一、交叉编译
1.1 编译原理
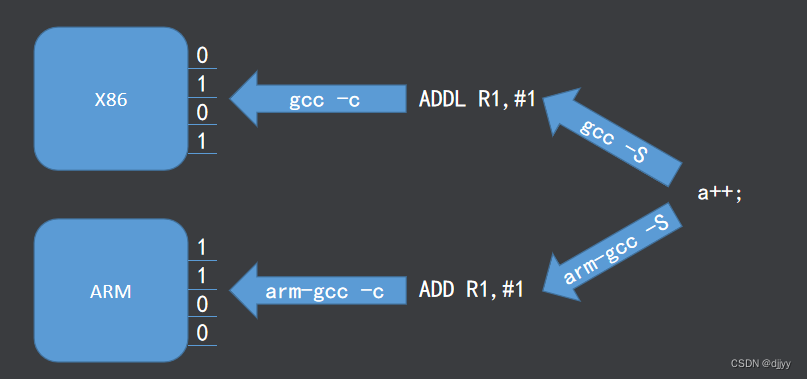
机器码(二进制)是处理器能直接识别的语言,不同的机器码代表不同的运算指令,处理器能够识别哪些机器码是由处理器的硬件设计所决定的,不同的处理器机器码不同,所以机器码不可移植
汇编语言是机器码的符号化,即汇编就是用一个符号来代替一条机器码,所以不同的处理器汇编也不一样,即汇编语言也不可移植
C语言在编译时我们可以使用不同的编译器将C源码编译成不同架构处理器的汇编,所以C语言可以移植
1.2 编译过程

1.3 交叉编译
交叉编译:程序的编译和运行不在同一台机器上

1.4 交叉编译工具链
交叉编译工具链的获取:
1) 官网获取(不推荐,需要自己进行复杂配置与编译)
http://ftp.gnu.org/gnu/gcc/
2) BSP板级开发支持包(推荐)
samsung、全志...
交叉编译工具链的内容:
1) 交叉编译工具
gcc/readelf/size/nm/strip/objcopy/objdump/addr2line
2) 库
ARM架构的库
二、ELF文件格式
2.1ELF
ELF格式是Linux平台上应用最广泛的二进制工业标准之一
ELF格式的文件内包含了很多个段不同的段存储了不同的信息;因为ELF格式的文件要通过Linux系统的加载和管理才能运行,所以除了最基本的代码段和数据段之外,其中还存储了很多其它的信息,如符号表、调试信息等

2.2 ELF文件相关命令
file
file + 文件名 //查看文件的详细信息
readelf
readelf -h + 文件名 //列出elf文件的头部信息
readelf -a + 文件名 //列出elf文件的所有信息
2.3 BIN文件格式
BIN
BIN文件一般是直接运行在CPU之上 的可执行文件,文件内只包含了CPU能够直接识别和运行的指令和数据,不包含其它系统相关的信息
三、交叉编译工具链常用工具
交叉编译工具链的bin目录下是交叉编译工具链提供给我们的一些工具
size //列出目标文件每一段的大小以及总体的大小
size + 文件名

用size命令查看的文件大小和用ll命令的不一样,因为size的大小只包含能在cpu运行的内容,而ll是全部。


nm //列出目标文件中的符号表(标示符)
nm + 文件名
例如函数名就会放在符号表中

strip //丢弃目标文件中的符号
strip + 文件名
注:对于嵌入式开发,这个命令很重要
符号表对文件的执行没有太大意义,所以把符号表删了,不会影响程序的运行,还能节省空间。

可以用file命令查看文件是否瘦身

符号表的作用:如果我们不知道库中有什么函数,可以通过nm命苦查看到符号表中的函数名。

objdump //从目标文件中显示信息
eg:
objdump -d + 文件名 将目标文件反汇编(机器码->汇编)
objcopy //对目标文件进行复制和转换
eg:
objcopy --gap-fill=0xff -O binary a.out a.bin
将目标文件转换为bin格式
通过gcc编译器编译出来的代码,默认就是elf,但elf文件是运行在Linux系统之上的。没有Linux系统时,就不能用elf,只能用bin(比如uboot和ARM裸机)。此时,就可以用objcopy命令进行转换。