文章目录
- 零、学习目标
- 一、导言
- 二、内部表
- 1.1 什么是内部表
- 1.1.1 内部表的定义
- 1.1.2 内部表的关键特性
- 1.2 创建与操作内部表
- 1.2.1 创建并查看数据库
- 1.2.2 创建数据表
- 1.2.3 插入表记录
- 1.2.4 通过HDFS WebUI查看数据库与表
- 三、外部表
- 2.1 什么是外部表
- 2.2 创建与操作外部表
- 2.2.1 在虚拟机上建文本文件
- 2.2.2 上传文件到HDFS指定目录
- 2.2.3 基于HDFS目录创建外部表
- 2.2.4 查询外部表记录
- 2.2.5 在MySQL里查看hive元数据信息
- 四、内部表与外部表的区别
- 3.1 区别体现在删除表
- 3.2 通过实验进行验证
- 3.2.1 删除内部表
- 3.2.2 删除外部表
- 3.2.3 查看MySQL里hive元数据
- 五、总结与展望
零、学习目标
- 理解并掌握Apache Hive内部表和外部表的定义、核心特性和应用场景。
- 掌握在Hive中创建、查询、插入数据以及删除内部表的具体操作步骤,理解其数据生命周期管理机制及对Hive系统的依赖性。
- 学会如何基于已存在的HDFS数据创建Hive外部表,并了解其在数据安全性、跨平台共享方面的优势,以及在删除外部表时元数据与实际数据的区别处理方式。
- 通过实践操作对比内部表与外部表在删除后的不同效果,明确两者在数据持久性和访问控制上的差异。
- 根据业务需求和数据管理策略,学会灵活运用内部表和外部表来优化大数据处理流程,提高数据资产管理效率,并针对底层数据文件进行有效维护与管理。
一、导言
- Apache Hive作为大数据处理的重要工具,其内部表与外部表是两种核心的数据存储和管理机制。内部表由Hive全权管理,数据存储在HDFS特定目录下,删除时会连同元数据及HDFS数据一同删除;创建过程包括定义表结构、插入数据等步骤,并且完全依赖于Hive系统。