模仿唐诗宋词,和模仿莎士比亚十四行诗的中英文差距
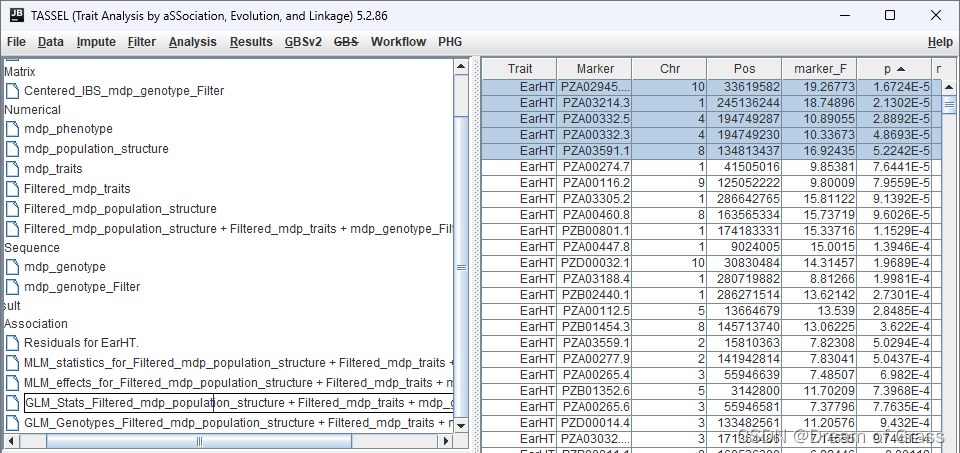
根据前文介绍的三大反例特性,我们可以尝试给出几个典型的反例。比如诗词创作,尤其是长短句约束更加严格的词牌,对照反例特性:
- 有明确且唯一可行的标准定义——一个固定词牌的格律,不可能超出《钦定词谱》的定义外随意创作。
- 即使稍微犯错也会造成较大影响,故而不可接受——由于《钦定词谱》本身已经是古人根据数以万计的作品总结出来的格律,其中大量都是脍炙人口的经典作品,中国人可谓从小学到大,倒背如流。尤其是诸如《青玉案·元夕》、《念奴娇·赤壁怀古》、《水调歌头·明月几时有》、《满江红·怒发冲冠》、《沁园春·雪》这些长短句,填类似词牌,增减一个字,都会被视为"大逆不道"。
- 错误不是很容易发现或证实,至少相对当前使用者的知识水平来说很难——虽然知名词牌的字数大家都熟,但进一步讲究押韵、平仄,又大大超出普通人的知识范畴,很难判读。
青玉案词牌
