导语:本文主要介绍了基于BERT的文本分类方法,通过使用huggingface的transformers库实现自定义模型和任务。具体步骤包括:使用load_dataset函数加载数据集,并应用自定义的分词器;使用map函数将自定义分词器应用于数据集;使用filter函数过滤数据集中的不必要字段;使用batch函数将处理后的数据集批处理;使用DataCollatorWithPadding将批处理后的数据集进行整理;将整理后的数据集传递给模型进行训练。在transformers库中,可以使用AutoModel和AutoTokenizer分别加载预训练模型和Tokenizer。对于文本分类任务,可以使用SequenceClassifierOutput类定义任务的输出。在训练模型时,可以使用DataCollatorForLanguageModeling对数据进行排序和分割。最后,使用Trainer类对模型进行训练和评估
一、Tokenizer
1.1 Tokenizer 初介绍
在前文也介绍过,NLP 中重要的一环就是数据预处理,那么在数据预处理过程中,我们会完成那些任务呢?一般来说会分为以下四步:
1.分词:将自然语言分解成字或者词。
2.创建词典:根据分词结果,构建相应映射词典。
3.数据转换:将词典中的文本序列转换为数字序列。
4.数据填充与截断:通过截断、填充,将数字序列进行长度的统一。
Tokenizer则是集上述过程为一体的工具,有了它,就可以轻松实现上述所有步骤,实现数据预处理。
1.2 Tokenizer 核心逻辑
Transformers 中提供了AutoTokenizer方便开发者使用,有了它我们只要提供 models 名字,就可以自动去选择分词器完成分词!(对于怕麻烦的人来说简直不要太友好,无需在记忆相应的API或查阅文档)
分词步骤:构建分词器->句子分词->查看词典->索引转换->填充截断,AutoTokenizer提供了每一步骤实现的函数,感兴趣的同学可以跟着下列代码输出各步骤得到的结果,了解分词的具体过程。当然,强大的AutoTokenizer也支持直接输出最终结果。
from transformers import AutoTokenizerstr = "我最喜欢学 ai!"tokenizer = AutoTokenizer.from_pretrained("uer/roberta-base-finetuned-dianping-chinese")#随便加载一个 model 的分词器tokenizer.save_pretrained("./test")#可以保存分词器到本地
tokenizer = AutoTokenizer.from_pretrained("./test/")#直接用本地的分词器 无需远程#分词
tokens = tokenizer.tokenize(str)
print(tokenizer.vocab,tokenizer.vocab_size) #打印词典词典长度# 索引转换(文本序列->数字序列)
ids = tokenizer.convert_tokens_to_ids(tokens)
# 索引转换(数字序列->文本序列)
tokens = tokenizer.convert_ids_to_tokens(ids)#字符转数字序列
#默认encode会在字符串开头添加cls 末尾添加 sep(bert的标记位), add_special_tokens=true取消添加
ids = tokenizer.encode(str, add_special_tokens=True) # 会把长度填补到 15
inputs_res = tokenizer.encode_plus(str, padding="max_length", max_length=15 )
# input_ids:字符的->id的集合
# token_type_ids:标记字符属于哪一个字符串
# attention_mask: 标记真实/填充位 1 为真实 0 为填充print(inputs_res)
# 结果:{'input_ids': [101, 2769, 3297, 1599, 3614, 2110, 8578, 106, 102, 0, 0, 0, 0, 0, 0],
# 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], //标识是否是一个句子
# 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0]}//后 6 位是填补的
1.3 Tokenizer 应用
在实际使用过程中,分词流程一般记住以下两点就可以了:
1.将句子分成词/字/特殊字符(这里可以自己设置所需,后文会陆续介绍)。
2.完成 token-> id,并获取一些额外信息, 以distilbert-base-uncased-finetuned-sst-2-english(情感分析 model)为例,使用方法如下:
# 分词 demo
from transformers import AutoTokenizer
model_name="distilbert-base-uncased-finetuned-sst-2-english"
tokenizers=AutoTokenizer.from_pretrained(model_name)
strArr=['I have a dream','yes']
inputs=tokenizers(strArr, padding=True,truncation=True,return_tensors="pt")
print(inputs)
借助AutoTokenizer+from_pretrained()就可以快速构建一个分词器,完成“傻瓜式“分词操作。不过在使用分词器的时候还是要注意有一些额外的参数,常用的如:padding、truncation、retuen_tensors等
{'input_ids': tensor([[101, 151, 9531, 143, 10252, 102],[101, 9719, 106, 102, 0, 0]]),
'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0],[0, 0, 0, 0, 0, 0, 0, 0]]),
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1],[1, 1, 1, 0, 0, 0, 0, 0]])}
有一些参数在使用过程中有一些注意事项,比如常用的padding可以取"max_length" 、“longest”,默认会取 longest也就是以最长的句子为准进行补齐操作;max_length可以设置为指定值,当max_length值小于分词的长度,如果不设置truncation=True,则超出部分并不会被截断;token_type_ids标识是否为一句话,常在句子合并中使用 比如两个句子合并成一句,token_type_ids能准确区分出合并的句子成分是从属于元数据中的哪一句…最后贴一个 huggingface 文档 https://huggingface.co/docs/tokenizers/index
二、Datasets
2.1Datasets初介绍
Datasets是一个数据集加载库,通过它我们可以轻松加载本地或者 Huggingface 提供的数据集。
# pip datasets之后
from datasets import *
加载远程数据时的常用操作:
1.划分加载数据集(load_dataset——split):默认数据集一般会分为train(训练集)、validation(验证集)、两部分,加载过程中可以通过设置split参数决定加载哪一部分,举个例子:
dataset=load_dataset("madao33/new-title-chinese",split="train")
split=“train”,表示只加载训练集,如果split="train[:100]"则表示加载前 100条数据,加载数据的时候支持切片语法,也可以按照百分比进行dataset切片split=“train[:50%]”,split也接受数组类型的参数,比如想将 train 分两次加载,可以写成:splint=[“train[:50%]”,“train[:50%]”],类比一下也可以组合加载validation和 train~具体看所需
如果数据集为复合类型的,即包含一些子任务,比如加载 super_glue数据集的 rte 任务,在 huggingface 的docs会指明包含的任务
dataset=load_dataset("super_glue","rte")
2.数据集划分(train_test_split——test_size):加载dataset 之后我们可以指定测试集大小,例如,test_size=0.2表示将20%的数据划分为测试集,而80%的数据将用于训练集。 在实际应用中往往配合stratify_by_column参数,使划分更加均衡,如按照 label 均衡划分
dataset.train_test_split(test_size=0.2,stratify_by_column="label")
3.选取加载数据集(select):接收的参数为数组类型,从而实现数据的选取,区间为闭开区间
dataset.select([1,3])
#输出结果:Dataset({features: ['title', 'content'],num_rows: 2}) 就意味着过滤出了1,2 两个索引下的两条数据。
4.过滤加载数据集(filter):通过 filter 方法可以实现数据集的划分:
dataset["train"].filter(lambda content: "原标题:中国北京世界园艺博览会" in content["content"])
#输出结果:Dataset({features: ['title', 'content'],num_rows: 1}) 就意味着只过滤出了一条。
5.查看数据集内容(通过索引):数据集的结构是 dict,所以想要取具体的数据集内容,直接按照 dict 的取值方法即可,比如我想要取 train 中的第一条:
print(dataset["test"][1])
6.数据映射(map):处理数据的时候,往往要对数据进行一些操作处理,这个时候可以通过 map 方法,调用一个函数,函数的逻辑则为操作逻辑,比如为每个数据的 title加“example”前缀:
def add(str):str["title"] = "example" + str["title"]return str
dataset.map(add)
print(dataset.map(add)["train"][:10]["title"])
7.保存数据到本地与加载(save_to_disk、load_from_disk):当对数据处理完成之后,可以直接存到本地,再次使用的时候就可以直接加载.
