论文笔记--
- 1. 文章简介
- 2. 文章概括
- 3 文章重点技术
- 3.1 模型架构
- 3.2 训练数据
- 3.3 模型评估
- 3.3.1 文本
- 3.3.1.1 Science
- 3.3.1.2 Model sizes
- 3.3.1.3 Multilingual
- 3.3.1.4 Long Context
- 3.3.1.5 Human preference
- 3.3.2 多模态
- 3.3.2.1 图像理解
- 3.3.2.2 视频理解
- 3.3.2.3 图像生成
- 3.3.2.4 音频理解
- 3.4 部署
- 4. 文章亮点
- 5. 原文传送门
1. 文章简介
- 标题:Gemini: A Family of Highly Capable Multimodal Models
- 作者:Gemini Team, Google
- 日期:2023
2. 文章概括
近日google发行的Gemini系列多模模型引发了业内的争相转发,该系列模型包含Ultra, Pro和Nano三种尺寸,分别适用于不同的预算和预期。该多模态模型在文本、图片、音频、视频等多个领域表现突出,特别地,Gemini Ultra是第一个在MMLU测评集上性能达成人类专家水平的模型。
3 文章重点技术
3.1 模型架构
Gemini模型基于Transformer解码器架构,支撑32K的上下文长度。Gemini家族包含Ultra/Pro/Nano三种尺寸的模型,其中Ultra表现最好,且在多个任务上达到了SOTA;Pro模型在多个任务上表现也很好,可在成本有限的情况下作为Ultra的替代品;Nano-1(1.8B)和Nano-2(3.25B)可支撑不同内存的on-device部署。具体如下表所示