可见,填词是一个非常符合 ChatGPT 反例的场景。时值元宵节前后,正好让我们试一试,看看 ChatGPT 能写出和《青玉案·元夕》差距有多大的作品来。
我们先试试直接让 ChatGPT 任意发挥,填词一首:

看来 ChatGPT 不但不懂什么是青玉案,也不懂什么是填词。倒是给我们出了一道完形填空题!不过没关系,ChatGPT 的多轮对话能力我们早有耳闻,试试直接教它,我们直接输入著名的《青玉案·元夕》,要求 ChatGPT 进行模仿:

看起来 ChatGPT 并不理解啥叫平仄……所以我们退而求其次吧,只要能拼个字数看起来像回事的就行。
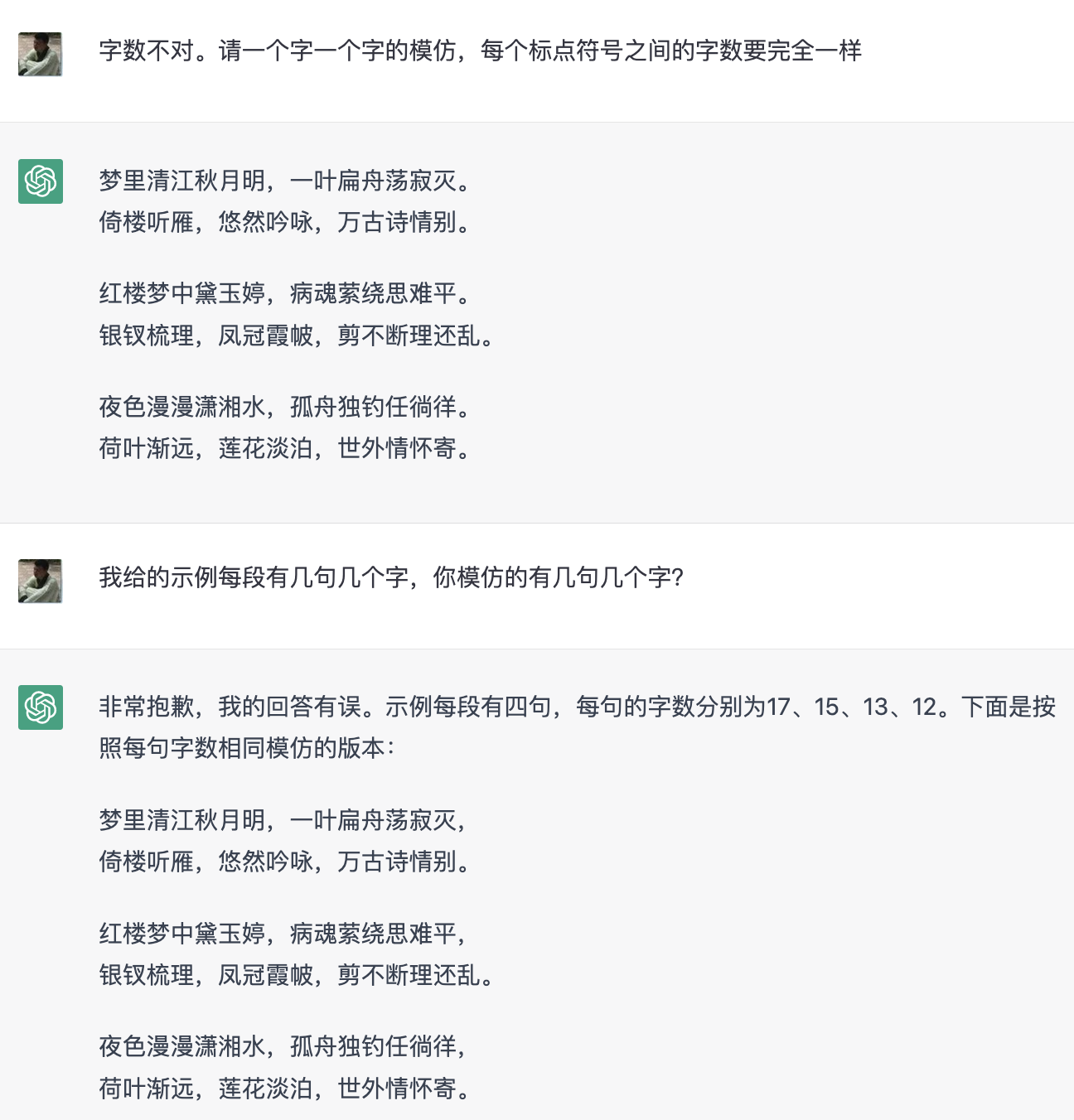
ChatGPT 非常顽固,每次都拒绝修改,给出一模一样的作品。这也就罢了,字数和句数也完全数的不对。17,15,13,12 完全暴露了 ChatGPT 是个文本生成模型,没有任何实际逻辑的本质。
不过没关系,我们还可以降低难度,一句一句来:

依然失败,ChatGPT 在精确要求字数的时候,完全不可能遵守要求。最后努力一次吧,或许是中文训练集较少,我们改成阿拉伯数字试试?