dataset.save_to_disk("./dataset_data")
dataset= load_from_disk("./dataset_data")
加载本地数据时的常用操作:
加载数据集文件(load_dataset/Dataset.from_xxx):加载的方法和上述的远程加载使用同一个,只是在设定参数上有一定区别,格式如下:
dataset = load_dataset("csv", data_files="./test.csv", split="train")
也可以对应数据集类型直接调用方法from_xxx xxx取决于文件名后缀:
dataset = Dataset.from_csv("./test.csv")
多个数据集文件的时候可以通过文件夹进行批量加载(指定文件夹路径即可):
dataset = load_dataset("csv", data_files="./test/", split="train")
2.2Datasets+tokenizer 使用
在实际训练模型的过程中,数据集肯定是要结合分词器一起使用,处理成机器能够识别的序列,然后喂给 model。在实际开发中,经常将上述tokenizer 和 map 方法结合起来,举个例子:
def tokenizer_def(str):return tokenizer(str["title"])
tokenizer_dataset=dataset.map(tokenizer_def,batched=True)[:8]
上述函数就将数据集中的 title 字段,进行了标记,同时处理多个文本样本时,启用batched=True可以显著提高分词的效率。


可以看到其实就是文本内容+ tokenizer 生成的内容组合到一起,没有什么高深的,不过我们在想一下,当生成 token 之后,我们其实就不需要原文本了,那我们就可以把转换前的原文本删掉,并且现在的数据格式还不是最终model 想要的,我们需要近一步整理这些数据:
sample={k: v for k, v in tokenizer_dataset.items() if k not in ['title', 'content']}
不了解 py 的同学可以看下这段解释,大神自动忽略…这是一个字典推导式,用于从名为tokenizer_dataset的字典中筛选出那些键不在[‘title’, ‘content’]中的键值对,并将它们构成一个新的字典。{k: v}:表示创建一个新字典,其中的键为k,值为v。循环语句会遍历tokenizer_dataset字典中的每一个键-值对,将键赋值给变量k,将值赋值给变量v。并检查当前循环中的键k是否不在[‘title’, ‘content’]列表中。
除了上述的函数自处理方式,也可以通过 datasets.map() 函数中的remove_columns 参数,移除指定的列(字段),可移除的字段不包括:input_ids 、token_type_ids、attention_mask等…也就是标记过程中,分词器自动生成的属性。
tokenizer_dataset=dataset.map(tokenizer_def,batched=True,remove_columns=['title', 'content'])[:8]
这句代码和上面的作用是一样的~是不是更简洁呢
在实际生产中,对于数据的处理大多都是批量的,就会用到DataCollatorXXX
去处理这些批量数据,打包成一个一个的 batch,但是DataCollator官方库只会处理默认的tokenizer 生成的字段:input_ids 、token_type_ids、attention_mask等… 若数据中还有其他自定义字段,则不能调用DataCollator进行处理,所以再把数据喂到DataCollator前,先剔除多余的字段,确保将“纯净的、标记后的”数据喂给 models。以DataCollatorPadding 为例子:
from transformers import DataCollatorWithPadding
data_collator=DataCollatorWithPadding(tokenizer=tokenizer)
batch=data_collator(sample)
