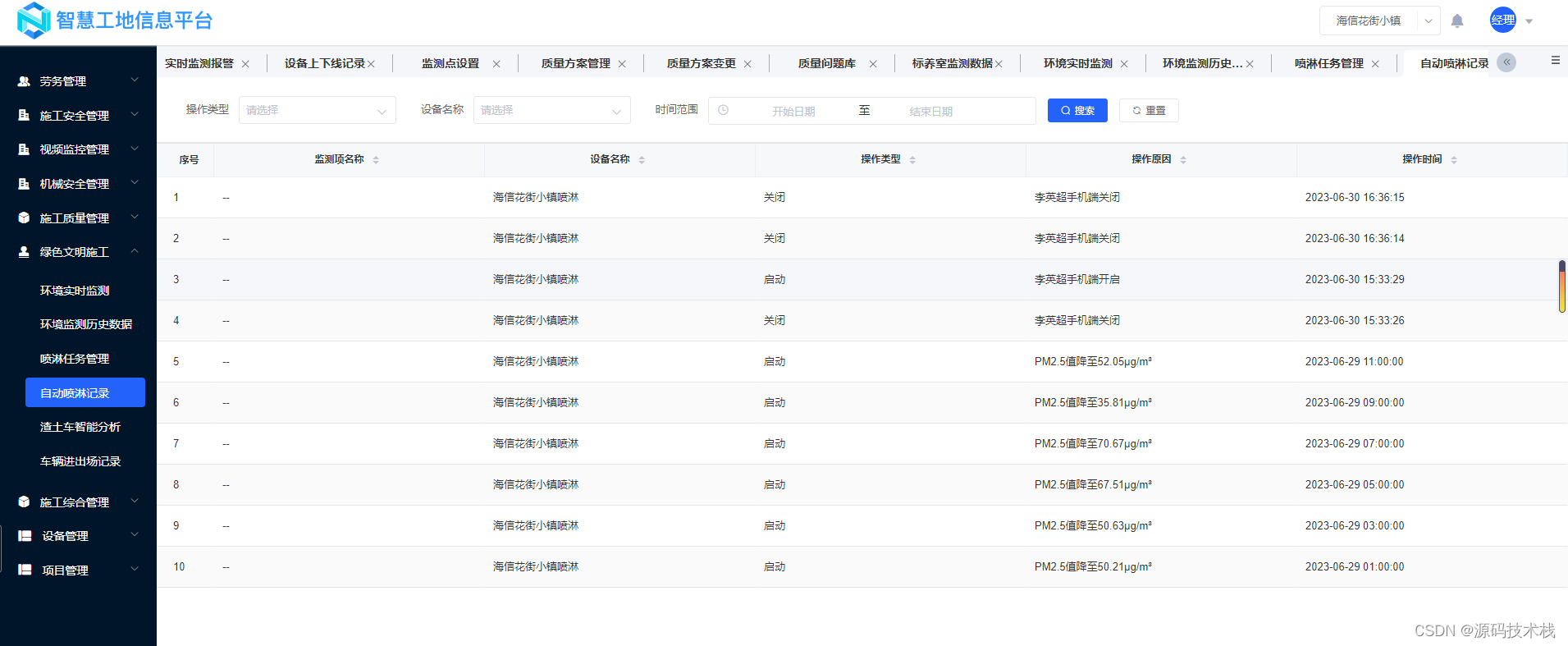
0x31 质数
定义:
若一个正整数无法被除了1和它自身之外的任何自然数整除,则称该数为质数(或素数),否则则称该正整数为合数。
在整个自然数集合中,质数的数量不多,分布比较稀疏,对于一个足够大的整数N,不超过 N N N的质数大约有 N / l n N N/lnN N/lnN个,即 l n N lnN lnN个数中大约有一个质数。
1.质数的判定
试除法
若一个正整数 N N N为合数,则存在一个能整除 N N N的整数 T T T,其中 2 ≤ T ≤ N 2\leq T \leq \sqrt{N} 2≤T≤N。
我们只需扫描 2 ∼ N 2\sim \sqrt{N} 2∼N之间所有的整数,依次检查它们能否整除 N N N,若都不能整除,则 N N N是质数,否则 N N N是合数。试除法的时间复杂度是 O ( N ) O(\sqrt{N}) O(N)。当然我们需要特判0和1这两个数,它们既不是质数也不是合数。
bool is_prime(int n)
{if(n<2)return false;for(int i=2;i<=sqrt(n);++i)if(n%i==0)return false;return true;
}
“试除法”作为最简单也最经典的确定性算法,是我们在算法竞赛中通常会使用的方法。有一些效率更高的随机性算法,例如“Miller-Robbin”等,有较小的概率把合数误判定为质数,但多次判定合起来错误概率趋近于0。
2.质数的筛选
给定一个整数N,求出 1 ∼ N 1\sim N 1∼N之间所有的质数,称为质数的筛选问题。
Eratosthenes筛法(埃式筛法)
Eratosthenes筛法基于这样的想法:任意整数 x x x的倍数 2 x 2x 2x, 3 x 3x 3x,…都不是质数。
我们可以从2开始,由小到大扫描每个数 x x x,然后把它的倍数 2 x 2x 2x, 3 x 3x 3x,…, ⌊ N / x ⌋ ∗ x \lfloor N/x \rfloor *x ⌊N/x⌋∗x标记为合数。当扫描到一个数,若它未被标记,则说明它不能被 2 ∼ x − 1 2\sim x-1 2∼x−1之间的任何数整除,该数就是质数。
Eratosthenes筛法如下:

我们发现,2和3都会把6标记为合数。实际上,小于 x 2 x^2 x2的 x x x的倍数在扫描更小的数时就已经被标记过了。因此,我们可以对Eratosthenes筛法进行优化,对于每个数 x x x,我们只需要从 x 2 x^2 x2开始,把 x 2 x^2 x2, ( x + 1 ) ∗ x (x+1)*x (x+1)∗x, ( x + 2 ) ∗ x (x+2)*x (x+2)∗x,…, ⌊ N / x ⌋ ∗ x \lfloor N/x \rfloor *x ⌊N/x⌋∗x标记为合数即可。
void prime(int n)
{memset(v,0,sizeof(v)); //合数标记,全都标记为质数for(int i=2;i<=n;++i){if(v[i]) continue;cout<<i<<endl; //i是质数for(int j=i;j<=n/i;++j)v[i*j]=1;}
}
Eratosthenes筛法的时间复杂度为 O ( ∑ 质数 p ≤ N N P ) = O ( N l o g l o g n ) O(\sum_{质数p\leq N} \frac{N}{P})=O(Nloglogn) O(∑质数p≤NPN)=O(Nloglogn)。该算法实现简单,效率已经非常接近线性,是算法竞赛中最常用的质数筛法。
Euler筛法(欧拉筛法/线性筛法)
即使在优化后(从 x 2 x^2 x2开始),Eratosthenes筛法仍然会重复标记合数。例如12既会被2标记又会被3标记。其根本原因是我们没有确定出唯一的产生12的方式。