而外部表则赋予用户更大的灵活性,它可以引用已存在于HDFS中的数据,仅在删除时移除元数据,保留实际数据,利于跨平台共享和防止意外删除。通过实际操作演示,我们深入理解了如何创建、查询和管理这两种表类型,并强调了它们在不同应用场景下的价值。在未来的大数据实践中,依据数据来源、持久性和安全性需求,灵活运用Hive内部表与外部表将有利于提升数据处理效能与保障数据资产安全。
二、内部表
1.1 什么是内部表
1.1.1 内部表的定义
- Hive内部表是Hive数据仓库中的一种表类型。当在Hive中创建一个内部表时,表的数据和元数据都由Hive进行管理。
1.1.2 内部表的关键特性
-
存储位置:Hive内部表的数据默认存储在Hadoop Distributed File System (HDFS) 中的一个指定目录下,这个目录由Hive自动管理。
-
元数据管理:Hive内部表的元数据(如表结构、分区信息等)存储在 Hive Metastore 中,这是一个集中式的服务,用于存储和管理所有Hive表的元数据。
-
数据生命周期:删除Hive内部表时,不仅会删除表的元数据,还会从HDFS中删除与该表相关联的实际数据文件。
-
独立性:由于Hive完全管理内部表的数据和元数据,因此这些表对Hive具有完全的依赖性。如果不再使用Hive,内部表的数据将无法直接通过其他方式访问。
-
表操作限制:对Hive内部表进行数据修改或移动等操作可能会受到限制,因为这些操作可能会影响Hive对数据的管理和追踪。
- 总的来说,Hive内部表是一种适合于数据仓库环境中长期存储和管理数据的表类型,它提供了方便的数据管理和查询功能,但同时也要求用户考虑其对数据持久性和访问方式的需求。
1.2 创建与操作内部表
1.2.1 创建并查看数据库
-
创建
park数据库,执行命令CREATE DATABASE park

-
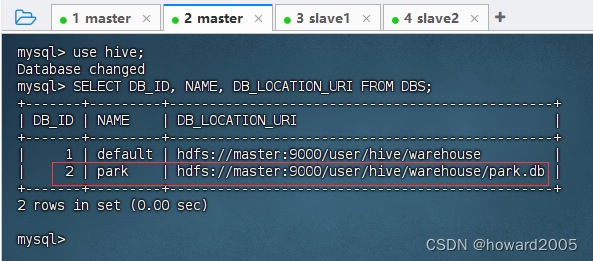
在MySQL里查看数据库信息
-
注意:数据库
park的DB_ID是2,后面我们会用到它。 -
在HDFS上查看
