PyTorch深度学习实战(26)——卷积自编码器
- 0. 前言
- 1. 卷积自编码器
- 2. 使用 t-SNE 对相似图像进行分组
- 小结
- 系列链接
0. 前言
我们已经学习了自编码器 (AutoEncoder) 的原理,并使用 PyTorch 搭建了全连接自编码器,但我们使用的数据集较为简单,每张图像只有一个通道(每张图像都为黑白图像)且图像相对较小 (28 x 28)。但在现实场景中,图像数据通常为彩色图像( 3 个通道)且图像尺寸通常较大。在本节中,我们将实现能够处理多维输入图像的卷积自编码器,为了与普通自编码器进行对比,同样使用 MNIST 数据集。
1. 卷积自编码器
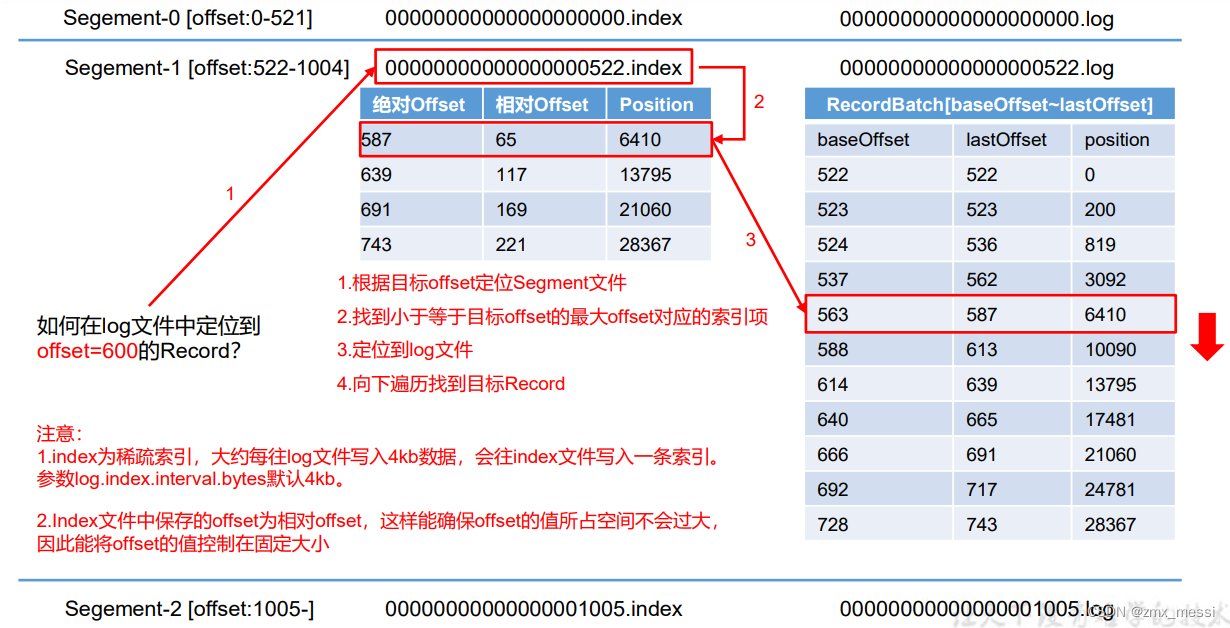
与传统的全连接自编码器不同,卷积自编码器 (Convolutional Autoencoder) 利用卷积层和池化层替代了全连接层,以处理具有高维空间结构的图像数据。这样的设计使得卷积自编码器能够在较少的参数量下对输入数据进行降维和压缩,同时保留重要的空间特征。卷积自编码器架构如下所示:

从上图中可以看出,输入图像被表示为瓶颈层中的潜空间变量,用于重建图像。图像经过多次卷积(编码器)得到低维潜空间表示,然后在解码器中,将潜空间变量还原为原始尺寸,使解码器的输出能够近似恢复原始输入。
本质上,卷积自编码器在其网络中使用卷积、池化操作来代替原始自编码器的全连接操作,并使用反卷积操作 (Conv2DTranspose) 对特征图进行上采样。了解卷积自编码器的原理后,使用 PyTorch 实现此架构。
(1) 数据集的加载和构建方式与全连接自编码器完全相同:
from torchvision.datasets import MNIST
from torchvision import transforms
from torch.utils.data import DataLoader, Dataset
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torchvision.utils import make_grid
import numpy as np
from matplotlib import pyplot as plt
device = 'cuda' if torch.cuda.is_available() else 'cpu'img_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize([0.5], [0.5]),transforms.Lambda(lambda x: x.to(device))
])trn_ds = MNIST('MNIST/', transform=img_transform, train=True, download=True)
val_ds = MNIST('MNIST/', transform=img_transform, train=False, download=True)batch_size = 256
trn_dl = DataLoader(trn_ds, batch_size=batch_size, shuffle=True)
val_dl = DataLoader(val_ds, batch_size=batch_size, shuffle=False)
(2) 定义神经网络类 ConvAutoEncoder。
定义 __init__ 方法:
class ConvAutoEncoder(nn.Module):def __init__(self):super().__init__()
定义编码器架构:
self.encoder = nn.Sequential(nn.Conv2d(1, 32, 3, stride=3, padding=1), nn.ReLU(True),nn.MaxPool2d(2, stride=2),nn.Conv2d(32, 64, 3, stride=2, padding=1), nn.ReLU(True),nn.MaxPool2d(2, stride=1))
在以上代码中,通道数最初由 1 开始,逐渐增加到 64,同时通过 nn.MaxPool2d 和 nn.Conv2d 操作减小输入图像尺寸。
定义解码器架构:
self.decoder = nn.Sequential(nn.ConvTranspose2d(64, 32, 3, stride=2), nn.ReLU(True),nn.ConvTranspose2d(32, 16, 5, stride=3, padding=1), nn.ReLU(True),nn.ConvTranspose2d(16, 1, 2, stride=2, padding=1), nn.Tanh())
定义前向传播方法 forward:
def forward(self, x):x = self.encoder(x)x = self.decoder(x)return x
(3) 使用 summary 方法获取模型摘要信息:
model = ConvAutoEncoder().to(device)
from torchsummary import summary
summary(model, (1,28,28))
输出结果如下所示:
```shell
----------------------------------------------------------------Layer (type) Output Shape Param #
