前言
大家好,这里是白泽,我是21年8月接触的 Go 语言,学习 Go 也正好两年半,我决定重启我之前未完成的计划,继续阅读《The Go Programing Language》,一年多前我更新至第五章讲解的时候,工作的忙碌和 GPT 的出现让我搁置了这个计划。现在补上六至八章的讲解,并整理成一个合集,方便大家阅读。
我也开源了一个 Go 语言的学习仓库,有需要的同学可以关注,其中将整理往期精彩文章、以及 Go 相关电子书等资料。
仓库地址:github.com/BaiZe1998/g…
本文的内容就是针对《The Go Programing Language》第一至八章的整理以及本人的领读,涵盖 Go 语言的核心知识。
区别于连篇累牍,我希望这份笔记是详略得当的,可能更适合一些对Go有着一些使用经验,但是由于是转语言或者速食主义者,对 Go 的许多知识点并未理解深刻,笔记中虽然会带有一些个人的色彩,但是 Go 语言的重点我将悉数讲解。
再啰嗦一句:笔记中讲述一个知识点的时候有时并非完全讲透,或是浅尝辄止,或是抛出疑问却未曾解答。希望你可以接受这种风格,而有些知识点后续涉及到后续章节,当前未过分剖析,也会在后面进行更深入的讲解。
最后,如果遇到错误,或者你认为值得改进的地方,也很欢迎你评论或者联系我进行更正,又或者你也可以直接在仓库中提issue或者pr,或许这也是小小的一次“开源”。
感兴趣可以关注公众号 「白泽talk」,白泽目前也打算打造一个氛围良好的行业交流群,文章的更新也会提前预告,欢迎加入:622383022。
一、综述
1.1 Hello Word
介绍包管理,编译依赖,运行代码的流程;无需分号结尾以及严格的自动格式化
1.2 命令行参数
参数初始化,获取命令行参数的方式,给出了一个低效的循环获取命令行参数的代码,在此基础上进行优化
关于字符串常量的累加(是否是不断创建新值,变量创建后如何存储,结合Java堆|栈)
1.3 查找重复行
strings.join底层发生了什么
map乱序的原因
os.stdin Scan的终止条件
输出错误内容到标准错误
何时可以跳过error检查
1.4 GIF 动画
可以生成gif格式的图片
1.5 获取一个URL
resp.Body.Close()可以avoid leaking resources,具体发生了什么
io.Copy(dst, src)与ioutil.ReadAll的工作模式区别
1.6 并发获取多个URL
当多个goroutine同时对一个channel进行输入输出的时候,会发生阻塞
1.7 实现一个 Web 服务器
fmt.Fprintf(dir, src)可以将内容输出到指定输出(web的response、标准错误),因为dir实现了接口(io.Writer)
启动服务程序的时候mac&linux为什么末尾要加&
服务端handler路由匹配到前缀则可以触发,并且开启不同goroutine处理request(那么上限是多少,高访问量会发生什么)
1.8 杂项
switch在满足case之后不会继续下沉,且default可以放置在任何位置
switch也可以以tarless的模式书写
goto语法不常用,但是go也提供了
func也可以作为一种类型
结构、指针、方法、接口、包、注释
二、程序结构
2.1 名字
包名通常小写字母命名
通常来说,对于作用域较短的变量名,Go推荐短命名,如i而不是index,而对于全局变量则倾向于更长,更凸显意义的命名
驼峰而非下划线命名
2.2 声明
注意全局变量的作用域最小也是整个包的所有文件,大写则可以跨包
2.3 变量
引用类型:slice、pointer、map、channel、function
可以同时初始化多种类型的变量,并且Go没有未初始化的变量
var x float64 = 100 // 此时不使用短变量命名
:= 是声明,而 = 是赋值
巧妙:如果:=左侧部分变量已经声明过(作用域相同),则只会对其进行赋值,而只声明+赋值未声明过的变量,且左侧必须至少有一个未声明才能用:=,且declarations outer block are ignored
x := 1
p := &x
*p = 2 // 则 x == 1
var x, y int
&x == &x, &x == &y, &x == nil // true false false
Go的flag包可以实现获取命令行参数的功能:-help的来源
p := new(int) // p是int类型的指针(或者某个类型的引用),此时*p == 0
*p = 2 // new 并不常用
垃圾回收:一个变量如果不可达(unreachable),则会被回收
关于变量的生命周期:全局变量在程序运行周期内一直存在,而局部变量则会在unreachable时会被回收,其生命周期从变量的声明开始,到unreachable时结束
栈内存:栈内存由编译器自动分配和释放,开发者无法控制。栈内存一般存储函数中的局部变量、参数等,函数创建的时候,这些内存会被自动创建;函数返回的时候,这些内存会被自动释放,栈可用于内存分配,栈的分配和回收速度非常快
堆内存:只要有对变量的引用,变量就会存在,而它存储的位置与语言的语义无关。如果可能,变量会被分配到其函数的栈,但如果编译器无法证明函数返回之后变量是否仍然被引用,就必须在堆上分配该变量,采用垃圾回收机制进行管理,从而避免指针悬空。此外,局部变量如果非常大,也会存在堆上。
在编译器中,如果变量具有地址,就作为堆分配的候选,但如果逃逸分析可以确定其生存周期不会超过函数返回,就会分配在栈上。
总之,分配在堆还是栈完全由编译器确定。而原本看起来应该分配在栈上的变量,如果其生命周期获得了延长,被分配在了堆上,就说它发生了逃逸。编译器会自动地去判断变量的生命周期是否获得了延长,整个判断的过程就叫逃逸分析。
/*
此时x虽然是局部变量,但是被分配在堆内存,在f()调用结束后依旧可以通过global获取x的内容,我们称x从f当中escape了
逃逸并非是一件不好的事情,但是需要注意,对于那些需要被回收的短生命周期的变量,不要在编程当中被长生命周期的变量(全局变量)引用,否则会很大程度上影响Go的垃圾回收能力,造成内存分配压力
*/
var global *int
func f() {var x intx = 1global = &x
}
// 此时*y没有从g()当中escape,因此是分配在栈内存当中,调用结束变成unreachable,需要被回收
fun g() {y := new(int)*y = 1
}
2.4 赋值
x, y = y, x
a[i], a[j] = a[j], a[i]
// 计算斐波那契数列,=赋值右侧的表达式会按照旧值先计算后赋值给左侧变量
func fib(n int) int {x, y := 0, 1for i := 0; i < n; i++ {x, y = y, x+y}
}
2.5 类型声明
type IntA int
type IntB int
