目录
yolov8导航
YOLOv8(附带各种任务详细说明链接)
搭建环境说明
不同版本模型性能对比
不同版本对比
参数解释
模型解释
训练
训练示意代码
训练数据与.yaml配置方法
.yaml配置
数据集路径
标签数据说明
训练参数说明
训练过程示意及输出文件说明
训练成功示意
输出文件说明
验证
验证示意代码
验证结果
验证参数
预测
预测示意代码
boxes输出示意
keypoints输出示意
预测参数说明
总结
yolov8导航
如果大家想要了解关于yolov8的其他任务和相关内容可以点击这个链接,我这边整理了许多其他任务的说明博文,后续也会持续更新,包括yolov8模型优化、sam等等的相关内容。
YOLOv8(附带各种任务详细说明链接)
搭建环境说明
如果不知道如何搭建的小伙伴可以参考这个博文:
超级详细的!多种方式YOLOV8安装及测试
操作系统:win10 x64
编程语言:python3.9
开发环境:Anaconda
示例项目下载地址:
基于YOLOv8-Pose的姿态识别项目,带数据集可直接跑通的源码
不同版本模型性能对比
不同版本对比
| 模型 | 尺寸 (像素) | mAP姿态 50-95 | mAP姿态 50 | CPU ONNX 速度 (毫秒) | A100 TensorRT 速度 (毫秒) | 参数 (M) | 浮点数运算 (B) |
|---|---|---|---|---|---|---|---|
| YOLOv8n-pose | 640 | 50.4 | 80.1 | 131.8 | 1.18 | 3.3 | 9.2 |
| YOLOv8s-pose | 640 | 60.0 | 86.2 | 233.2 | 1.42 | 11.6 | 30.2 |
| YOLOv8m-pose | 640 | 65.0 | 88.8 | 456.3 | 2.00 | 26.4 | 81.0 |
| YOLOv8l-pose | 640 | 67.6 | 90.0 | 784.5 | 2.59 | 44.4 | 168.6 |
| YOLOv8x-pose | 640 | 69.2 | 90.2 | 1607.1 | 3.73 | 69.4 | 263.2 |
| YOLOv8x-pose-p6 | 1280 | 71.6 | 91.2 | 4088.7 | 10.04 | 99.1 | 1066.4 |
参数解释
- 尺寸 (像素): 输入图像的分辨率。
- mAP姿态 50-95: 模型在多种IoU阈值(从0.50到0.95)上的平均准确率,用于评估模型在姿态估计任务上的总体性能。
- mAP姿态 50: 在IoU为0.50的阈值上的模型准确率,通常更容易达成,用于评估模型对较大误差的容忍度。
- CPU ONNX 速度 (毫秒): 在CPU上使用ONNX格式运行时的推理速度。
- A100 TensorRT 速度 (毫秒): 在NVIDIA A100 GPU上使用TensorRT优化时的推理速度。
- 参数 (M): 模型中的参数数量,以百万为单位。参数越多,模型通常越复杂。
- 浮点数运算 (B): 执行一次前向传播所需的浮点运算次数,以十亿为单位。这反映了模型的计算复杂度。
模型解释
- YOLOv8n-pose: “n”代表“nano”,是系列中最轻量级的模型,适用于计算资源受限的环境。
- YOLOv8s-pose: “s”代表“small”,是相对轻量级但性能更好的模型,平衡了速度和准确度。
- YOLOv8m-pose: “m”代表“medium”,是中等大小的模型,提供较高的准确度,适用于需要更准确结果的场景。
- YOLOv8l-pose: “l”代表“large”,是较大的模型,具有更高的准确度,但速度较慢,适用于高精度要求的应用。
- YOLOv8x-pose: “x”代表“extra large”,是系列中最大最精确的模型,但速度最慢,适用于对准确度有极高要求的场景。
- YOLOv8x-pose-p6: 是YOLOv8x的一个变种,使用更大的输入尺寸(1280像素),提供了更高的准确度,但需要更多的计算资源。
训练
训练示意代码
from ultralytics import YOLOmodel = YOLO('yolov8n-pose.yaml').load('yolov8n-pose.pt') # 从YAML构建并传输权重if __name__ == '__main__':# 训练模型results = model.train(data='coco8-pose.yaml', epochs=10, imgsz=320)# 模型验证model.val()-
导入 YOLO 类: 从
ultralytics库导入YOLO类。 -
创建模型实例: 使用
yolov8n-pose.yaml配置文件创建一个YOLO模型实例,并通过.load('yolov8n-pose.pt')方法加载预训练的权重。 -
模型训练:
- 在
if __name__ == '__main__':条件下,确保训练代码只在直接运行脚本时执行。 - 使用