================================================================Conv2d-1 [-1, 32, 10, 10] 320ReLU-2 [-1, 32, 10, 10] 0MaxPool2d-3 [-1, 32, 5, 5] 0Conv2d-4 [-1, 64, 3, 3] 18,496ReLU-5 [-1, 64, 3, 3] 0MaxPool2d-6 [-1, 64, 2, 2] 0ConvTranspose2d-7 [-1, 32, 5, 5] 18,464ReLU-8 [-1, 32, 5, 5] 0ConvTranspose2d-9 [-1, 16, 15, 15] 12,816ReLU-10 [-1, 16, 15, 15] 0ConvTranspose2d-11 [-1, 1, 28, 28] 65Tanh-12 [-1, 1, 28, 28] 0
================================================================
Total params: 50,161
Trainable params: 50,161
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.14
Params size (MB): 0.19
Estimated Total Size (MB): 0.34
----------------------------------------------------------------
从以上模型架构信息可以看出,使用尺寸为 batch size x 64 x 2 x 2 的 MaxPool2d-6 层作为瓶颈层。
模型训练过程,训练和验证损失随时间的变化以及对输入图像的重建结果如下:
def train_batch(input, model, criterion, optimizer):model.train()optimizer.zero_grad()output = model(input)loss = criterion(output, input)loss.backward()optimizer.step()return loss@torch.no_grad()
def validate_batch(input, model, criterion):model.eval()output = model(input)loss = criterion(output, input)return lossmodel = ConvAutoEncoder().to(device)
criterion = nn.MSELoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=0.001, weight_decay=1e-5)num_epochs = 20
train_loss_epochs = []
val_loss_epochs = []
for epoch in range(num_epochs):N = len(trn_dl)trn_loss = []val_loss = []for ix, (data, _) in enumerate(trn_dl):loss = train_batch(data, model, criterion, optimizer)pos = (epoch + (ix+1)/N)trn_loss.append(loss.item())train_loss_epochs.append(np.average(trn_loss))N = len(val_dl)for ix, (data, _) in enumerate(val_dl):loss = validate_batch(data, model, criterion)pos = epoch + (1+ix)/Nval_loss.append(loss.item())val_loss_epochs.append(np.average(val_loss))epochs = np.arange(num_epochs)+1
plt.plot(epochs, train_loss_epochs, 'bo', label='Training loss')
plt.plot(epochs, val_loss_epochs, 'r-', label='Test loss')
plt.title('Training and Test loss over increasing epochs')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.grid('off')
plt.show()for _ in range(5):ix = np.random.randint(len(val_ds))im, _ = val_ds[ix]_im = model(im[None])[0]plt.subplot(121)# fig, ax = plt.subplots(1,2,figsize=(3,3)) plt.imshow(im[0].detach().cpu(), cmap='gray')plt.title('input')plt.subplot(122)plt.imshow(_im[0].detach().cpu(), cmap='gray')plt.title('prediction')plt.show()