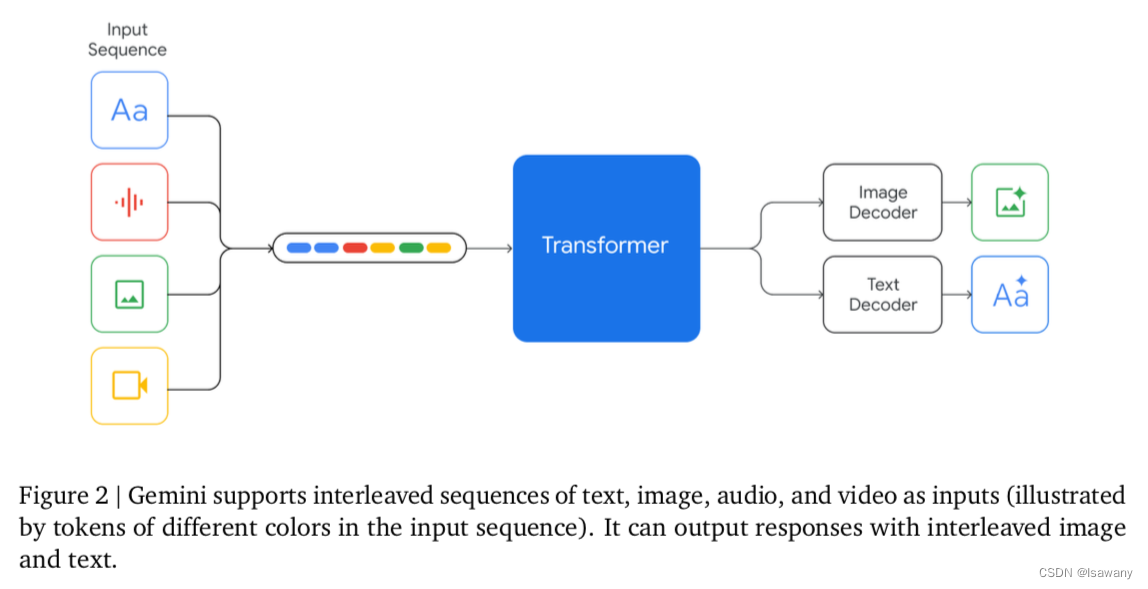
Gemini系列模型支持文本、图像和音视频交错的输入,支持输出文本和图像。如下图所示。其中图像部分的编码类似Google之前的Flamingo,CoCa和PaLI模型;Video的编码是通过将Video处理为祯的序列,然后采样序列进行编码得到输出。
3.2 训练数据
Gemini的训练数据来源包含网页、书籍、代码,数据类型包含图像、音频、视频等。文章首先利用启发式规则和基于模型的分类起对所有的数据集进行质量过滤,再通过安全过滤移除有害内容。文章通过在小尺寸模型上的数值实验得到最终的数据配比,再用相同的数据配比去训练大的模型。
3.3 模型评估
Gemini是一种多模态模型,故文章从文本 、图像、视频几个方面对模型进行了性能评估。
3.3.1 文本
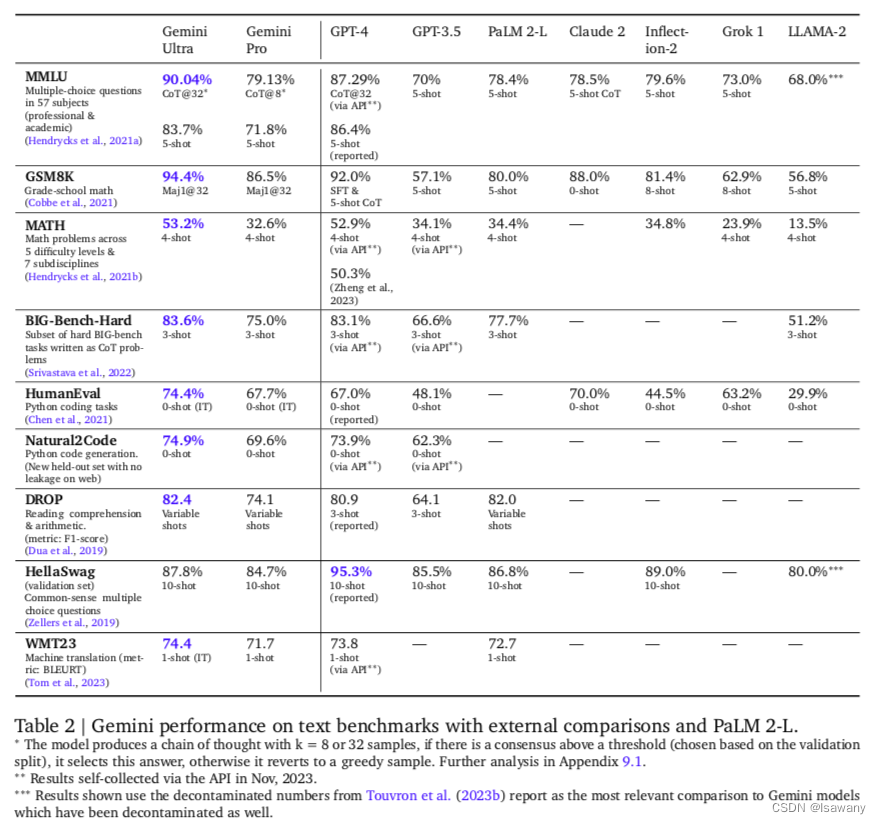
文章对比了Gemini Pro/Ultra和一系列现存的表现较好的LLMs,评估结果见下表。可以看到,Gemini Pro的表现超过了GPT-3.5等大部分模型,Gemini Ultra的表现超过了所有的模型。
3.3.1.1 Science
特别地,在MMLU上,Gemini Ultra达到了90.04%的accuracy,成为第一个在该数据集上超过人类专家的表现(89.8%)的模型,且acc领先SOTA(86.4%)3%+。