随着云原生概念的深入普及和应用落地,企业应用架构由单体架构演进为微服务架构,应用将状态剥离到中间件层,通过无状态化实现更灵活的容器化部署和水平伸缩。然而,引入微服务框架、Kubernetes、分布式中间件等组件,使得系统变得复杂且“黑盒化”;被监控对象多样化程度倍增,监控对象数量也呈指数级增长;同时业务在线化使得企业更加关注系统可观测性,故障预警和恢复实时性诉求逐步提升,监控的实时性要求已从分钟级提高至秒级。
对于一个企业级的监控平台,要服务于不同的商业客户,客户的系统规模有不同的级别。一个典型的运营商BOSS系统项目,项目的规模一般会有500+左右的虚机,2500+左右的容器实例,每个业务产品大概会有3-5个核心业务指标。对于主机和容器,一般会要求30秒左右的采集频度;对于核心业务指标,需要实现秒级监控。
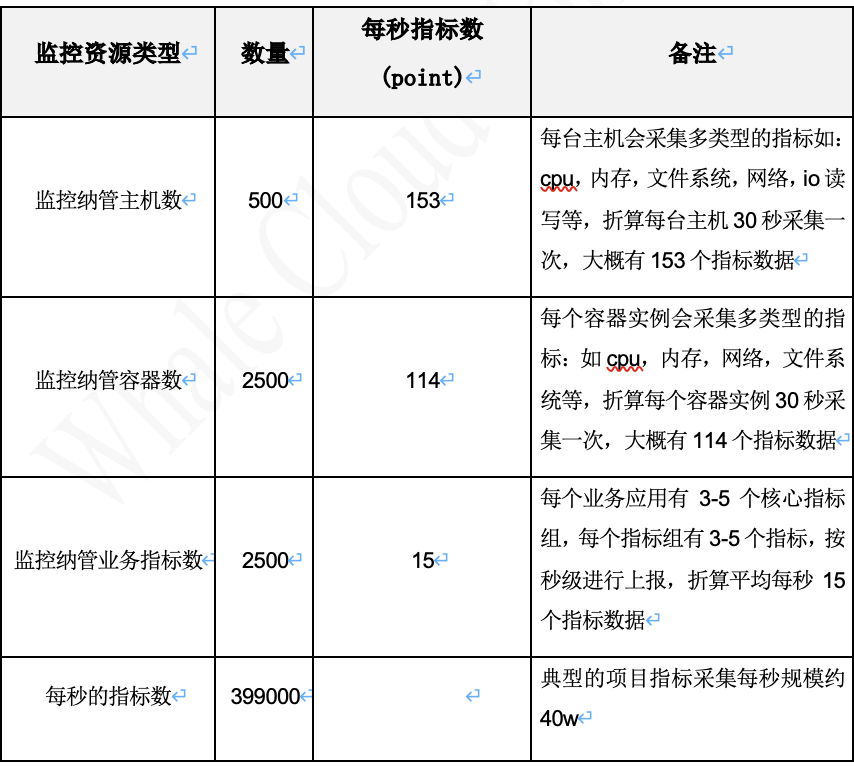
从上面的数据计算分析可以看出,要满足常规业务生产运维支撑时的持续可观测诉求,首先需要具备百万级指标处理能力。具体包括如下三个方面:
- 具备海量指标实时采集的能力
-
海量指标实时采集是必要条件,指标采集管理模块要能够实时采集海量的监控对接指标数据,采集服务端要具备水平扩展的能力。
-
低成本,高效的对接各类监控对象也是采集管理模块重点考量的条件之一。
- 具备指标秒级计算的能力
实时计算框架首先应具备海量指标的秒级处理能力,随着业务规模的扩大,系统需要能够快速而准确地处理大量的实时数据。为了应对用户告警场景中的多样化需求,包括同比昨天、同比上周或同比上个月等计算规则,实时计算框架必须具备批式处理的能力,以有效规避内存占用可能出现的问题。
复杂的实时计算规则通常伴随着较高的使用成本,因此实时计算框架在规则配置方面需要提供更低的接入门槛,以降低用户的配置和维护成本,使其更易于自定义处理规则。
构建存算分离的架构亦是关键,尤其在极端情况下,即使指标存储系统出现异常,也不能对指标的实时计算造成影响。这种存算分离的设计能够保障实时计算的稳定性和可靠性。
- 具备毫秒级延迟的指标读写能力
实现指标存储的高实时性是首要任务,确保能够达到毫秒级的延迟,以满足对实时性要求极高的业务场景。存储效能的高效性同样至关重要,尤其在处理海量指标数据的情境下,指标存储服务需要具备出色的性能,以确保快速而可靠地存储大量数据。
为了应对用户对指标数据的实时查询需求,指标存储服务必须能够提供秒级响应,确保用户能够及时获取最新的数据并进行分析。在满足企业级容灾管理需求方面,指标存储架构应具备多副本的能力,以确保数据备份和容灾,从而提高整体系统的稳定性和可用性。
01 单一开源产品的端到端解决方案
目前业界完备的单一开源监控平台端到端解决方案,比较流行的有Zabbix和Prometheus监控解决方案,它们提供了一体化的监控告警能力,具备采集、计算、存储和告警能力。
