当前版本:
- Python 3.8.4
简介
列表(list)是Python编程语言中的基本数据类型之一,也是一个非常重要的通用序列。在其它编程语言中,它们通常被称为“数组”。可以存储多个元素,包括数字、字符串、甚至其他列表,是最常用的数据类型之一。
这篇文章主要介绍列表的各种处理方式和应用方法。
文章目录如下
1. 如何定义列表
2. 处理列表的方式
2.1. 统计元素
2.2. 添加元素
2.3. 修改元素
2.4. 删除元素
2.5. 索引取值
2.6. 拷贝方式
3. 列表的应用方法
3.1. 迭代循环
3.2. 数据处理
3.3. 实现缓存
3.4. 数据结构算法
① 线性搜索
② 二分搜索
③ 排序算法
1. 如何定义列表
列表可以使用两个方式定义:
l = [] # 定义一个空列表
l = list() # 定义一个空列表列表用方括号 [ ] 来表示,左括号开始,右括号结束。括号中的数据称为元素,这些元素以逗号分割,可以是数字、字符串,或者列表。
# 定义一个列表,包含数字、字符串和列表
l = [123 ,'AAA', [10, 20]]
在定义列表式时,除了手动去固定写入元素外,还可以使用迭代来定义:
l = [x for x in range(1, 6)]
- 将函数的返回值或结果赋值给列表也是同理。
那么列表的作用是什么呢?
比如某个项目需要一个自动化框架,将需要处理的内容写到 Excel 文件中,再通过这个框架去读取文件内容,那么列表可以作为临时存储空间,将其保存到内部后开始操作:
# 将文件名放入列表中
file = ['file1.xlsx', 'file2.xlsx', 'file3.xlsx']# 遍历这个列表中的文件名
for f in file:print(f"开始执行项目,处理文件:{f}")'''省略处理文件的代码'''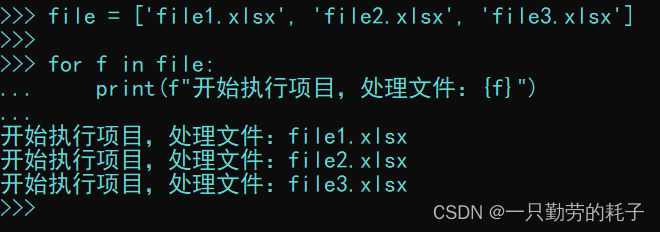
- 列表的各种应用方法见《目录3》
2. 处理列表的方式
列表的主要处理方法包括:增删改查、索引取值、深拷贝和浅拷贝的区别,下面按章节逐个介绍。
2.1. 统计元素
在列表中,用逗号分割的字符被称为元素,比如:
l = [ 100, 200, 'AAA', 'BBB' ]这里面包含4个元素,这四个元素分别是100、200、AAA、BBB。与字符串不同,字符串是按单个字符统计,列表是按分隔符统计。
例:获取第2个元素
l = [ 100, 200, 'AAA', 'BBB' ]
print(l[1])直接通过索引即可(索引的具体用法见《目录 2.5》)

统计元素的方法如下:
- len:统计元素个数
- count:统计某个元素出现的次数
- max:统计最大的数值
- min:统计最小的数值
- sort:数字升序排序
- sorted:数字升序或降序排序
- reverse:元素反转
【方式一】统计元素的个数 len
l = [ 100, 200, 'AAA', 'BBB' ]
len(l)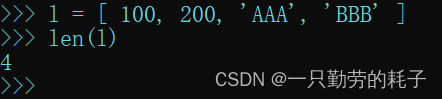
【方式二】统计某个元素出现的个数 count
l = [ 100, 200, 'AAA', 'BBB' ]
l.count("A")
- 注意:count的查看元素的个数,而不是单个字符的个数
【方式三】查询最大值 max(仅支持数字)
L = [3, 43, 2, 98]
max(L)
【方式四】查询最小值 min(仅支持数字)
L = [3, 43, 2, 98]
min(L)
【方式五】升序 sort、sorted(仅支持数字)
L1 = [4, 1, 9]
L1.sort()L2 = [5, 3, 7]
L2 = sorted(L2, reverse=False)
【方式六】降序 sorted(仅支持数字)
L = [5, 3, 7]
L = sorted(L, reverse=True)
【方式七】元素反转 reverse
L = [ 100, 200, 'AAA', 'BBB' ]
L.reverse()
2.2. 添加元素
列表可以通过索引指定位置添加元素,也可以直接向列表最后面追加元素。
- insert:按索引添加
- append:在列表后面追加1个元素
- extend:在列表后面追加多个元素
【方式一】指定索引添加元素 insert
'''方法1'''
L = [ 100, 200, 'AAA', 'BBB' ]
L.insert(0, 500) # 在索引为0处添加元素'''方法2'''
L = [ 100, 200, 'AAA', 'BBB' ]
L[0:0] = [500] # 在索引为0处添加元素
在索引为1处添加多个元素
L = [ 100, 200, 'AAA', 'BBB' ]
L[1:1] = [500, 'EEE'] # 在索引为1处添加元素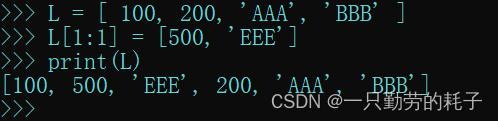
【方式二】在列表后面追加元素 append
L = [1, 2, 3]
L.append('AAA')
append 不支持追加多个元素,但可以使用符号 +
L = [1, 2, 3]
L = L + ['AAA', 'BBB']