model.train()方法开始训练过程,指定数据集配置文件coco8-pose.yaml、训练周期epochs=10和输入图像大小imgsz=320。
- 在
-
模型验证:
- 使用
model.val()方法在验证集上评估模型的性能。
- 使用
训练数据与.yaml配置方法
.yaml配置
# 数据集的根目录路径。
path: C:/Users/admin/Desktop/CSDN/YOLOV8_DEF/ultralytics-pose/coco8-pose
# 训练集的相对路径,这里是 path 路径下的 images/train 目录,包含4张训练用图片。
train: images/train
# 验证集的相对路径,这里是 path 路径下的 images/val 目录,包含4张验证用图片。
val: images/val
test: # test# 关键点的形状,表示有17个关键点,每个关键点有3个维度(通常是x坐标、y坐标和一个表示可见性的标记)。
kpt_shape: [17, 3]
# 翻转索引,用于在数据增强(如图像翻转)时调整关键点的顺序。
flip_idx: [0, 2, 1, 4, 3, 6, 5, 8, 7, 10, 9, 12, 11, 14, 13, 16, 15]# 类别名称。
names:0: person# 提供一个可选的下载链接,用于获取数据集。
download: https://ultralytics.com/assets/coco8-pose.zip数据集路径
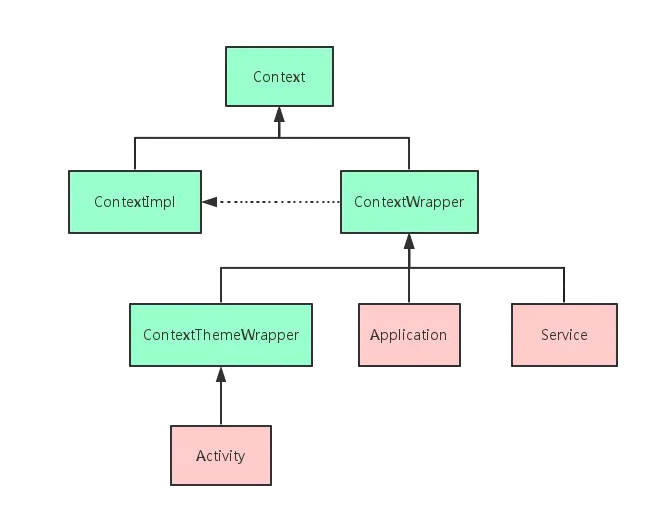
这里需要注意,训练集测试集的图片和标签都要一一对应。同时,注意观察这里面的路径是和 .yaml文件中都是对应的关系。
标签数据说明
0 0.662641 0.494385 0.674719 0.988771 0.717187 0.189583 2.000000 0.798438 0.127083 2.000000 0.701562 0.091667 2.000000 0.921875 0.118750 2.000000 0.000000 0.000000 0.000000 0.971875 0.379167 2.000000 0.554688 0.262500 2.000000 0.000000 0.000000 0.000000 0.367188 0.427083 2.000000 0.767188 0.772917 2.000000 0.421875 0.500000 2.000000 0.829688 0.960417 1.000000 0.517188 0.881250 1.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000
0 0.198031 0.560677 0.392687 0.586521 0.104688 0.522917 2.000000 0.142187 0.481250 2.000000 0.084375 0.468750 2.000000 0.250000 0.497917 2.000000 0.000000 0.000000 0.000000 0.301563 0.633333 2.000000 0.048438 0.635417 2.000000 0.365625 0.833333 1.000000 0.015625 0.858333 1.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000
0 0.487922 0.144948 0.200563 0.285396 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.437500 0.145833 2.000000 0.562500 0.108333 2.000000 0.414062 0.287500 1.000000 0.593750 0.225000 1.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.464062 0.400000 1.000000 0.551562 0.395833 1.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000
0 0.360898 0.098250 0.106328 0.196500 0.418750 0.041667 1.000000 0.423438 0.027083 1.000000 0.401562 0.031250 2.000000 0.000000 0.000000 0.000000 0.384375 0.045833 2.000000 0.000000 0.000000 0.000000 0.368750 0.091667 2.000000 0.000000 0.000000 0.000000 0.326562 0.177083 2.000000 0.000000 0.000000 0.000000 0.373437 0.108333 2.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000