对于Zabbix,是一个比较传统的监控管理平台,在设备监控方面具备比较成熟和完备的对接流程,但在面向大规模的指标流量需求上有一些不足:对于指标存储,zabbix标准版本指标存储默认还存储在关系型数据库mysql中。同时在采集领域,当前的云原生组件优先默认支持prometheus,zabbix的开源插件存在一定的滞后以及定制化成本。
原生的 Prometheus 并不支持高可用,也不能做横向扩缩容,当集群规模较大时,单一 Prometheus 会出现性能瓶颈。同时Prometheus 告警规则是基于文件的管理模式,用户使用门槛较高。当前虽然Thanos已经具备了prometheus集群管理的方案,但依然无法解决prometheus单一性能和运维难度高等问题。
综上所述,不管是面对海量指标处理,还是在运维管理复杂度,二者都无法满足企业级的商用监控诉求。
02 开源+自研的融合解决方案
当前业界监控平台建设的主流思路是基于开源产品的能力,结合自身面对的场景进行改进和优化,以构建更贴近自身业务场景的技术解决方案。这类平台方案通常使用时序数据库(如InfluxDB、OpenTSDB、VictoriaMetrics、Prometheus)与流式计算框架(如Flink、Spark、Kapacitor、Prometheus)相结合,以满足对超大规模项目的监控处理需求。
浩鲸科技监控平台解决方案也是这种建设思路,监控平台功能架构如下:
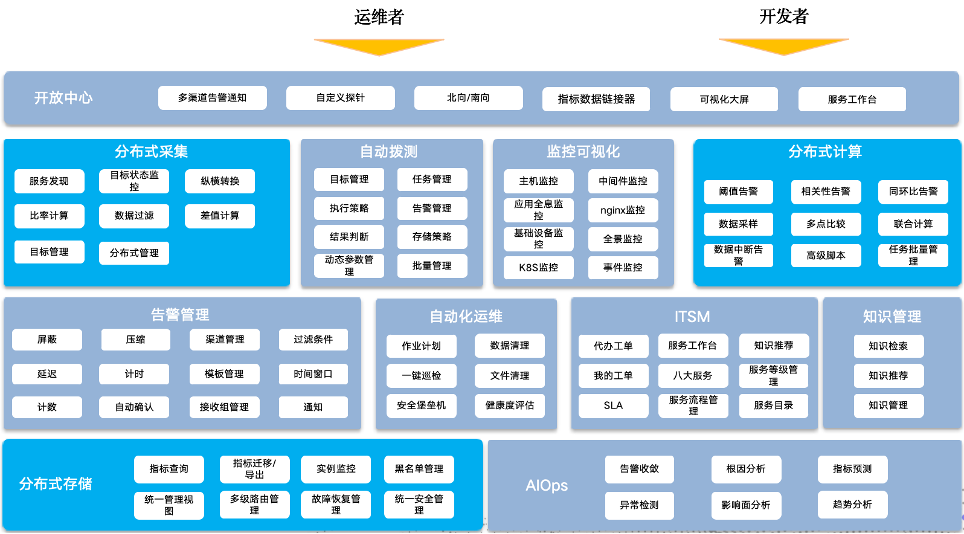
百万级指标采集、处理平台的改进和优化,重点要在指标采集、指标存储和指标计算三个方面。
>>>>遵从OpenMetrics标准协议自建分布式采集服务
在OpenMetrics协议下,业界普遍采用 Prometheus 作为采集服务的事实标准,在业界绝大多数的可观测平台中,Prometheus 是充当了生态适配和采集组件服务端的角色。但作为采集组件服务端,原生 Prometheus 存在以下劣势:
-
Prometheus 作为采集服务,原生的 prometheus-remote 模块,具备数据远端写的能力,但资源消耗较大。
-
目标的管理载体是本地文件或者依赖于 consul 服务发现组件,要么不易与第三方系统集成,要么要引入新的组件,增大复杂度。
-
缺乏足够的中间计算的能力,OpenMetrics 协议下,指标数据类型包括counter,guage等多种。如cpu使用率指标为 count 类型的时间累计值,原始值对用户不可读;同时一个指标组中只有一个指标,还是以 cpu 指标举例,对于 cpu 指标,就有 system、idle、wait、user 等指标;用户想要了解主机 cpu 性能状态,要查询每个指标组。
为解决这些问题,分布式采集服务(nms-prometheus-scraper)应运而生:
-
首要构建原则是支持 OpenMetrics 协议,可以复用业界大量的*_exporter组件,降低开发对接的成本。
