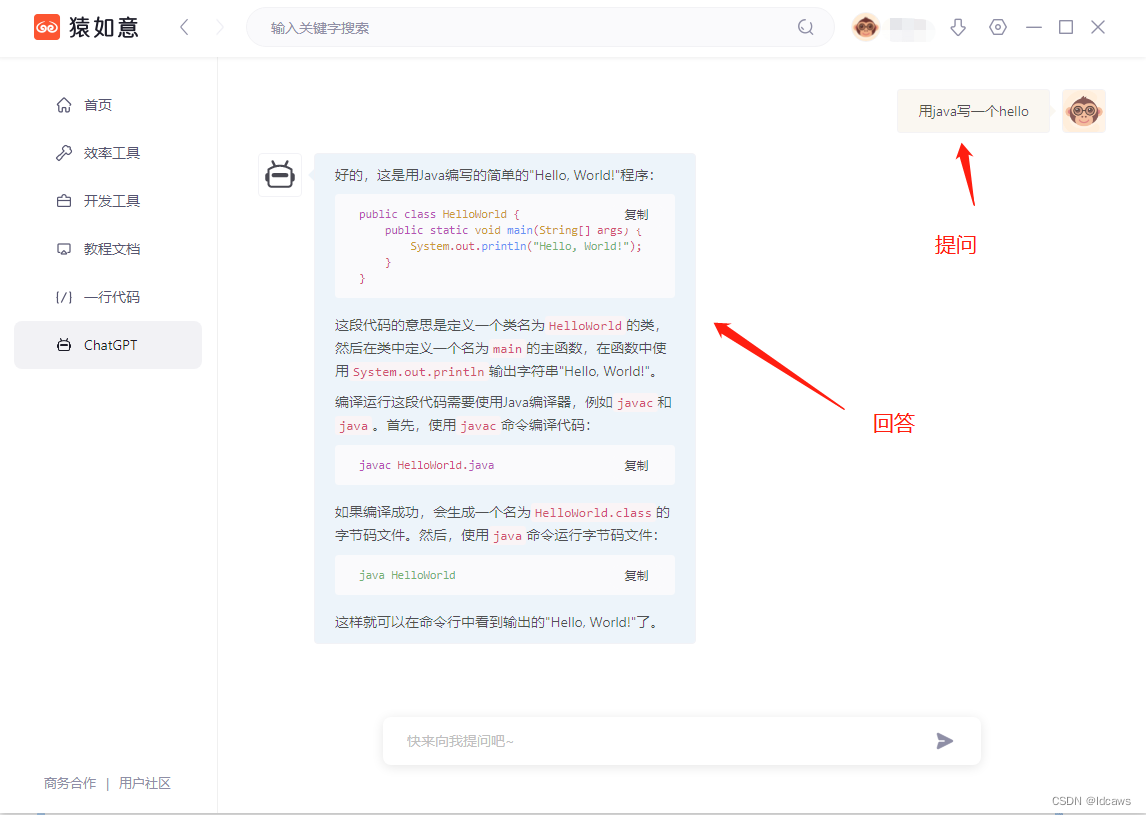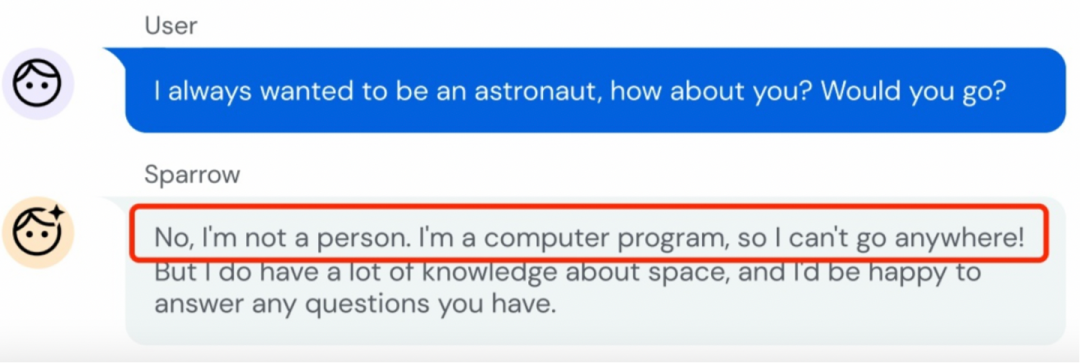
文 | 郑楚杰@知乎
编者记:近日来,ChatGPT的连续刷屏让人们重新看到了AI的希望,编者通过对ChatGPT的试用,发现其对话能力早已不同于两年前的对话系统了,可以说,有了质的飞跃,向着用户体验奇点迈进了一大步。本文就来跟随一位对话领域的大佬,一起了解下对话领域这两年是如何演变至今日的起飞的!