文章在处理MMLU的数据时采用了chain-of-thought(COT) prompt方法,文章发现,采用COT+greedy补充的方法可以有效提升模型表现。具体来说,文章会对测试数据生成 k k k个COT的样本,如果 k k k个样本的一致性达到给定的阈值(此时认为满足COT的自我一致性),则选择COT的结果作为最终生成回答,否则直接采用贪婪采样。
3.3.1.2 Model sizes
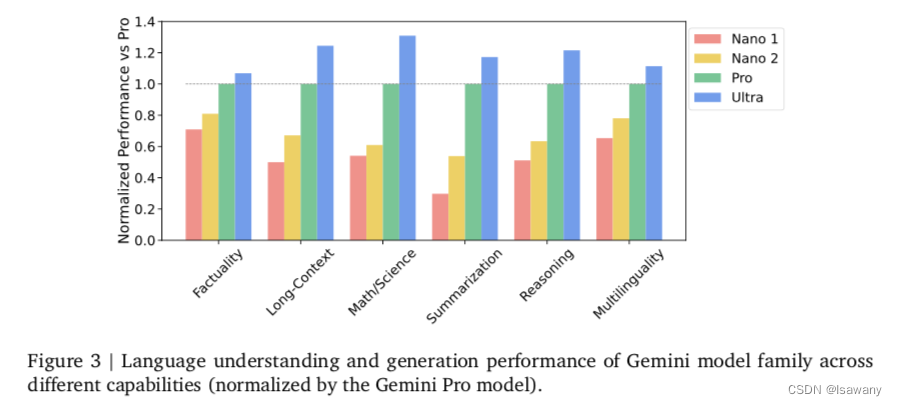
文章对比了Gemini家族在不同benchmarks上的不同维度的能力。具体来说,文章将评测集分成了6中能力维度:Factuality, Long-Context, Math/Science, Reasoning,Multilingual和Summarization,发现在所有维度上模型表现随着模型尺寸的增加而增加,且Nano模型尽管尺寸很小,在Factuality和Multilinguality上表现也足够强大。具体见下图
3.3.1.3 Multilingual
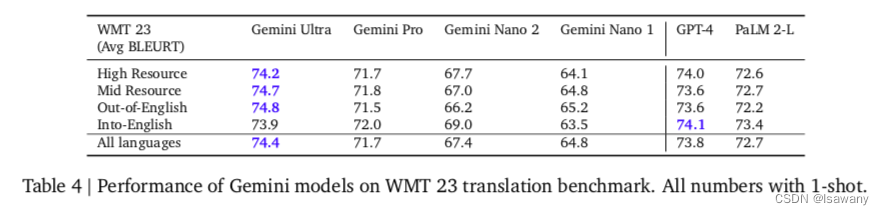
Gemini模型同样表现出了强大的多语言处理能力。在机器翻译的benchmarks上,Gemini Ultra模型在所有out-of-English任务(从英文翻译为其它语言)上超过SOTA,在Into-English任务上也几乎持平SOTA,见下表。此外,Gemini在一些更具挑战性的任务(如MGSM)上表现也超过了现存最好的模型。实验证明,Gemini具有多语言、多模态处理问题的能力。
3.3.1.4 Long Context