这里说一下我本人在处理数据的时候遇到的一个混淆点(大神可跳过):
最初我理解,如果利用 def 函数调用 tokenizer 将数据标记,然后再传入到DataCollatorWithPadding(tokenizer=tokenizer),这个过程就重复了,误以为tokenizer=tokenizer 是标记化的过程,其实不然,这里指定的tokenizer不是用来进行标记化,而是为了将预先创建的 tokenizer 对象传递给 DataCollatorWithPadding,以便在数据整理过程中使用相同的 tokenizer。并且DataCollatorWithPadding只接受标记化后的数据而不是文本数据,所以先标记化是必须的!否则会报错的 。
现在生成的 batch 就是标准化格式的了,可以喂到 models 中去了。
最后再贴一个社区已经提供给我们 docs : https://huggingface.co/docs/datasets/index
三、Model
3.1 Model 初介绍
当数据预处理进行完之后,就要将数据“喂”到model中去,先来理解两个model 中的基本概念:编码器(Encoder)、解码器(Decoder)。
Encoder接收输入的内容并构建固定长度的向量。Decoder则使用Encoder的编码结果以及其他信息或数据(例如:每个样本对应的标签或类别信息、环境变量),输出最终目标结果,无论是编码器还是解码器,都是由多个TransformerBlock组成的,TransformerBlock主要由两个子模块组成:注意力机制(attention mechanism)和前馈神经网络(FFN),注意力机制可以选择性获取上下文信息,并对每个位置进行编码;前馈神经网络则可以对自注意力机制的输出进行进一步处理,以提取更高层次的特征表示。数据流如下:
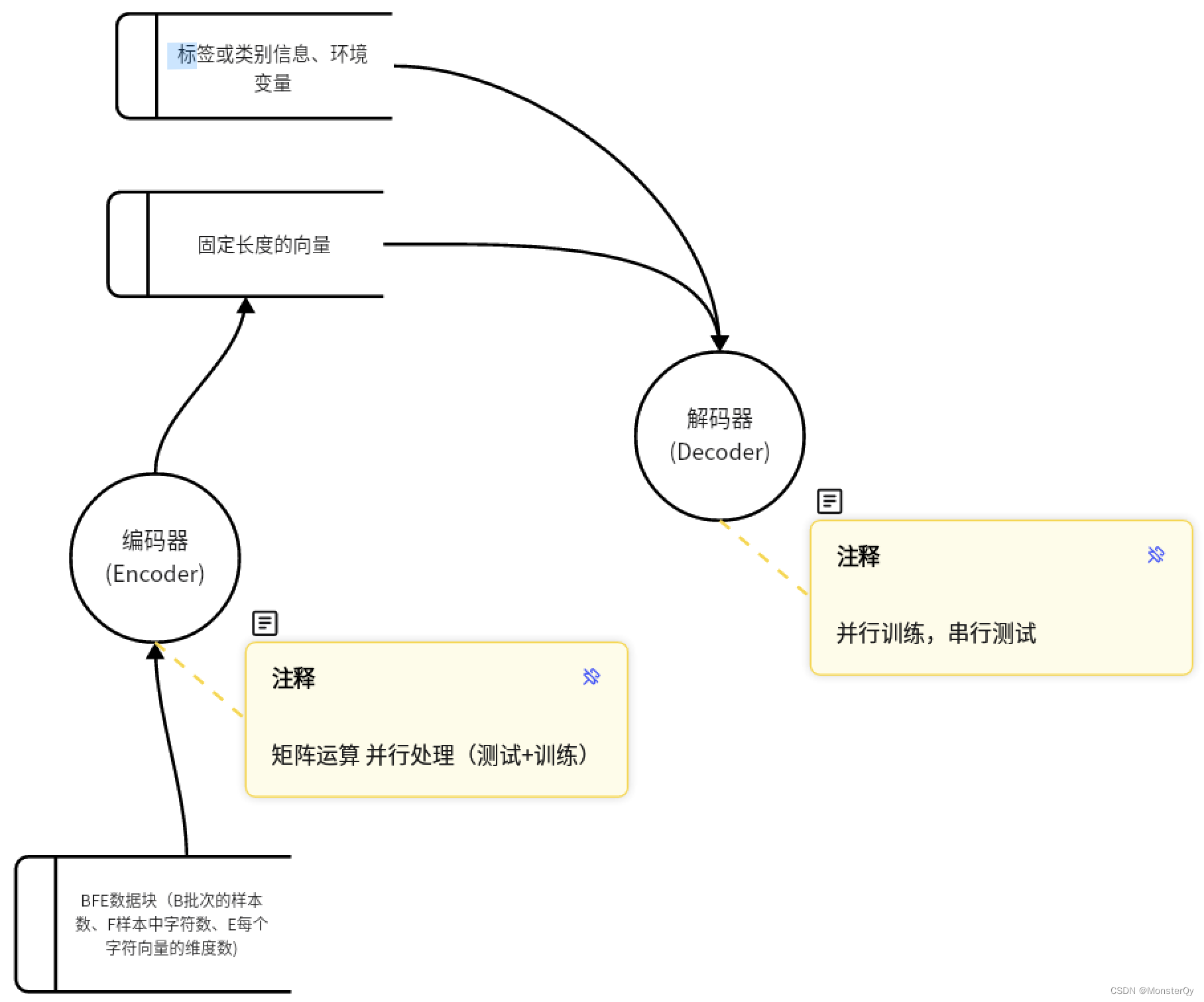
通过编码器和解码器的搭配使用,model可以被分为一下三种类型:
1.编码器模型:自编码模型(无监督学习),双向注意力机制,考虑输入序列当前位置之前和之后的所有信息,对每个位置进行编码时都可以看到完整上下文。常被用来实现文分类、阅读理解,实现BERT、ALBERT、RoBERTa等预训练模型。
2.解码器模型:自回归模型(生成模型),单向注意力机制,只考虑输入序列中当前位置之前的信息,对每个位置进行编码时,只可以看到上文,看不到下文。常被用来实现文本生成任务,实现GPT、Bloom、LLaMA等预训练模型。
3.编码器解码器模型:序列到序列模型(生成模型)Encoder部分使用双向注意力机制,Decoder 部分使用单向注意力机制。常被用来实现文本摘要、机器翻译任务,实现BART、GLM、Marian等预训练模型。
Model Head :如果只用Model去处理Token,那么只会返回编码结果,并不能返回我们想要的最终结果哦。这个时候就需要利用Model Head,它可以对 Model 输出的结果进行进一步映射,从而解决任务。在NLP中所有的任务其实都是分类任务,仔细思考一下,对于分类任务来说,其本质区别就是分类位置的不同,那为了实现这个“不同”,我们就可以去选择不同的输出头去完成~从输入 token 到最终输出结果的流程图如下:
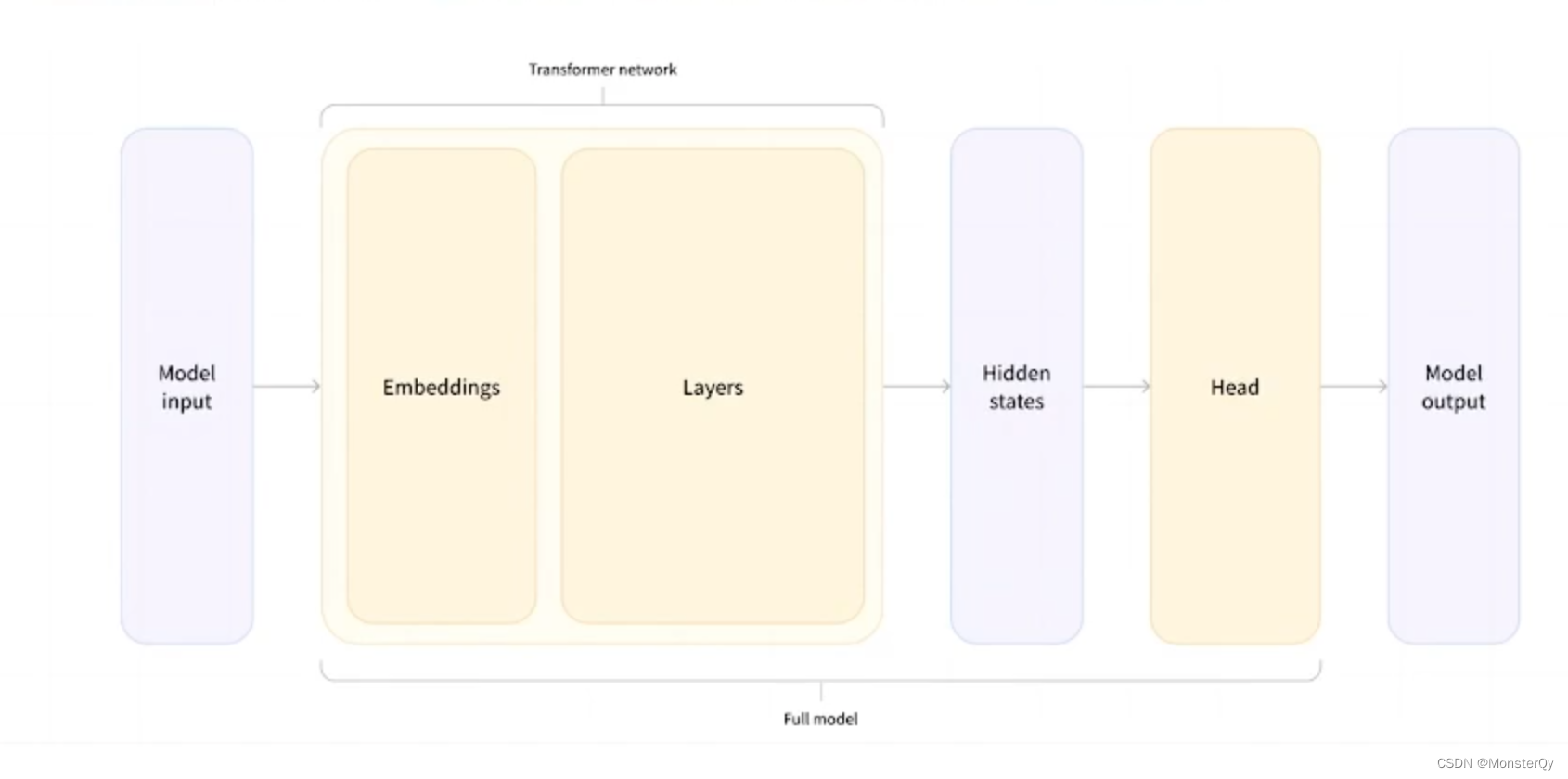
3.2 Model 及ModelHead使用
类似于Tokenizer,model 在使用的时候也是利用Automodel 就可以直接实现模型的加载使用了(inputs来自于上文 tokenizer)
from transformers import AutoModel
model=AutoModel.from_pretrained(model_name)
model_output=model(**inputs)
print(model_output.last_hidden_state.shape)# torch.Size([2, 6, 768])
输出结果中的2 代表有 2 个文本数据,6 则为分出的 token 数目,768为固定输出的一个向量。
ModelHead使用方式和 tokenizer、model 也是大同小异,