park数据库对应的目录/user/hive/warehouse/park.db

1.2.2 创建数据表
-
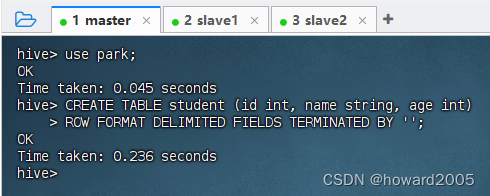
在数据库
park里里创建student内部表 -
切换到
park数据库后,执行语句:CREATE TABLE student (id int, name string, age int) ROW FORMAT DELIMITED FIELDS TERMINATED BY '';
-
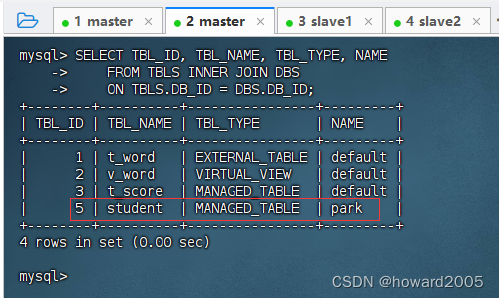
在MySQL查看表信息,执行语句:
SELECT TBL_ID, TBL_NAME, TBL_TYPE, NAME FROM TBLS INNER JOIN DBS ON TBLS.DB_ID = DBS.DB_ID;
1.2.3 插入表记录
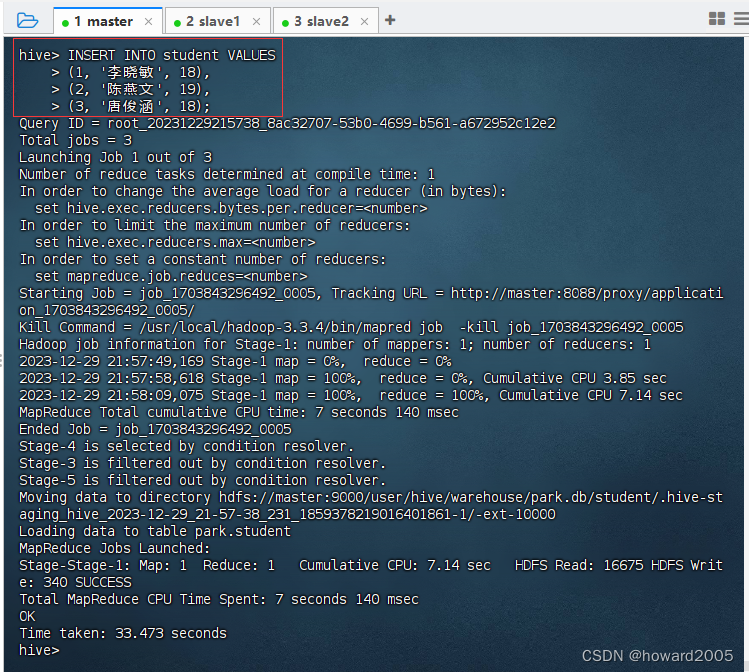
- 使用
INSERT INTO命令插入数据
INSERT INTO student VALUES(1, '李晓敏', 18),(2, '陈燕文', 19),(3, '唐俊涵', 18);
- 执行上述语句,插入3条记录
1.2.4 通过HDFS WebUI查看数据库与表
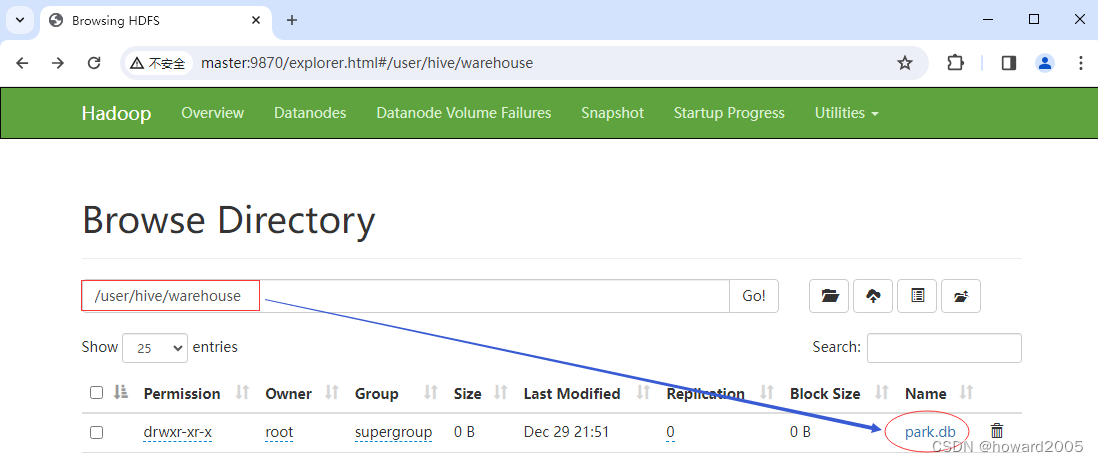
- 查看
park数据库在HDFS对应的目录
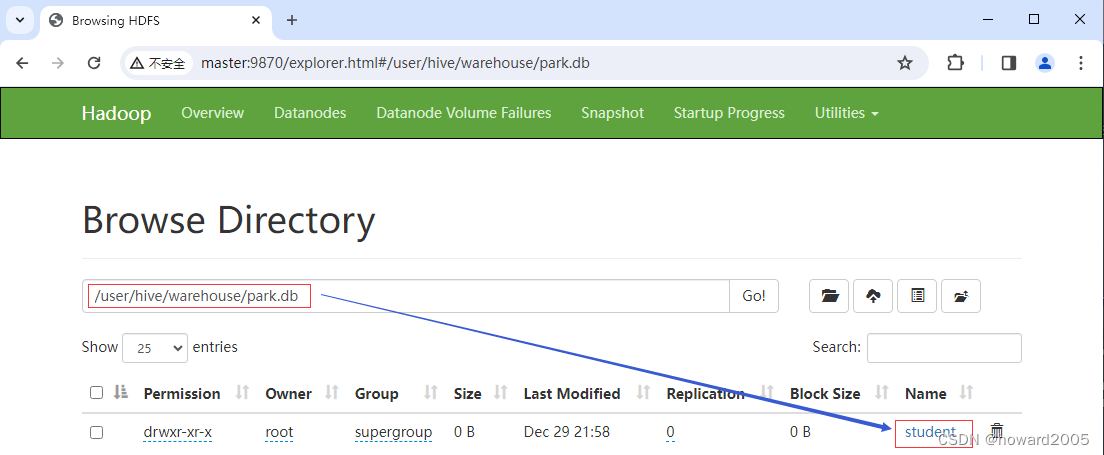
- 查看
student表在HDFS对应的目录
- 查看表记录在HDFS对应的文件
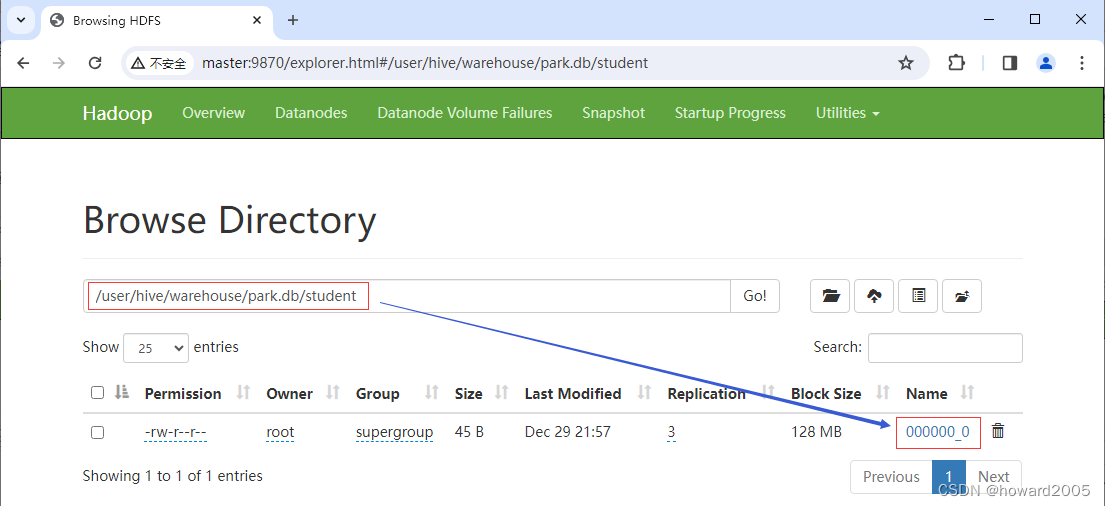
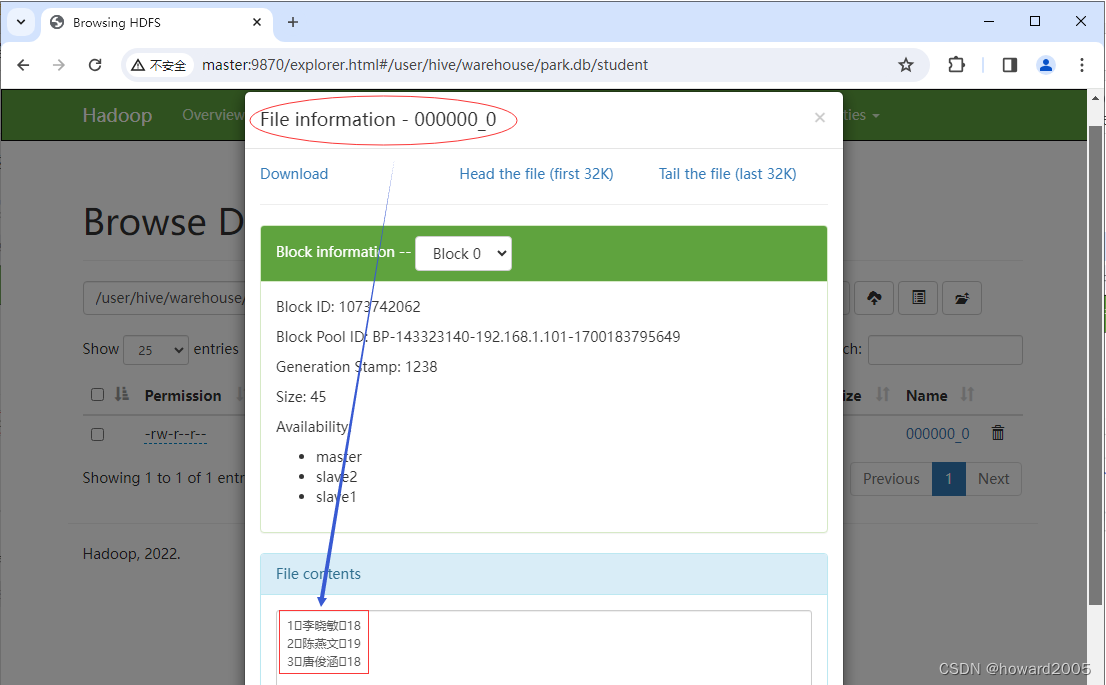
- 查看文件
000000_0的内容
三、外部表
2.1 什么是外部表