0 0.283820 0.093937 0.126391 0.178792 0.264062 0.097917 2.000000 0.273438 0.083333 2.000000 0.254688 0.085417 2.000000 0.296875 0.064583 2.000000 0.000000 0.000000 0.000000 0.335938 0.110417 2.000000 0.257812 0.122917 2.000000 0.331250 0.208333 1.000000 0.237500 0.202083 1.000000 0.304688 0.127083 2.000000 0.239063 0.127083 2.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000
0 0.101781 0.181698 0.203563 0.363396 0.171875 0.095833 2.000000 0.000000 0.000000 0.000000 0.162500 0.089583 2.000000 0.000000 0.000000 0.000000 0.139063 0.104167 2.000000 0.004687 0.158333 2.000000 0.112500 0.185417 2.000000 0.000000 0.000000 0.000000 0.167187 0.312500 1.000000 0.000000 0.000000 0.000000 0.178125 0.189583 2.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000
0 0.662703 0.090156 0.054250 0.175229 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.651563 0.033333 2.000000 0.684375 0.033333 2.000000 0.629687 0.070833 1.000000 0.692187 0.081250 1.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.634375 0.206250 1.000000 0.681250 0.208333 1.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000
0 0.586672 0.097323 0.124219 0.194646 0.545312 0.018750 2.000000 0.556250 0.002083 2.000000 0.535937 0.002083 2.000000 0.589063 0.006250 2.000000 0.000000 0.000000 0.000000 0.618750 0.058333 2.000000 0.526563 0.075000 1.000000 0.612500 0.179167 2.000000 0.000000 0.000000 0.000000 0.537500 0.181250 1.000000 0.000000 0.000000 0.000000 0.600000 0.275000 1.000000 0.531250 0.283333 1.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 这些数据来自 coco8-pose 数据集的标签文件,用于描述图像中人物的姿态。每行代表一个图像中的一个人物,格式如下:
-
类别ID:每行的第一个数字,这里都是
0,代表 “person” 类别。 -
归一化的中心坐标、宽度和高度:
- 第二个和第三个数字是目标(人物)的中心坐标的 x 和 y,已归一化到 [0, 1] 的范围。
- 第四个和第五个数字是目标的宽度和高度,同样归一化到 [0, 1] 的范围。
-
关键点:之后的每三个数字是一个关键点。每个关键点由以下三个部分组成:
- 第一个数字(x坐标):关键点的 x 坐标,归一化到 [0, 1]。
- 第二个数字(y坐标):关键点的 y 坐标,归一化到 [0, 1]。
- 第三个数字:关键点的可见性。通常,1 表示关键点可见,2 表示关键点被遮挡,0 表示关键点不存在或未标记。
例如,对于一行数据:
0 0.662641 0.494385 0.674719 0.988771 0.717187 0.189583 2.000000 ...