# modelHead demofrom transformers import AutoModelForSequenceClassification
model_for_head=AutoModelForSequenceClassification.from_pretrained(model_name) model_for_head_output=model_for_head(**inputs)
print(model_for_head_output)
#SequenceClassifierOutput(loss=None, logits=tensor([[-3.7845, 4.0785],
#[-4.0741, 4.3500],
#[ 3.1336, -2.5025]], grad_fn=<AddmmBackward0>), hidden_states=None, attentions=None)
输出结果中可以看到,这个 modelhead 对于每一个词进行了 2分类,分类成几个是可以通过参数num_labels进行设定的,如下代码就是分成了 10 类。(记得加ignore_mismatched_sizes=True 否则会报错)
model_for_head=AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=10, ignore_mismatched_sizes=True)
补充一下,huggingface为了方便用户能够快递的了解到model 在使用时可以配置的 config,还提供了“AutoConfig”,也就是说在调用 model 的时候,想要知道可以配置哪些参数,无需死记硬背API,可以直接利用config查看源码:
from transformers import AutoConfig
config=AutoConfig.from_pretrained(model_name)
print(config,'config')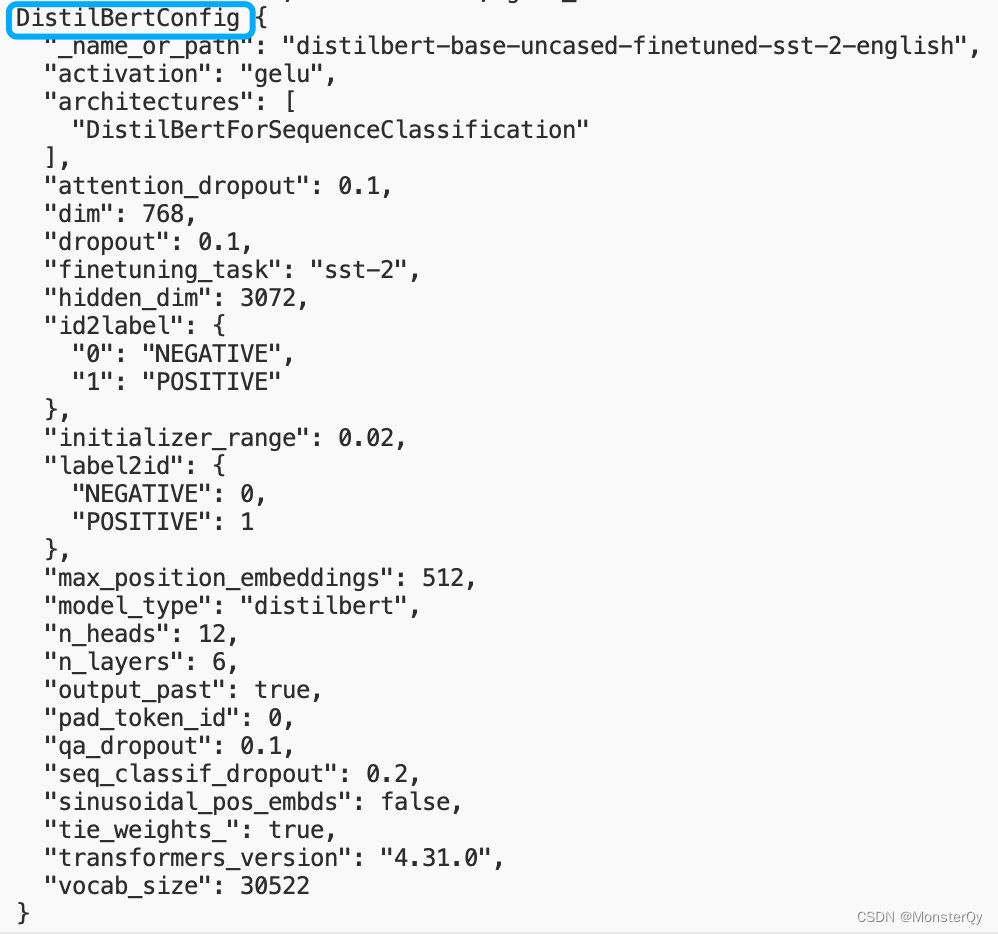
可以看到该模型的 config 类型为DistilBertConfig,那我们就可以直接在 transformers 中导入这个包,然后跳转到源码中查看,如下图就是可以利用的 args,并且需要注意的是DistilBertConfig继承于PretrainedConfig,所以也要去查看PretrainedConfig中的 args(在实际应用中更多的是使用PretrainedConfig中声明的args)
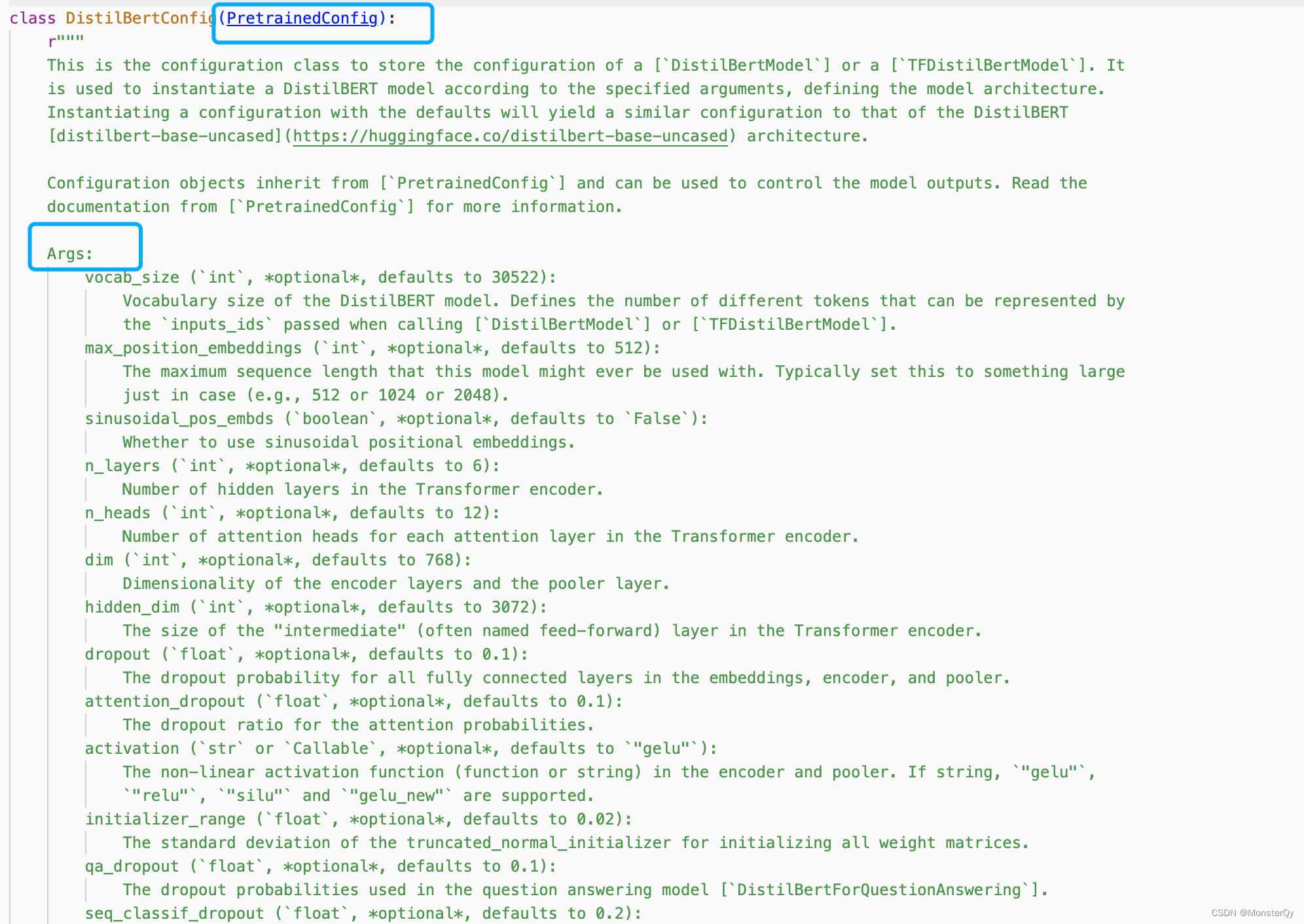
老规矩,贴一个官方链接 https://huggingface.co/models
四、 Evaluate
4.1 Evaluate 初介绍
如果说model、tokenizer 、dataset是训练模型必需品,那evaluate的作用就是锦上添花,它可以帮助你监控性能、调整超参数、选择模型,并生成性能报告。使用起来还是十分简便的
使用起来依旧是老方法——安装pip install evaluate->调用API即可
常用的 api 如下:
1.查看支持的函数list_evaluation_modules()
print(evaluate.list_evaluation_modules())
如上图所示就会打印出来evaluate所有支持的函数。
2.加载函数load()
cuad=evaluate.load('cuad')
加载成功在此基础上可以直接对此评估函数调用.inputs_description 查看函数的使用详情
print(cuad.inputs_description)
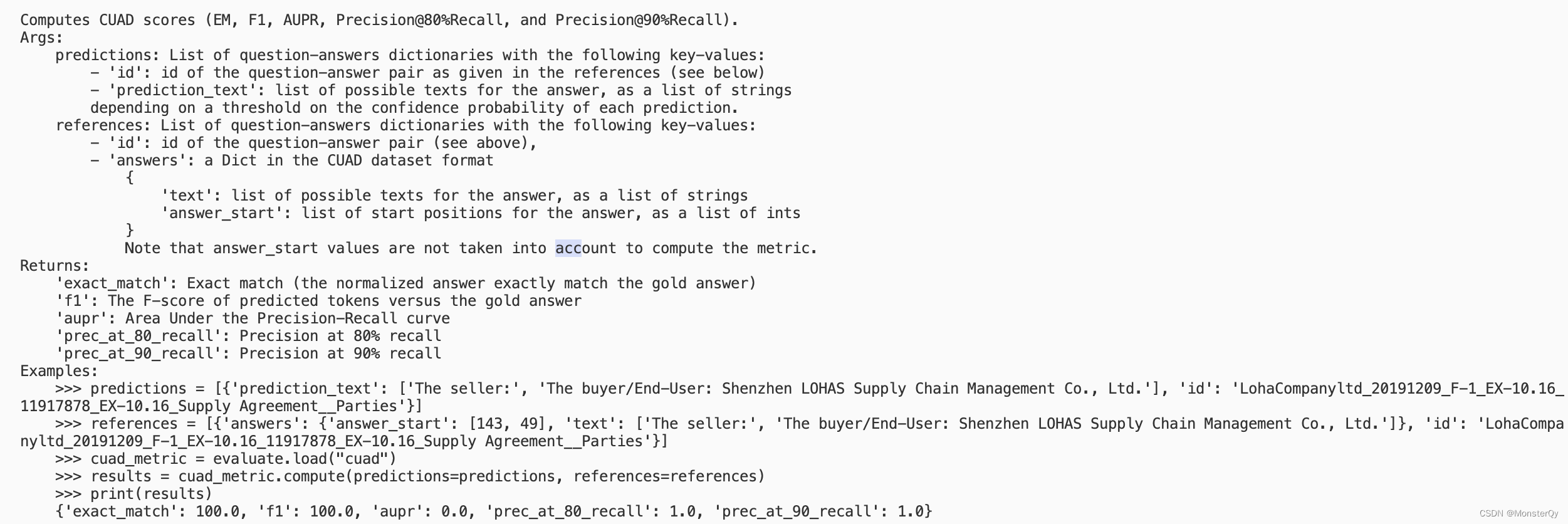
如上图,这个函数需要两个参数,参数的格式为词典,并且明确指明了 key-value , return 5 个值 每个值的作用,以及最后给出了一个完整的使用示例。
除了inputs_description ,也可以直接在加载函数成功之后打印函数本身print(cuad) 也能获取到相应的使用说明+函数本身的一些属性。