【方式三】追加多个元素 extend
L = [1, 2, 3]
L.extend(('a', 'b', 10)) # 需要使用一个括号
直接迭代添加整数
L = ['A', 'B', 'C']
L.extend(range(10,15)) # 使用range迭代
2.3. 修改元素
python 一般利用索引来修改元素
【方式一】按索引修改单个元素
L = ['A', 'B', 'C', 'D', 'E']
L[0] = 10 # 修改第1个元素
L[-1] = 20 # 修改最后1个元素
【方式二】按索引修改多个元素
L = ['A', 'B', 'C', 'D', 'E']
L[:3] = [10, 20] # 将前3个元素修改为2个元素
【方式三】迭代修改指定的元素名
L = [100, 'BBB', 'AAA', 'BBB', 'BBB']
# 用迭代的方式将BBB修改为EEE
new_L = [elem if elem != 'BBB' else 'EEE' for elem in L]
2.4. 删除元素
python 支持通过索引删除和元素名删除
【方式一】按索引删除元素 del、pop
L = ['A', 'B', 'C', 'D', 'E']# del支持删除多个元素
del L[0]
del L[:3]# pop只支持删除一个元素
L.pop(0) # 删除第一个元素
【方式二】按元素名删除 remove
L = ['A', 'B', 'C', 'B', 'D']
L.remove('B') # 仅支持删除1个元素
【方式三】按元素名删除多个元素(迭代)
L = ['A', 'B', 'C', 'B', 'D']
d = ['A', 'B'] # 需要删除的元素列表
new_L = [elem for elem in L if elem not in d] # 迭代删除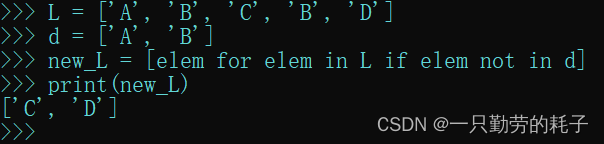
【方式四】按索引删除多个元素(迭代)
del_index=[0, 1, 2] #指定要删除的索引下标,不能使用负数(-1)
L1 = ['a', 'b', 'c', 'd', 'e']
L2=[i for num,i in enumerate(L1) if num not in del_index]
2.5. 索引取值
索引(Index)是用于标识和访问数据结构中元素的位置或标签,在Python中,索引用于访问字符串、列表、元组和其他序列类型的元素。
索引的值从0开始
元素:a b c d e f
索引:0 1 2 3 4 5- 第1个元素的索引为0,第2个元素的索引为1,以此类推。。。
读取对应索引的值使用 变量[ ] 的方式
L = ['a', 'b', 'c', 'd', 'e']
L[0] # 读取第1个元素
L[3] # 读取第4个元素
L[-1] # 读取最后1个元素
除了读取单个元素,还能通过切片的方式范围读取
变量[起始索引:结束索引]L = ['a', 'b', 'c', 'd', 'e']
L[:2] # 读取前2个元素
L[-2:] # 读取后2个元素
L[1:3] # 读取索引为1~2的元素
- 第1个元素用0表示,最后1个元素用-1表示。
- 范围读取时冒号前面为空(默认读取前面全部),冒号后面为空(默认读取后面全部)。
- 范围取值时不包括结束索引。[1:3] 表示读取索引1,2;[3:6] 表示读取索引3,4,5。
切片时支持指定步长
变量[起始索引:结束索引:步长] # 步长默认1L = ['a', 'b', 'c', 'd', 'e']
L[1::1] # 读取索引为1和后面的元素,步长为1
L[1::2] # 读取索引为1和后面的元素,步长为2
L[::2] # 读取全部元素,步长为2
2.6. 拷贝方式
python 支持深拷贝和浅拷贝两种方式。
- 深拷贝复制对象及其子对象本身,递归地复制整个对象结构。改变原始对象中的子对象不会影响到深拷贝后的对象。
- 浅拷贝仅复制对象的引用,而不复制子对象本身。改变原始对象中的子对象也会影响到浅拷贝后的对象。
它们各自的优点
- 深拷贝的优点是创建了一个全新的独立对象,可以对深拷贝后的对象进行修改,而不会影响到原始对象。深拷贝通常用于需要独立副本的场景,特别是在进行递归操作或修改子对象时。
- 浅拷贝的优点是速度较快,因为它仅复制引用而不进行实际的复制操作。如果原始对象的子对象较大而且不会被修改,那么浅拷贝可以节省大量的内存。
他们各自的缺点
- 深拷贝的缺点:它可能会消耗更多的内存和处理时间,特别是当要复制的对象结构较大、嵌套层级较深时。进行深拷贝可能需要递归地复制整个对象,这可能会导致性能下降。
- 浅拷贝的缺点:如果原始对象中的子对象是可变的,那么改变原始对象中的子对象也会影响到浅拷贝后的对象,可能会导致意外的副作用。
定义一个深拷贝需要导入标准库 copy
# 导入标准库
import copy# 定义一个列表a
a = [1, 2, 3, [4, 5]]# 将列表a的值深拷贝到b
b = copy.deepcopy(a)
浅拷贝可以使用 copy() 函数实现,或者直接赋值
# 方式一
a = [1, 2, 3, [4, 5]]
