【PostgreSQL】在DBeaver中实现序列、函数、触发器、视图设计
- 基本配置
- 一、序列
- 1.1、序列使用
- 1.1.1、设置字段为主键,数据类型默认整型
- 1.1.2、自定义序列,数据类型自定义
- 1.2、序列延申
- 1.2.1、理论
- 1.2.2、测试
- 1.2.3、小结
- 二、函数
- 2.1、SQL直接创建
- 2.1.1、理论
- 2.1.2、测试
- 2.2、借用DBeaver创建
- 三、视图
- 3.1、SQL语句
- 3.2、示例
- 四、触发器
- 4.1、SQL语句
- 4.1.1、触发器函数
- 4.1.2、函数与表关联
- 4.2、示例
基本配置
数据库管理工具:DBeaver23.2.3
PostgreSQL 14.6
测试数据库在博文中已经资源绑定分享
一、序列
1.1、序列使用
在MySQL数据库中,实现主键自增,只需要设置字段为主键即可,但在Pg数据库中却有所不同。
实现的途径主要有2种:
1.1.1、设置字段为主键,数据类型默认整型
此时字段默认为serial4,即自增 4 字节整数,范围1 到 2147483647。以表employees_history为例,主键字段id默认值为nextval(‘employees_history_id_seq’::regclass),同时会自动添加序列employees_history_id_seq。
函数 nextval(regclass) 返回类型bigint,描述如下:
递增序列对象到它的下一个数值并且返回该值。这个动作是自动完成的。即使多个会话并发运行nextval,每个进程也会安全地收到一个唯一的序列值。
1.1.2、自定义序列,数据类型自定义
当主键数据类型不是整型时,使用序列自增主要采用该种方法。
首先,用SQL语句创建testseq_d_seq序列:
CREATE SEQUENCE public.testseq_d_seqINCREMENT BY 1MINVALUE 1MAXVALUE 2147483647START 1CACHE 1NO CYCLE;
为方便起见,也可在DBeaver数据库的序列中右键新建序列,在完成序列命名后,完成序列的创建。
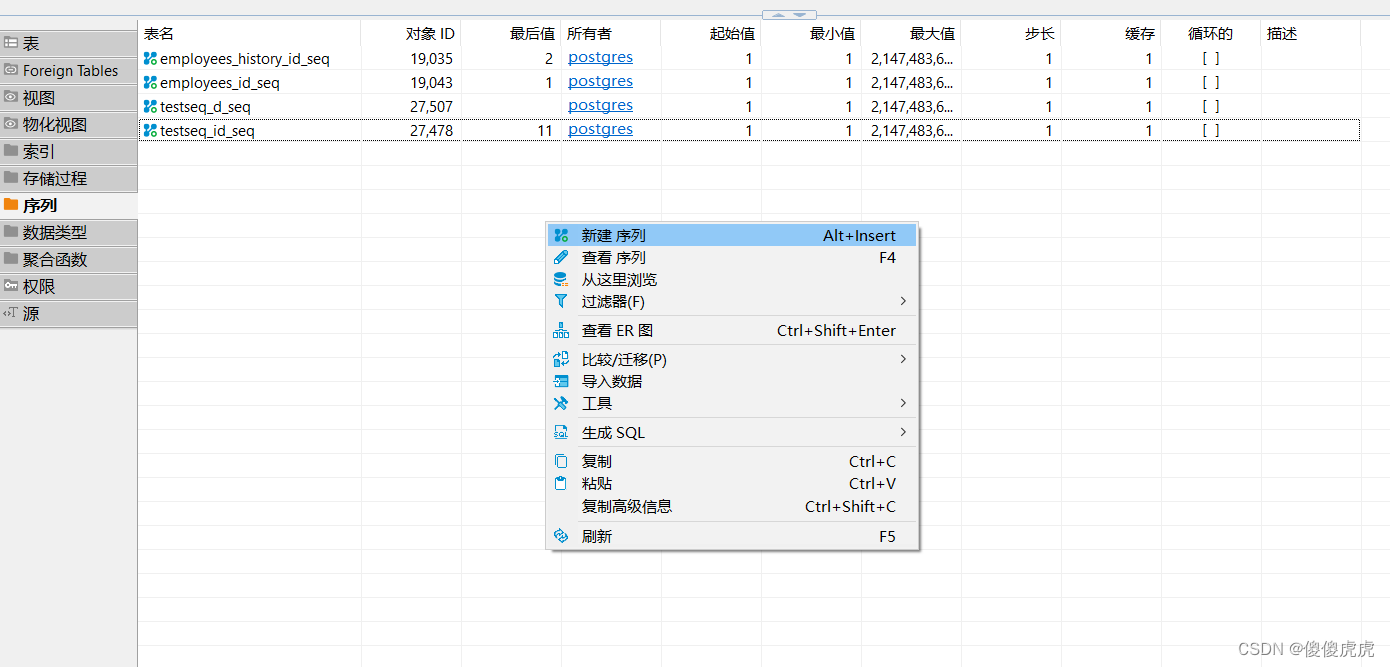
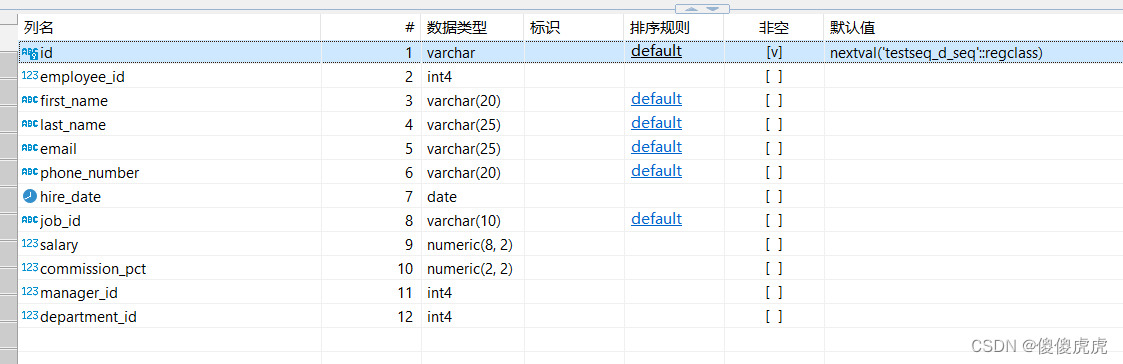
其次,根据需要将主键字段设置成所需数据类型,并与创建的序列绑定,设置默认值。
nextval('testseq_d_seq'::regclass)
1.2、序列延申
在内容的存储过程,有时候会遇到预处理数据后再存储的情况,本节以实现‘A-%’格式存储为例,即所有存储的主键字段必须以A-开头,展开介绍。
1.2.1、理论
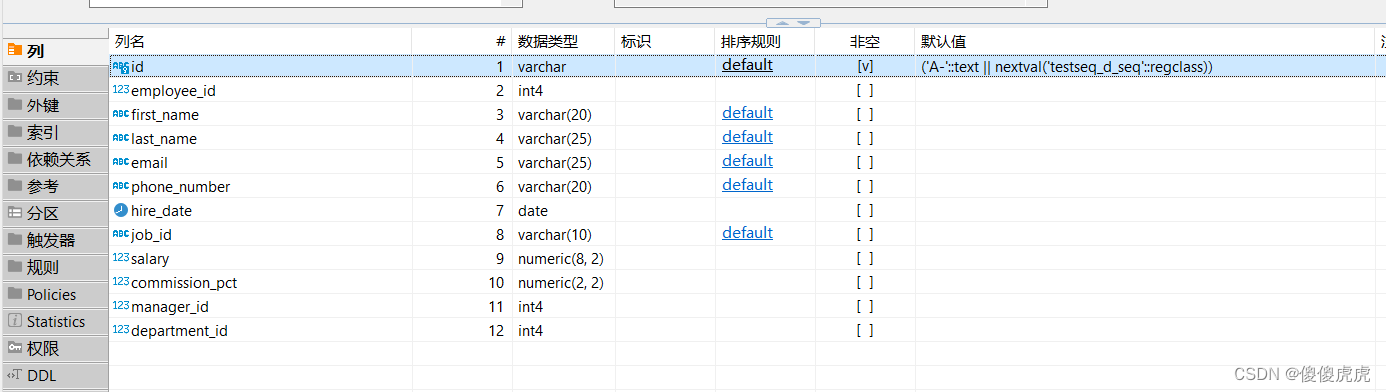
在展开介绍前,首先查看了一些资料,以PostgreSQL 字符串函数汇总为主,该大神的博文中清晰的罗列了基本的字符串函数,因此本文就不再进行重复论述。根据需求,我们从中选取合适的函数开展数据预处理,设置主键默认值如下:
('A-'::text || nextval('testseq_d_seq'::regclass))
1.2.2、测试
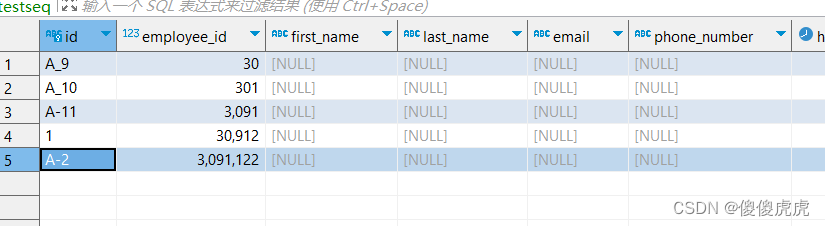
通过输入SQL插入记录进行测试,最终输出的记录主键字段为‘A-2’,实现需求。
INSERT INTO public.testseq
(employee_id, first_name, last_name, email, phone_number, hire_date, job_id, salary, commission_pct, manager_id, department_id)
VALUES(3091122, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL)
1.2.3、小结
在本小节中,我们以一个简单的示例介绍了数据库的数据预处理存储,后续大家也可以根据需要在数据库中自定义的使用函数进行需求实现,提高开发效率。当然,由于提供函数有限,针对较为复杂的预处理,依旧还是采用后端处理后再存储到数据库中。
二、函数
在PostgreSQL 数据库中自定义一些函数,可以有效帮助我们提高开发效率。本章主要介绍函数创建的2种方式:
2.1、SQL直接创建
2.1.1、理论
采用SQL创建属于万能的方式,基本的语句结构如下:
CREATE FUNCTION function_name(parameter1 datatype1, parameter2 datatype2, OUT output_parameter datatype)
RETURNS return_type AS $$
-- 函数体
$$ LANGUAGE language_name;
function_name函数名parameter传参datatype参数类型output_parameter输出参数return_type函数返回类型language_name编程语言
为方便函数内容的更新,同时也避免由于相同函数命名存在导致执行报错的发生,增加OR REPLACE优化后的语句结构如下:
CREATE OR REPLACE FUNCTION function_name(parameter1 datatype1, parameter2 datatype2, OUT output_parameter datatype)
RETURNS return_type AS $$
-- 函数体
$$ LANGUAGE language_name;
2.1.2、测试
用SQL创建函数,需求如下:
- 可传不定长字符串、整型;
- 可更新时间;
- 可选传参数。
编写的SQL语句如下所示,其中character varying为不定长字符串数据类型:
CREATE OR REPLACE FUNCTION public.test_han(_employee_id integer, _last_name character varying, _salary integer DEFAULT 10, _job_id character varying DEFAULT NULL, OUT _id character varying)RETURNS character varying AS $$BEGININSERT INTO testseq (employee_id,last_name,hire_date,job_id,salary)VALUES(_employee_id,_last_name,now( ),_job_id,_salary) RETURNING id INTO _id;
END;
$$ LANGUAGE plpgsql
在DBeaver运行后,最终函数显示的源如下所示:
CREATE OR REPLACE FUNCTION public.test_han(_employee_id integer, _last_name character varying, _salary integer DEFAULT 10, _job_id character varying DEFAULT NULL::character varying, OUT _id character varying)RETURNS character varyingLANGUAGE plpgsql
AS $function$BEGININSERT INTO testseq (employee_id,last_name,hire_date,job_id,salary)VALUES(_employee_id,_last_name,now( ),_job_id,_salary) RETURNING id INTO _id;
END;
$function$
;
两个SQL语句都可以正常运行。用语句select test_han(12,'test')进行函数调用,最终完成记录的插入,同时返回参数如下:
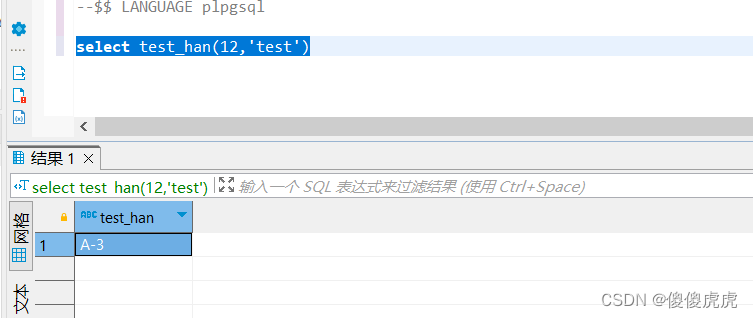
2.2、借用DBeaver创建
该方法本质依旧是执行SQL语句,只不过不需要进行函数创建的SQL语句编写,更关注于函数体的业务需求实现。
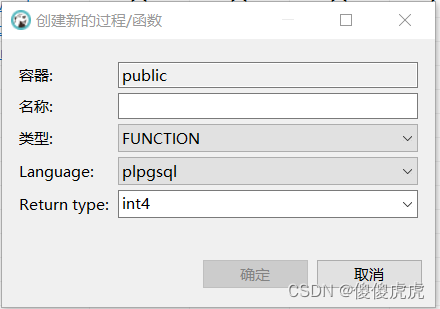
首先,将DBeaver切到public-存储过程,然后右键 新建 存储过程 ,填写函数名称、语言类型、返回参数类型,完成函数架构的搭建。
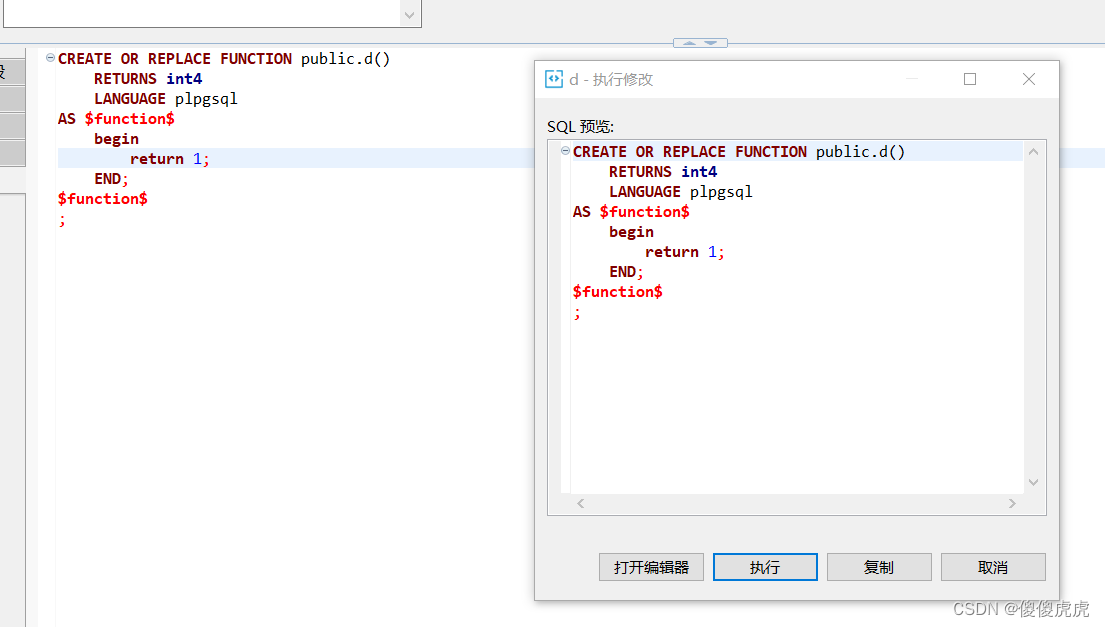
然后,在架构中编写函数体与传参。最后,快捷键Ctrl+S保存,点击执行,完成函数创建。
三、视图
视图是一张假表,只不过是通过相关的名称存储在数据库中的一个 PostgreSQL语句。而且视图是只读的,因此可能无法在视图上执行DELETE、INSERT 或UPDATE语句。但是可以在视图上创建一个触发器,当尝试 DELETE、INSERT 或 UPDATE 视图时触发,需要做的动作在触发器内容中定义。
