一、损失函数
举个例子

比如说根据Loss提供的信息知道,解答题太弱了,需要多训练训练这个模块。
Loss作用:1.算实际输出和目标之间的差距
2.为我们更新输出提供一定的依据(反向传播)
看官方文档
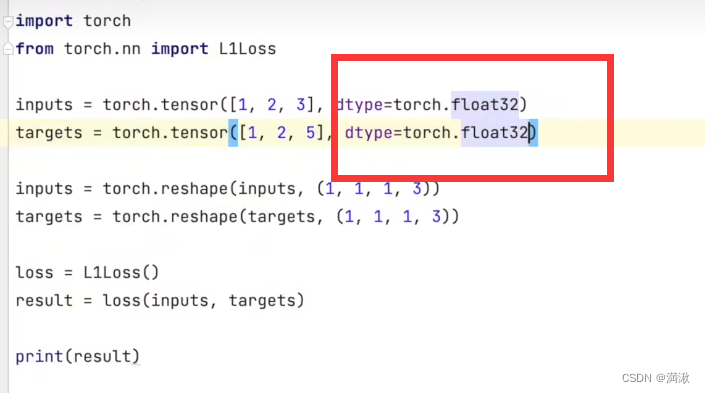
每个输入输出相减取平均取绝对值再取平均
第一个损失函数:L1Loss
(差的绝对值取平均)


需要注意输入输出

N=batch_size你有多少个数据
![]()
第一个损失函数:MSELoss
(平方差误差,平方取平均)



![]()
![]()
稳妥的写法是先引入nn,然后再找到MSEloss()这个方法,避免由于拼写出错而报错
二、交叉熵
算交叉熵一般都要soft-max的,和是1
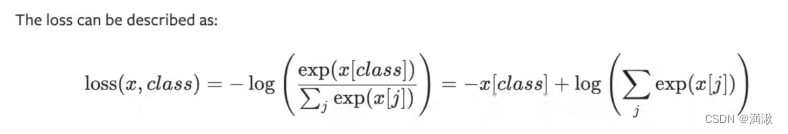
这里的-x[class],只对目标分类计算,这里的目标分类class=1,因此-x[class]=-0.2
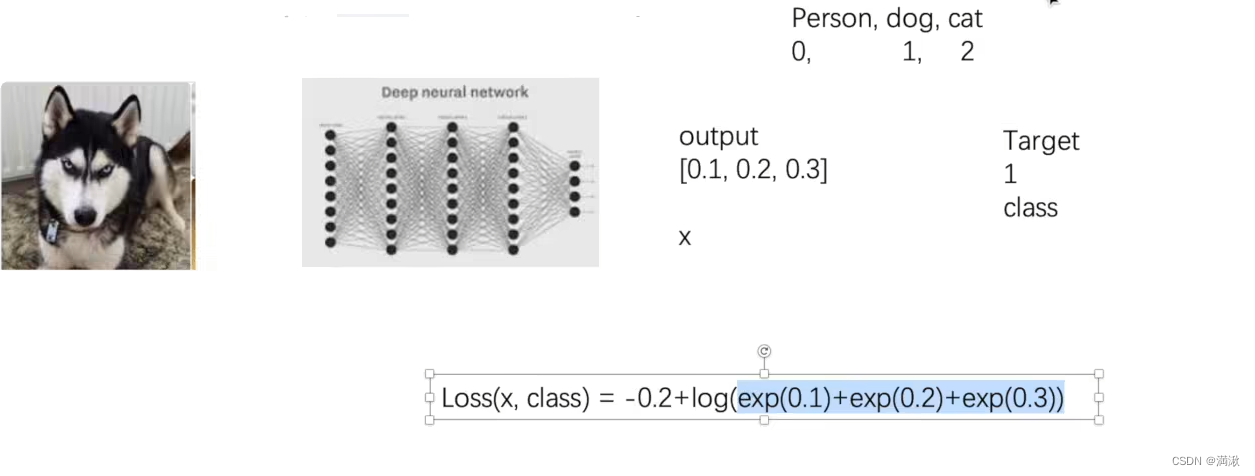
如果预测输出为[0.8,0.9,0.8]这种的预测概率很高又很接近的就不行,分类器的效果就不是很好。
 为了让这部分比较大,只有当output和Target完全命中的时候,这一项就比较大,就是会相匹配。
为了让这部分比较大,只有当output和Target完全命中的时候,这一项就比较大,就是会相匹配。