我是从 19 年开始做对话研究的。
根据我的感受,在 21 年之前,对话这块的风向一直是 Meta AI / FAIR 引领的,例如:人格化 (18)、知识性 (19)、共情性 (19)、一致性 (19)、安全性 (19)、反馈/终身学习 (19)、跨模态 (20)、长时记忆 (21)。
值得一提的是,他们一直在开源所收集的数据、所训练的模型。
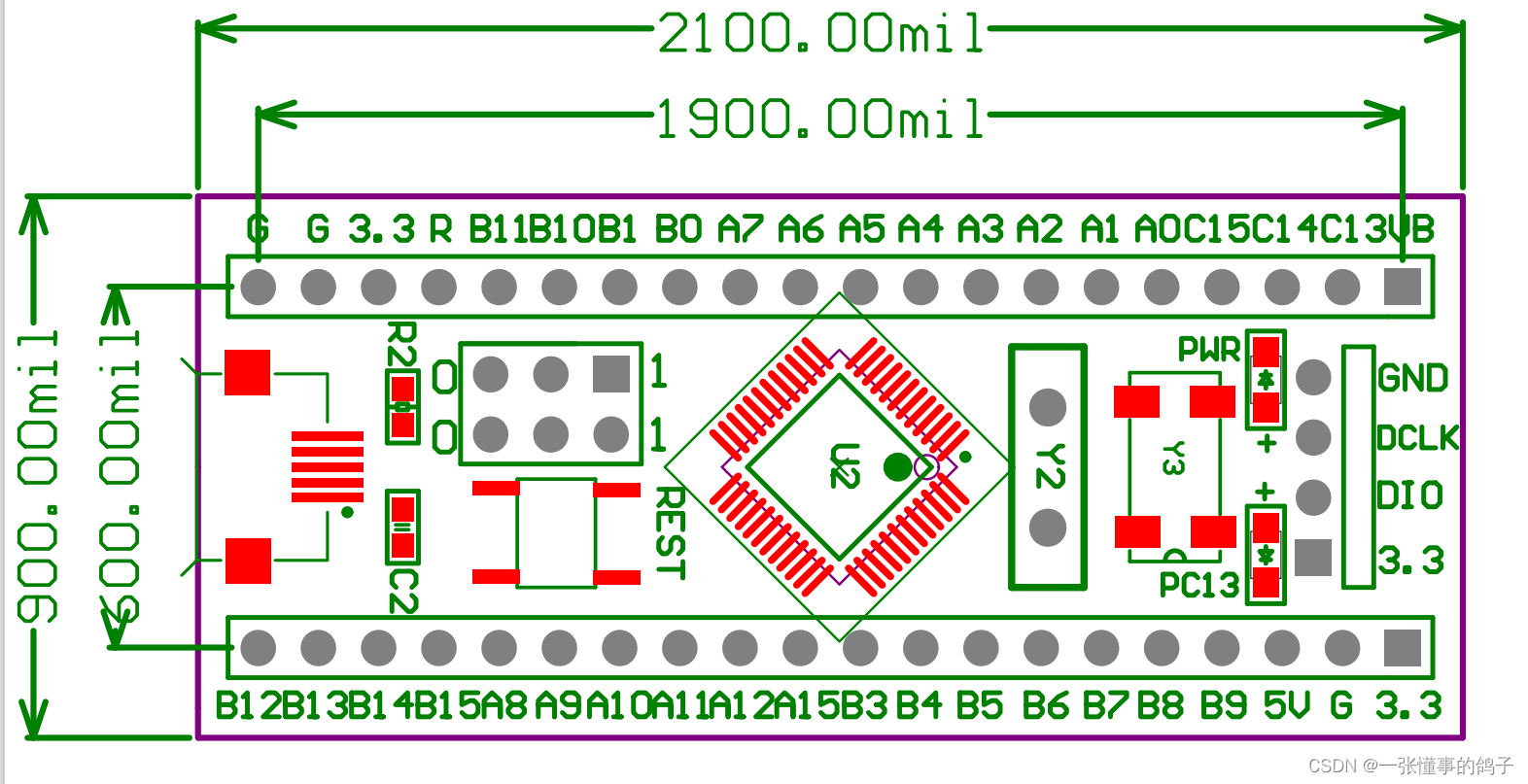
从上面罗列的也可以看出,过去做对话的思路是从局部到整体,各个击破再加以整合。从今年 Meta AI 发布的 BlenderBot 3 和 CICERO 也能看出这一思路的影子
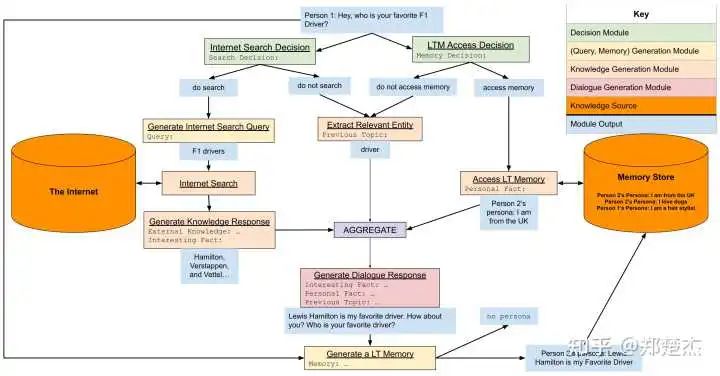
BlenderBot 3 流程图,模块化搞起来
从今年(22年)开始,Google 的 LaMDA、DeepMind 的 Sparrow、OpenAI 的 InstructGPT 和 ChatGPT,其实换了不一样的思路:局部过于琐碎,直接一把梭。
与其由开发者为各个模块/技能点制定规范,不如由用户方给出指导和信号,这样训出来的模型更与用户需求 aligned。
甚至开发者都无需再了解「对话」这一场景的本质内涵(如前述的对话一致性),大力出奇迹但需要承认的是,这种粗粒度搞对话系统的方式需要基础模型足够强大,就像 ChatGPT 的基础模型 InstructGPT 在此前已经是地表最强了一方面,基础模型的能力是 ChatGPT 整套流程得以 work 的前提。
以 Meta AI 的 OPT 模型为例,虽然达到了与 GPT-3 同等的 175B 参数量,但生成能力仍然差很多,即使它用了 ChatGPT 的 demonstration data 训练,训出来的 policy 也不具备足够的泛化能力另一方面,很多文本生成的长尾/基础问题,如对话一致性、文本生成的连贯性和重复性等,会在高质量的预训练数据和 scaling 的作用下神奇地得到极大缓解。