0表示这是类别 “person”。0.662641和0.494385是人物中心的归一化 x 和 y 坐标。0.674719和0.988771是归一化的宽度和高度。- 接下来的数字
0.717187 0.189583 2.000000描述了第一个关键点:归一化坐标 (0.717187, 0.189583) 和其可见性状态 2(被遮挡)。
这种数据格式对于基于关键点的姿态估计任务非常关键,允许模型学习如何识别和定位人体的不同部位。
训练参数说明
训练过程示意及输出文件说明
训练成功示意
实际上就是模型开始迭代了就成功了,此处省略...
看到了这个runs\segment\train\weights\best.pt这个路径的时候说明模型已经训练完了,并且把训练的结果已经保存到了这个文件夹中。输出的结果如下:

输出文件说明
-
Weights文件:这是一个模型权重文件,通常以
.pt(PyTorch模型)格式保存。它包含了经过训练的神经网络的所有参数和权重。这个文件是模型训练过程的直接产物,用于后续的图像识别和分析任务。 -
Args.yaml文件:这个文件通常包含了模型训练时使用的配置参数。它详细记录了训练过程中使用的所有设置,如学习率、批大小、训练轮数等。这个文件的目的是为了提供一个清晰的训练配置概览,使得训练过程可以被复现或调整。
-
F1-置信度曲线 (BoxF1_curve.png):展示模型预测的F1得分与置信度阈值的关系。
-
精确度-置信度曲线 (BoxP_curve.png):反映了模型预测的精确度随置信度阈值变化的趋势。
-
精确度-召回曲线 (BoxPR_curve.png):表明了精确度与召回率之间的权衡关系。
-
召回率-置信度曲线 (BoxR_curve.png):描绘了召回率随置信度阈值变化的情况。
-
混淆矩阵 (confusion_matrix.png):展示了模型预测结果与真实标签的对比情况。
-
归一化混淆矩阵 (confusion_matrix_normalized.png):混淆矩阵的归一化版本,便于比较不同类别的预测准确率。
-
标签分布图 (labels.jpg):显示了数据集中不同类别标签的分布情况。
-
标签相关图 (labels_correlogram.jpg):展示了数据集中不同标签间的相关性。
-
姿势F1-置信度曲线 (PoseF1_curve.png):特定于姿势检测的F1得分与置信度阈值之间的关系。
-
姿势精确度-置信度曲线 (PoseP_curve.png):针对姿势检测的精确度与置信度阈值的关系图。
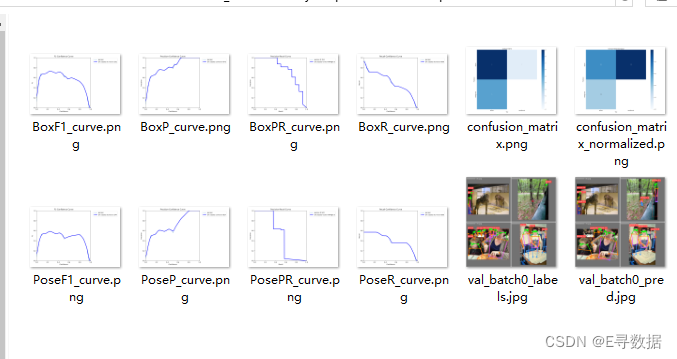
- results.png:这是一个包含多个图表的总览图,每个小图代表了不同的性能指标,如损失和精确度,随训练过程中的轮次变化。
- results.csv:通常这个文件包含了每个训练轮次的具体数值数据,可以用来生成上述的图表。
- PosePR_curve.png:展示了姿势检测任务的精确度-召回率曲线,这是评估分类模型好坏的常用方法,特别是在目标检测任务中。
- PoseR_curve.png:表示姿势检测任务的召回率与置信度阈值之间的关系,用于找到模型召回率最优化的置信度阈值。
验证
验证示意代码
# 验证模型
metrics = model.val() # 无需参数,数据集和设置已记忆上文中进行模型训练的时候有这个代码,是直接对模型基于验证数据集进行验证测试模型实际预测效果。
验证结果
当执行完了验证之后会输出如下文件:
验证参数
| 键 | 值 | 描述 |
|---|---|---|
| data | None | 数据文件的路径,例如 coco128.yaml |
| imgsz | 640 | 输入图像的大小,以整数表示 |
| batch | 16 | 每批图像的数量(AutoBatch 为 -1) |
| save_json | False | 将结果保存至 JSON 文件 |
| save_hybrid | False | 保存混合版本的标签(标签 + 额外预测) |
| conf | 0.001 | 用于检测的对象置信度阈值 |
| iou | 0.6 | NMS(非极大抑制)用的交并比(IoU)阈值 |
| max_det | 300 | 每张图像的最大检测数量 |
| half | True | 使用半精度(FP16) |
| device | None | 运行所用的设备,例如 cuda device=0/1/2/3 或 device=cpu |
| dnn | False | 使用 OpenCV DNN 进行 ONNX 推理 |
