蔽,只留下xml解析代码,发现CPU占用率依然在90%以上,而一旦把xml解析代码屏蔽,留下其他业务代码,CPU占用率马上降低到了70%,TPS上升,GC次数下降并保持稳定。
从上面这些处理的结果来看,CPU占用率过高的原因跟JVM参数大小没有直接关系,而跟xml参数解析有关,因为xml参数报文包含十几个节点,层级也较多,解析后生成的都是比较复杂的大对象。
当设置JVM堆内存偏小时,GC频繁会导致业务线程停顿,TPS下降,最后CPU占用率也低了;
当设置JVM堆内存偏大时,GC次数下降,TPS上升,CPU占用率立刻升高到95%以上。
由于我们对xml参数解析使用的是dom4j的方法,所以没办法在xml解析上面进行优化,只能在JVM参数和并发数上进行处理。
最终为了平衡CPU占用率、TPS、GC三个方面的指标,考虑业务实际场景,我们设置JVM堆内存为1.5G,限制TPS为200。
END今天的分享就到此结束了,点赞关注不迷路