paper link:https://arxiv.org/pdf/2302.09899.pdf
1. Introduction
图像分割是最古老、研究最广泛的计算机视觉 (CV) 问题之一。图像分割是指将图像划分为不同的非重叠区域,并将相应的标签分配给图像中的每个像素,最终获得ROI区域位置及其类别信息。一般,我们将分割任务分为语义分割和实例分割,前者是将每个像素与相应的语义类别进行分类,从而为属于该类别的所有对象或图像区域赋予相同的类别标签;后者则更进一步,试图区分出同一类别的不同实例(如下图所示)。本文主要围绕语义分割进行展开介绍。

总所周知,传统图像分割方法(如阈值法、聚类法)能有效应对固定场景,但对复杂多变的场景缺乏鲁棒性。随着深度学习方法的出现,分割性能有了质的提升,处理复杂场景变得游刃有余。然而,深度学习方法需要大量的数据与标记,尤其是像素级别的标记,这需要耗费巨大的人力和时间成本。因此,基于半监督学习的方法深得科研与从业者喜爱。
半监督同时从有监督的标签信息和无监督的无标签信息中抽取数据,从而减少了全监督中所需要的标注工作,这在缺少标注信息任务中很有意义!例如:医学图像。
本文主要贡献总结如下:
- 提供了半监督语义分割方法的新分类及其描述。
- 对文献中使用最广泛的数据集进行了一系列最先进的半监督分割方法的实验。
- 对取得的结果、当前方法的优点和缺点、挑战和该领域未来的工作路线进行讨论。
2. 半监督语义分割方法
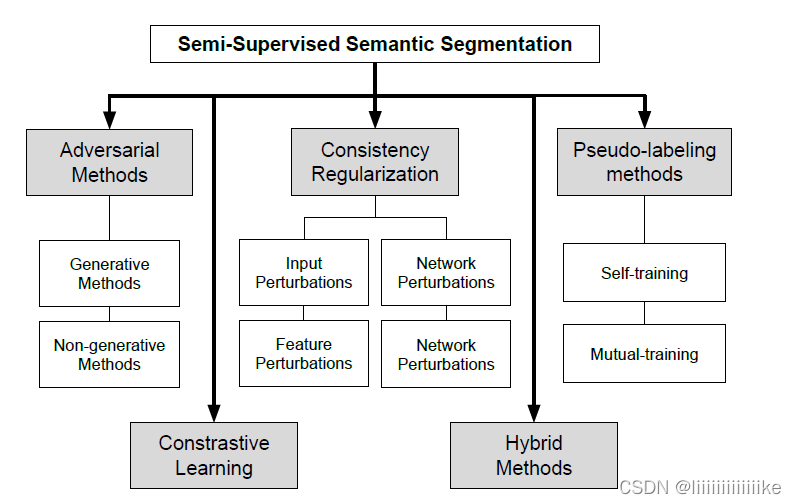
半监督语义分割方法主要分为以下五个内容:
- Adversarial Methods:类似 GAN 结构和在两个网络之间进行对抗性训练的方法,一个作为生成器,另一个作为鉴别器。
- Constrastive Learning:基于对比学习的方法。 这种学习范式将相似元素分组,并将它们与特定表示空间中的不同元素分开。
- Consistency Regularization:一致性正则化方法。 这些方法在损失函数中包含一个正则化项,以最小化同一图像的不同预测之间的差异,这些差异是通过对图像或相关模型应用扰动获得的。
- Hybrid Methods:混合方法,即将一致性正则化、伪标记和对比学习等方法组合构成。
- Pseudo-labeling Methods:伪标记方法。一般而言,这些方法依赖于先前对未标记数据所做的预测,以及在标记数据上训练的模型以获得伪标签。