3.1、SQL语句
创建视图的SQL语句结构如下所示,注意以 ; 结尾:
CREATE VIEW view_name AS
--SELECT语句
view_name视图名
同样的,为了方便更新视图,避免出现存在同命名导致SQL执行失败情况的出现,采用OR REPLACE优化SQL语句,优化后的结构如下:
CREATE OR REPLACE VIEW view_name AS
--SELECT语句
3.2、示例
获取表employees中数据创建视图,SQL语句如下:
CREATE OR REPLACE VIEW asd as select * from employees e
四、触发器
PostgreSQL支持两种级别的触发方式:行级(row-level)触发器和 语句级(statement-level)触发器,区别在于触发的时机和触发次数。例如,对于一个影响 20 行数据的 UPDATE 语句,行级触发器将会触发器 20 次,而语句级触发器只会触发 1 次。
4.1、SQL语句
创建触发器一共2步,首先用CREATE [OR REPLACE] FUNCTION创建触发器函数,其次用create trigger将触发器函数与表关联起来,从而完成创建。
4.1.1、触发器函数
基本的触发器函数SQL结构如下所示:
CREATE [ OR REPLACE ] FUNCTION trigger_function()
RETURNS trigger AS $$
-- 函数体
$$ LANGUAGE language_name;
触发器函数与普通函数创建类似,区别在于触发器函数没有传参,而且返回类型是trigger 。同时,在触发器函数的内部,系统自动封装了许多特殊的变量,这个在大神postgresql-触发器的博文中有清晰的罗列,这边就不进行重复的讲述,主要记录一些常用的:
- NEW ,类型为 RECORD,代表了行级触发器 INSERT、UPDATE 操作之后的新数据行。对于 DELETE 操作或者语句级触发器而言,该变量为 null。
- OLD,类型为 RECORD,代表了行级触发器 UPDATE、DELETE 操作之前的旧数据行。对于 INSERT 操作或者语句级触发器而言,该变量为 null。
- TG_OP,触发的操作,INSERT、UPDATE、DELETE 或者 TRUNCATE。
4.1.2、函数与表关联
基本的关联SQL语句结构如下:
-- 使用 CREATE TRIGGER 语句创建一个触发器,语法如下:
CREATE TRIGGER trigger_name
{BEFORE | AFTER | INSTEAD OF} {event [OR ...]}ON table_name[FOR [EACH] {ROW | STATEMENT}][WHEN ( condition ) ]EXECUTE FUNCTION trigger_function;
