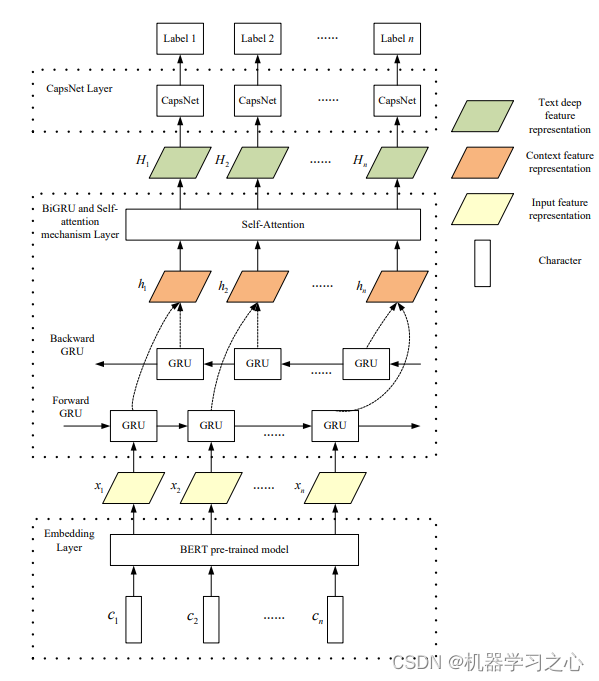
简介
Spark shell是一个特别适合快速开发Spark原型程序的工具,可以帮助我们熟悉Scala语言。即使你对Scala不熟悉,仍然可以使用这个工具。Spark shell使得用户可以和Spark集群交互,提交查询,这便于调试,也便于初学者使用Spark。前一章介绍了运行Spark实例之前的准备工作,现在你可以开启一个Spark shell,然后用下面的命令连接你的集群:
spark-shell spark://vm02:7077
格式:spark-shell spark://host:port, 可以进入spark集群的任意一个节点
默认情况是进入到一个scala语言环境的一个交互窗口。
[hadoop@vm03 bin]$ spark-shell spark://vm02:7077
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
23/12/21 20:06:11 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://vm03:4040
Spark context available as 'sc' (master = local[*], app id = local-1703160374523).
Spark session available as 'spark'.
Welcome to____ __/ __/__ ___ _____/ /___\ \/ _ \/ _ `/ __/ '_//___/ .__/\_,_/_/ /_/\_\ version 3.5.0/_/Using Scala version 2.12.18 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_144)
Type in expressions to have them evaluated.
Type :help for more information.scala>以上进入spark交互窗口中,输出一些日志信息,包含指定APP ID信息。
master = local[*], app id = local-1703160374523
local[*] 是一种运行模式,用于指定 Spark 应用程序在本地模式下运行,而 * 表示 Spark 应该使用所有可用的 CPU 核心。如果需要使用多线程运行模式需要指定运行的线程数量local[N].
加载一个简单的text文件
在服务器上随便创建一个txt文件用于做演示
随便造数据如下:
[hadoop@vm02 ~]$ vim text.txtName, Age, City, Occupation, Salary
John, 25, New York, Engineer, 80000
Alice, 30, San Francisco, Data Scientist, 90000
Bob, 28, Los Angeles, Software Developer, 85000
Eva, 22, Chicago, Student, 0
Michael, 35, Boston, Manager, 100000
Olivia, 29, Seattle, Designer, 95000
David, 31, Austin, Analyst, 88000
Sophia, 26, Denver, Teacher, 75000
Daniel, 33, Miami, Doctor, 120000
Emma, 27, Atlanta, Nurse, 70000
William, 32, Houston, Researcher, 95000
Ava, 24, Phoenix, Artist, 78000
James, 29, San Diego, Programmer, 92000
Grace, 28, Portland, Writer, 86000
Jackson, 30, Nashville, Musician, 110000
Lily, 26, Minneapolis, Chef, 89000
Ethan, 35, Detroit, Entrepreneur, 130000
Chloe, 23, Philadelphia, Student, 0
Logan, 31, Pittsburgh, Engineer, 98000
Harper, 27, Charlotte, Manager, 105000
Aiden, 28, Las Vegas, Developer, 90000
Mia, 25, Dallas, Scientist, 95000
Lucas, 30, San Antonio, Designer, 85000
Evelyn, 29, Raleigh, Teacher, 78000
Noah, 34, Orlando, Doctor, 115000
Amelia, 26, Sacramento, Analyst, 92000
Sophie, 32, Tampa, Nurse, 75000
Owen, 28, St. Louis, Researcher, 98000
Isabella, 31, Kansas City, Writer, 86000
使用spark-shell交互页面,进行读取该文件内容。
scala> val infile = sc.textFile("file:/home/hadoop/text.txt")