-
nms-prometheus-scraper 是专门为采集服务而开发的,解决了prometheus 在只作为采集服务时内存占用超大的问题;nms-prometheus-scraper 采集服务,采集指标后不落盘,直接写后端存储,效率极大提升。
-
为了应对大规模的采集需求,nms-prometheus-scraper+mysql 构建了分布式集群管理能力;采集目标和分组在mysql中管理,nms-prometheus-scraper 基于目标分组来做采集负载均衡,这种不依赖于复杂度第三方组件的设计模式,极大地降低的运维复杂度。
-
为了提高指标的可读性,我们通过内置通用的指标计算服务,方便用户对指标做进一步的加工,如常见的纵表转横表,counter 类型的数据转换为比率,一些数据差值计算等。
通过上述优化改进,使用 nms-prometheus-scraper 可达到更高的采集处理性能,降低损耗的设计初衷。
浩鲸科技指标采集服务平台功能架构:
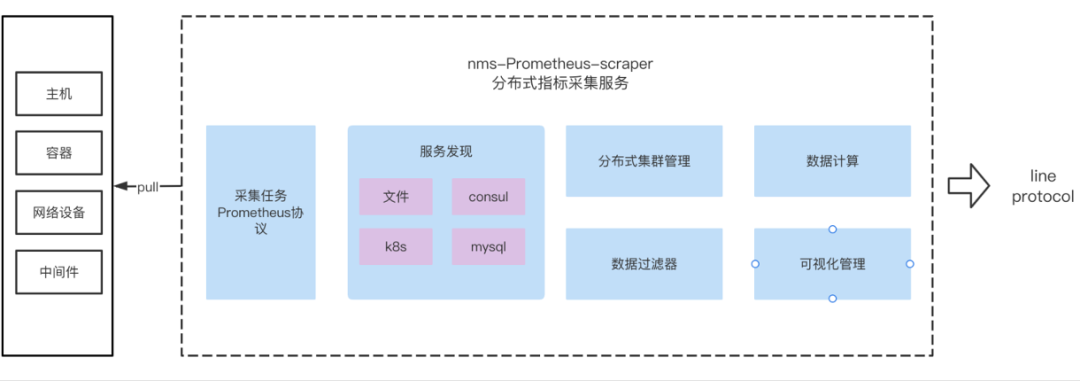
nms-prometheus-scraper 分布式采集服务,对比原生 prometheus 具备如下优势:
-
原生的分布式能力支持,可弹性伸缩。
-
支持 Prometheus 原生服务发现能力、文件、consul、k8s等。
-
业界绝大多数的 cmdb 后端存储在 mysql 数据库中,分布式采集服务增加针对mysql的目标服务发现能力,方便资源的一键接入服务发现。
-
数据不落盘,采集后直写分布式时序数据集群。
-
绝大部分的指标原始数据不具备可读性,需要进行函数运算才能更好的表达业务语义。分布式采集服务提供了数据运算,纵转横等能力,使得数据更具可读性和符合用户使用习惯。
-
高性能,低损耗。3000+主机、采集频度30s、6.7万points/s、nms-prometheus-scraper,内存占用是Prometheus的1/8, cpu使用率是Prometheus的1/7。
>>>>解决InfluxDB单点隐患的分布式时序存储
InfluxDB 作为时序数据库领域的领导者,被广泛运用。在一些中小型的项目中,InfluxDB 以单点的高性能、易用性以及自运维等优势是时序数据库的首选。但原生的 InfluxDB 开源版本,不支持分布式集群的方案,无法在超大规模,超高可用性要求的项目下落地。为了解决这个问题,可采用分布式时序存储方案,基于中间件代理模式构建分布式的 influxdb 分布式存储集群。
-
分布式集群首先要能够支持 InfluxDB 的标准 http 协议,支持查询和写入。能够面向上层透明,方便无缝切换。
-
可以基于多种的分片算法来分片路由管理时序数据,达到水平扩展的能力。
-
分布式集群要支持多副本的能力,支持副本个数可配置,解决企业级的高可用需求。