Target的N是要求多少个batchsize,如实际的对哈士奇的分类,类别有三个,但是每次输入的图片只有一个也就是batchsize等于1。
另外,还需要注意:
![]()
输入必须是没有处理过的对每一类的得分。
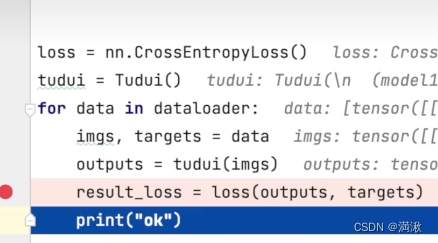
以代码为例:

![]()

三、反向传播
利用上一次的的网络来说明
1.计算实际输出和目标之间的差距
DataLoader这边就是一个数据的加载,加载的目标数据是dataset,输入的batch_size为64

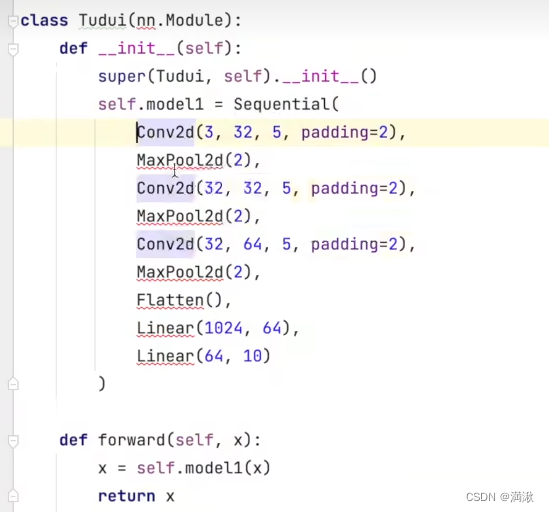

为了观察输出方便,将batch_size设置为1
图片输入进去有以下输出

target
![]()
分类问题可以用交叉熵误差

神经网络输出和真实输出的一个差距

2.为我们更新输出提供一定的一句(反向传播)
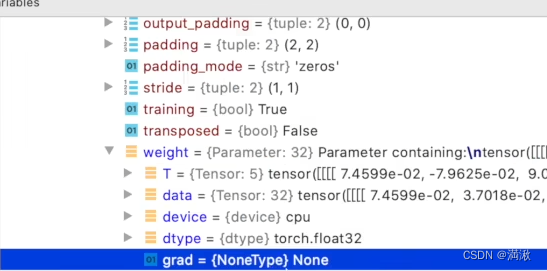
每个卷积的卷积核就需要调优的参数,给每个卷积核参数设置了一个grad(梯度),每一个节点(待更新参数)都会求出一个对应梯度,优化过程中针对这个梯度进行优化,最终实现整体loss最优。
以梯度下降法进行说明,
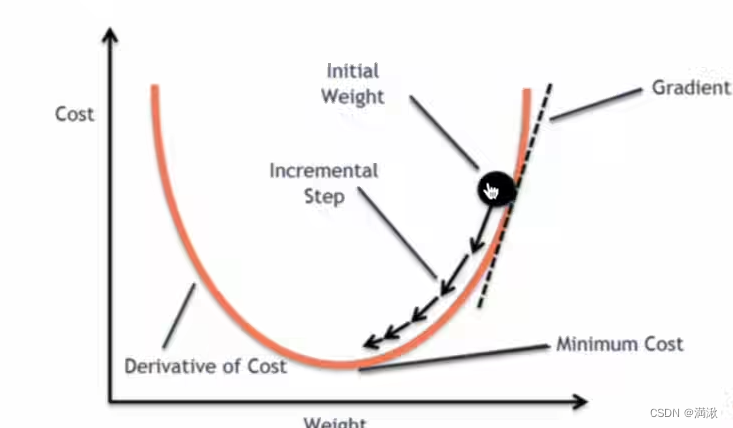


删除了反向传播之后,发现梯度不更新了








![[足式机器人]Part2 Dr. CAN学习笔记 - Ch02动态系统建模与分析](https://img-blog.csdnimg.cn/direct/630219cc3a314904ba754366a8add31b.png#pic_center)