infile: org.apache.spark.rdd.RDD[String] = file:/home/hadoop/text.txt MapPartitionsRDD[1] at textFile at <console>:23
val infile = sc.textFile("/home/hadoop/text.txt")
这段代码的目的是读取指定路径下的文本文件,创建一个Spark RDD(infile),该RDD包含文件中的每一行作为一个元素。这是在Spark中处理文本数据的一种常见方式。将text.txt文件中的每行作为一个RDD(Resilient Distributed Datasets)中的单独元素加载到Spark中,并返回一个名为infile的RDD。
多副本范例
注意当你连接到Spark的master之后,若集群中没有分布式文件系统,Spark会在集群中每一台机器上加载数据,所以要确保集群中的每个节点上都有完整数据。通常可以选择把数据放到HDFS、S3或者类似的分布式文件系统去避免这个问题。在本地模式下,可以将文件从本地直接加载,例如
sc.textFile([filepah]),想让文件在所有机器上都有备份,请使用SparkContext类中的addFile函数,代码如下:
import org.apache.spark.SparkFiles;
val file =sc.addFile("file:/home/hadoop/text.txt")
val inFile=sc.textFile(SparkFiles.get("text.txt"))addFile可以把文件分发到各个worker当中,然后worker会把文件存放在临时目录下。之后可以通过SparkFiles.get()获取文件
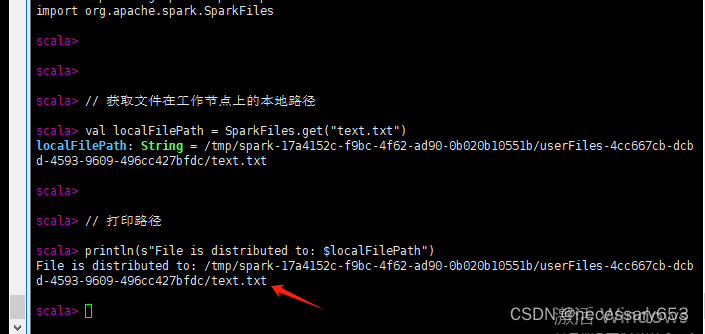
import org.apache.spark.SparkFiles// 获取文件在工作节点上的本地路径
val localFilePath = SparkFiles.get("text.txt")// 打印路径
println(s"File is distributed to: $localFilePath")在其他节点,可以通过 SparkFiles的get()函数获取其存储路径
文件内容读取范例
在读取文件的时候,需要所有节点均存在该文件,不然后报错文件不存在,本spark基于hadoop for hdfs的分布式文件系统进行演练,首先需要将文件上传到hdfs文件系统中去
[hadoop@vm02 ~]$ hdfs dfs -mkdir /hadoop
[hadoop@vm02 ~]$ hdfs dfs -ls /
Found 3 items
drwxr-xr-x - hadoop supergroup 0 2023-12-21 22:31 /hadoop
drwxr-xr-x - hadoop supergroup 0 2023-12-18 10:06 /hbase
drwxr-xr-x - hadoop supergroup 0 2023-11-28 09:33 /home
[hadoop@vm02 ~]$ hdfs dfs -put /home/hadoop/text.txt /hadoop/
[hadoop@vm02 ~]$ hdfs dfs -ls /hadoop
Found 1 items
-rw-r--r-- 3 hadoop supergroup 1119 2023-12-21 22:31 /hadoop/text.txt
将文件上传到hdfs中去,使用first进行查看文件内容表头信息
import org.apache.spark.SparkFiles;
val infile = sc.textFile("hdfs://vm02:8020/hadoop/text.txt")
infile.first() 这里的8020是hdfs的rpc端口。

spark-shell的逻辑回归
在 Spark 中,逻辑回归是一种用于二分类问题的机器学习算法。尽管它的名字中包含"回归",但实际上它是一种分类算法,用于预测一个二元目标变量的概率。
scala> import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.classification.LogisticRegressionscala> import org.apache.spark.ml.feature.VectorAssembler
import org.apache.spark.ml.feature.VectorAssemblerscala> import org.apache.spark.sql.{SparkSession, DataFrame}
import org.apache.spark.sql.{SparkSession, DataFrame}scala> scala> scala> val spark = SparkSession.builder.appName("LogisticRegressionExample").getOrCreate()
23/12/22 00:15:24 WARN SparkSession: Using an existing Spark session; only runtime SQL configurations will take effect.