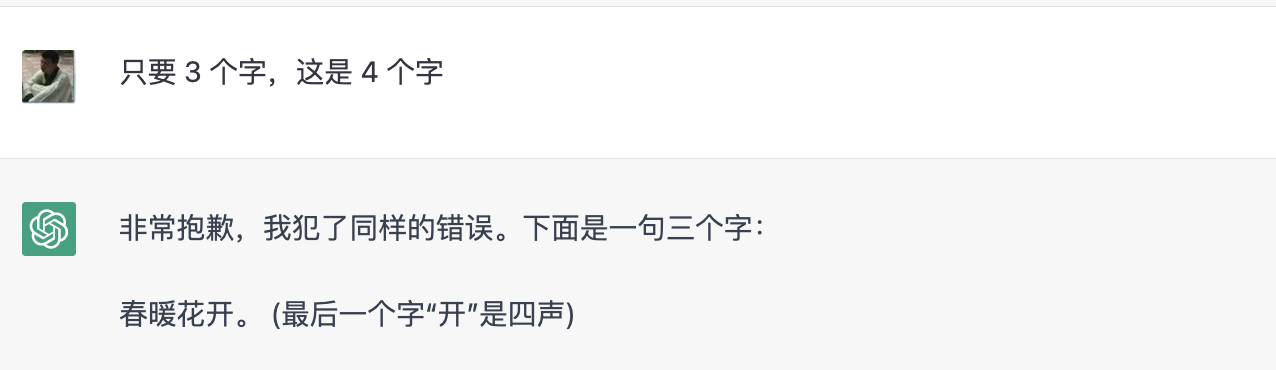
没有区别,说明 ChatGPT 并不是对中英文数字含义本身有不同的理解力,而是真的就做不到"精确"的控制字数。
十四行诗
和中国格律诗词相对应,英文世界中也有类似的文学形式,那就是十四行诗(sonnet)。十四行诗是欧洲 13 世纪形成的一种定型诗。最著名的是英国大文豪莎士比亚创作的英式十四行诗,莎士比亚对语言的影响直接影响了现代英语的形成。NLP 领域中,很多入门数据集直接就是莎士比亚著作。
和中国当代依然有大批诗词爱好者一样,西方也一直延续有十四行诗创作的爱好者。我们来试试,类似主题下,我们改用英文提问,ChatGPT 的十四行诗创作水平如何。
考虑到中国对莎士比亚的了解多集中在其剧作成就,这里我们单独提供一下十四行诗的结构要求。下面这段话摘录自维基百科"十四行诗"中文词条:
意大利十四行诗分为两段,先八后六。前八句韵脚是 a-b-b-a, a-b-b-a。后六句有两种,c-d-e-c-d-e,或者 c-d-c-c-d-c。第九句不只改韵脚,很多时候题目或感觉也不一样。 