var (x IntA = 1 // 此时x和y是不同类型,因此无法比较与一起运算y IntB = 2
)
T(x)将x转成T类型,转换操作可以执行的前提是x和T在底层是相同的类型,或者二者是未命名的指针类型,底层指向相同的类型
这样的转换虽然转化了值的类型,但是并没有改变其代表的值
当然,数值类型的变量之间也允许这种转换(损失精度),或者将string转换成[]byte的切片等,当然这些转化方式将改变值的内容
2.6 包和文件
包中.go文件的初始化流程:
- 如果package p内部import了q,则会先初始化package q
- main package最后初始化,可以确保main func在执行时所有的package已经完成初始化
2.7 作用域
变量的scope(作用域)是处于compile-time(编译时)的特征
变量的lifetime(生命周期)是处于run-time(运行时)的特征
if x := f(); x == 0 {fmt.Println(x, y)
} else if y := g(x); x == y {fmt.Println(x, y)
} else {fmt.Println(x, y)
}
fmt.Println(x, y) // compile error: x and y are not visible here
变量作用域的测试如下:
func test() (int, error) {return 1, nil
}
func main() {x := 0
for i := 1; i <= 5; i++ {x := ifmt.Println(x, &x)}fmt.Println(x, &x) // 此时x依旧是0,说明for内部的x是重新声明的x, err := test() // 此时x和err通过:=声明+赋值,但是结合2.3节的内容,此时x已经声明,所以只对其进行赋值为1,但是地址不变fmt.Println(x, &x, err) // 此处打印的x == 1时的地址与赋值前x == 0地址相同
}
// 结果
1 0x1400012a010
2 0x1400012a030
3 0x1400012a038
4 0x1400012a040
5 0x1400012a048
0 0x1400012a008
1 0x1400012a008 <nil>
三、基本数据类型
3.1 整数
负数的%运算
&^(位运算符:and not),x &^ y = z,y中1的位,则z中对应为0,否则z中对应为x中的位
00100010 &^ 00000110 = 00100000
无符号整数通常不会用于只为了存放非负整数变量,只有当涉及到位运算、特殊的算数运算、hash等需要利用无符号特性的场景下才会去选择使用
比如数组下标i用int存放,而不是uint,因为i–使得i == -1时作为判断遍历结束的标志,如果是uint,则0减1则等于2^64-1,而不是-1,无法结束遍历
注意:int的范围随着当前机器决定是32位还是64位
var x int32 = 1
var y int16 = 2
var z int = x + y // complie error
var z int = int(x) + int(y) // ok
// 大多数数值型的类型转换不会改变值的内容,只会改变其类型(编译器解释这个变量的方式),但是当整数和浮点数以及大范围类型与小范围类型转换时,可能会丢失精度,或者出现意外的结果
3.2 浮点数
math.MaxFloat32
math.MinFloat32
const x = 6.2222334e30 // 科学计数法
// math包中有很多的使用浮点数的函数,并且fmt包有很多适用于浮点数的格式化输出,包括保留小数点的具体精度等
float32精度大概6位
float64精度大概15位(更常用,因为单精度计算损失太快)
// 直接用浮点数为返回值结果,再二次用于其他的比较判断返回结果是否有效,有时会有误差导致错误,推荐额外增加一个bool参数
func compute() (value float64, ok bool) {if failed {return 0, false}return result, true
}
3.3 复数
var x complex128 = complex(1, 2) // 1+2i
var y complex128 = complex(3, 4) // 3+4i
fmt.Println(x*y) // -5+10i
fmt.Println(real(x*y)) // -5
fmt.Println(imag(x*y)) // 10
// 两个复数相等当且仅当实部和虚部相当
fmt.Println(cmplx.Sqrt(-1)) // 0+1i
3.4 布尔量
bool是if或者for的判断条件
s != "" && s[0] == 'x' // 当逻辑运算符左侧表达式可以决定操作结果则将放弃执行右侧表达式
// &&的优先级高于||
3.5 字符串
string在GO语言中是不可变的量
len获取的是字符串的字节数目,而不是码点(UTF-8 Unicode code point)
字符串第i个字节,并不一定是字符串的第i个字符,因为UTF-8编码对于非ASCII的code point需要2个或更多字节
str := "hello, world"
fmt.Println(s[:5]) // hello
fmt.Println(s[7:]) // world
fmt.Println(s[:]) // hello world
s := "left"
t := s
s += " right" // 此时s指向新创建的string ”left right“,而t指向之前的s表示的“left”
a := "x"
b := "x"
a == b // true,且string可以按照字典序比较大小
string是不可变的,意味着同一个string的拷贝可以共享底层的内存,使得拷贝变得很轻量,比如s和s[:7]可以安全的共享相同的数据,因此substring操作也很轻量。没有新的内存被分配。
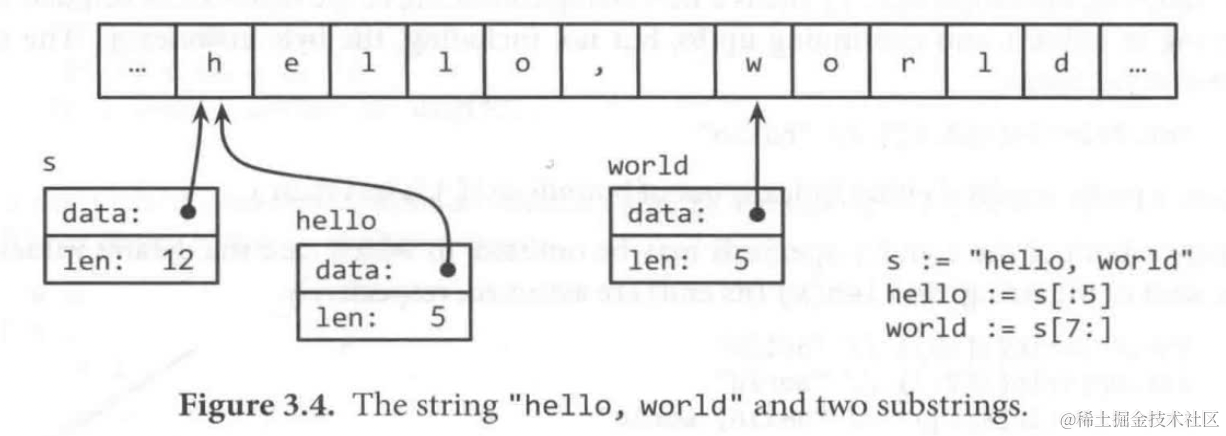
反引号中的字符串表示其原生的意思,内容可以多行定义,不支持转义字符
func main() {a := `hello worldlalala`fmt.Println(a)
}
Unicode
UTF-8使用码点描述字符(Unicode code point),在Go中对应术语:rune(GO中使用int32存储)
可以使用一个int32的序列,来代表rune序列,固定长度带来了额外的开销(因为大多数常用字符可以使用16bits描述)
UTF-8
可变长编码,使用1-4 bytes来代表一个rune,1byte存储 ASCII ,2 or 3 bytes 存储大多数常用字符 rune,并且采用高位固定的方式来区分范围(前缀编码,无二义性,编码更紧凑)