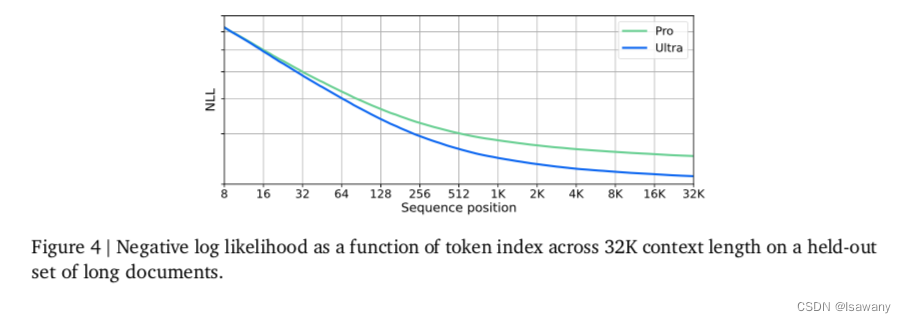
针对长文本,文章做了如下的综合回溯测试:首先在context开始位置增加一些key-value键值对,然后增加填充文本,然后在整个上下文中query固定的key,实验发现,Ultra模型可以以98%的acc查询给定的key对应的value。此外,文章测试了NLL VS Token index的实验,结果如下图所示,可以看到随着token index增加到32K,NLL逐渐降低,说明模型具备处理长的上下文的能力。
3.3.1.5 Human preference
文章进行了side-by-side blind evaluations来测试相同prompt下人类对两个模型产生回答的偏好。为此,文章首先对Gemini进行了指令微调,得到Instruction-tuned Gemini Pro(ItGP)模型。接下来对该模型和PaLM2 模型在指令遵循、创意写作、多模态理解、长文本理解、安全性等方面进行了比较。实验表明基于ItGP的模型对人类更加有帮助且更安全:

3.3.2 多模态
3.3.2.1 图像理解
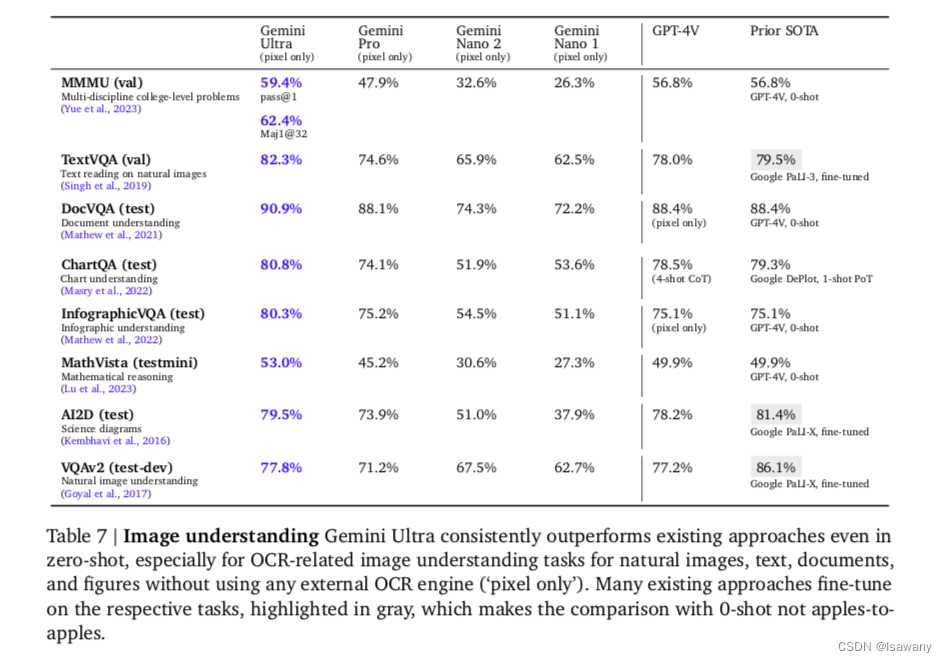
文章从4个不同能力维度的8个测试集测试了模型的图像理解能力。结果如下表所示,可以看到,Gemini Ultra在全部zero-shot任务重表现最好,特别针对和OCR相关的图像理解任务,Gemini Ultra 的zero-shot表现甚至超过了以前的一些Fine-tuned的SOTA结果。
下图为一个Gemini处理多模态reasoning的示例,可以看到模型具备识别、图像转换、指令遵循和抽象推理等多种多模态推理能力