ps: load其他evaluate函数,如 f1的时候,报错ImportError: To be able to use evaluate-metric/f1, you need to install the following dependencies[‘sklearn’] using ‘pip install sklearn’ for instance’ 但是 pip install sklearn之后仍无效,后来通过以下命令成功解决此问题:
pip install scikit-learn
3.计算compute()
全局计算:将所涉及的所有参数直接按照打印出来的格式塞到计算函数中 。
predictions = [{'prediction_text': ['The seller:', 'The buyer/End-User: Shenzhen LOHAS Supply Chain Management Co., Ltd.'],
'id': 'LohaCompanyltd_20191209_F-1_EX-10.16_11917878_EX-10.16_Supply Agreement__Parties'}]references = [{'answers': {'answer_start': [143, 49],
'text': ['The seller:', 'The buyer/End-User: Shenzhen LOHAS Supply Chain Management Co., Ltd.']},
'id': 'LohaCompanyltd_20191209_F-1_EX-10.16_11917878_EX-10.16_Supply Agreement__Parties'}]
results = cuad.compute(predictions=predictions, references=references)
迭代计算(add_batch):在实际训练中,我们常常会对数据以 batch 为单位进行计算。
for refs, preds in zip([references,references], [predictions,predictions]):cuad.add_batch(references=refs, predictions=preds)
print(cuad.compute()) #我直接组合了上述参数作为 batch
这样的输出结果和results是一样的
4.组合计算combine()
上述的评估函数是可以组合到一起进行组合计算的,例如:
combine_evaluate = evaluate.combine([“accuracy”, “cuad” ])
就会输出每一个函数下的结果,便捷~
5.结果可视化
上述输出的结果大多都是数字,不够直观,你可以选择自己调用matplotlib进行数据可视化,也可以直接使用evaluate 中提供的功能,目前evaluate提供了雷达图(暂时只有一种,这里插一句可以通过源码,看出来有没有更新)供我们评估结果可视化:
from evaluate.visualization import radar_plot
combine_evaluate = evaluate.combine(["accuracy", "cuad" ])
data = [
{"accuracy": 0.59, "cuad": 0.6, "f1": 0.75, "ter": 10.6},
{"accuracy": 0.48, "cuad": 0.17, "f1": 0.11, "ter": 10.2},
{"accuracy": 0.18, "cuad": 0.38, "f1": 0.38, "ter": 75.6},
{"accuracy": 0.18, "cuad": 0.48, "f1": 0.41, "ter": 141.6}
]
model_names = ["Model1", "Model2", "Model3", "Model4"]plot = radar_plot(data=data, model_names=model_names)
plot.show()
五、 Trainer
有了上述一些列的操作,我们就可以正式开启我们的diy训练了 撒花🌸~其实训练模型在 huggingface 的帮助下已经变成了各种api调用(感激不尽)所以, trainer 过程依旧如此!