s := "Hello, 世界"
fmt.Println(len(s)) // 13
fmt.Println(utf8.RuneCountInString(s)) // 9

字符串和数组切片
字符串包含了一连串的字节(byte),创建后不可变。而[]byte内容是可变的
s := "abc"
b := []byte(s) // 分配新的字节数组内存
s2 : string(b) // 发生内存拷贝
为了避免没有必要的转换和内存分配,bytes包中提供了很多与string包中相同功能的方法,更推荐使用(共享内存)
bytes.Buffer用于字符(字符串)的累加构造字符串操作很方便,高效
// 一些操作Buffer的api
var buf bytes.Buffer
fmt.Fprintf(&buf, "%d", x)
buf.WriteString("abc")
buf.WriteByte('x')
buf.WriteRune(码点值)
字符串和数值类型的转换
// 整数转string
x := 123
y := fmt.Sprintf("%d", x)
fmt.Println(y, strconv,Itoa(x)) // "123" "123"
// %b %d %u %x 用于进制转换
s := fmt.Sprintf("x=%b", x) // "x=1111011"
// string转整数
x, err := strconv.Atoi("123")
y, err := strconv.ParseInt("123", 10, 64)// base 10, up to 64 bits,第三个参数表示转换的整型的范围为int64
// fmt.Scanf()可以用于读取混合数据(整型、字符等)
3.6 常量
所有常量的底层都是由:boolean、string、number组成(在编译时确定,不可变,常量的运算结果依旧是常量)
const a = 2
const b = 2*a // b 在编译时完成
大多数常量的声明没有指定类型,但是也可以指定,没有类型的常量Go中称为无类型常量(untyped constant),具体的类型到使用到的时候确定
untyped constant
const a = 10
fmt.Printf("%T\n", a) // int(隐式类型)
var b float64 = 4*a // 在需要的时候,a转变成了float64
fmt.Printf("%T\n", b) // float64
在默认情况下,untyped constant 不是没有具体类型,而是隐式转换成了如下类型,因此上述a的类型可以打印为int
并且untyped constant拥有更高的精度,可以认为至少有 256bit 的运算精度
- untyped boolean
- untyped integer (隐式转换成 int)
- untyped rune (隐式转换成 int32)
- untyped floaing-point (隐式转换成 float64)
- untyped complex (隐匿转换成 complex128)
- untyped string
常量生成器
可以参与计算且拥有增长属性
type Flags uint
const (a = 1 << iota // 1b // 2c // 4d // 8
)
const (_ = 1 << (10 * iota)KiB // 2^10MiB // 2^20GiB // 2^30TiB // PiB // EiB // ZiB // 2^70...
)
四、复合类型
4.1 数组
长度不可变,如果两个数组类型是相同的则可以进行比较,且只有完全相等才会为true
a := [...]int{1, 2} // 数组的长度由内容长度确定
b := [2]int{1, 2}
c := [3]int{1, 2}
4.2 切片
切片由三部分组成:指针、长度(len)、容量(cap)
切片可以通过数组创建
// 创建月份数组
months := [...]string{1:"January", 省略部分内容, 12: "December"}
基于月份数组创建切片,且不同切片底层可能共享一片数组空间
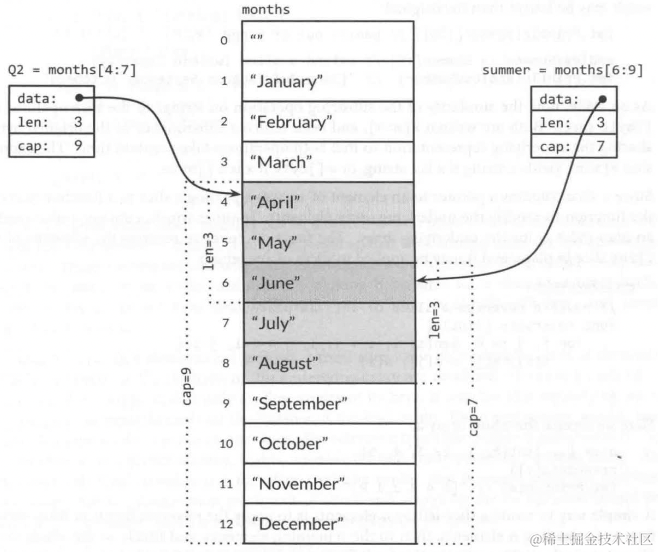
fmt.Println(summer[:20]) // panic: out of range
endlessSummer := summer[:5] // 如果未超过summer的cap,则会扩展slice的len
fmt.Println(endlessSummer) // "[June July August September October]"
[]byte切片可以通过对字符串使用类似上述操作的方式获取
切片之间不可以使用==进行比较,只有当其判断是否为nil才可以使用
切片的zero value是nil,nil切片底层没有分配数组,nil切片的len和cap都为0,但是非nil切片的len和cap也可以为0(Go中len == 0的切片处理方式基本相同)
var s []int // len(s) == 0, s == nil
s = nil // len(s) == 0, s == nil
s = []int(nil) // len(s) == 0, s == nil
s = []int{} // len(s) == 0, s != nil
The append Function
使用append为slice追加内容,如果cap == len,则会触发slice扩容,下面是一个帮助理解的例子(使用了2倍扩容,并非是Go内置的append处理流程,那将会更加精细,api也更加丰富):

4.3 映射
map(hash table) — 无序集合,key必须是可以比较的(除了浮点数,这不是一个好的选择)
x := make(map[string]int)
y := map[string]int{"alice": 12,"tom": 34
}
z := map[string]int{}
// 内置函数
delete(y, "alice")
对map的元素进行取地址并不是一个好的注意,因为map的扩容过程中可能伴随着rehash,导致地址发生变化(那么map的扩容规则?)
ages["carol"] = 21 // panic if assignment to entry in nil map
// 判断key-value是否存在的方式
age, ok := ages["alice"]
if age, ok := ages["bob"]; !ok {...
}
4.4 结构体
type Point struct {x, y int
}
type Circle struct {center Pointradius int
}
type Wheel struct {circle Circlespokes int
}
w := Wheel{Circle{Point{8, 8}, 5}, 20}
w := Wheel{circle: Circle{center: Point{x: 8, y: 8},radius: 5,},spokes: 20,}
4.5 JSON
// 将结构体转成存放json编码的byte切片
type Movie struct {Title stringYear int `json:"released"` // 重定义json属性名称Color bool `json:"color,omitempty"` // 如果是空值则转成json时忽略
}
data, err := json.Marshal(movie)
data2, err := json.MarshalIndent(movie, "", " ")
// 输出结果
{"Title":"s","released":1,"color":true}
{"Title": "s","released": 1,"color": true
}
// json解码
content := Movie{}
json.Unmarshal(data, &content)
fmt.Println(content)
4.6 文本和HTML模板
略
五、方法
5.1 方法声明
// 可以提前声明返回值z
func add(x, y int) (z int) {z = x-yreturn
}
如果两个方法的参数列表和返回值列表相同,则称之为拥有相同类型(same type)
参数是值拷贝,但是如果传入的参数是:slice、pointer、map、function,channel虽然是值拷贝,但是也是引用类型的值,会对其指向的值做出相应变更
你可能会遇到查看某些go的内置func源码的时候它没有声明func的body部分,例如append方法
// The append built-in function appends elements to the end of a slice. If
// it has sufficient capacity, the destination is resliced to accommodate the
// new elements. If it does not, a new underlying array will be allocated.
// Append returns the updated slice. It is therefore necessary to store the
// result of append, often in the variable holding the slice itself:
// slice = append(slice, elem1, elem2)
// slice = append(slice, anotherSlice...)
// As a special case, it is legal to append a string to a byte slice, like this:
// slice = append([]byte("hello "), "world"...)
func append(slice []Type, elems ...Type) []Type
事实上append在代码编译的时候,被替换成runtime.growslice以及相关汇编指令了(可以输出汇编代码查看细节),你可以在go的runtime包中找到相关实现,如下:
// growslice handles slice growth during append.
// It is passed the slice element type, the old slice, and the desired new minimum capacity,
// and it returns a new slice with at least that capacity, with the old data
// copied into it.
// The new slice's length is set to the old slice's length,
// NOT to the new requested capacity.
// This is for codegen convenience. The old slice's length is used immediately
// to calculate where to write new values during an append.
// TODO: When the old backend is gone, reconsider this decision.
// The SSA backend might prefer the new length or to return only ptr/cap and save stack space.
func growslice(et *_type, old slice, cap int) slice {if raceenabled {callerpc := getcallerpc()racereadrangepc(old.array, uintptr(old.len*int(et.size)), callerpc, abi.FuncPCABIInternal(growslice))}if msanenabled {msanread(old.array, uintptr(old.len*int(et.size)))}if asanenabled {asanread(old.array, uintptr(old.len*int(et.size)))}// 省略...
}
声明函数时指定返回值的名称,可以在return时省略
func add(x, y int) (z int, err error) {data, err := deal(x, y)if err != nil {return // 此时等价于return 0, nil}// 这里是赋值而不是声明,因为在返回值列表中声明过了z = x+yreturn // 此时等价于return z, nil
}
5.2 错误
error是一个接口,因此可以自定义实现error
type error interface {Error() string
}
如果一个函数执行失败时需要返回的行为很单一可以通过bool来控制
func test(a int) (y int, ok bool) {x, ok := test1(a)if !ok {return }y = x*xreturn
}
更多情况下,函数处理时可能遇到多种类型的错误,则使用error,可以通过判断err是否为nil判断是否发生错误
func test(a int) (y int, err error) {x, err := test1(a)if err != nil {return }y = x*xreturn
}
// 打印错误的值
fmt.Println(err)
fmt.Printf("%v", err)
Go通过if和return的机制手动返回错误,使得错误的定位更加精确,并且促使你更早的去处理这些错误(而不是像其他语言一样选择抛出异常,可能使得异常由于调用栈的深入,导致最终处理不便)
错误处理策略
一个func的调用返回了err,则调用方有责任正确处理它,下面介绍五种常见处理方式:
- 传递:
// 某func部分节选
resp, err := http,Get(url)
if err != nil {// 将对Get返回的err处理交给当前func的调用方return nil, err
}
fmt.Errorf()格式化,添加更多描述信息,并创建一个了新的error(参考fmt.Sprintf的格式化)

