水善利万物而不争,处众人之所恶,故几于道💦
文章目录
- 需求
- 分析
- 编写MapReduce实现上述功能
- Mapper类
- Reducer类
- Driver类
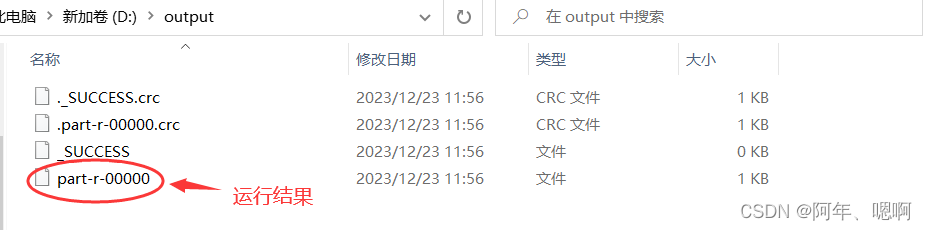
- 查看输出结果
需求
假设有一个文本文件word.txt,我们想要统计这个文本文件中每个单词出现的次数。
文件内容如下:

期望输出结果:

分析
根据MapReduce的思想,整体分为两个过程一个是Map阶段,一个是Reduce阶段。可以粗略得出下面几步:
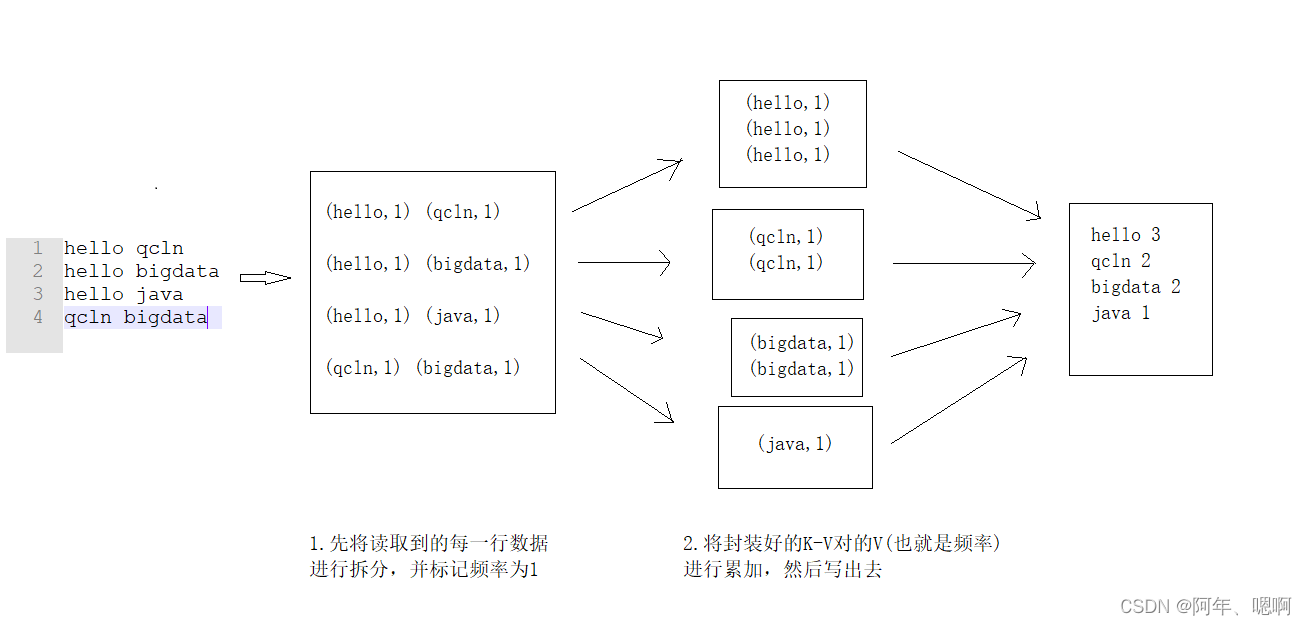
①将读取到的数据进行单词间的拆分,拆出来一个一个的单词。
②将每个单词出现的次数标记为1。eg:(hello,1)、(qcln,1)…
③然后相同单词进入一个ReduceTask,进行value值的累加,也就算出了这个单词出现的次数。
④将最终的结果输出。
编写MapReduce实现上述功能
要先添加Hadoop的项目依赖(建Maven项目)
<dependencies><dependency><!-- Hadoop的项目依赖--><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.3</version></dependency><dependency><!--这个可加可不加,是为了在控制台打印日志的,加上的话要在resources目录下建一个log4j.properties配置文件--><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.30</version></dependency>
</dependencies>
resources目录下log4j.properties配置文件内容:
log4j.rootLogger=INFO,stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
项目目录结构:
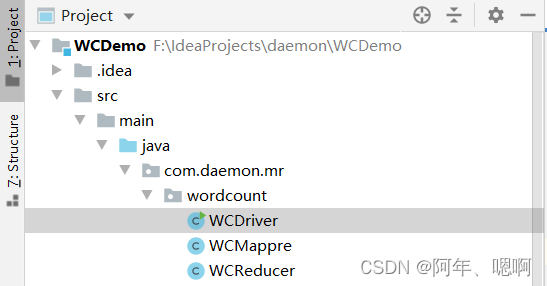
编写MapReduce程序的话要写三个类Mapper、Reducer、Driver
Mapper类:继承Mapper类,重写map方法。每行数据读进来后,他都要调用map方法对数据进行处理,处理完后,再把数据写回框架,让框架处理。
Recuder类:继承Reducer类,重写reduce方法。key值相同的数据会进入同一个reduce方法,这个阶段会调用reduce方法对这一组key值相同的数据进行处理。
Driver类:整个MapReduce程序的入口,在这个类中写main方法。这个类主要是创建一个job实例,然后给job赋值(指定Mapper类、Reducer类、Mapper输出的key value类型、最终结果输出的key value类型、Map Reduce程序的读取文件路径和结果输出路径),最后提交该job
Mapper类
package com.daemon.mr.wordcount;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;/*** Author: Pepsi* Date: 2023/12/21* Desc:*//*
* Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>泛型含义:1.偏移量:是一行中数据的偏移量,可以理解成这一行数据长度的样子。比如第一行 abcde 第二行 qwe,假如第一行的偏移量是0,第二行的偏移量可能就是8这个类型只能为LongWritable类型,偏移量比较大2.读到的每行数据的类型3.输出的key的类型 因为这里词频统计map后想要输出(aaa,2)这种形式,所以key是Text value是LongWritable类型4.输出的value的类型这个类主要的作用就是封装kv对也就是标记,也就是WordCount需求中将每行数据处理为(hello,1)这种格式
* */
public class WCMappre extends Mapper<LongWritable,Text, Text, LongWritable> {// 创建一个输出键的对象,待会儿取到数据后直接赋值给他,然后写出去// 定义在map外面就不用频繁创建对象了private Text outKey = new Text();// 创建一个输出值的对象,也就是那个频率,这里直接给他初始化为1,直接用 private LongWritable outValue = new LongWritable(1);/**** @param key 读取到每行数据的偏移量* @param value 读取到的那一行数据* @param context 上下文对象,可以理解为程序本身,因为是框架下编程,所以处理结果要还给框架* @throws IOException* @throws InterruptedException*/@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//super.map(key, value, context);//System.out.println("这是偏移量:"+key);//将读取到的一行数据转换为字符串类型(Text类型是Hadoop的类型没法切割)// 然后按照空格切分,因为要读取的数据文件中单词之间使用空格分开的String[] words = value.toString().split(" ");// 得到这一行的单词数组后,进行遍历每个单词for (String word : words) {// 将上面创建好的Text对象的值设置为当前遍历到的单词 ==> outKey=qcln outValue=1outKey.set(word);// 写回框架,后续交给框架处理 ==> (qcln,1)context.write(outKey,outValue);}}
