目录
一、为什么使用selenium
二、selenium语法——元素定位
1.根据 id 找到对象
2.根据标签属性的属性值找到对象
3.根据Xpath语句获取对象
4.根据标签名获取对象
5.使用bs语法获取对象
6.通过链接文本获取对象
三、selenium语法——访问元素信息
1.获取属性的属性值
2.获取标签名
3.获取元素文本
四、selenium 交互
五、无界面操作
参考
1.什么是selenium?
- selenium是一个用于web应用程序测试的工具。
- selenium测试直接运行在浏览器中,就像真正的用户一样。
- 支持通过各种driver(FirefoxDriver,IternetExplorerDriver,OperaDriver,ChromeDriver)驱动真实浏览器完成测试。
- selenium也是支持无界面浏览器操作的。
2.为什么使用selenium?
模拟浏览器功能,自动执行网页中的js代码,实现动态加载。
3.如何安装selenium?
安装selenium及谷歌驱动
4.selenium的使用步骤?
- 导入:from selenium import webdriver
- 创建谷歌浏览器操作对象:
path = 谷歌浏览器驱动文件路径
browser = webdriver.Chrome(path)
- 访问网址
url = 要访问的网址
browser.get(url)
selenium 的元素定位
元素定位:自动化要做的就是模拟鼠标和键盘来操作这些元素,如点击、输入等等。操作这些元素前首先要找到它们,webdriver提供很多定位元素的方法。
方法:
(1)find_element(By.ID, 'id 名')
eg:button = browser.find_element(By.ID, ‘su’)
(2)find_element(By.NAME, 'name 名')
eg:name = browser.find(By.NAME,‘wd’)
(3)find_elements(By.XPATH, 'Xpath语法')
eg:xpath = browser.find_elements(By.XPATH, "//input[@id-"su"]")
(4)find_elements(By.TAG_NAME,' Tag name ')
eg:names = browser.find_elements (By.TAG_NAME, "input")
(5)find_elements(By.CSS_SELECTLOR, ' bs4语法 ')
eg:my_input = browser.find_elements(By.CSS_SELECTLOR, "#kw")[0]
(6)find_elements(By.LINK_TEXT, ' 链接文本')
eg:browser.find_elements(By.LINK_TEXT,"新闻")
访问元素信息
获取元素属性
.get_attribute(‘class’)
获取元素文本
.text
获取id
.id
获取标签名
.tag_name
selenium 交互
(1)点击:click()
(2)输入:send_keys()
(3)后退操作:browser.back()
(4)前进操作:browser.forward()
(5)模拟js滚动:
js = ‘document.documentElement.scrollTop=100000’
browser.execute_script(js) 执行js 代码
(6)获取网页代码:page_source
(7)退出:browser.quit()
一、为什么使用selenium

import urlliburl = 'http://www.jd.com'response = urllib.request.urlopen(url)content = response.read().decode()
print(content)我们模拟浏览器获取网页内容,然后搜索获取的内容,是否有 “J_seckill” 这个元素

可以看到,显示没有该元素。
原因是验证你的浏览器不是真实的浏览器,所以没有返回数据。
但是!!! 用selenium就可以解决这个问题。
# (1)导入
from selenium import webdriver
# from selenium.webdriver.common.by import BY# (2)创建浏览器操作对象
browser = webdriver.Chrome()# (3)访问网站
url = 'https://www.jd.com'
browser.get(url)# (4)获取源码
# page_source获取网页源码
content = browser.page_source
print(content)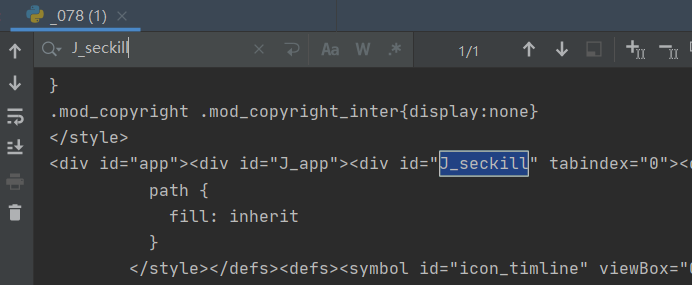
二、selenium语法——元素定位
1.根据 id 找到对象

