前言
前面把shp文件中的内容读取到数据库,接下来就把数据库中的表变成shp文件。
正文
简单的创建一个shp文件
暂时不读取数据库的表,先随机创建一个shp文件。既然是随机的,这就需要使用到faker这个第三方库,代码如下。
import geopandas as gpd
from faker import Faker
from shapely.geometry import Polygon
def create_shp(shp_path):# 中文fake = Faker('zh_CN')geo_data = []for _ in range(100):# 随机生成经纬度latitude, longitude = fake.latitude(), fake.longitude()# 创建四个点,矩形points = [(float(longitude), float(latitude)),(float(longitude)+10, float(latitude)),(float(longitude)+10, float(latitude)+10),(float(longitude), float(latitude)+10)]# 创建一个Polygon对象polygon = Polygon(points)# 添加到列表geo_data.append({'geometry': polygon, 'name': fake.name(), 'address': fake.address().replace('\n', ', ')})# 创建GeoDataFrame对象gdf = gpd.GeoDataFrame(geo_data, crs="4326")gdf.to_file(shp_path,encoding='utf-8')运行代码
if __name__ == '__main__':create_shp('C:/Users/26644/Desktop/out/faker_data.shp')在桌面的out文件中生成faker_data.shp文件,如下图所示
查看数据
查看生成shp文件中的数据
用arcmap打开shp文件,添加一下属性,展示如下图所示。

查看一下属性表
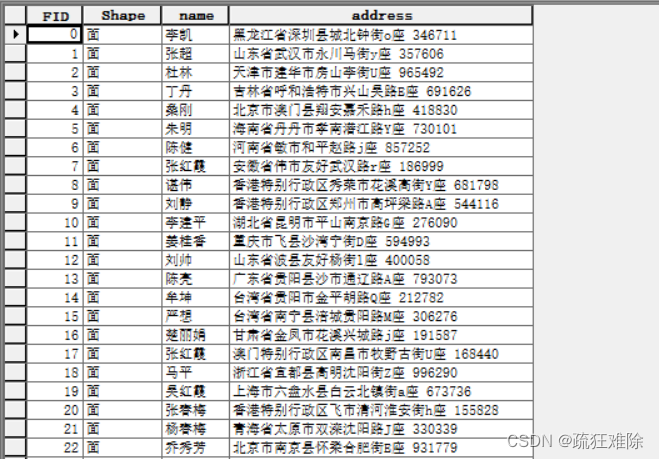
数据都是伪造的,如有雷同,请勿当真。当然全是面(POLYGON),字段或者类型,这些都是可以自己定义的,看个人需求,还是可以,有模有样的。
根据数据库创建shp文件
简单地读取表的数据
读取表中的数据,很明显,需要使用select语句,可以直接如下sql
select * from table就可以读取表中的全部信息,代码如下。
from sqlalchemy import create_engine,Table,select,MetaData
import geopandas as gpdengine = create_engine('postgresql+psycopg2://username:password@localhost/arcgis')
gdf = gpd.read_postgis('select * from cd', engine, geom_col='geometry')
gdf.to_file('C:/Users/26644/Desktop/out/成都.shp', encoding='utf-8')代码几行,结果如下。

可以看到除了FID,还有一个id字段,这个是表中的字段,这个其实看个人需要,因为arcmap为这个shp文件添加了FID,其实在创建表中就不需要主键id字段,通过geopandas读取shp创建表就没有id字段,有也没问题,看个人需要。
复杂地读取表中的数据
代码如下。
from sqlalchemy import create_engine, Table, MetaData, select
from geoalchemy2 import Geometry
import geopandas as gpd
from sqlalchemy.sql.base import ReadOnlyColumnCollection
from sqlalchemy.exc import NoSuchTableErrorengine = create_engine('postgresql+psycopg2://username:password@localhost/arcgis')
metadata = MetaData()class db2shp:def __init__(self,table_name,shp_path,has_id: bool = False,geom_type: str = 'geometry',):""":param table_name: 表名:param shp_path: shp文件路径:param has_id: shp是否包含id列,假设表中带有id:param geom: geometry的类型"""self.table_name = table_nameself.shp_path = shp_pathself.has_id = has_idself.geom_type = geom_typeself.__table: Table = Noneself.__columns: ReadOnlyColumnCollection = Noneself.__sql: str = Nonedef __get_table(self):"""获取表:return: """try:self.__table = Table(self.table_name, metadata, autoload_with=engine)except NoSuchTableError as e:print(e)def __get_column(self):"""获取列名:return: """if self.has_id:self.__columns = self.__table.columns.keys()else:self.__columns = self.__table.columns.keys()[1:]def __get_sql(self):"""获取sql语句:return: """self.__sql = select(*[getattr(self.__table.c, col) for col in self.__columns])def __get_data(self):"""获取数据:return: """with engine.connect() as connection:return gpd.read_postgis(self.__sql, connection, geom_col=self.geom_type)def get_shp(self):"""获取shp文件:return: """self.__set()data = self.__get_data()data.to_file(self.shp_path, encoding='utf-8')def __set(self):"""设置属性:return: """self.__get_table()self.__get_column()self.__get_sql()考虑是否需要读取id字段,当然,假设表有id字段。如果表本身没有id字段,代码肯定有所不同。
运行上面代码。
convert = db2shp('cd', 'C:/Users/26644/Desktop/out/成都_1.shp')
convert.get_shp()
结果如下。
打开属性表

可以看到和下载的成都.shp的数据一样,字段也可以查看一下。

shp文件转json
代码如下。
import geopandas as gpd# 读取.shp文件
gdf = gpd.read_file('C:/Users/26644/Desktop/out/成都_1.shp')# 转为GeoJSON格式
gdf.to_file('cd.json', driver='GeoJSON')结果如下。
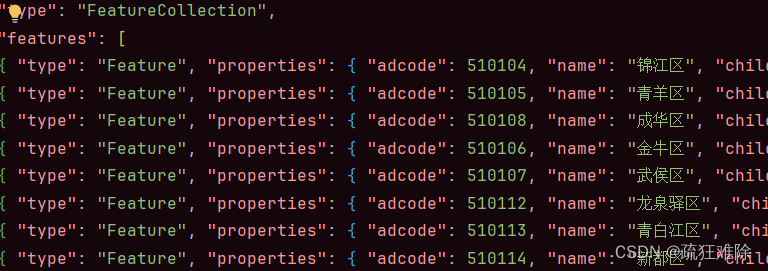
完成。