- event 可以是在所提到的表table_name上的INSERT、UPDATE、DELETE、TRUNCATE操作,而且UPDATE 支持在表的一个或多个指定列上操作(UPDATE OF col1, clo2)。
- 触发器可以在事件之前(BEFORE)或者之后(AFTER)
触发,INSTEAD OF 只能用于替代视图上的 INSERT、UPDATE 或者 DELETE 操作。 - FOR EACH ROW 表示行级触发器,FOR EACH STATEMENT 表示语句级触发器。
- WHEN 用于指定一个额外的触发条件,满足条件才会真正支持触发器函数。
DROP 可以删除整个表,包括表结构和数据,速度最快;
TRUNCATE 可以快速地删除表中的所有数据,但不删除表结构,速度中等;
DELETE 可以删除表中的数据,不包括表结构,速度最慢。
4.2、示例
需求:实现当对表employees进行insert、delete、update时,进行历史记录保存,保存到employees_history。
首先,创建触发器函数,SQL语句如下:
CREATE OR REPLACE FUNCTION public.track_emp_change()RETURNS triggerLANGUAGE plpgsql
AS $function$
begin -- tg_op 触发的操作 if tg_op = 'INSERT' theninsert into public.employees_history(employee_id, action_type, change_dt)values(new.employee_id,'INSERT',now());elsif tg_op = 'UPDATE' theninsert into public.employees_history(employee_id, action_type, change_dt)values(old.employee_id, 'UPDATE',now());elsif tg_op = 'DELETE' theninsert into public.employees_history(employee_id, action_type, change_dt)values(old.employee_id,'DELETE',now());end if;return new;
end ;
$function$
;
其次,创建表与函数的关联,SQL语句如下:
create trigger trg_employees_change before
insertor
deleteor
updateonpublic.employees for each row execute function track_emp_change()
最终,通过INSERT INTO public.employees(id, department_id, "time")VALUES(2390, 601, now())进行调用测试,完成需求实现。