b = a.copy()# 方式二
a = [1, 2, 3, [4, 5]]
b = [a, "BBB"]

注意:修改原始列表,浅拷贝过去的列表不会发生变化
a = [1, 2, 3, [4, 5]]
b = a.copy()
对于浅拷贝,它仅仅是复制了列表对象的引用,所以当你改变原始列表(例如修改索引为0的值)时,只有原始列表受到影响,而副本不会受到影响。也就是说只有改变子对象,浅拷贝的值才会发生变化。
3. 列表的应用方法
3.1. 迭代循环
迭代循环是列表惯用的方式,比如直接循环列表中的元素
L = [1, 2, 3, [4, 5]]
for i in L:print(f"当前元素为:{i}")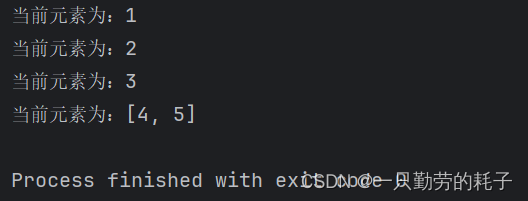
除了直接遍历元素,还能遍历该元素的索引 enumerate
# 定义列表
L = ['AAA', 'BBB', 'CCC']# 遍历列表中的索引和元素
for index,element in enumerate(L):print(f"索引:{index}, 元素:{element}")
索引的起始值为0,所以默认从0开始。如果业务有其他需求,我们还可以指定从1开始
# 定义列表
L = ['AAA', 'BBB', 'CCC']# 遍历列表中的索引和元素
for index,element in enumerate(L, start=1):print(f"索引:{index}, 元素:{element}")
3.2. 数据处理
我们时常使用列表来存储和操作数据集,不少操作中需要进行排序、过滤、计算等操作,介绍几种方法:
【方式一】列表排序(元素仅支持数字)
L = [4, 2, 1, 3, 5]
L.sort() # 升序
L = sorted(L, reverse=False) # 升序
L = sorted(L, reverse=True) # 降序
L.reverse() # 反转
【方式二】过滤列表(筛选偶数)
# 定义一个全数字的列表
L = [1, 2, 3, 4, 5]
# 过滤偶数
L_new = list(filter(lambda x: x % 2 == 0, L))
【方式三】计算列表的值
# 定义一个全是数字的列表
L = [1, 2, 6, 8, 5, 10]# 求和
sum_result = sum(L)# 求最大值
max_result = max(L)# 求最小值
min_result = min(L)# 求平均值
avg_result = sum(L) / len(L)# 所有值乘以 10
multiplied_list = [x * 10 for x in L]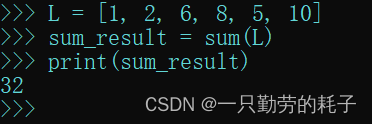
3.3. 实现缓存
列表的可变性使其适用于实现缓存机制,可以存储临时的计算结果或其他需要快速访问的数据。
# 封装一个使用列表缓存的类
class ListCache:def __init__(self, max_size):self.max_size = max_size # 缓存的最大容量self.cache = [] # 定义一个空的缓存列表def get(self, key):'''检查是否有对应的缓存项'''for item in self.cache:if item['key'] == key:return item['value']return Nonedef set(self, key, value):'''判断缓存是否已满'''if len(self.cache) >= self.max_size:self.cache.pop(0) # FIFO方式移除最旧的缓存项# 使用字典的方式添加新的缓存项self.cache.append({'key': key, 'value': value})if __name__ == '__main__':# 创建一个最大容量为 2 的缓存LC = ListCache(2)# 向方法中添加两个缓存数据LC.set('k1', 'AAA')LC.set('k2', 'BBB')# 查看结果print(LC.get('k1')) # AAAprint(LC.get('k2')) # BBB# 向方法中添加第3个缓存数据LC.set('k3', 'CCC')print(LC.get('k1')) # 此时的k1已经被清理
3.4. 数据结构算法
列表是一种常见的数据结构,它可以存储多个元素,并且元素的顺序是有序的。这里列举几种常见的算法
① 线性搜索
- 线性搜索的方式是从列表的起始位置开始逐个比较元素,直到找到目标元素或遍历完整个列表
代码如下
# 定义一个列表
arr = [4, 2, 7, 1, 9, 5]
# 需要查找的值
target = 7def linear_search(arr, target):# 遍历该数组的长度for i in range(len(arr)):# 通过索引来判断这个值是否为真if arr[i] == target:return i # 返回目标元素的索引return -1 # 如果目标元素不存在于列表中,返回 -1# 传入列表和需要查找的值