当error最终被处理的时候,需要反映出其错误的调用链式关系
并且error的内容组织在一个项目中需要统一,以便于后期借助工具统一分析
- 错误重试
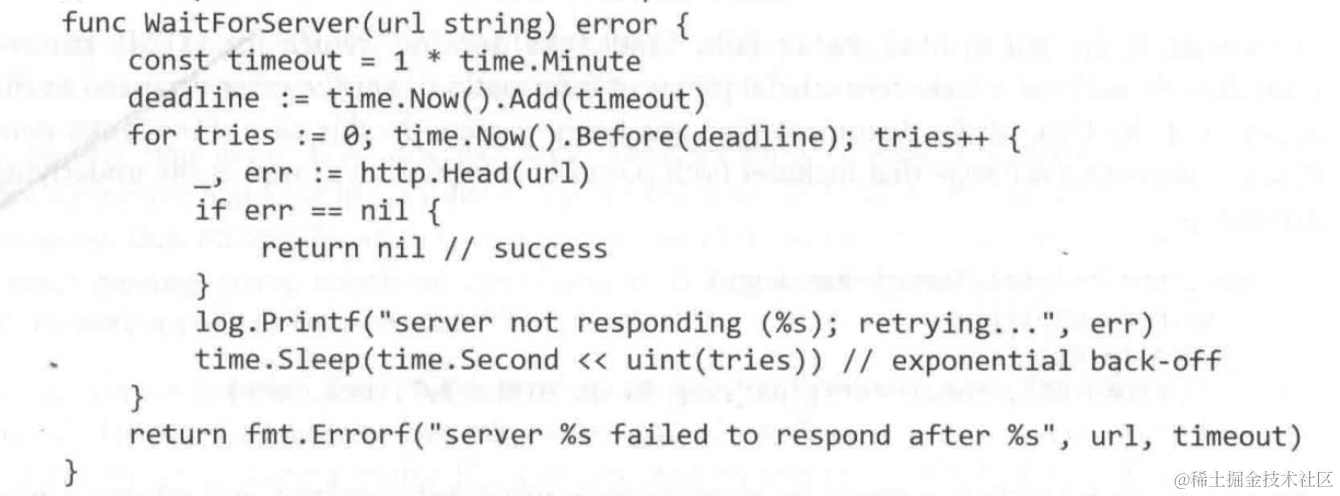
- 优雅关闭
如果无法处理,可以选择优雅关闭程序,但是推荐将这步工作交给main包的程序,而库函数则选择将error传递给其调用方。

使用log.Fatalf更加方便

会默认输出error的打印时间

- 选择将错误打印
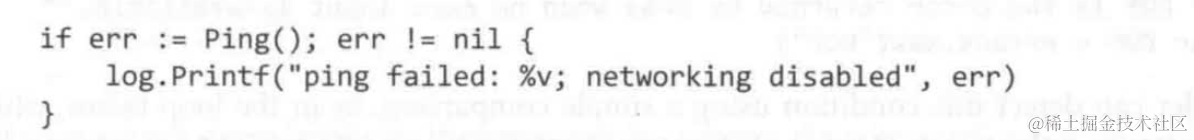
或者输出到标准错误流

- 少数情况下,可以选择忽略错误,并且如果错误选择返回,则正确情况下省略else,保持代码整洁

EOF(End of File)
输入的时候没有更多内容则触发io.EOF,并且这个error是提前定义好的


5.3 作为值的函数
函数是一种类型类型,可以作为参数,并且对应变量是“引用类型”,其零值为nil,相同类型可以赋值


函数作为参数的例子,将一个引用类型的参数传递给多个func,可以为这个参数多次赋值(Hertz框架中使用了这种扩展性的思想)

5.4 匿名函数
函数的显式声明需要在package层面,但是在函数的内部也可以创建匿名函数

从上可以看出f存放着匿名函数的引用,并且它是有状态的,维护了一个递增的x
捕获迭代变量引发的问题
正确版本
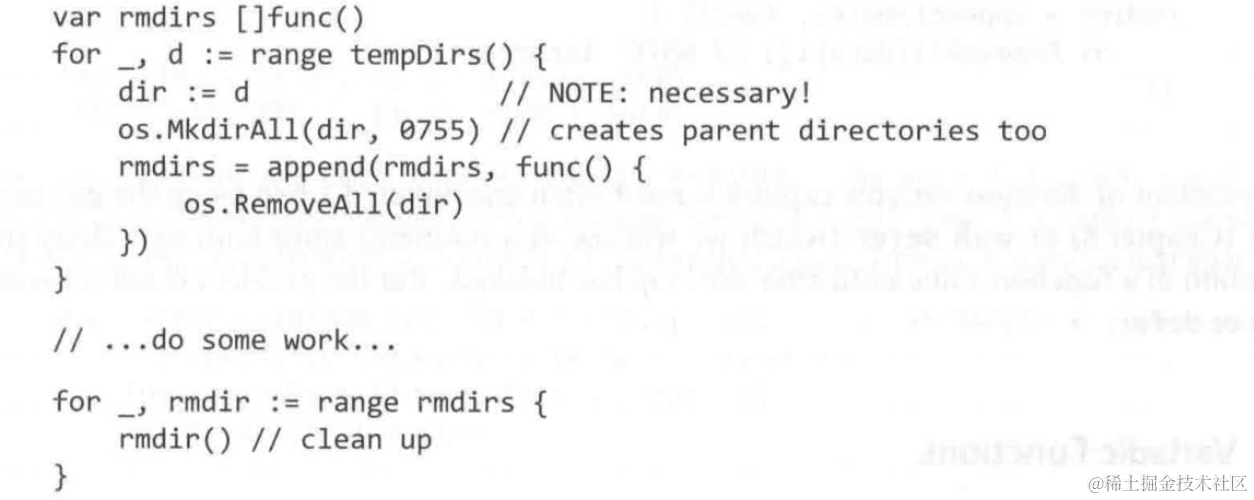
错误版本

