ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。
1,本地安装 Python
https://www.python.org/downloads/
测试:cmd输入python
2,下载chatglm
项目地址:https://github.com/THUDM/ChatGLM-6B下载后放到第二步程序包下,自行创建目录 chatglm-6b
3,下载模型数据
THUDM/chatglm-6b at main
4,执行下载依赖包命令
在ChatGLM-6B-main目录下cmdpip --default-timeout=1688 install -r requirements.txt
pip install gradio
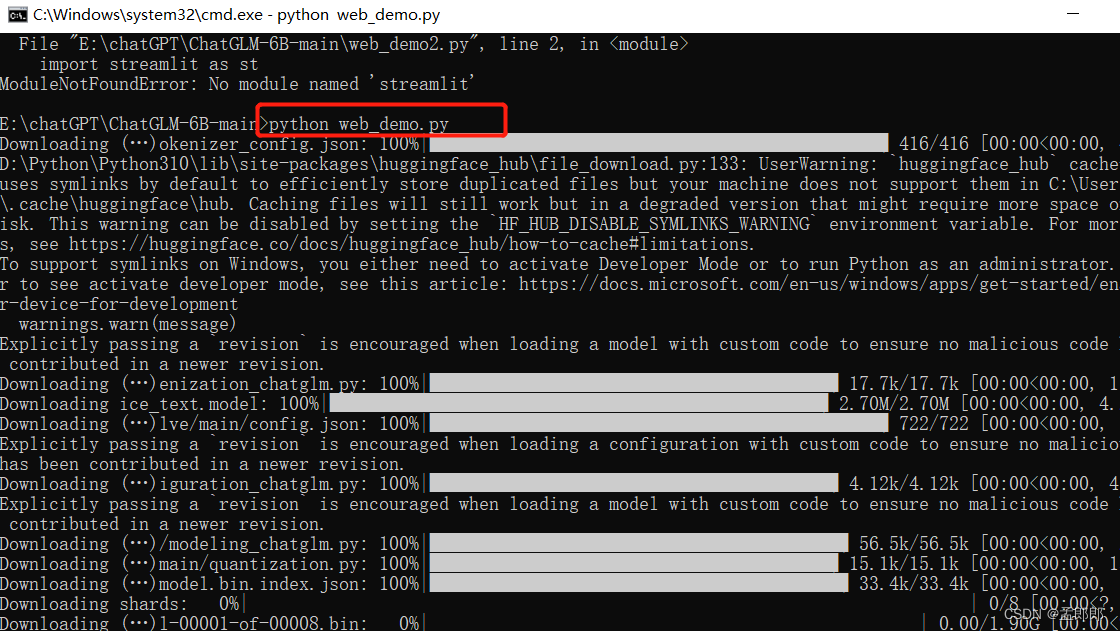
5,运行网页版 demo
python web_demo.py6,运行命令行 Demo
python cli_demo.py

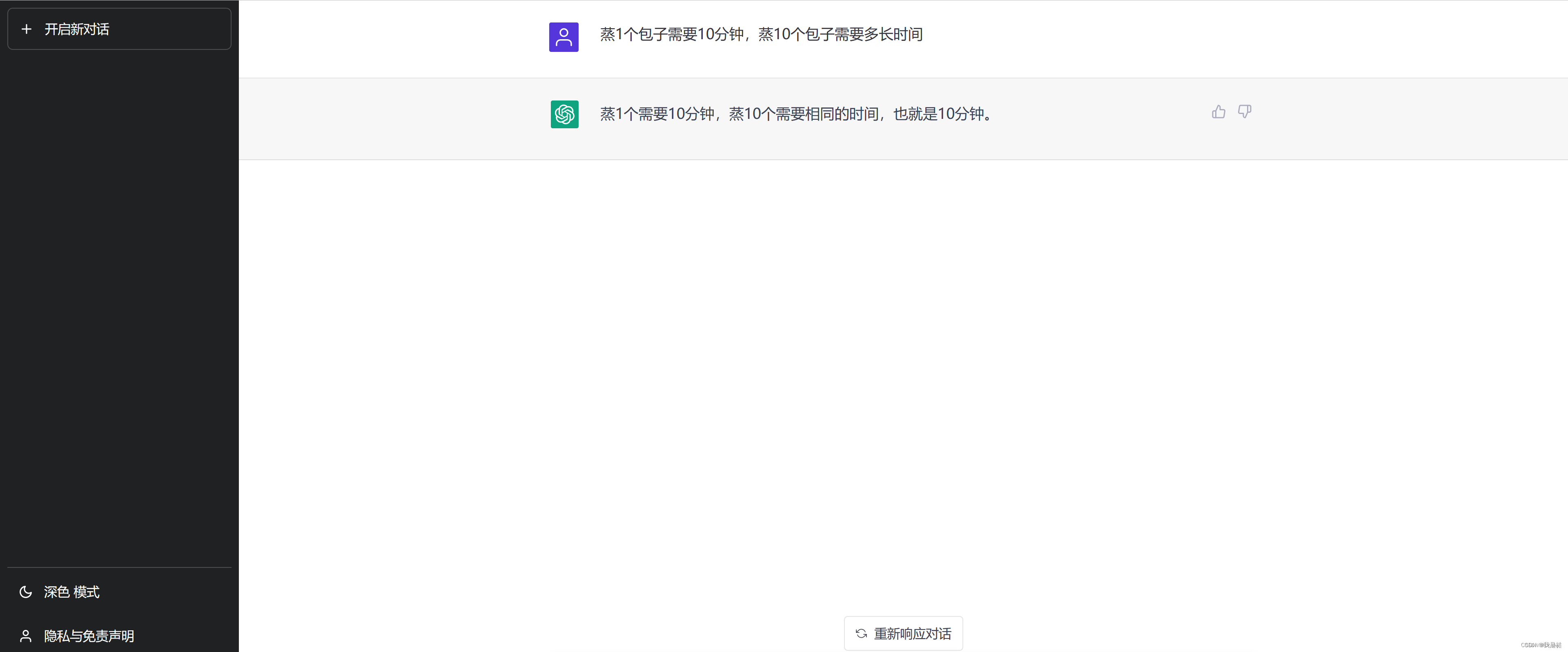
执行效果

相关部署问题
问题:提示信息中看到又一次下载模型包
方案:需要把模型包复制到程序运行时的缓存目录中,缓存路径可能如下:
C:\Users\用户目录\.cache\huggingface\hub\models--THUDM--chatglm-6b\snapshots\fb23542cfe773f89b72a6ff58c3a57895b664a23
问题: Unable to load vocabulary from file. Please check that the provided vocabulary is accessible and not corrupted.
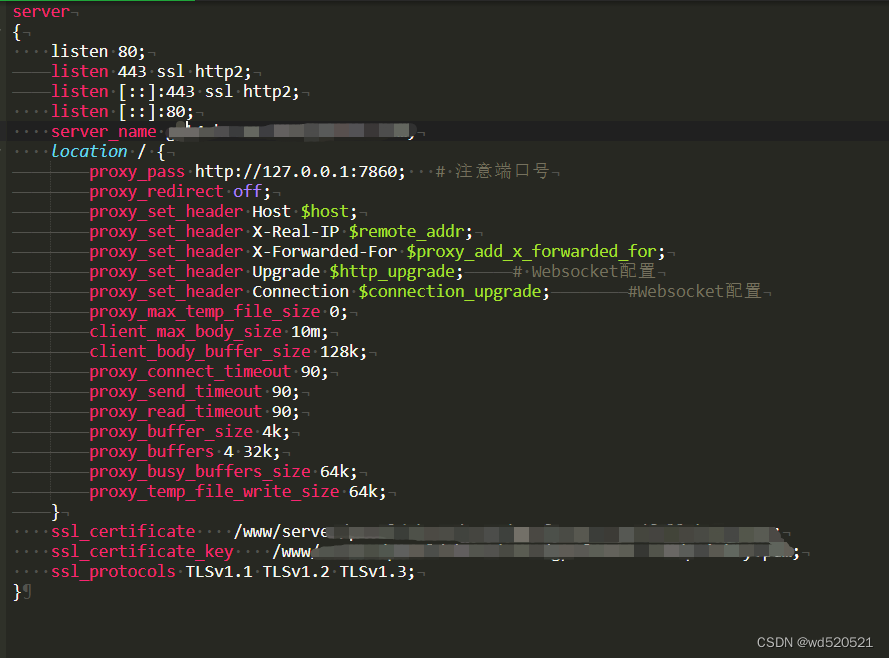
方案:修改cli_demo.py 的chatglm-6b地址
D:\workspace\ChatGLM\ChatGLM-6B-main\chatglm-6b
问题:nvcc --version报错
方案:安装cuda
cuda_11.7.0_516.01_windows.exe
https://developer.nvidia.com/cuda-toolkit-archive
问题: Torch not compiled with CUDA enabled
方案:
import torch
print(torch.__version__)#torch版本
print(torch.cuda.is_available())#GPU是否可用
查看显卡:
nvidia-smi
nvcc --version安装pyTorch
pip install "torch-2.0.0+cu118-cp311-cp311-win_amd64.whl" -i https://pypi.tuna.tsinghua.edu.cn/simple/
问题:torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 128.00 MiB (GPU 0; 4.00 GiB total capacity; 3.37 GiB already allocated; 0 bytes free; 3.37 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
方案:
监控内存
nvidia-smi -l 1GPU内存6G修改:
model = AutoModel.from_pretrained("D:\workspace\ChatGLM\ChatGLM-6B-main\chatglm-6b", trust_remote_code=True).half().quantize(4).cuda()
GPU内存不够改为CPU执行:model = AutoModel.from_pretrained("D:\workspace\ChatGLM\ChatGLM-6B-main\chatglm-6b", trust_remote_code=True).float()