从上图中,我们可以看到卷积自编码器重建后的图像比全连接自编码器更清晰,可以通过改变编码器和解码器中的通道数,观察模型训练结果。在下一节中,我们将根据瓶颈层潜变量对相似图像进行分组
2. 使用 t-SNE 对相似图像进行分组
假设相似的图像具有相似的潜变量(也称嵌入),而不相似的图像具有不同的潜变量,使用自编码器,可以在低维空间中表示图像。接下来,我们继续学习图像的相似度度量,在二维空间中绘制潜变量,使用 t-SNE 技术将卷积自编码器的 64 维向量缩减至到 2 维空间。
在 2 维空间中,我们可以方便的可视化潜变量,以观察相似图像是否具有相似的潜变量,相似图像在二维平面中应该聚集在一起。接下里,我们在二维平面中表示所有测试图像的潜变量。
(1) 初始化列表,以便存储潜变量 (latent_vectors) 和相应的图像类别(存储每个图像的类别只是为了验证同一类别的图像是否具有较高的相似性,并不会在训练过程使用):
latent_vectors = []
classes = []
(2) 遍历验证数据加载器 (val_dl) 中的图像,并存储编码器的输出 (model.encoder(im).view(len(im),-1)) 和每个图像 (im) 对应的类别 (clss):
for im,clss in val_dl:latent_vectors.append(model.encoder(im).view(len(im),-1))classes.extend(clss)
(3) 连接潜变量 (latent_vectors) NumPy 数组:
latent_vectors = torch.cat(latent_vectors).cpu().detach().numpy()
(4) 导入 t-SNE 库 (TSNE),并将潜变量转换为二维向量 (TSNE(2)) ,以便进行绘制:
from sklearn.manifold import TSNE
tsne = TSNE(2)
(5) 通过在图像潜变量 (latent_vectors) 上运行 fit_transform 方法来拟合 t-SNE:
clustered = tsne.fit_transform(latent_vectors)
(6) 拟合 t-SNE 后绘制数据点:
fig = plt.figure(figsize=(12,10))
cmap = plt.get_cmap('Spectral', 10)
plt.scatter(*zip(*clustered), c=classes, cmap=cmap)
plt.colorbar(drawedges=True)
plt.show()

可以看到同一类别的图像能够聚集在一起,即相似的图像将具有相似的潜变量值。
小结
卷积自编码器是一种基于卷积神经网络结构的自编码器,适用于处理图像数据。卷积自编码器在图像处理领域有广泛的应用,包括图像去噪、图像压缩、图像生成等任务。通过训练卷积自编码器,可以提取出输入图像的关键特征,并实现对图像数据的降维和压缩,同时保留重要的空间信息。在本节中,我们介绍了卷积自编码器的模型架构,使用 PyTorch 从零开始实现在 MNIST 数据集上训练了一个简单的卷积自编码器,并使用 t-SNE 技术在二维平面中表示了所有测试图像的潜变量。
系列链接
PyTorch深度学习实战(1)——神经网络与模型训练过程详解
PyTorch深度学习实战(2)——PyTorch基础
PyTorch深度学习实战(3)——使用PyTorch构建神经网络
PyTorch深度学习实战(4)——常用激活函数和损失函数详解
PyTorch深度学习实战(5)——计算机视觉基础
PyTorch深度学习实战(6)——神经网络性能优化技术
PyTorch深度学习实战(7)——批大小对神经网络训练的影响
PyTorch深度学习实战(8)——批归一化
PyTorch深度学习实战(9)——学习率优化
PyTorch深度学习实战(10)——过拟合及其解决方法
PyTorch深度学习实战(11)——卷积神经网络
PyTorch深度学习实战(12)——数据增强
PyTorch深度学习实战(13)——可视化神经网络中间层输出
PyTorch深度学习实战(14)——类激活图
PyTorch深度学习实战(15)——迁移学习
PyTorch深度学习实战(16)——面部关键点检测
PyTorch深度学习实战(17)——多任务学习
PyTorch深度学习实战(18)——目标检测基础
PyTorch深度学习实战(19)——从零开始实现R-CNN目标检测
PyTorch深度学习实战(20)——从零开始实现Fast R-CNN目标检测
PyTorch深度学习实战(21)——从零开始实现Faster R-CNN目标检测
PyTorch深度学习实战(22)——从零开始实现YOLO目标检测
PyTorch深度学习实战(23)——使用U-Net架构进行图像分割
PyTorch深度学习实战(24)——从零开始实现Mask R-CNN实例分割
PyTorch深度学习实战(25)——自编码器(Autoencoder)



![Spring MVC框架支持RESTful,设计URL时可以使用{自定义名称}的占位符@Get(“/{id:[0-9]+}/delete“)](https://img-blog.csdnimg.cn/direct/2ee1008dffda49108d2bc419a2865341.png)