所有循环内创建的func捕获并共享了dir变量(相当于引用类型),所以创建后rmdirs切片内所有元素都有同一个dir,而不是每个元素获得dir遍历时的中间状态
因此正确版本中dir := d的操作为遍历的dir申请了新的内存存放
func main() {arr := []int{1, 2, 3, 4, 5}temp := make([]func(), 0)for _, value := range arr {temp = append(temp, func() {fmt.Println(value)})}for i := range temp {temp[i]()}
}
// 结果
5
5
5
5
5
另一种错误版本(i最终达到数组长度上界后结束循环,并且导致dirs[i]发生越界)

// 同样是越界的测试函数
func main() {arr := []int{1, 2, 3, 4, 5}temp := make([]func(), 0)for i := 0; i < 5; i++ {temp = append(temp, func() {fmt.Println(arr[i])})}for i := range temp {temp[i]()}
}
// 结果
panic: runtime error: index out of range [5] with length 5
以上捕获迭代变量引发的问题容易出现在延迟了func执行的情况下(先完成循环创建func、后执行func)
5.5 变参函数

vals此时是一个int类型的切片,下面是不同的调用方式
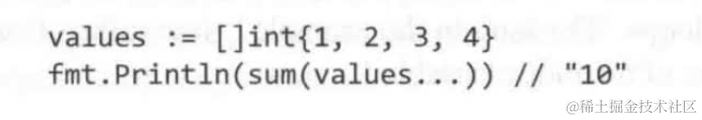

虽然…int参数的作用与[]int很相似,但是其类型还是不同的,变参函数经常用于字符串的格式化printf

测试
func test(arr ...int) int {arr[0] = 5sum := 0for i := 0; i < len(arr); i++ {sum += arr[i]}return sum
}
func main() {arr := []int{1, 2, 3, 4, 5}fmt.Println(test(arr...))fmt.Println(arr)
}
// 切片确实被修改了
19
[5 2 3 4 5]
5.6 延后函数调用
defer通常用于资源的释放,对应于(open&close|connect&disconnect|lock&unlock)
defer最佳实践是在资源申请的位置紧跟使用,defer在当前函数return之前触发,如果有多个defer声明,则后进先出顺序触发
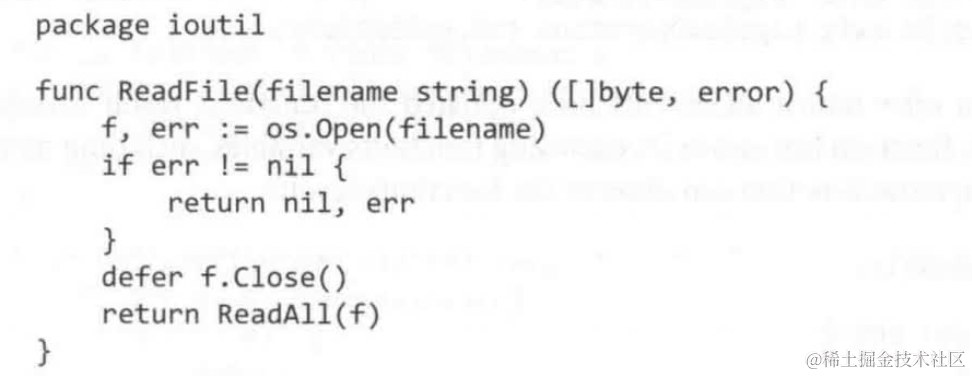

defer也可以用于调试复杂的函数(通过return一个func的形式)


测试1:
func test() func() {fmt.Println("start")defer func() {fmt.Println("test-defer")}()return func() {fmt.Println("end")}
}
func main() {defer test()()fmt.Println("middle")
}
// 输出
start
test-defer
middle
end
可以观察到test()()分为两步执行,start在defer声明处打印,end在main函数return前打印,并且test内定义的defer也在test函数return前打印test-defer
此时start和end包围了main函数,因此可以用这种方式调试一些复杂函数,如统计执行时间
测试2:
func test() func() {fmt.Println("start")defer func() {fmt.Println("test-defer")}()return func() {fmt.Println("end")}
}
func main() {defer test()fmt.Println("middle")
}
// 输出
middle
start
test-defer
此时将test()()改为test(),则未触发test打印end,并且先执行了打印middle
另一个特性:defer可以修改return返回值:

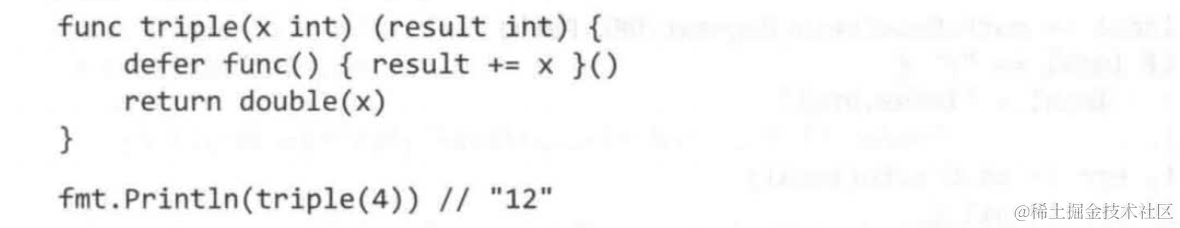
此时double(x)的结果先计算出来,后经过了defer内result += x的赋值,最后得到12
此外因为defer一般涉及到资源回收,那么如果有循环形式的资源申请,需要在循环内defer,否则可能出现遗漏
5.7 panic(崩溃)
Go的编译器已经在编译时检测了许多错误,如果Go在运行时触发如越界、空指针引用等问题,会触发panic(崩溃)
panic也可以手动声明触发条件

发生panic时,defer所定义的函数会触发(逆序),程序会在控制台打印panic的日志,并且打印出panic发生时的函数调用栈,用于定位错误出现的位置
func test() {fmt.Println("start")
}
func main() {defer test()panic("panic")
}
// 结果
start
panic: panic
panic不要随意使用,虽然预检查是一个好的习惯,但是大多数情况下你无法预估runtime时错误触发的原因

手动触发panic发生在一些重大的error出现时,当然如果发生程序的崩溃,应该优雅释放资源如文件io
关于panic发生时defer的逆序触发如下:




5.8 recover(恢复)
panic发生时,可以通过recover关键字进行接收(有点像异常2捕获),可以做一些资源释放,或者错误报告工作,因此可以优雅关闭系统,而不是直接崩溃

如果recover()在defer中被调用,则当前函数运行发生panic,会触发defer中的recover(),并且返回的是panic的相关信息,否则在其他时刻调用recover()将返回nil(没有发挥recover()作用)
上图中的案例recover()接受到panic后,选择打印panic内容,将其看作是一个错误,而不选择停止程序运行,因此也就有了“恢复”的含义
但是recover()不能无端使用,因为panic的发生,只报告错误,放任程序继续执行,往往会使得程序后续的运行出现不可预计的问题,即使是使用recover,也只关注当前方法内的panic,而不要去考虑处理其他包的方法调用可能产生的panic,因为这更难把握程序运行的安全性
因此只有少数情况下使用recover,并且确实是有这个需求,否则还是建议触发panic的行为