5.1 Trainer 初介绍
trainer()是一个用于训练和评估模型的高级训练器。它提供了一个简化的接口,可以轻松地进行模型训练、评估和推理。
使用trainer可以实现以下功能:
数据加载和预处理:处理数据加载、批处理、分布式训练等数据处理任务。
模型训练:自动执行模型的训练过程,包括前向传播、反向传播和参数优化。
模型评估:计算模型在验证集或测试集上的性能指标,如准确率、损失等。
模型保存和加载:保存和加载训练好的模型,方便后续使用或部署。
学习率调度:支持学习率的自动调整,可以根据训练过程中的性能动态调整学习率。
提前停止:根据验证集性能的变化情况,在模型性能不再提升时自动停止训练,避免过拟合。
不过,在使用 trainer 的时候需要注意,它对模型的输入和输出是有一定限制的,要求模型返回元组或者 modeloutput 的子类。并且若输入中提供了 labels,模型需要返回 loss 结果,若输入的是元祖类型的数据,则要求loss 为元组中的一个值。听起来有一点高深,但是不要担心,目前huggingface 自带的模型是符合要求的,这些是在对模型进行修改时需要考虑的因素。
官方文档链接: https://huggingface.co/docs/transformers/main_classes/trainer#trainer
5.2 trainer 初体验
依旧是老套路,从 transformer 中导入Trainer
from transformers import Trainer
声明,然后 hover 一下,就可以看到支持的所有参数,我们来一个一个说明一下
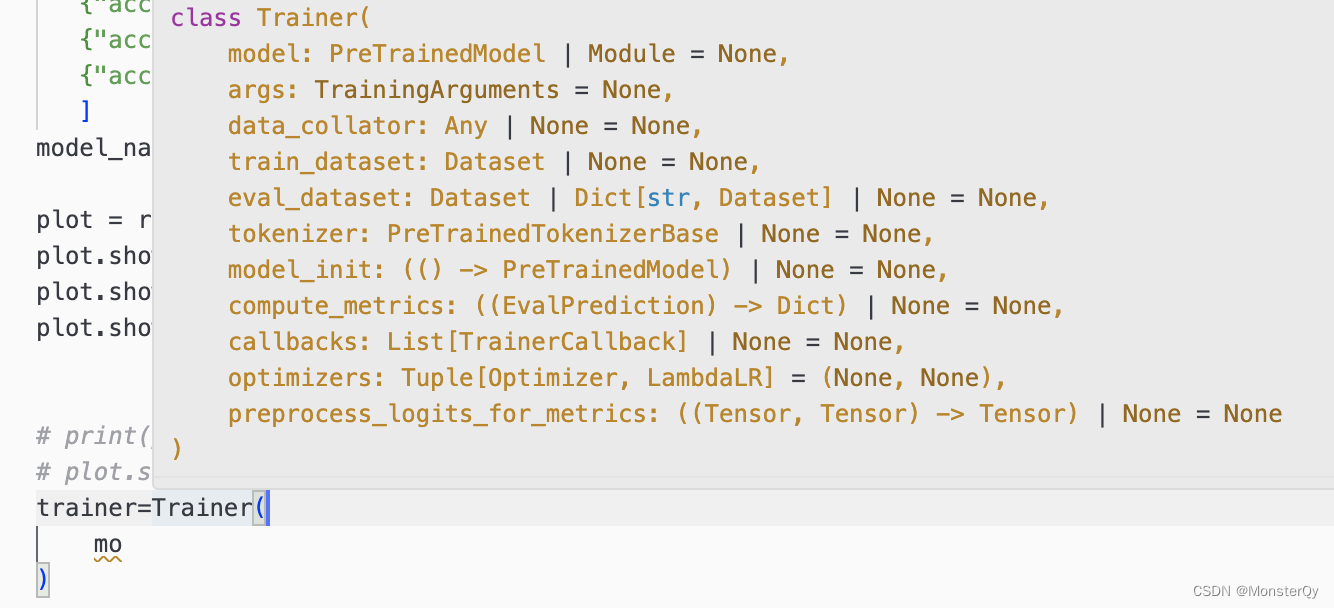
上文介绍的model、data_collator、train_dataset、eval_dataset、tokenizer直接指定就好了,这里不再赘述。其他的参数可以看官网介绍
https://huggingface.co/docs/transformers/v4.32.1/en/main_classes/trainer
值得一提的是对于args的设置,可以通过导包➕结合文档的方式 快速添加参数。
from transformers import TrainingArguments
training_args=TrainingArguments('test-trainer')
print(training_args)
#加载训练模型
trainer=Trainer(
model,
data_collator,
tokenizer,
train_dataset=tokenizer_dataset[:10],
eval_dataset=tokenizer_dataset[10:2],
args=training_args
)
print(trainer.train())
至此,我们就成功跑通实现了模型的训练~
六、pipeline
6.1 pipeline 初介绍
继入门篇(一)顺利安装环境并成功跑通一个 demo的童鞋们,肯定有一点疑惑,我们之前明明用的是 pipeline,怎么你在这篇文章闭口不提了?