index = linear_search(arr, target)
print(f"元素{target}的索引为:{index}")
② 二分搜索
-
二分搜索要求列表是有序的。通过将列表分成两半并与中间元素进行比较,以确定目标元素位于哪一半,然后再在该半中进行搜索。该算法的时间复杂度为 O(log n),比线性搜索更高效。
代码如下
# 定义一个列表
arr = [1, 12, 4, 6, 7, 3]
# 需要查询的值
target = 7def binary_search(arr, target):arr.sort() # 先将数组排序(升序)low = 0 # 定义最小索引high = len(arr) - 1 # 定义最大索引while low <= high:mid = (low + high) // 2 # 取中间索引的值(整数)if arr[mid] == target: # 判断是否该索引的值等于targetreturn mid # 为真,返回目标元素的索引elif arr[mid] < target:low = mid + 1 # 如果结果小于target,将索引+1else:high = mid - 1 # 如果结果大于target,将索引-1return -1 # 如果目标元素不存在于列表中,返回 -1# 向函数中传入列表和需要查找的值
index = binary_search(arr, target)
print("目标元素的索引:", index)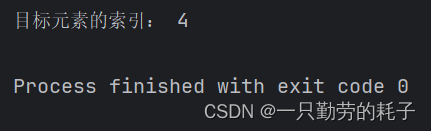
③ 排序算法
冒泡排序
arr = [4, 2, 7, 1, 9, 5]def bubble_sort(arr):n = len(arr)for i in range(n):for j in range(0, n-i-1):if arr[j] > arr[j+1]:arr[j], arr[j+1] = arr[j+1], arr[j]return arrsorted_arr = bubble_sort(arr)
print("排序后的列表:", sorted_arr)
插入排序
arr = [4, 2, 7, 1, 9, 5]def insertion_sort(arr):n = len(arr)for i in range(1, n):key = arr[i]j = i - 1while j >= 0 and arr[j] > key:arr[j+1] = arr[j]j -= 1arr[j+1] = keyreturn arrsorted_arr = insertion_sort(arr)
print("排序后的列表:", sorted_arr)
选择排序
arr = [4, 2, 7, 1, 9, 5]def selection_sort(arr):n = len(arr)for i in range(n-1):min_index = ifor j in range(i+1, n):if arr[j] < arr[min_index]:min_index = jarr[i], arr[min_index] = arr[min_index], arr[i]return arrsorted_arr = selection_sort(arr)
print("排序后的列表:", sorted_arr)
快速排序
arr = [4, 2, 7, 1, 9, 5]def quick_sort(arr):if len(arr) <= 1:return arrpivot = arr[0]less = [x for x in arr[1:] if x <= pivot]greater = [x for x in arr[1:] if x > pivot]return quick_sort(less) + [pivot] + quick_sort(greater)sorted_arr = quick_sort(arr)
print("排序后的列表:", sorted_arr)
归并排序
arr = [4, 2, 7, 1, 9, 5]def merge_sort(arr):if len(arr) <= 1:return arrmid = len(arr) // 2left_half = arr[:mid]right_half = arr[mid:]left_half = merge_sort(left_half)right_half = merge_sort(right_half)return merge(left_half, right_half)def merge(left, right):result = []i, j = 0, 0while i < len(left) and j < len(right):if left[i] < right[j]:result.append(left[i])i += 1else:result.append(right[j])j += 1result.extend(left[i:])result.extend(right[j:])return resultsorted_arr = merge_sort(arr)