六、方法
6.1 方法声明
Go的面向对象与传统意义上的不同
传统的方法声明和为Point结构声明方法

声明方法接收者的名称p,通常可以选择对应类型的第一个小写字母,声明方法接收者与声明参数列表很相似
两种方法调用方式如下:

注意p的参数和方法不能同名,否则编译时将出错,但是不同类型的方法接收者可以拥有同名方法,如下:


Path是一个Point类型的切片,而不是一个Point类型的结构
并且Go与其他面向对象语言不同,它可以各种类型的变量(数值型、string、slice、map、甚至function因为其也是一种类型)声明方法,为其添加额外的行为。
除了这个类型变量的底层不是一个指针point或者接口interface
type MyX *int
// 非法
func (m MyX) test(x int, y int) {fmt.Println(x, y)
}
Go语言的方法没有重载功能,同一个类型的方法不能出现同名,及时参数列表不同

// 下面是一个错误的例子
type MyX int
func (m MyX) test(x int, y int) {fmt.Println(x, y)
}
func (m MyX) test(x int) {fmt.Println(x)
}
6.2 带有指针接收器的方法

可以借助指针的特性,实现对变量携带属性的修改
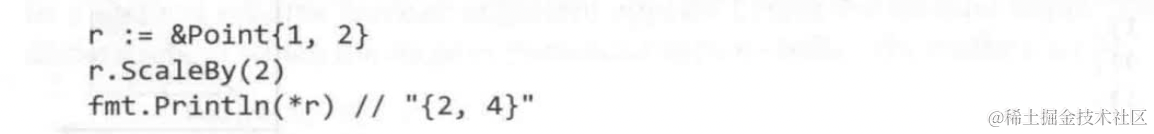
注意⚠️:
如果声明的是带有指针接收器的方法,但是创建的变量不是指针类型,则方法调用时会将变量隐式转换成指针类型

如果声明的是普通类型接收器的方法,但是创建的变量是指针类型,则方法调用时会将变量隐式转换成原本的非指针类型
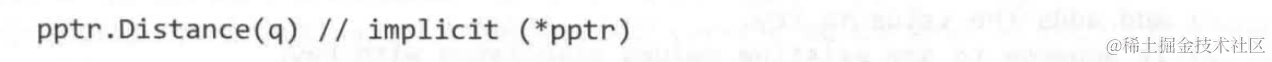
并且:如果一个实例对应类型的方法都不是通过指针接收器声明的,则对该实例进行copy操作则是安全的,否则通过指针接收器调用的方法,可能会涉及实例内部的状态向外泄露
nil作为有效的接收者


一个有趣的测试:
type Test struct {x, y int
}
func (t *Test) Sum() int {if t == nil {return 100}return t.x + t.y
}
func main() {x := &Test{1, 2}fmt.Println(x.Sum())x = nilfmt.Println(x.Sum())
}
// 输出
3
100
因此当x为nil的时候,其函数调用触发行为是可以自定义的
6.3 嵌套结构体组成新类型
嵌套结构可以赋值可以简化,相当于组合成的struct拥有内部struct的属性

组合成的struct拥有内部struct的方法,因此一个需要拥有多个方法的结构可以通过拆解成多个结构各自拥有部分方法的组合

注意Go的结构的嵌套是“has a”的关系,而不是“is a”的关系,因此寻常语言的上下转型不适用
一个结构可以内嵌匿名属性

此时ColoredPoint拥有拥有自己声明的方法,以及内嵌结构的所有方法,如果出现相同名称的方法则外层拥有更高的优先级,同名属性同理,如果出现同层级相同优先级则会报错
./main.go:35:16: ambiguous selector xxx
结构嵌套小试牛刀

6.4 方法调用的两种形式
寻常实例化后调用方法

先获取某个结构体的方法表达式,传入需要触发方法的结构实例作为第一个参数,方法的参数列表对应剩余参数

type A struct {y int
}
func (a *A) Sum(x int) {fmt.Println(a.y, x)
}
func main() {fun := (*A).Suma := &A{1}fun(a, 2)
}
使用场景:

6.5 封装
Go语言只有一种控制变量或者方法的访问性的规则,就是首字母大小写


这种写法,则跨package的时候,words字段不能被其他包内的实例访问,一定程度上确保了slice的安全性
type A struct {y int
}
// 此时的sum也不能被跨包访问
func (a *A) sum(x int) {fmt.Println(a.y, x)
}
七、接口
7.1 作为规约的接口

io.Writer也是一个接口,所谓规约就是约束了行为,但是不制定细节实现方式,只要它实现了Write方法

比如可以自己定义一个结构,并声明一个Write方法


另一个很重要的接口

7.2 接口类型

接口的嵌套

7.3 接口约定的达成
Go语言中,使用“is a”可以表达一个type实现了某个接口声明的所有方法(“has a”是用于结构的嵌套)
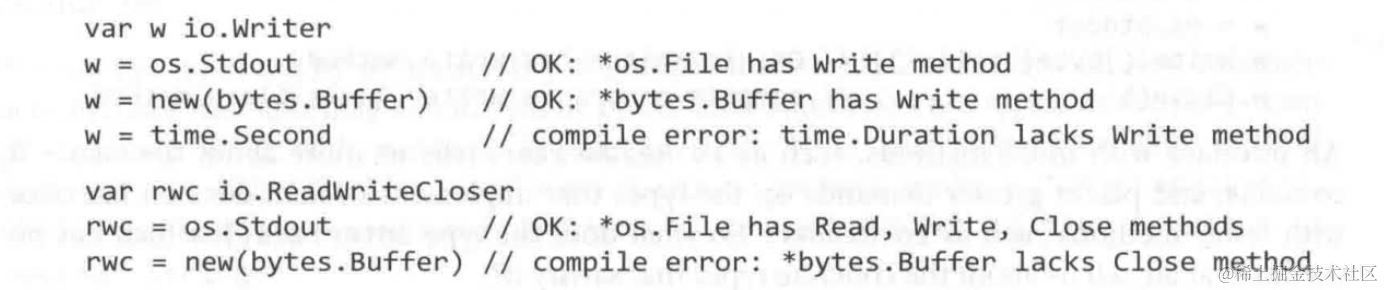
赋值:f右侧可以多于左侧(只要覆盖左侧接口声明即可)

之前提到过,Go为一个type声明方法的时候,可以使用指针接收器也可以不使用,但是在方法调用的时候,即使类型与声明时不对应,也会隐式完成转换
⚠️但是要注意的是,对于使用指针接收器声明的方法,非指针接收器类型本身是不拥有这些方法的;但是非指针接收器声明的方法,指针类型是拥有声明的方法的
type IntSet struct {
}
func (*IntSet) String() string {fmt.Println("test")return "test"
}
func main() {t := IntSet{}var _ = t.String() // okvar _ = (&t).String() // okvar _ fmt.Stringer = &t // okvar _ fmt.Stringer = t // Cannot use 't' (type IntSet) as the type fmt.Stringer Type does not implement 'fmt.Stringer' as the 'String' method has a pointer receiver
}
反之合法
type IntSet struct {
}
func (IntSet) String() string {fmt.Println("test")return "test"
}
func main() {t := IntSet{}var _ = t.String() // okvar _ = (&t).String() // okvar _ fmt.Stringer = &t // okvar _ fmt.Stringer = t // ok
}
空接口没有声明任何方法,因此可以接收任何类型的变量