线性筛法通过“从小到大累计质因子”的方式标记每一个合数,即让12只有3*2*2一种方式产生。设数组 v v v记录每个数的最小质因子,我们按照以下步骤维护 v v v。
1.依次考虑 2 ∼ N 2\sim N 2∼N中的每个数 i i i。
2.若 v [ i ] = i v[i]=i v[i]=i,说明 i i i是质数,把它保存下来。
3.扫描不大于 v [ i ] v[i] v[i]的每个质数 p p p,令 v [ i ∗ p ] = p v[i*p]=p v[i∗p]=p。也就是在 i i i的基础上累积一个质因子 p p p。因为 p ≤ v [ i ] p\leq v[i] p≤v[i],所以 p p p就是合数 i ∗ p i*p i∗p的最小质因数。

每个合数只会被它的最小质因数 p p p筛一次,时间复杂度为 O ( n ) O(n) O(n)。
int v[MAX_N],prime[MAX_N];
int m=0; //质数数量
void primes(int n)
{memset(v,0,sizeof(v)); //最小质因子for(int i=2;i<=n;++i){if(v[i]==0)v[i]=i,prime[++m]=i;//给当前的i乘上一个质因子for(int j=1;j<=m;++j){//i有比prime[j]更小的质因子或超出n的范围,停止循环if(prime[j]>v[i]||prime[j]*i>n)break;//prime[j]是合数prime[j]*i的最小质因子v[prime[j]*i]=prime[j];}}
}
我们也可以直接把 v v v数组改为 i s _ p r i m e is\_prime is_prime数组,判断这个数是不是质数。
bool is_prime[MAX_N];
int prime[MAX_N];
int m;
void prime(int n)
{for(int i=2;i<=n;++i)is_prime[i]=true;for(int i=2;i<=n;++i){if(is_prime[i])prime[++m]=i;for(int j=1;j<=m&&i*prime[j]<=n;++j){is_prime[i*prime[j]]=false;//如果i整除prime[j],则说明prime[j]正好是i*prime[j]最小质因数//后面的prime[j+1]大于最小质因数,退出循环if(i%prime[j]==0)break;}}
}
但是这个写法的实际运行时间可能与优化后的埃式筛法近似,因为存在低效的取模运算。
3.质因数分解
算术基本定理
任何一个大于1的正整数都能唯一分解为有限个质数的乘积,可写作:
N = p 1 c 1 p 2 c 2 . . . p m c m N=p_1^{c_1}p_2^{c_2}...p_m^{c_m} N=p1c1p2c2...pmcm
其中 c i c_i ci都是正整数, p i p_i pi都是质数,且满足 p 1 < p 2 < . . . < p m p_1<p_2<...<p_m p1<p2<...<pm。
试除法
结合质数判定的“试除法”和质数筛选的“Eratosthenes筛法”,我们可以扫描 2 ∼ ⌊ N ⌋ 2\sim \lfloor \sqrt{N} \rfloor 2∼⌊N⌋的每个数 d d d,若 d d d能整除 N N N,则从 N N N中除掉所有因子 d d d,同时累计除去的 d d d的个数。时间复杂度为 O ( N ) O(\sqrt{N}) O(N)。
void divide(int n)
{m=0;for(int i=2;i<=sqrt(n);++i){if(n%i==0)//i是质数{p[++m]=i,c[m]=0;while(n%i)n/=i,c[m]++;}}if(n>1) //n是质数p[++m]=n,c[m]=1;
}
“Pollard's Rho”算法是一个比“试除法”效率更高的质因数分解方法。