spark: org.apache.spark.sql.SparkSession = org.apache.spark.sql.SparkSession@13f05e8escala> val data = Seq(| (1.0, 0.1, 0.5),| (0.0, 0.2, 0.6),| (1.0, 0.3, 0.7),| (0.0, 0.4, 0.8)| )
data: Seq[(Double, Double, Double)] = List((1.0,0.1,0.5), (0.0,0.2,0.6), (1.0,0.3,0.7), (0.0,0.4,0.8))scala> scala> val columns = Seq("label", "feature1", "feature2")
columns: Seq[String] = List(label, feature1, feature2)scala> scala> val df: DataFrame = data.toDF(columns: _*)
df: org.apache.spark.sql.DataFrame = [label: double, feature1: double ... 1 more field]scala> df.show()
+-----+--------+--------+
|label|feature1|feature2|
+-----+--------+--------+
| 1.0| 0.1| 0.5|
| 0.0| 0.2| 0.6|
| 1.0| 0.3| 0.7|
| 0.0| 0.4| 0.8|
+-----+--------+--------+scala> val assembler = new VectorAssembler()
assembler: org.apache.spark.ml.feature.VectorAssembler = VectorAssembler: uid=vecAssembler_dc7bc810fe30, handleInvalid=errorscala> .setInputCols(Array("feature1", "feature2"))
res1: assembler.type = VectorAssembler: uid=vecAssembler_dc7bc810fe30, handleInvalid=error, numInputCols=2scala> .setOutputCol("features")
res2: res1.type = VectorAssembler: uid=vecAssembler_dc7bc810fe30, handleInvalid=error, numInputCols=2scala> scala> val assembledData = assembler.transform(df)
assembledData: org.apache.spark.sql.DataFrame = [label: double, feature1: double ... 2 more fields]scala> assembledData.show()
+-----+--------+--------+---------+
|label|feature1|feature2| features|
+-----+--------+--------+---------+
| 1.0| 0.1| 0.5|[0.1,0.5]|
| 0.0| 0.2| 0.6|[0.2,0.6]|
| 1.0| 0.3| 0.7|[0.3,0.7]|
| 0.0| 0.4| 0.8|[0.4,0.8]|
+-----+--------+--------+---------+scala> val lr = new LogisticRegression()
lr: org.apache.spark.ml.classification.LogisticRegression = logreg_29b7d06469bascala> .setLabelCol("label")
res4: org.apache.spark.ml.classification.LogisticRegression = logreg_29b7d06469bascala> .setFeaturesCol("features")
res5: org.apache.spark.ml.classification.LogisticRegression = logreg_29b7d06469bascala> .setMaxIter(10)
res6: res5.type = logreg_29b7d06469bascala> .setRegParam(0.01)
res7: res6.type = logreg_29b7d06469bascala> val lrModel = lr.fit(assembledData)
23/12/22 00:15:43 WARN InstanceBuilder: Failed to load implementation from:dev.ludovic.netlib.blas.JNIBLAS
lrModel: org.apache.spark.ml.classification.LogisticRegressionModel = LogisticRegressionModel: uid=logreg_29b7d06469ba, numClasses=2, numFeatures=2scala> val summary = lrModel.summary
summary: org.apache.spark.ml.classification.LogisticRegressionTrainingSummary = org.apache.spark.ml.classification.BinaryLogisticRegressionTrainingSummaryImpl@4369db27scala> println(s"Coefficients: ${lrModel.coefficients}")
Coefficients: [-4.371555225626981,-4.37155522562698]scala> println(s"Intercept: ${lrModel.intercept}")
Intercept: 3.9343997030642823scala> println(s"Objective History: ${summary.objectiveHistory.mkString(", ")}")