但是因为interface{}没有任何方法,当一个值赋值给它之后就失去了其原本的特性,因此需要有一个机制去从interface{}中重新提取出原来的变量。(断言机制,后续7.10会提及)
7.4 作为值的接口
一个interface的状态可以由type和value修饰,称其为动态的type和动态的value,这个type的概念并不是通常意义下的类型概念(因为Type是一个静态的概念,是编译时的特性)
其type表示赋值给这个接口的变量对应的type
其value是一个指针,指向赋值给这个接口的变量对应的value
对下面这四行代码进行分析:

对于一个接口类型来说:

一个接口的零值状态如下(没有变量为其赋值),这里的type也是一种“值”,用于描述这个接口的特性:

一个接口是否为nil是根据其动态类型(type&value)决定的,因此上述w是一个nil接口(w == nil == true)

第二行代码赋值后(value是一个指针):


第三行代码赋值后:


第四行代码赋值后:


接口是一个可以比较的类型,两个接口类型都为nil时相等
或者其动态的type和value都相等(要求可以比较,如果是slice等不可比较的类型,则会panic)

因此interface可以作为hash的key,也可以作为switch的操作数
打印接口的动态type

当interface的value为nil
当一个接口的变量的动态value指向nil(因为它是一个指针),则称这个变量为non-nil,并且不等于nil,因为其动态type不等于nil
func main() {var buf *bytes.Buffer// buf = new(bytes.Buffer)// 将一个实现了Write方法的结构传递给io.Writer接口类型outf(buf)
}
func f(out io.Writer) {if out != nil {out.Write([]byte("done"))}
}
// 报错
panic: runtime error: invalid memory address or nil pointer dereference
原因:此时out是一个non-nil接口,其动态的value指向nil,但是其动态的type为*bytes.Buffer,因此out != nil确实为true

下面三节讲解interface如何应用在排序、web服务、错误处理当中
7.5 使用sort.Interface排序
一些常用的sort方法
func Ints(x []int) { Sort(IntSlice(x)) }
// 本质上IntSlice实现了sort.Interface定义的三个接口
type IntSlice []int
func (x IntSlice) Len() int { return len(x) }
func (x IntSlice) Less(i, j int) bool { return x[i] < x[j] }
func (x IntSlice) Swap(i, j int) { x[i], x[j] = x[j], x[i] }
// 下面两个用法等价
sort.Sort(sort.IntSlice(arr))
sort.Ints(arr)
7.6 错误接口
error本质上也是实现了一个接口

并且返回的是一个结构的指针

fmt.Errorf()更加方便错误的格式化创建

7.7 类型断言
在前面我们说了一个接口底层有两个动态的值,一个是type,一个是指向value的指针
通过x.(T)的方式从接口实例x中,提取出x接口实例底层动态的value,底层type类型不对应T,则panic(断言操作之前一般有着接口赋值操作)

如果T也是一个接口类型,则断言机制会判断x的底层type是否满足这个T接口,并且当成功时,断言的结果依旧是一个接口,只是底层type的值变成了T

通常通过断言是否成功来取值

并且可以选择复用原来的变量名称

7.8 使用类型断言分辨错误
定义一个封装的PathError:

使用如下:

os包提供了三个方法用于分辨Error

简易用法如下:

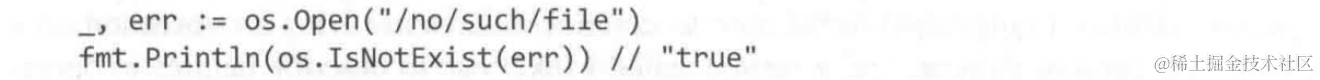
这个机制的作用在于可以自定义一些错误,并且在发生错误时动态判断错误的类型,从而作出相应处理
7.9 使用接口类型断言查询行为
可以通过接口类型的断言,将一个接口实例更具体化为携带某个功能的接口实例

7.10 按类型的程序分支
使用interface的两个场景:
- 用接口去定义行为(methods)
- 用接口去接收各个实现某个行为(methods)的类型实例,配合断言进行动态处理
类型断言配合else-if:

类型断言配合switch:
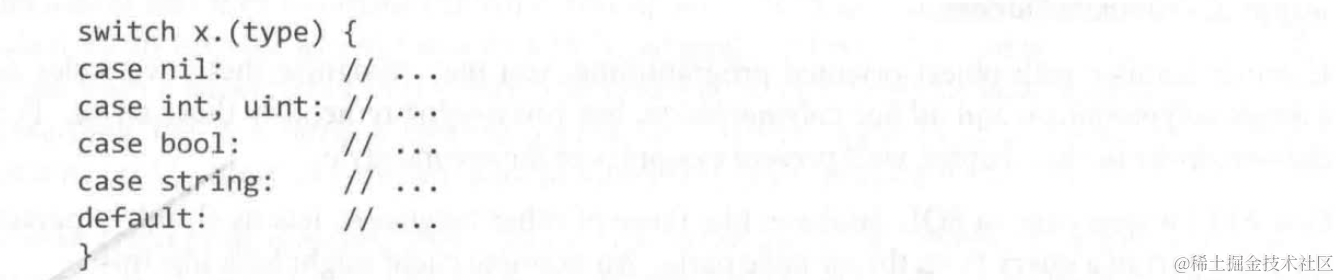
关于变量的复用(以x为例):

switch块内部的x与sqlQuote方法的参数x并不会发生冲突
7.11 使用interface的建议
不要为每个单独的实例去事先定义一个接口,接口的作用是抽象(二个或更多)
不一定要强行满足面向对象特性编码,有时独立的function和变量也是好的选择
八、goroutine和信道
8.1 goroutine
程序入口main方法称为main goroutine,当main方法结束return时,所有的子goroutine终止
携程与线程的行为很像,但是具体差别是由Go的语言层面的实现决定的,这也是Go能支持更高并发性能的原因所在,后续将进行更多讲解
8.2 示例:并发时钟服务器


Listen:IP地址和Port的监听
Accept:阻塞直到有客户端的请求连接
Conn:负责维护一个与客户端的连接(循环),并且在绝大多数情况下会由于client断开连接导致server端循环终止
此时时钟服务器是顺序提供服务的,如果有多个客户端同时请求服务,则同一时间只能有一个连接建立
使用go关键字开启goroutine则可以实现同时为多个客户端提供时间打印服务

8.3 channel 信道
作为goroutine之间的通信机制,用于携程之间传递各种类型的value(是引用类型的,但channel可以用==比较)
比如创建一个用于收发int类型的信道:
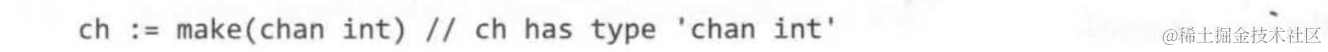
channel主要有两种操作方式:send和receive(一个goroutine为其存入value,另一个取出value,从而实现了跨goroutine通信的功能)

channel的第三种操作方式:close(ch)
对于关闭后的channel,不能在往里面放入value,会panic,但是如果去reveive则会将其取出,直到没有值在信道当中,则不断显示该type对应的零值
channel有两种创建方式:

unbuffered channel
对于无缓冲的信道,sent和receive是相互阻塞的,如果receive时信道中没有数据,则会阻塞,直到sent完成;相反,如果信道中已经有数据,则sent会被阻塞,直到receive完成
此时,sent和receive操作是同步的,通过这个机制可以实现控制程序执行的功能

