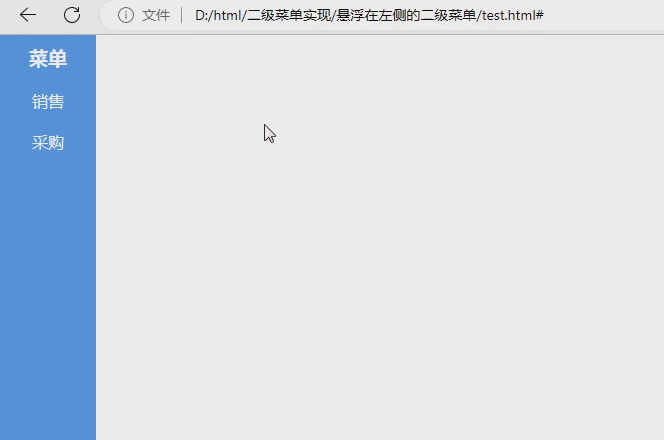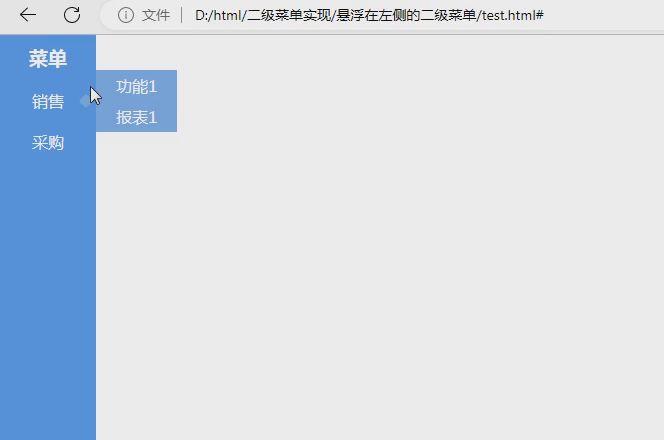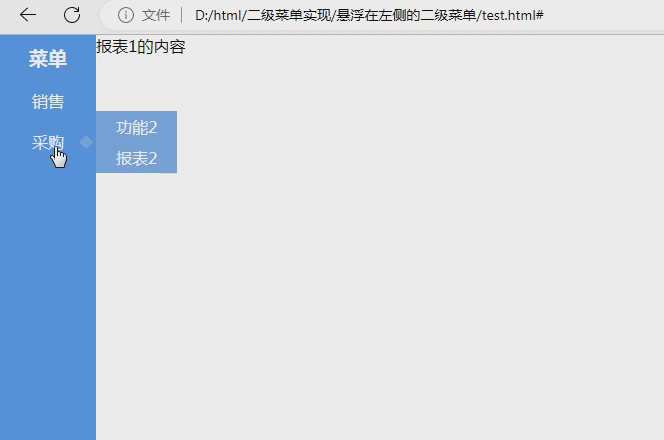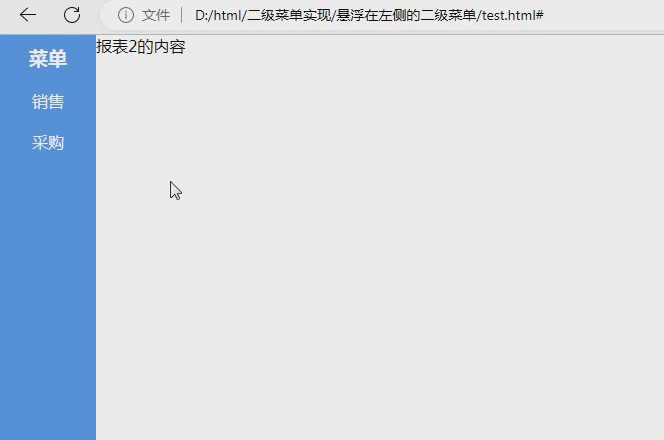
数据驱动将测试数据和测试行为完全分离,实施数据驱动测试步骤如下:
A、编写测试脚本,脚本需要支持从程序对象、文件或者数据库读入测试数据;
B、将测试脚本使用的测试数据存入程序对象、文件或者数据库等外部介质中;
C、运行脚本过程中,循环调用存储在外部介质中的测试数据;
D、验证所有的测试结果是否符合预期结果;
1、使用unittest和ddt进行数据驱动:
#-*- coding: UTF-8 -*-
from selenium import webdriver
import unittest
import time
import logging
import traceback
import ddt
from selenium.common.exceptions import NoSuchElementException# 初始化日志对象
logging.basicConfig(# 日志级别level = logging.INFO,# 日志格式# 时间、代码所在文件名、代码行号、日志级别名字、日志信息format='%(asctime)s %(filename)s[line: %(lineno)d] %(levelname)s %(message)s',# 打印日志时间datafomat='%a, %d %b %Y %H: %M: %S',# 日志文件存放的目录及日志文件名filename='d:/DataDriverTesting/report.log',# 打开日志文件的方式filemode='w'
)
@ddt.ddt
class TestDemo(unittest.TestCase):def setUp(self):self.driver = webdriver.Chrome()@ddt.data([u"神奇动物在哪里", u"叶"],[u"疯狂动物成", u"古德温"],[u"大话西游之月光宝盒", u"周星驰"])@ddt.unpackdef test_data(self,testdata, expectdata):self.driver.get("http://www.baidu.com")self.driver.implicitly_wait(2)try:self.driver.find_element_by_id("kw").send_keys(testdata)self.driver.find_element_by_id("su").click()time.sleep(3)self.assertTrue(expectdata in self.driver.page_source)except NoSuchElementException,e:logging.error(u"查找的页面元素不存在,异常堆站信息:"+str(traceback.print_exc()))except Exception, e:logging.error(u"未知错误,错误信息如下:"+str(traceback.print_exc()))else:logging.info(u"搜索%s,期望%s,通过"%(testdata, expectdata))def tearDown(self):self.driver.quit()if __name__ == '__main__':unittest.main()备注:
在unittest中结合ddt实现数据驱动,首先是在头部导入ddt模块,其次在测试类前声明使用ddt,然后在测试方法前使用@ddt.data()添加该测试方法需要的测试数据,该函数接收一个可迭代的类型,以此来判断需要执行的次数,多组测试数据间以逗号隔开,如果每组数据存在多个,需要将每组数据存于列表中;最后使用@unpack 进行修饰,对测试数据解包,传参;
2、使用JSon存储数据实现数据驱动测试:
数据存储:test_data_list.json中
["邓肯||蒂姆","乔丹||迈克尔","库里||斯蒂芬","杜兰特||凯文","詹姆斯||勒布朗"
]
数据和脚本文件要在同一级目录中:
#-*- coding: UTF-8 -*-
from selenium import webdriver
import HTMLTestRunner
import unittest
import time
import logging
import traceback
import ddt
from selenium.common.exceptions import NoSuchElementException# 初始化日志对象