}
Reducer类
package com.daemon.mr.wordcount;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;/*** Author: Pepsi* Date: 2023/12/21* Desc:*//*
Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
1.输入的key的类型 也就是Map阶段输出key的类型
2.输入的value的类型 也就是Map阶段输出的value的类型
3.最终结果输出的key的类型 也就是写出到文件中的key的类型,是单词,所以是Text类型
4.最终的结果输出的value的类型 也就是写出到文件中的value的类型,是单词出现的次数,所以是LongWritable类型(IntWritable也行,只不过如果数据量大,怕IntWritable放不下)*/
public class WCReducer extends Reducer<Text, LongWritable,Text,LongWritable> {// 用来存放单词出现的总次数,最后要将他写出去private LongWritable outVale = new LongWritable();/**** @param key map结果输出的key* @param values 相同key的所有值* @param context 上下文* @throws IOException* @throws InterruptedException*/@Overrideprotected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {//super.reduce(key, values, context);// 累加变量,存放单词出现的总次数,待会要把这个结果赋给LongWritable,然后写出去long count = 0;// 遍历每个valuefor (LongWritable value : values) {// get()方法返回一个long类型的值count+=value.get();}// 将long类型的累加变量赋值给LongWritable => outVale=2outVale.set(count);// 将结果写出去 => (qcln,2)context.write(key,outVale);}
}
Driver类
package com.daemon.mr.wordcount;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;/*** Author: Pepsi* Date: 2023/12/21* Desc:*/
public class WCDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {Configuration conf = new Configuration();// 1. 创建job实例,可以不传conf,传的话可以用conf.set(key,value)进行一些配置Job job = Job.getInstance(conf);// 2. 给job赋值// 设置jar的入口类,如果是本地运行可以不写,如果想要将项目打jar包扔在集群上运行必须写job.setJarByClass(WCDriver.class);// 指定Mapper和Reducer类job.setMapperClass(WCMappre.class);job.setReducerClass(WCReducer.class);// 设置Mapper输出的key value 类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(LongWritable.class);// 设置整个程序输出的key value类型 -- Reducer的输出也就是整个程序的输出,所以也可以理解为Reducer的输出类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(LongWritable.class);// 设置程序从哪读取文件,将结果输出到哪,输出目录不能存在FileInputFormat.setInputPaths(job,new Path("D:\\word.txt"));FileOutputFormat.setOutputPath(job,new Path("D:\\output"));// 3. 提交job,运行。 也可以不接收这个返回值boolean b = job.waitForCompletion(true);// 程序结束返回的状态码System.exit(b ? 0 : 1);}
}查看输出结果