| plots | False | 在训练期间显示图表 |
| rect | False | 矩形验证,每批图像为了最小填充整齐排列 |
| split | val | 用于验证的数据集分割,例如 'val'、'test' 或 'train' |
预测
预测示意代码
from ultralytics import YOLO# 加载模型
model = YOLO('yolov8n-pose.pt') # 预训练的 YOLOv8n 模型# 在图片列表上运行批量推理
results = model(['im1.jpg', 'im2.jpg'], save=True) # 返回 Results 对象列表# 处理结果列表
for result in results:boxes = result.boxes # 边界框输出的 Boxes 对象keypoints = result.keypoints # 姿态输出的 Keypoints 对象print(boxes, masks, keypoints, probs)boxes输出示意
cls: tensor([0., 0.], device='cuda:0')
conf: tensor([0.9119, 0.2966], device='cuda:0')
data: tensor([[4.3100e+02, 2.1800e+02, 5.5000e+02, 4.9800e+02, 9.1195e-01, 0.0000e+00],[4.4000e+02, 1.8000e+02, 4.9300e+02, 2.6900e+02, 2.9657e-01, 0.0000e+00]], device='cuda:0')
id: None
is_track: False
orig_shape: (500, 727)
shape: torch.Size([2, 6])
xywh: tensor([[490.5000, 358.0000, 119.0000, 280.0000],[466.5000, 224.5000, 53.0000, 89.0000]], device='cuda:0')
xywhn: tensor([[0.6747, 0.7160, 0.1637, 0.5600],[0.6417, 0.4490, 0.0729, 0.1780]], device='cuda:0')
xyxy: tensor([[431., 218., 550., 498.],[440., 180., 493., 269.]], device='cuda:0')
xyxyn: tensor([[0.5928, 0.4360, 0.7565, 0.9960],[0.6052, 0.3600, 0.6781, 0.5380]], device='cuda:0')Process finished with exit code 0
keypoints输出示意
conf: tensor([[0.1623, 0.0385, 0.0703, 0.4830, 0.6888, 0.9871, 0.9915, 0.9602, 0.9762, 0.9018, 0.9322, 0.9988, 0.9990, 0.9975, 0.9980, 0.9871, 0.9890],[0.9038, 0.8243, 0.8706, 0.5569, 0.6885, 0.9573, 0.9722, 0.7333, 0.8560, 0.6121, 0.7367, 0.8585, 0.8884, 0.4269, 0.4872, 0.1876, 0.2166]], device='cuda:0')
data: tensor([[[0.0000e+00, 0.0000e+00, 1.6227e-01],[0.0000e+00, 0.0000e+00, 3.8458e-02],......,[0.0000e+00, 0.0000e+00, 4.8720e-01],[0.0000e+00, 0.0000e+00, 1.8759e-01],[0.0000e+00, 0.0000e+00, 2.1661e-01]]], device='cuda:0')
has_visible: True
orig_shape: (500, 727)
shape: torch.Size([2, 17, 3])
xy: tensor([[[ 0.0000, 0.0000],[ 0.0000, 0.0000],[ 0.0000, 0.0000],......,[ 0.0000, 0.0000],[ 0.0000, 0.0000]]], device='cuda:0')