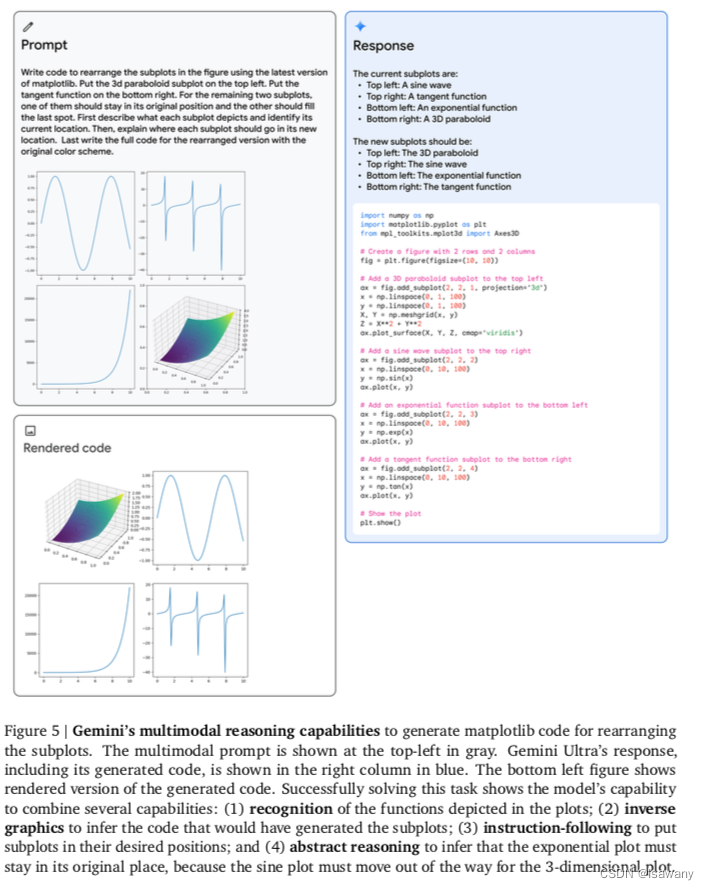
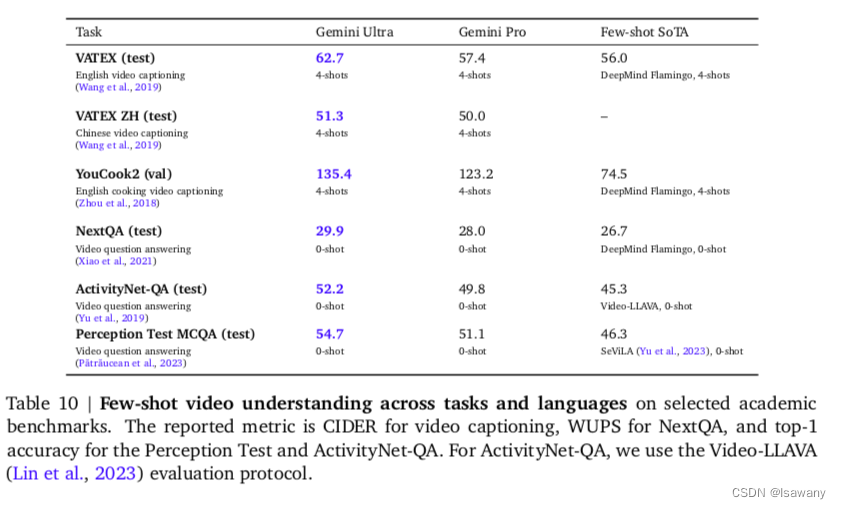
3.3.2.2 视频理解
Gemini同样在多个video理解任务重达到了SOTA水平,表现了Gemini强大的时序推理能力
3.3.2.3 图像生成
Gemini支持图像、文本输出,从而模型可以在few-shot设置下生成图文交错输出,可用于设计博客、网站等。下图为一个Gemini的图像理解和生成的示例,该示例也出现在最近大火的Gemini推广视频中。

3.3.2.4 音频理解
文章进一步测试了Gemini系列模型在ASR(语音识别)、AST(语言翻译)的benchmarks上的表现。结果表明,Gemini Pro模型在所有AST和ASR的任务中显著优于USM、Whisper模型:
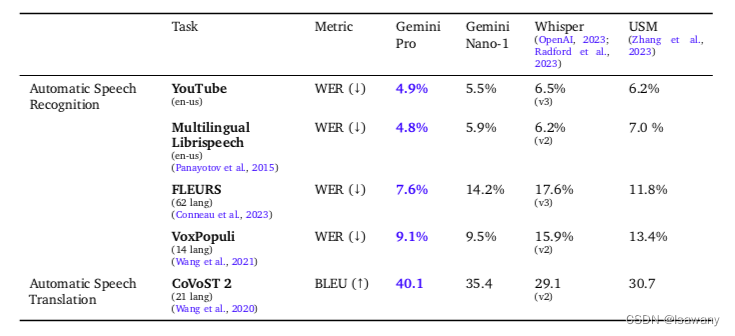
3.4 部署
部署模型前,google做了一系列工作保证模型的性能和安全性,包括数据过滤,迭代式的指令微调和评估等。
4. 文章亮点
文章提出并发布了Gemini模型,是现存最强大的多模态模型,在多个文本、图像、视频、音频的benchmarks上均达到了SOTA。Gemini模型预计12/13发布集成方案,届时我们可以基于Gemini来进行进一步的研究。
5. 原文传送门
Gemini: A Family of Highly Capable Multimodal Models
google gemini官网地址
gemini post 地址