英国类分为3段四句加最后两句。最后的两句通常与前面的差异很大,比意大利类第九句改变更多。一般英国十四行诗的韵脚是"a-b-a-b, c-d-c-d, e-f-e-f, g-g", 或者"a-b-a-b, b-c-b-c, c-d-c-d, e-e"。

完全符合"a-b-a-b, c-d-c-d, e-f-e-f, g-g"的韵脚和行数要求。
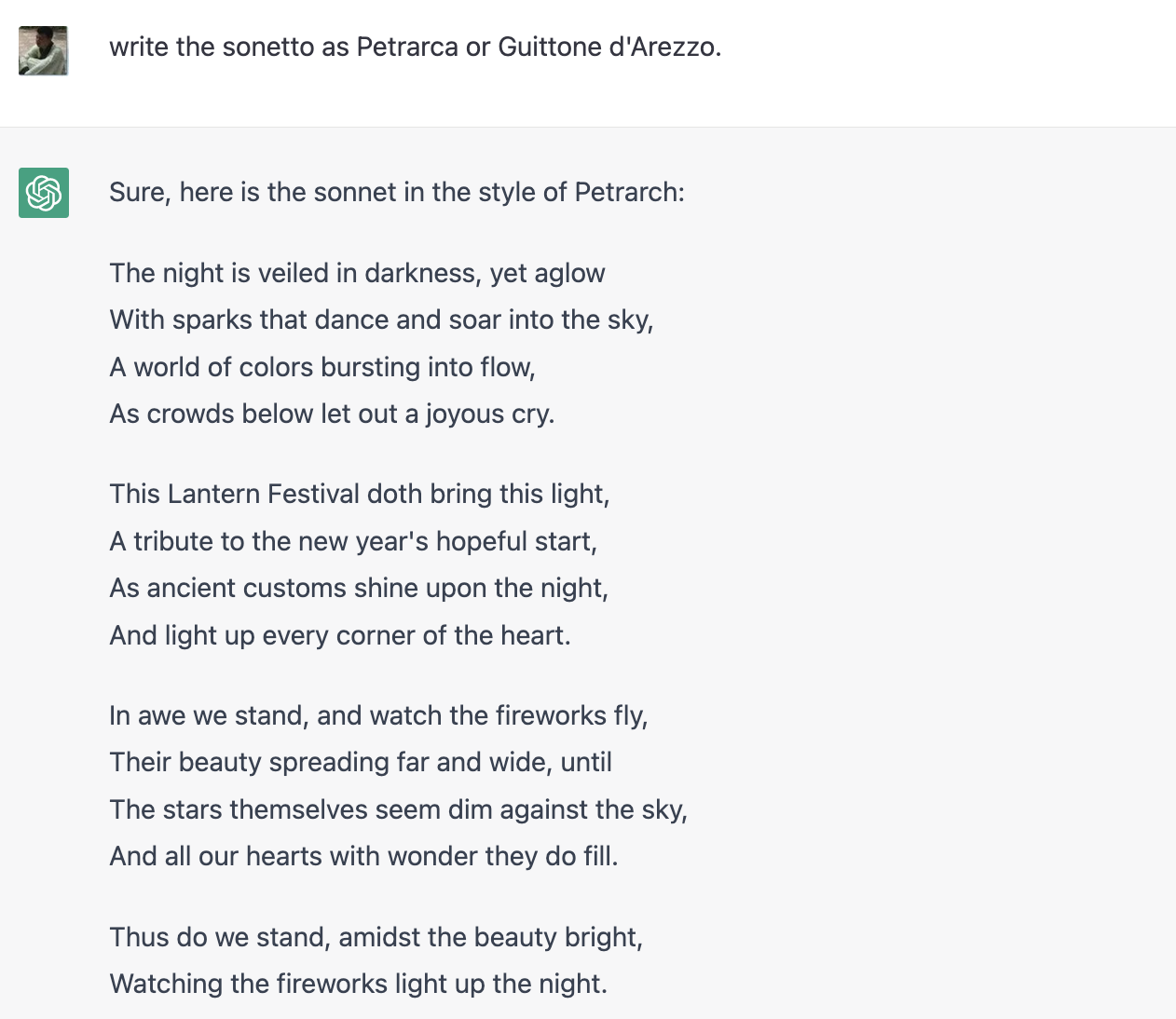
不过如果想换成意大利式的十四行诗,ChatGPT 却并不能生成三段式"a-b-b-a, a-b-b-a, c-d-e-c-d-e"韵脚。可见,我们在谈论 ChatGPT 时,通常忽略的数据集问题,实际影响多么巨大!
本节最后额外可以提一句,世界上还有第三种定型诗,是日本的俳句。有兴趣的读者,也可以再尝试看看 ChatGPT 的日文水平如何。

![差异表达基因分析[转载]](https://img2018.cnblogs.com/blog/1324606/201812/1324606-20181217090833846-15662303.png)