xyn: tensor([[[0.0000, 0.0000],[0.0000, 0.0000],[0.0000, 0.0000],......,[0.0000, 0.0000],[0.0000, 0.0000]]], device='cuda:0')
这些参数是深度学习模型YOLOv8-pose分析图像后的输出结果,每个参数的含义如下:
cls:类别索引,指示检测对象的类别。conf:置信度,表示模型对其检测结果的置信程度。data:检测到的对象的详细数据,包括位置坐标和置信度。id:如果进行对象跟踪,则是对象的唯一标识符。is_track:是否启用了对象跟踪功能。orig_shape:原始图像的尺寸。shape:返回结果的形状。xywh:边界框的中心坐标和尺寸。xywhn:归一化的边界框中心坐标和尺寸。xyxy:边界框的左上角和右下角坐标。xyxyn:归一化的边界框左上角和右下角坐标。Keypoints对象:包含人体姿态关键点的置信度和坐标数据。has_visible:指示关键点是否可见。orig_shape:原始图像的尺寸。xy:关键点的(x, y)坐标。xyn:关键点坐标的归一化版本。
预测参数说明
| 名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
source | str | 'ultralytics/assets' | 图像或视频的源目录 |
conf | float | 0.25 | 检测对象的置信度阈值 |
iou | float | 0.7 | 用于NMS的交并比(IoU)阈值 |
imgsz | int or tuple | 640 | 图像大小,可以是标量或(h, w)列表,例如(640, 480) |
half | bool | False | 使用半精度(FP16) |
device | None or str | None | 运行设备,例如 cuda device=0/1/2/3 或 device=cpu |
show | bool | False | 如果可能,显示结果 |
save | bool | False | 保存带有结果的图像 |
save_txt | bool | False | 将结果保存为.txt文件 |
save_conf | bool | False | 保存带有置信度分数的结果 |
save_crop | bool | False | 保存带有结果的裁剪图像 |
show_labels | bool | True | 隐藏标签 |
show_conf | bool | True | 隐藏置信度分数 |
max_det | int | 300 | 每张图像的最大检测数量 |
vid_stride | bool | False | 视频帧速率跳跃 |
stream_buffer | bool | False | 缓冲所有流媒体帧(True)或返回最新帧(False) |
line_width | None or int | None | 边框线宽度。如果为None,则按图像大小缩放。 |
visualize | bool | False | 可视化模型特征 |
augment | bool | False | 应用图像增强到预测源 |
agnostic_nms | bool | False | 类别不敏感的NMS |
retina_masks | bool | False | 使用高分辨率分割掩码 |
classes | None or list | None | 按类别过滤结果,例如 classes=0,或 classes=[0,2,3] |
boxes | bool | True | 在分割预测中显示框 |
总结
本篇博客详细介绍了使用YOLOv8-pose进行姿态估计的全过程,包括不同版本模型的性能比较、训练与验证步骤,以及预测代码的实现。它对模型参数、训练过程和输出结果进行了解释,同时提供了详细的配置文件示例和标签数据格式说明。此外,还演示了如何使用预训练模型进行图像预测,并如何处理和理解预测结果。最后,它还讨论了如何评估和比较不同模型的性能。如果有哪里写的不够清晰,小伙伴本可以给评论或者留言,我这边会尽快的优化博文内容,另外如有需要,我这边可支持技术答疑与支持。




![[Angular] 笔记 20:NgContent](https://img-blog.csdnimg.cn/direct/87f629ff002d4a09b2e76c17f78fdf5c.png)