别急,有了上述的基础概念,现在来聊聊pipeline。它翻译过来是流水线,也就是说它是代表一个连贯性的功能,在pipeline中处理任务可以大致分为三步,通过“流水线”对数据进行预处理(Tokenizer),然后调用模型(Model),最后处理结果(Post Processing)。细致化来讲就是:
加载模型和预训练的 tokenizer。
预处理输入数据,将文本转换为标记化序列。
将标记化序列输入到模型中。
处理模型输出并根据任务返回相应的结果。
至此,我相信你一定豁然开朗了,在我们想要测试一个 model 的时候,可以直接用pipeline 测试效果,但如果我们想玩点什么,就要自己处理数据,加载 model,进行 train。
不过 pipline支持的任务类型也是有限的,他支持 huggingface 大部分任务,但并不支持所有哦!在社区我们可以看到目前任务可以被分为以下几大类(这里要区分一下任务和模型,任务是模型的父级,如下图红框为任务,蓝框为模型):
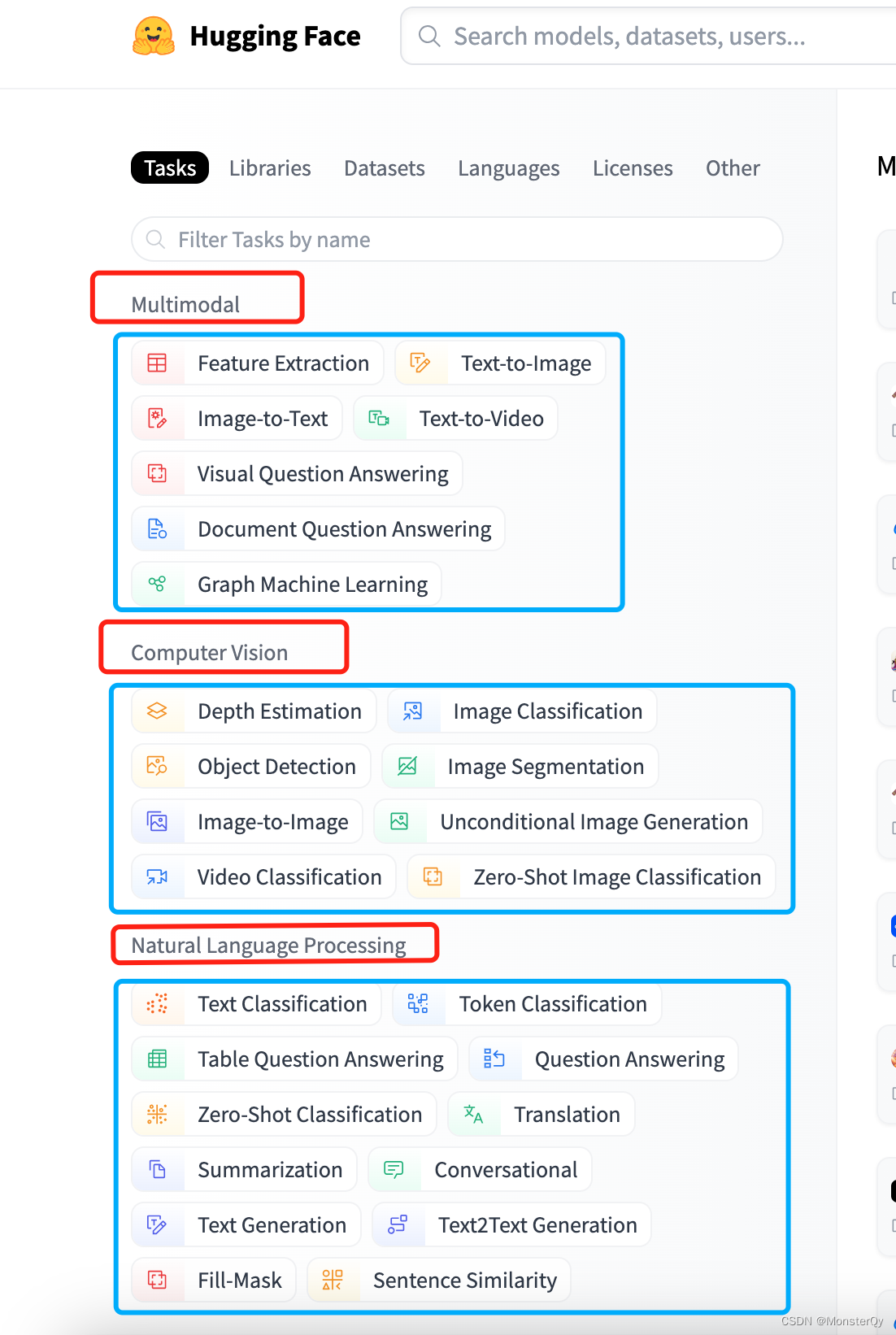
1、Multimodal:多模态任务中的模型可以处理多种类型的数据,如文本、语音、图像和视频等。在模型中将多个信息进行融合,从而提高对自然语言的理解和生成能力。例如,在Text-to-Image中,Multimodal可以将自然语言文本转换为图像,带来新的应用和发展机会。
2、 Computer Vision:计算机视觉任务中的模型可以处理与图像和视频相关的自然语言文本,用于图像和视频的生成、标注、分类和检索等任务。例如,在Depth Estimation中,估计图像中的物体信息,通过对其进行分析和建模来推断深度信息,从而可以被应用到VR等技术中去。
3、Natural Language Processing:自然语言处理任务中的模型的目标是让计算机能够理解、处理和生成自然语言文本。NLP技术可以应用于多种场景,例如,在Text Classification中,可以实现将给定的文本分配到预定义的类别中,帮助用户更快、更准确地处理大量文本数据。
4、Audio:音频任务中的模型的目标是处理音频相关的任务,例如语音识别、语音合成、音频分类等。例如,在Automatic Speech Recognition中,将语音转换为计算机可以理解和处理的文本数据,从而实现语音交互、搜索、翻译等应用。