Objective History: 0.6931471805599453, 0.5954136109155707, 0.5904687934140505, 0.5901819039583514, 0.5901795791081599, 0.5901795782746598在进行 拟合模型的时候,会占用较高的内存,如果内存不足,会导致内存溢出而退出spark-shell会话。通过以下命令,增加算子内存
spark-shell --conf spark.executor.memory=4g但是不能超过可用内存
free -h 代码含义解释
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.feature.VectorAssembler
import org.apache.spark.sql.{SparkSession, DataFrame}此部分导入了必要的Spark MLlib类和Spark SQL类。
val spark = SparkSession.builder.appName("LogisticRegressionExample").getOrCreate()
这创建了一个Spark会话,应用程序的名称为"LogisticRegressionExample"。
val data = Seq((1.0, 0.1, 0.5),(0.0, 0.2, 0.6),(1.0, 0.3, 0.7),(0.0, 0.4, 0.8)
)val columns = Seq("label", "feature1", "feature2")val df: DataFrame = data.toDF(columns: _*)
df.show()
此部分使用示例数据创建了一个名为df的DataFrame,其中每一行表示一个数据点,具有标签("label")和两个特征("feature1"和"feature2")。show()方法用于显示DataFrame。
val assembler = new VectorAssembler().setInputCols(Array("feature1", "feature2")).setOutputCol("features")val assembledData = assembler.transform(df)
assembledData.show()
使用VectorAssembler将"feature1"和"feature2"列组合成名为"features"的单列。结果的DataFrame存储在assembledData中,并显示出来。
val lr = new LogisticRegression().setLabelCol("label").setFeaturesCol("features").setMaxIter(10).setRegParam(0.01)
此部分创建了一个逻辑回归模型(lr)并设置了一些参数,例如标签列,特征列,最大迭代次数(setMaxIter)和正则化参数(setRegParam)。
val lrModel = lr.fit(assembledData)
使用fit方法在组合数据(assembledData)上训练逻辑回归模型。
val summary = lrModel.summary
println(s"Coefficients: ${lrModel.coefficients}")
println(s"Intercept: ${lrModel.intercept}")
println(s"Objective History: ${summary.objectiveHistory.mkString(", ")}")
此部分输出逻辑回归模型训练的各种结果。显示了系数,截距和训练过程中目标函数的历史记录。summary对象提供了有关训练摘要的其他信息。
这里使用scala 语法相当繁琐,转换为python的语法就会简单很多
python示例
from pyspark.sql import SparkSession
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.classification import LogisticRegression# 创建 Spark 会话
spark = SparkSession.builder \.appName("LogisticRegressionExample") \.master("spark://10.0.0.102:7077") \
.getOrCreate()# 创建包含一些示例数据的 DataFrame
data = [(1.0, 0.1, 0.5),(0.0, 0.2, 0.6),(1.0, 0.3, 0.7),(0.0, 0.4, 0.8)
]columns = ["label", "feature1", "feature2"]df = spark.createDataFrame(data, columns)
df.show()# 使用 VectorAssembler 将特征列合并成一个特征向量
assembler = VectorAssembler(inputCols=["feature1", "feature2"], outputCol="features")
assembledData = assembler.transform(df)
assembledData.show()# 创建逻辑回归模型
lr = LogisticRegression(labelCol="label", featuresCol="features", maxIter=10, regParam=0.01)# 拟合模型
lrModel = lr.fit(assembledData)# 查看模型的训练结果
print("Coefficients: {}".format(lrModel.coefficients))
print("Intercept: {}".format(lrModel.intercept))
print("Objective History: {}".format(lrModel.summary.objectiveHistory()))
此时可以登录到spark web上查看任务情况
http://10.0.0.102:8081/

spark web ui 的端口信息可以通过以下方式查看
ps -ef |grep webui-port
当资源不足时,执行代码过程中没五秒钟会输出一次提示信息(不影响代码执行)

23/12/22 00:54:47 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources