让我们先从加利福尼亚州的房价说起
如果没有接触过机器学习,需要先进行环境配置
在每次开始之前都需要先运行以下代码,不报错方可继续
# Python 的版本需要大于3.5
import sys
assert sys.version_info >= (3, 5)# Scikit-Learn的版本需要大于0.20
import sklearn
assert sklearn.__version__ >= "0.20"import numpy as np
import os#绘图设置
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rc('axes', labelsize=14)
mpl.rc('xtick', labelsize=12)
mpl.rc('ytick', labelsize=12)
在python中 ,import 表示要用到别人写的代码,比如上边代码块的第一个import ,import sys,就表示要用到别人写的sys
假设我们现在是XX地产加利福尼亚州分公司的房价分析师,老板打算找个地区投资一块地,让我们分析并预测加利福尼亚各地区的房价,老板好决定投资哪一块地
传统的分析方法需要有一个团队,对各地区的房屋信息进行分析,比较复杂,但是如果运用机器学习的方法,咱们只需要一个人就够了
了解数据
假设负责数据收集的同事已经将收集好的一些地区房价数据打包上传好了,让我们下载下来
# 本块代码现在无需理解,复制粘贴执行即可
import os
import tarfile
import urllib.requestDOWNLOAD_ROOT = "https://gitee.com/yang-yizhou/dayangai/raw/master/"
HOUSING_PATH = os.path.join("datasets", "housing")
HOUSING_URL = DOWNLOAD_ROOT + "datasets/housing/housing.tgz"def fetch_housing_data(housing_url=HOUSING_URL, housing_path=HOUSING_PATH):if not os.path.isdir(housing_path):os.makedirs(housing_path)tgz_path = os.path.join(housing_path, "housing.tgz")opener = urllib.request.URLopener()opener.addheader('User-Agent', 'whatever')opener.retrieve(housing_url, tgz_path)housing_tgz = tarfile.open(tgz_path)housing_tgz.extractall(path=housing_path)housing_tgz.close()
运行定义好的函数来下载
#报错就多运行几次
fetch_housing_data()
再定义加载数据的函数
# 本块代码现在无需理解,复制粘贴执行即可
import pandas as pddef load_housing_data(housing_path=HOUSING_PATH):csv_path = os.path.join(housing_path, "housing.csv")return pd.read_csv(csv_path)
用定义好的函数加载数据
housing = load_housing_data()
这样,我们同事收集来的数据已经放在了housing中,我们来看一下housing的类型
type(housing)
输出:pandas.core.frame.DataFrame
housing是个DataFrame,译作数据集,对这个数据集我们可以通过“.”这个符号进行很多操作,比如
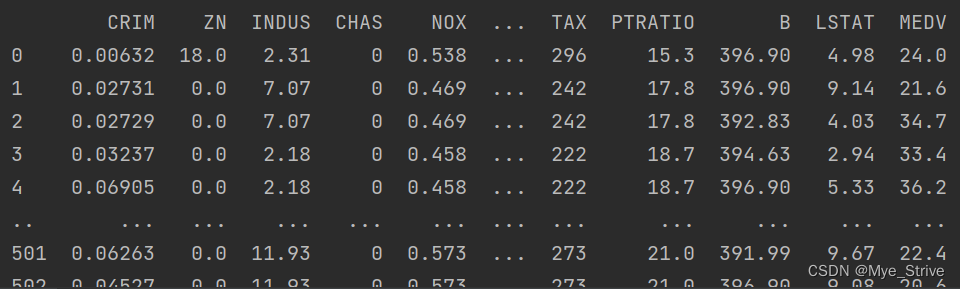
housing.head()
输出:

这样就输出了数据集上边(头部,head)的五个数据
可以看到,事无巨细,我们的同事把加州各个地区诸如房屋的均价,经纬度,距离海洋远近,总的房间数,人口等数据都收集到了,每一列我们称作一个特征(feature)
非常好!
但我们还得检查一下有无缺漏
housing.info()
输出:

看完housing的infomation,我们发现事情并不总是尽善尽美,housing这个数据集有两个问题
第一点:4号特征total_bedrooms只有20433个 non-null(数据存在),那就意味着还有207个数据是缺失的。
第二点:9号特征ocean_proximity ,dtype(类型)是object(不是数字),那我们就不能直接用机器学习的模型进行处理。
这两个问题是我们在了解数据部分发现的,暂且按下不表,我们会在数据处理的部分解决掉它们
房价的预测明显和地理位置有着紧密的联系,我们不妨用经纬度来作图,每一个点代表一个统计好的地区,看看地理分布
housing.plot(kind="scatter", x="longitude", y="latitude")
输出:

不太直观,试试用alpha修改下每个点的透明度
housing.plot(kind="scatter", x="longitude", y="latitude", alpha=0.1)
输出:

有门儿!统计的地区更多的集中在加州西南部,再进一步,把房屋均价用每个点的颜色来显示,越红表示房价越高
# 本代码块的每个参数可以根据单词意思作调整,看看输出效果,以便加深理解
housing.plot(kind="scatter", x="longitude", y="latitude", alpha=0.4, figsize=(10,7),c="median_house_value", cmap=plt.get_cmap("jet")
)
输出:

看起来西南部不但有更多的统计地区,房价也要更高,我们再进一步,把加州的地图也搬过来!
看看到底是怎么回事
# 本块代码现在无需理解,复制粘贴执行即可
PROJECT_ROOT_DIR = "."
images_path = os.path.join(PROJECT_ROOT_DIR, "images", "housing")
os.makedirs(images_path, exist_ok=True)
DOWNLOAD_ROOT = "https://gitee.com/yang-yizhou/dayangai/raw/master/"
filename = "california.png"
print("Downloading", filename)
url = DOWNLOAD_ROOT + "images/housing/" + filename
opener = urllib.request.URLopener()
opener.addheader('User-Agent', 'whatever')
opener.retrieve(url,os.path.join(images_path, filename))
# 本块代码现在无需理解,复制粘贴执行即可
import matplotlib.image as mpimg
california_img=mpimg.imread(os.path.join(images_path, filename))
ax = housing.plot(kind="scatter", x="longitude", y="latitude", figsize=(10,7),s=housing['population']/100, label="Population",c="median_house_value", cmap=plt.get_cmap("jet"),colorbar=False, alpha=0.4)
plt.imshow(california_img, extent=[-124.55, -113.80, 32.45, 42.05], alpha=0.5,cmap=plt.get_cmap("jet"))
plt.ylabel("Latitude", fontsize=14)
plt.xlabel("Longitude", fontsize=14)prices = housing["median_house_value"]
tick_values = np.linspace(prices.min(), prices.max(), 11)
cbar = plt.colorbar(ticks=tick_values/prices.max())
cbar.ax.set_yticklabels(["$%dk"%(round(v/1000)) for v in tick_values], fontsize=14)
cbar.set_label('Median House Value', fontsize=16)plt.legend(fontsize=16)
plt.show()
输出:

原来如此,加利福尼亚州的高价值住房大多集中于沿海,而我们负责统计的同事也更倾向于统计这些人口稠密的地区,这也符合我们的一般认知,把这个特征记录下来,也许会用得上
好,我们现在已经对数据有了初步的认识,可以开始处理数据了
加州房价篇 (二) : 处理数据
对应源码(需下载后查看)
对应视频
原文章地址
转载请注明出处