构建完的分布式指标存储服务具备如下的优势:
-
分布式集群,数据支持多副本容灾满足企业级数据安全的规范和高性能的要求,可支持百万级指标实时写入。
-
支持 influxdb 标准协议,面向上层透明,无缝对接,grafana,influxdb web console,InfluxDB SDK。
-
可视化的分片管理,管理运维复杂度低。
-
分布式集群版本支持 InfluxDB 标准函数。
-
分布式集群支持 InfluxDB 常用命令,如数据库管理,measurement管理,存储策略管理,连续查询管理等。
-
分布式服务代理,支持数据预加工与补齐。
-
InfluxDB 支持的存储策略,连续查询能力,可实现自动清理和归档,降低现场运维投入。
>>>>构建计算和存储分离的流批一体计算平台
Kapacitor 与 InfluxDB 都源于 influxData 技术栈下,基于 golang 开发,高性能,轻量化原生的 Kapacitor 存在如下三个劣势:
-
默认情况下,Kapacitor 可自动订阅InfluxDB数据源,数据在写入到 Influxdb 时,InfluxDB 会主动推送数据到订阅者。这种模式下,如果指标存储 InfluxDB 异常,将影响 Kapacitor 的指标计算
-
Kapacitor 是单点的模式,无法支持海量指标的计算处理需求。
-
基本上所有的流式计算框架,计算任务的配置和管理都存在一定的门槛;而计算阈值的调整,计算任务管理是现场运维的高频操作;降低任务配置门槛成为了分布式计算框架的核心关注点。
浩鲸科技流批一体计算平台功能架构:
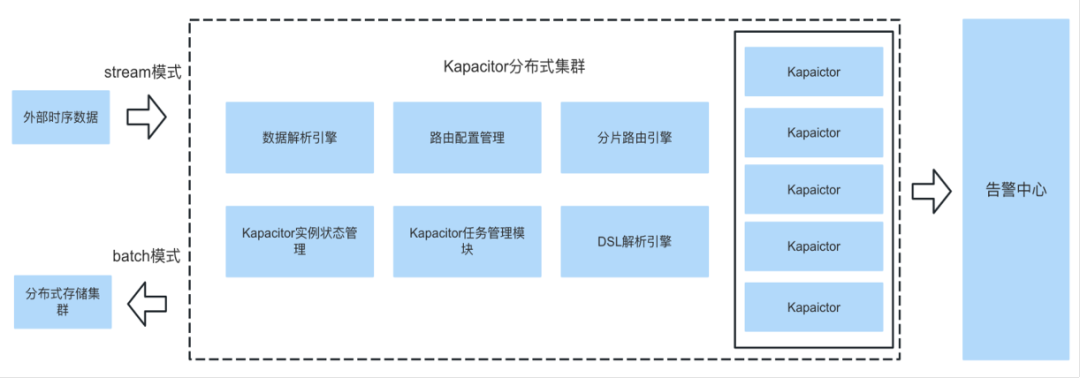
基于 Kapacitor 的劣势制约了其在大规模实时计算领域的落地效果,浩鲸科技的流批一体计算平台,从下面几个的架构提升点来解决这些问题:
-
在面向单点的问题,流批一体的实时计算方案采用和分布式时序存储方案一致的架构思路,通过中间件代理的模式来路由转发数据,达到分布式集群的能力。Kapacitor 不再直接订阅 InfluxDB 实例,而是直接监听中间件代理;外部数据写入时,写入中间件代理,由代理配置的路由转发规则,将数据路由到不同的kapacitor实例上。既解决了 kapacitor 单点的隐患,也解除了Kapacitor 计算程序,与 InfluxDB 存储程序的耦合。
-
对于运维复杂度门槛高的问题,流批一体的计算平台,通过可视化导航管理配置界面来与 Kapacitor 的 TICKscript 做转换,用户配置计算规则不需要直面门槛更高的领域脚本。当前可视化配置,可以支持95%实时计算告警场景。
最终,浩鲸科技通过自建基于 OpenMetrics 规范的分布式采集服务,优化InfluxDB存储为分布式架构,并结合Kapacitor打造流批一体计算平台,实现了高效、可扩展且易于管理的百万级指标采集、处理与计算解决方案。