- Hive外部表是Apache Hive中的一种表类型,它允许用户将已经存在于Hadoop文件系统(如HDFS)中的数据作为Hive表进行查询和分析。与内部表不同的是,删除外部表时,Hive仅删除表的元数据信息,而不删除底层存储的数据文件,这样可以防止意外数据丢失,并支持跨多个表或服务共享数据源。在大数据处理场景下,Hive外部表为用户提供了一种灵活、安全的数据管理方式。
2.2 创建与操作外部表
2.2.1 在虚拟机上建文本文件
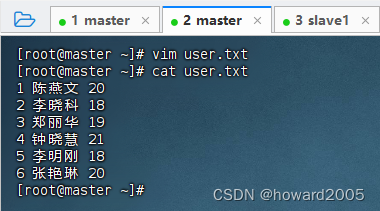
- 在master虚拟机上创建
user.txt文件
2.2.2 上传文件到HDFS指定目录
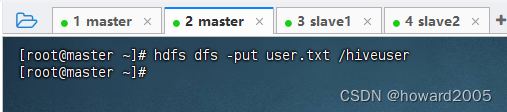
- 在HDFS上创建
hiveuser目录

- 将文件
user.txt上传到HDFS的/hiveuser目录
2.2.3 基于HDFS目录创建外部表
- 使用
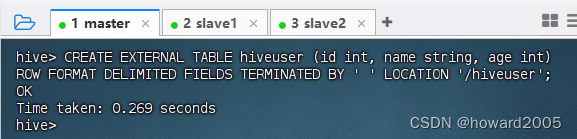
CREATE EXTERNAL TABLE命令创建外部表。 - 基于HDFS的
/hiveuser目录创建外部表hiveuser,执行语句:CREATE EXTERNAL TABLE hiveuser (id int, name string, age int) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' LOCATION '/hiveuser';
2.2.4 查询外部表记录
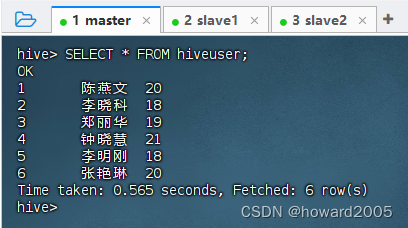
- 查询外部表
hiveuser全部记录
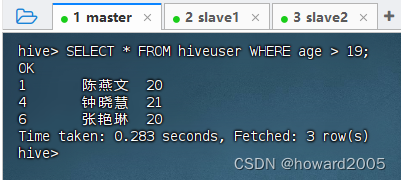
- 查询
19岁以上的记录
2.2.5 在MySQL里查看hive元数据信息
- 查看
park数据库里表的信息(注意:park数据库的DB_ID是2)。
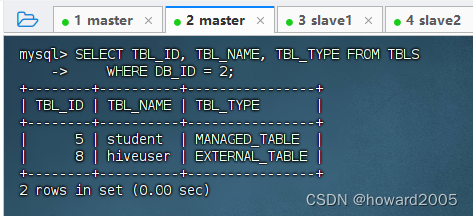
- 内部表:
MANAGED_TABLE - 外部表:
EXTERNAL_TABLE
四、内部表与外部表的区别
3.1 区别体现在删除表
- 内部表删除时连同HDFS数据一并移除;外部表删除仅剔除元信息,保留HDFS实际数据。
3.2 通过实验进行验证
3.2.1 删除内部表
- 删除内部表
student,执行语句:DROP TABLE student;
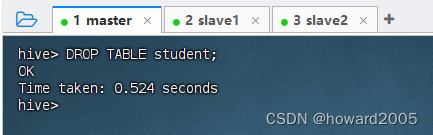
- 查看
student表对应的目录/user/hive/warehouse/park.db/student是否还存在

3.2.2 删除外部表
- 删除外部表
hiveuser,执行语句:DROP TABLE hivesuer;
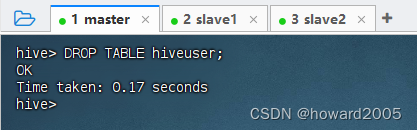
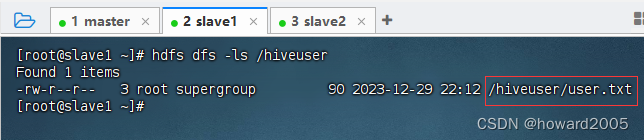
- 查看
hiveuser表对应的目录/hiveuser是否还存在
3.2.3 查看MySQL里hive元数据
- 查看数据库
park(其DB_ID是2)里是否还有表记录
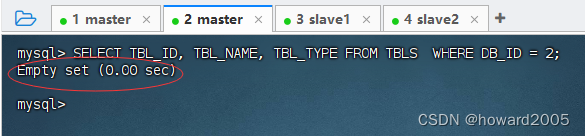
- 说明删除了内部表和外部表,其元数据信息都会被删除。
五、总结与展望
-
总结来说,内部表是Hive的默认表类型,其数据存储在Hive管理的目录下,当删除内部表时,相关HDFS上的数据也会被一并清除。创建和管理内部表的过程包括建表、加载数据以及进行DML操作等步骤。
-
外部表则为用户提供了更为灵活的数据管理方式,它指向HDFS上已存在的数据目录,删除外部表时仅移除元数据信息而不影响实际数据。在实际应用中,如需与其他系统共享数据源或避免误删重要数据,通常会选用外部表。展望未来使用场景,对于持续接入的外部数据源或需要长期保留的历史数据,合理运用Hive外部表将有助于提高数据处理效率与安全性,但同时需要注意对底层数据文件的维护与管理,防止由于表定义缺失导致的数据无法访问等问题。