这使得开发者无需再关注以往研究中的这些颇为头疼但又难以解决的问题,而只需要关注任务本身即可换句话说,其他的开发者即使有了 ChatGPT 的训练数据,也很难训出 ChatGPT 这样的效果,因为它们所立足的巨人的肩膀已经有着难以弥补的鸿沟了。
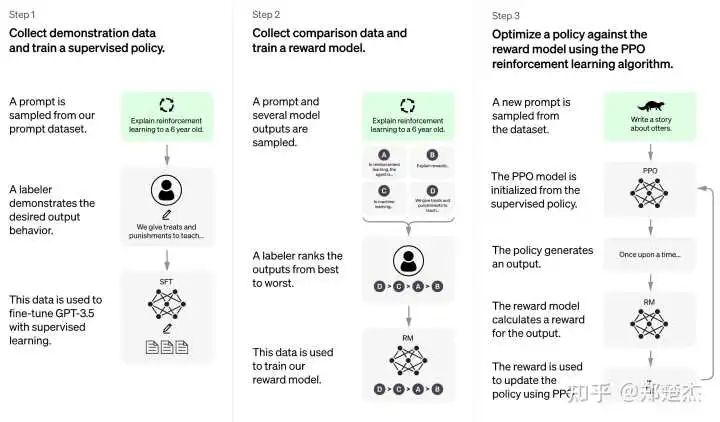
直接让用户示范「应该怎么做」、指导「怎么做更好」
另外,与 Meta AI(以及我组)不同的是,这些项目对对话系统的定位是功能性的 AI assistant,这抛弃了过去所突出的 human-like 或 personality,因此显然带有更原始的任务型对话系统的特征。
确切地说,它们是开放领域的任务型对话系统(不限任务范畴、任意输入形式),而非拟人化的闲聊机器人。
事实上,过于强调人格化也带来了许多安全隐患和伦理风险,侧重于功能性则带来更高的实用性。至于哪条道路才是未来,可能就见仁见智了。

DeepMind Sparrow 拒绝回答与人格相关的问题
当然,标数据必然花费了相当多的人力和财力(估计他们的标注质量比 Meta AI 一直采用的 AMT 标注要高得多),训大模型也需要庞大的算力。
这些项目的成功充分证明了钞能力的力量,作为护城河的数据更是不会开源了今年最大的感受是,通用领域的玩家下场搞垂直赛道真的是降维打击。
这也反映了以往对话领域的困境:令对话系统取得飞跃式进展的技术几乎都来自通用领域(大规模预训练、检索增强等),想搞真正有用的创新只能从数据层面入手。
当数据的优势也失去后,便难有招架之力了想到了 Jason Wei 大佬前阵子说的这段话(原 tweet 似乎被删了,可以辩证地看他的观点),做大模型能够带来很多全新的视角,就像 GPT-3、PaLM 已经是与 BERT、GPT-2 迥然不同的物种,就像 OpenAI 采用与过去不同的角度做了 ChatGPT。反倒是入场早的老玩家容易思路闭塞和脱节(敲响警钟)。


最后感慨一下,作为和 n+e 大哥同届本科的菜鸡,n 大哥已经开始改变世界了,而我还在挣扎于发论文毕业 :)
后台回复关键词【入群】
加入卖萌屋NLP、CV、搜广推与求职讨论群