# 根据 id 找到对象
button = browser.find_element(By.ID, 'su')
print(button)2.根据标签属性的属性值找到对象
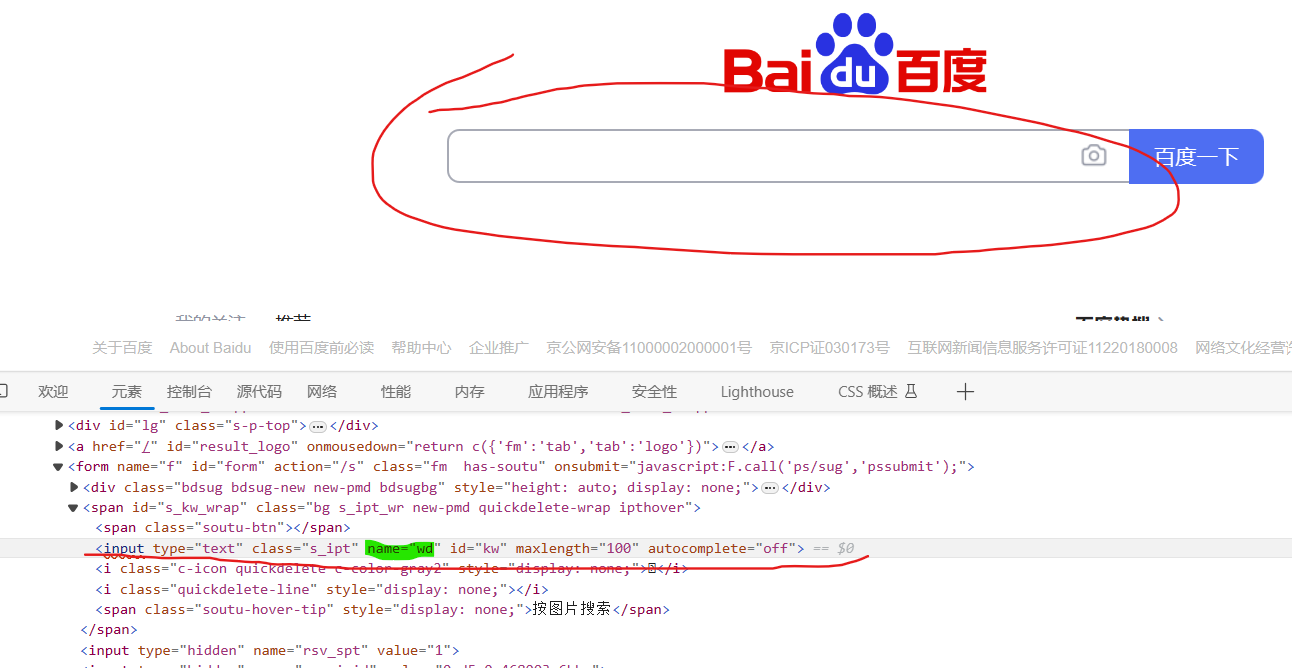
# 根据标签属性的属性值找到对象
button = browser.find_element(By.NAME,'wd')
print(button)3.根据Xpath语句获取对象
# 根据Xpath语句获取对象
# element表示只找一个元素,elements表示找到所有元素并返回列表
button = browser.find_element(By.XPATH,'//input[@id="su"]')
print(button)4.根据标签名获取对象
# 根据标签名获取对象
button = browser.find_elements(By.TAG_NAME,'input')
print(button)5.使用bs语法获取对象
# 使用bs语法获取对象
button = browser.find_elements(By.CSS_SELECTOR,'#su')
print(button)6.通过链接文本获取对象

# 通过链接文本获取对象
button = browser.find_elements(By.LINK_TEXT,'新闻')
print(button)完整代码:
from selenium import webdriver
from selenium.webdriver.common.by import By# 创建浏览器对象
browser = webdriver.Chrome()# 访问网站
url = 'https://www.baidu.com'
browser.get(url)# 元素定位
# # 根据 id 找到对象
# button = browser.find_element(By.ID, 'su')
# print(button)# # 根据标签属性的属性值找到对象
# button = browser.find_element(By.NAME,'wd')
# print(button)# # 根据Xpath语句获取对象
# button = browser.find_element(By.XPATH,'//input[@id="su"]')
# print(button)# # 根据标签名获取对象
# button = browser.find_elements(By.TAG_NAME,'input')# # 使用bs语法获取对象
# button = browser.find_elements(By.CSS_SELECTOR,'#su')# 通过链接文本获取对象
button = browser.find_elements(By.LINK_TEXT,'新闻')
print(button)三、selenium语法——访问元素信息
1.获取属性的属性值
# 获取属性值
input = browser.find_element(By.ID, 'su')
print(input.get_attribute('class'))
2.获取标签名
print(input.tag_name)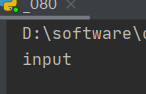
3.获取元素文本
input = browser.find_element(By.LINK_TEXT,'新闻')
print(input.text)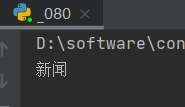
四、selenium 交互
使用selenium完成以下操作
在百度输入框中输入“周杰伦”,点击“百度一下”,滑到最底部,点击“下一页”,然后后退一步,再前进一步,最后关闭浏览器。
from selenium import webdriver
from selenium.webdriver.common.by import By
import time# 创建浏览器对象
browser = webdriver.Chrome()url = 'https://www.baidu.com'
browser.get(url)time.sleep(2)# 获取文本框的对象
input = browser.find_element(By.ID,'kw')# 在文本框中输入‘周杰伦’
input.send_keys('周杰伦')time.sleep(2)# 获取百度一下的按钮
button = browser.find_element(By.ID,'su')
# 点击百度一下
button.click()time.sleep(2)# 滑到底部
js_bottom = 'document.documentElement.scrollTop=100000'
browser.execute_script(js_bottom)time.sleep(2)# 获取下一页的按钮
next = browser.find_element(By.XPATH,'//a[contains(text(),"下一页")]')# 点击下一页
next.click()time.sleep(2)# 回到上一页
browser.back()time.sleep(2)# 回到刚才的位置
browser.forward()time.sleep(2)# 退出
browser.quit()五、无界面操作
直接打开浏览器会使操作效率变慢,Chrome headless可以进行无界面操作,极大提高的了工作效率。
from selenium import webdriverdef headless_browser():# 创建浏览器对象之前,创建options功能对象options = webdriver.ChromeOptions()# 添加无界面功能参数options.add_argument("--headless")# 构造浏览器对象,打开浏览器browser = webdriver.Chrome(options=options)return browserurl = 'https://ww.baidu.com'
browser = headless_browser()
browser.get(url)# 屏幕快照
browser.save_screenshot('_082_baidu.png')参考
尚硅谷Python爬虫教程小白零基础速通(含python基础+爬虫案例)