logging.basicConfig(# 日志级别level = logging.INFO,# 日志格式# 时间、代码所在文件名、代码行号、日志级别名字、日志信息format='%(asctime)s %(filename)s[line: %(lineno)d] %(levelname)s %(message)s',# 打印日志时间datafomat='%a, %d %b %Y %H: %M: %S',# 日志文件存放的目录及日志文件名filename='d:/DataDriverTesting/report.log',# 打开日志文件的方式filemode='w'
)
@ddt.ddt
class TestDemo(unittest.TestCase):def setUp(self):self.driver = webdriver.Chrome()@ddt.file_data("test_data_list")def test_data(self, value):self.driver.get("http://www.baidu.com")self.driver.implicitly_wait(2)testdata, expectdata = tuple(value.strip().split("||"))self.driver.implicitly_wait(2)try:self.driver.find_element_by_id("kw").send_keys(testdata)self.driver.find_element_by_id("su").click()time.sleep(3)self.assertTrue(expectdata in self.driver.page_source)except NoSuchElementException,e:logging.error(u"查找的页面元素不存在,异常堆站信息:"+str(traceback.print_exc()))except Exception, e:logging.error(u"未知错误,错误信息如下:"+str(traceback.print_exc()))else:logging.info(u"搜索%s,期望%s,通过"%(testdata, expectdata))def tearDown(self):self.driver.quit()if __name__ == '__main__':suite1 = unittest.TestLoader().loadTestsFromTestCase(TestDemo)suite = unittest.TestSuite(suite1)filename = "d:\\test.html"fp = file(filename,'wb')runner = HTMLTestRunner.HTMLTestRunner(stream=fp, title="Report_title", description='Report_description')runner.run(suite)3、使用Excel进行数据驱动测试:
安装Python解析Excel 2007及以上版本的模块:pip install openpyxl==2.3.3;
在Pycharm上新建一个工程,创建文件测试数据.xlsx文件,sheet名为搜索数据表;
| 序号 | 搜索词 | 期望结果 |
|---|---|---|
| 1 | 邓肯 | 蒂姆 |
| 2 | 乔丹 | 迈克尔 |
| 3 | 库里 | 斯蒂芬 |
创建ExcelUtil.py文件:
# -*- coding: UTF-8 -*-
from openpyxl import load_workbookclass ParseExcel(object):def __init__(self, excelPath, sheetName):# 将要读取的Excel加载到内存self.wb = load_workbook(excelPath)# 通过工作表名获取一个工作表对象self.sheet = self.wb.get_sheet_by_name(sheetName)# 获取工作表中存在数据的区域的最大行号self.maxRowNum = self.sheet.max_rowdef getDatasFromSheet(self):# 用于存放从工作表中读取出来的数据dataList = []# 因为工作表中的第一行是标题行,所以需要去掉for line in self.sheet.rows[1:]:# 遍历工作表中数据区域的每一行,并将每行中每个单元格的数据去除存于列表tmpList中# 然后再将存放一行数据的列表添加到最终数据列表dataList中tmpList = []tmpList.append(line[1].value)tmpList.append(line[2].value)dataList.append(tmpList)return dataListif __name__ =='__main__':excelPath = u"测试数据.xlsx"sheetName = u"搜索数据表"pe = ParseExcel(excelPath, sheetName)for i in pe.getDatasFromSheet():print i[0],i[1]创建DataDriven.py文件:
# -*- coding: UTF-8 -*-
from selenium import webdriver
import unittest
import time
import logging
import traceback
import ddt
from ExcelUtil import ParseExcel
from selenium.common.exceptions import NoSuchElementException# 初始化日志对象
logging.basicConfig(# 日志级别level = logging.INFO,# 日志格式# 时间、代码所在文件名、代码行号、日志级别名字、日志信息format='%(asctime)s %(filename)s[line: %(lineno)d] %(levelname)s %(message)s',# 打印日志时间datafomat='%a, %d %b %Y %H: %M: %S',# 日志文件存放的目录及日志文件名filename='d:/DataDriverTesting/report.log',# 打开日志文件的方式filemode='w'
)excelPath = u"测试数据.xlsx"
sheetName = u"搜索数据表"
excel = ParseExcel(excelPath, sheetName)@ddt.ddt
class TestDemo(unittest.TestCase):def setUp(self):self.driver = webdriver.Chrome()@ddt.data(*excel.getDatasFromSheet())def test_data(self, data):testdata,expectdata = tuple(data)self.driver.get("http://www.baidu.com")print testdata,expectdataself.driver.implicitly_wait(2)try:self.driver.find_element_by_id("kw").send_keys(testdata)self.driver.find_element_by_id("su").click()time.sleep(3)self.assertTrue(expectdata in self.driver.page_source)except NoSuchElementException,e:logging.error(u"查找的页面元素不存在,异常堆站信息:"+str(traceback.print_exc()))except Exception, e:logging.error(u"未知错误,错误信息如下:"+str(traceback.print_exc()))else:logging.info(u"搜索%s,期望%s,通过"%(testdata, expectdata))def tearDown(self):self.driver.quit()if __name__ == '__main__':unittest.main()备注:@ddt.data从excel.getDatasFormSheet()方法中接收一个可迭代的数组对象,以此来判断需要执行的次数。如果@ddt.data()中传的是一个方法,方法前需要加型号(*)修饰;
4、使用xml进行数据驱动测试:
在pycharm中创建一个项目,创建TestData.xml文件用于存放测试数据,具体内容如下:
<?xml version="1.0" encoding="utf-8" ?>
<bookList type="technology"><book><name>Selenium WebDriver实战宝典</name><author>吴晓华</author></book><book><name>HTTP权威指南</name><author>HTTP</author></book><book><name>探索式软件测试</name><author>惠特克</author></book>
</bookList>
创建XmlUtil.py文件用于解析XML文件,获取测试数据:
# -*- coding: UTF-8 -*-
from xml.etree import ElementTreeclass ParseXML(object):def __init__(self,xmlPath):self.xmlPath = xmlPathdef getRoot(self):tree = ElementTree.parse(self.xmlPath)return tree.getroot()def findNodeName(self,parentNode,nodeName):nodes = parentNode.findall(nodeName)return nodesdef getNodeOfChildText(self, node):# childrenTextDict = {i.tag: i.text for i in list(node.iter())[1:]}childrenTextDict = {}for i in list(node.iter())[1:]:childrenTextDict[i.tag] = i.textreturn childrenTextDictdef getDataFromXml(self):root = self.getRoot()books = self.findNodeName(root, "book")dataList = []for book in books:childrenText = self.getNodeOfChildText(book)dataList.append(childrenText)return dataList
if __name__=='__main__':xml = ParseXML(r'TestData')datas = xml.getDataFromXml()for i in datas:print i['name'],i['author']创建DataDrivenByXML.py文件用于编写数据驱动测试脚本:
# -*- coding: UTF-8 -*-
from selenium import webdriver
import unittest
import time
import os
import logging
import traceback
import ddt
from XmlUtil import ParseXML
from selenium.common.exceptions import NoSuchElementException# 初始化日志对象
logging.basicConfig(# 日志级别level = logging.INFO,# 日志格式# 时间、代码所在文件名、代码行号、日志级别名字、日志信息format='%(asctime)s %(filename)s[line: %(lineno)d] %(levelname)s %(message)s',# 打印日志时间datafomat='%a, %d %b %Y %H: %M: %S',# 日志文件存放的目录及日志文件名filename='d:/DataDriverTesting/report.log',# 打开日志文件的方式filemode='w'
)
'''
# 获取当前文件所在父目录的绝对路径
currentPath = os.path.dirname(os.path.abspath(__file__))
# 获取数据文件的绝对路径
dataFilePath = os.path.join(currentPath, "TestData.xml")
print dataFilePath
'''# 创建ParseXML实例对象
xml = ParseXML("TestData")@ddt.ddt
class TestDemo(unittest.TestCase):def setUp(self):self.driver = webdriver.Chrome()@ddt.data(* xml.getDataFromXml())def test_data(self, data):testdata, expectdata = data['name'], data['author']self.driver.get("http://www.baidu.com")print testdata,expectdataself.driver.implicitly_wait(2)try:self.driver.find_element_by_id("kw").send_keys(testdata)self.driver.find_element_by_id("su").click()time.sleep(3)self.assertTrue(expectdata in self.driver.page_source)except NoSuchElementException,e:logging.error(u"查找的页面元素不存在,异常堆站信息:"+str(traceback.print_exc()))except Exception, e:logging.error(u"未知错误,错误信息如下:"+str(traceback.print_exc()))else:logging.info(u"搜索%s,期望%s,通过"%(testdata, expectdata))def tearDown(self):self.driver.quit()if __name__ == '__main__':unittest.main()最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:

这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!