5、Tabular:表格任务中的模型提供了各种用于表格数据处理和分析的深度学习模型。例如,在Tabular regression中,则可利用表格数据进行回归分析,预测各类连续性变量,如基金股票价格、生产效率等。
6、Reinforcement Learning:强化学习任务中的模型通过让计算机在不断的交互中试错学习,以达到最优的决策。在强化学习中,计算机会根据当前状态采取某种行动,并通过环境的反馈来调整自己的行为策略,以获得最大化的长期奖励。
目前pipeline中的任务类型,除了最后两个,其他的都有一定量的覆盖,可以通过以下代码进行查看
from transformers.pipelines import SUPPORTED_TASKS
print(len(SUPPORTED_TASKS.items())) //支持的任务数量
for k, v in SUPPORTED_TASKS.items():
print('模型', k) //k是模型
输出结果

6.2 pipeline 初体验
虽然在(一)中带着大家执行了一个demo 但是还是不够流程化, 这里再次规范化介绍一下pipeline使用步骤
1.从 transformers 中引入 pipeline,
from transformers import pipeline
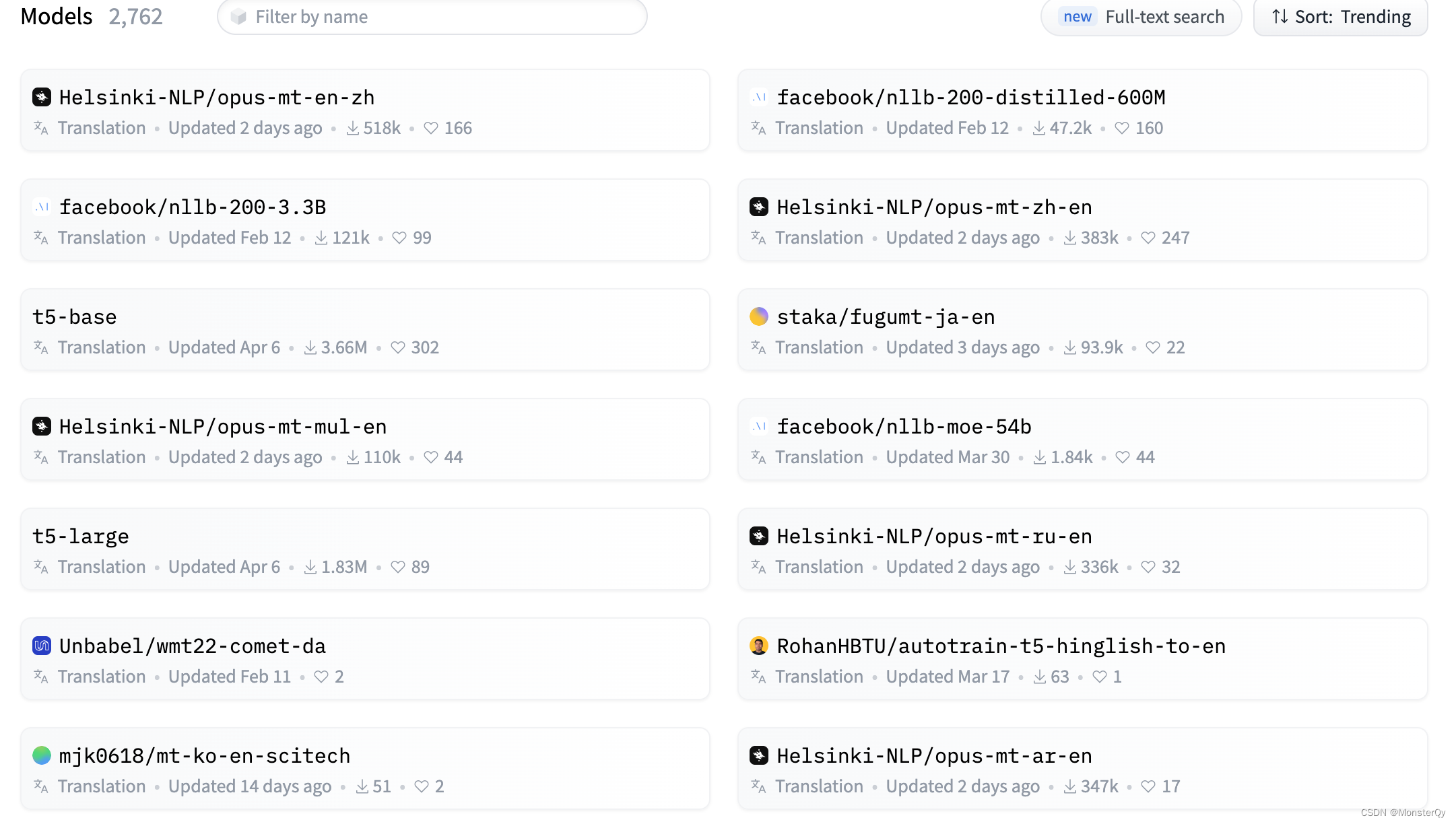
2.根据需求,创建一个流水线任务,可选的任务就是刚才输出的SUPPORTED_TASK.item(),model 则可以去 huggingface 下(如下图) 找到想要用的,语法如下:
pipe = pipeline("question-answering", model="uer/roberta-base-chinese-extractive-qa")
流水线创建好了,但是怎么去传参,然后落地使用呢,有两种方法
1、直接看huggingface 社区文档()
2、通过编译器:
以上面的 pipe为例,当构建好一个流水线之后,我们可以直接打印出来:

可以看到这个任务所属类型为QuestionAnsweringPipeline,然后跳转到 transformers 源码库里(鼠标 hover+ctrl),全局搜索
然后跳转到,可以看到它的参数和返回值:
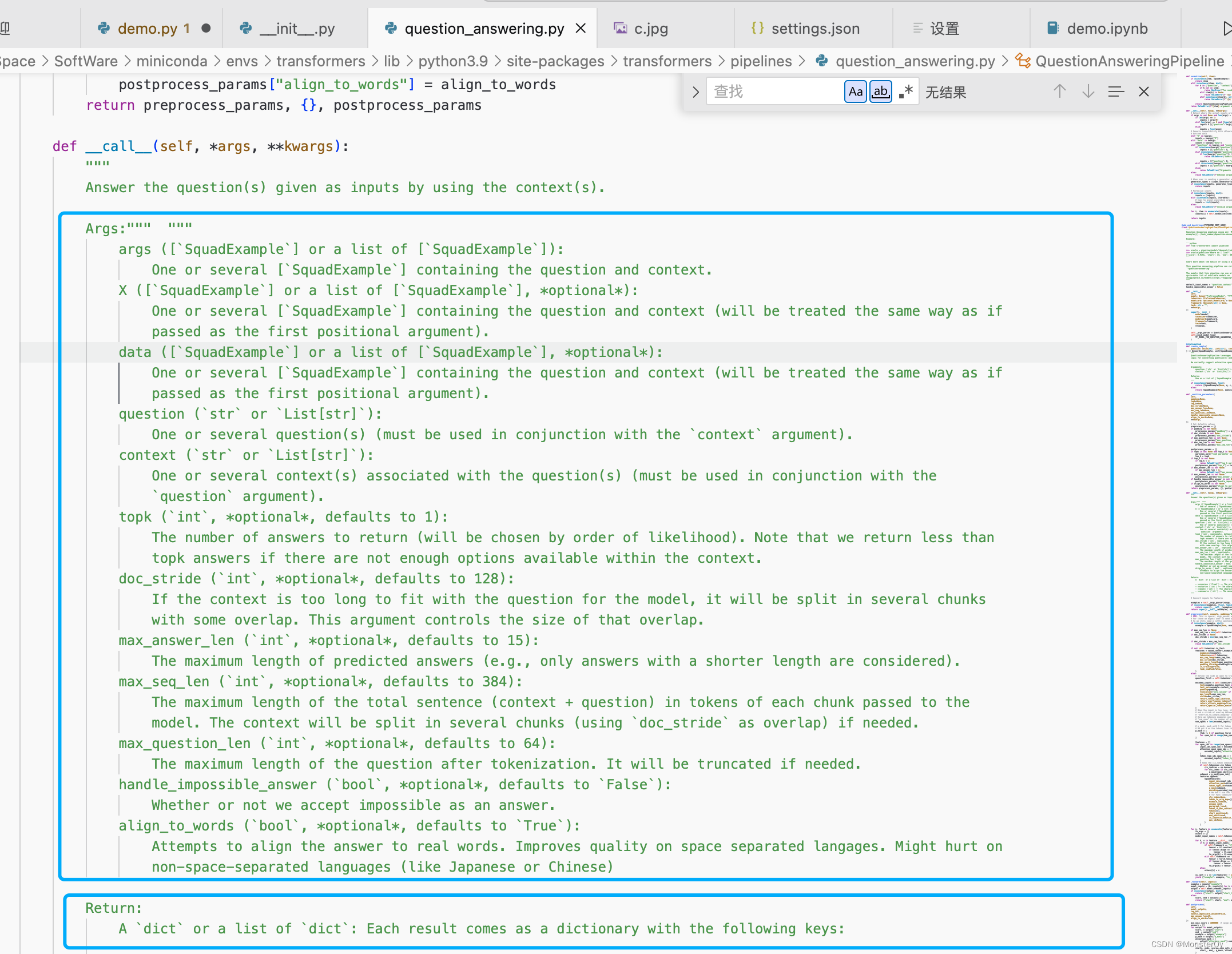
这个时候就可以按照参数提示进行调用了。