此时main goroutine不会终止,直到子goroutine执行完成,为done存入值(有时值是重要的,有时存入值这个行为是重要的,上图是后者)。
判断channel是否关闭
如果是x := <-natural的写法,则natural在close之后,x会因为外循环for的原因不断取出natural的type的对应0值

可以通过range的方式遍历channel,并且在channel关闭时结束遍历(并且channel的close只有当其确实有必要通知下游的接受者这个关闭消息才使用,因为Go的垃圾回收机制会判断当一个变量不可达之后,对其采取回收,这与文件操作需要手动close不同)


单向channel
双向channel可以赋值给单向channel(隐式转换)

带缓冲的channel
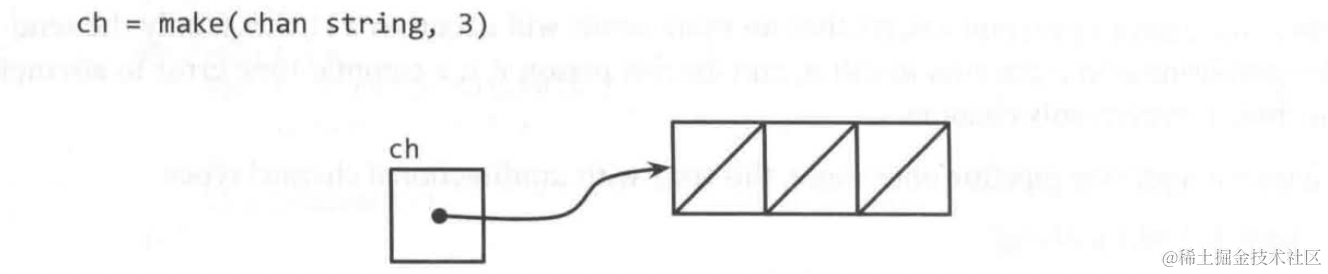
获取channel的缓冲长度

获取当前channel中缓冲的元素个数

总的来说,无缓冲的channel倾向于实现同步的通信;有缓冲的通信倾向于实现异步的通信
8.5 并行循环
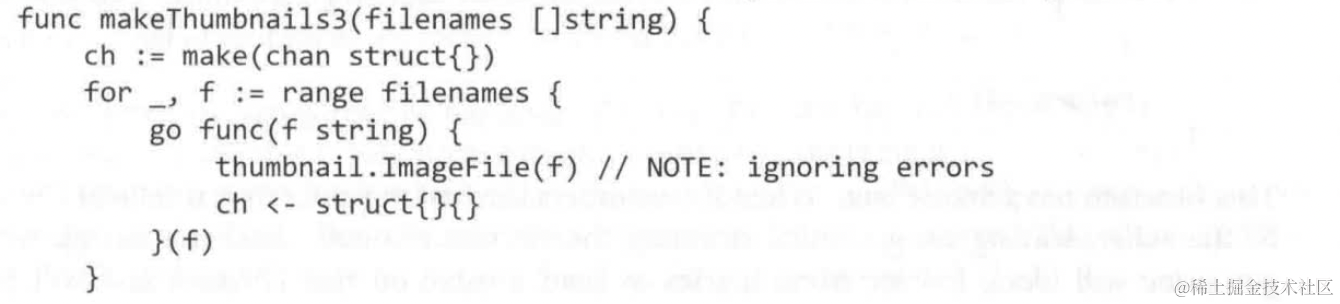

下面是一个goroutine泄漏的例子,当有一个非nil的error发生时,程序return error,但是与此同时相当数量的go协程因为errors信道里有信息,而无法存入,导致阻塞(因为消费信道信息的函数已经return了)
可能会导致程序的阻塞或者内存溢出
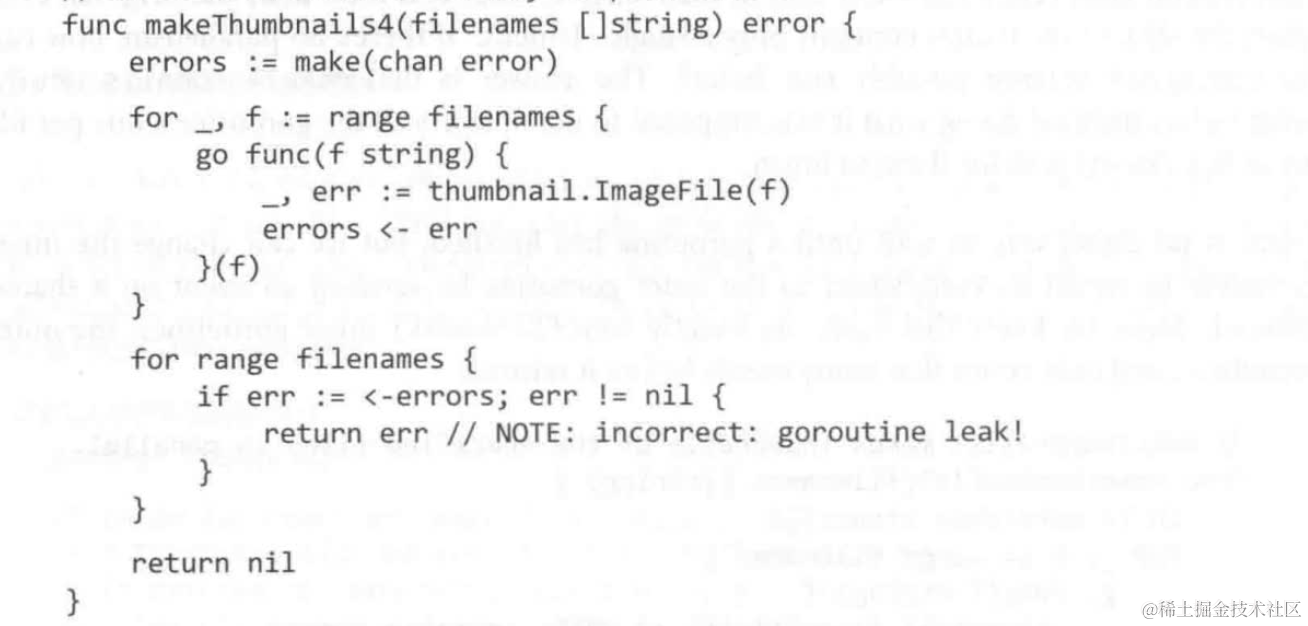
8.6 select多路复用

default是可选的,如果没有可以执行的case,则select会一直阻塞
如果有多个case同时可以执行,则select随机选择一个

小结
以上就是《The Go Programing Language》一至八章的讲解,希望能对你有所帮助。
感兴趣可以关注公众号 「白泽talk」,白泽目前也打算打造一个氛围良好的行业交流群,文章的更新也会提前预告,欢迎加入:622383022。








![[足式机器人]Part2 Dr. CAN学习笔记 - Ch02动态系统建模与分析](https://img-blog.csdnimg.cn/direct/630219cc3a314904ba754366a8add31b.png#pic_center)