介绍
人工智能研究实验室 OpenAI 最近宣布,他们已经开源了知识库检索插件的代码。 我参与的这个项目允许 ChatGPT 通过从各种数据源的相关文档片段中检索基于知识的数据来扩充其信息。 在这篇博文中,我将讨论这个项目的意义及其为企业带来的好处。
知识库检索插件
知识库检索插件是一种允许 ChatGPT 从外部托管的相关文档片段中检索信息的工具。 ChatGPT 可以通过提问或用自然语言表达需求,从您收集和存储的各种来源(如文件、笔记或电子邮件)中检索相关数据。 此功能为 ChatGPT 提供了一种简单高效的信息检索方式,使其更加准确可靠。
对企业的好处
通过 ChatGPT 向员工提供内部文档,企业可以从此插件中受益匪浅。 这为员工提供了一种简化的方式来从内部文档中检索信息,而无需搜索多个来源。 它还确保检索到的信息是准确的和最新的。 开发人员还可以使用此插件来托管他们自己的知识库,从而更轻松地从他们自己的来源检索数据。
怎么运行的
该插件使用 OpenAI 的 text-embedding-ada-002 嵌入模型生成文档块的嵌入,然后将嵌入存储和查询到矢量数据库中。 这就是我的切入点。我与 OpenAI 团队合作,使 Milvus 和 Zilliz 成为存储这些嵌入的首选矢量数据库之一。
简单的 API 公开了插件的端点,用于更新、查询和删除文档。 您可以使用元数据过滤器按来源、日期、作者等优化他们的搜索结果。为了让 Milvus 或 Zilliz 更新最新文档,该插件可以持续处理和存储来自各种数据源的文档,使用传入的 webhooks 进行更新和删除 端点。
下面是一个使用 Zilliz 插件查找 Apple 服务条款 (TOS) 中的 DRM 政策的简单示例。 ChatGPT 首先在 Zilliz Cloud 中搜索提示,然后总结结果。 ChatGPT 然后通过检索插件访问 Zilliz 以搜索最相关的数据。
如何设置 Zilliz Cloud
使用 Zilliz Cloud,您只需创建一个帐户并使用您的嵌入设置您的实例。 下面是快速入门指南和检索插件中需要配置的环境变量:
配置完成后,运行以下测试以确认集成正在使用此命令。
pytest ./tests/datastore/providers/zilliz/test_zilliz_datastore.py
如何设置 Milvus
当然,如果你更喜欢开源的 Milvus,你可以使用 Docker Compose、Helm、K8 的 Operator 或 Ansible 来部署和管理 Milvus。 按照此处的说明开始。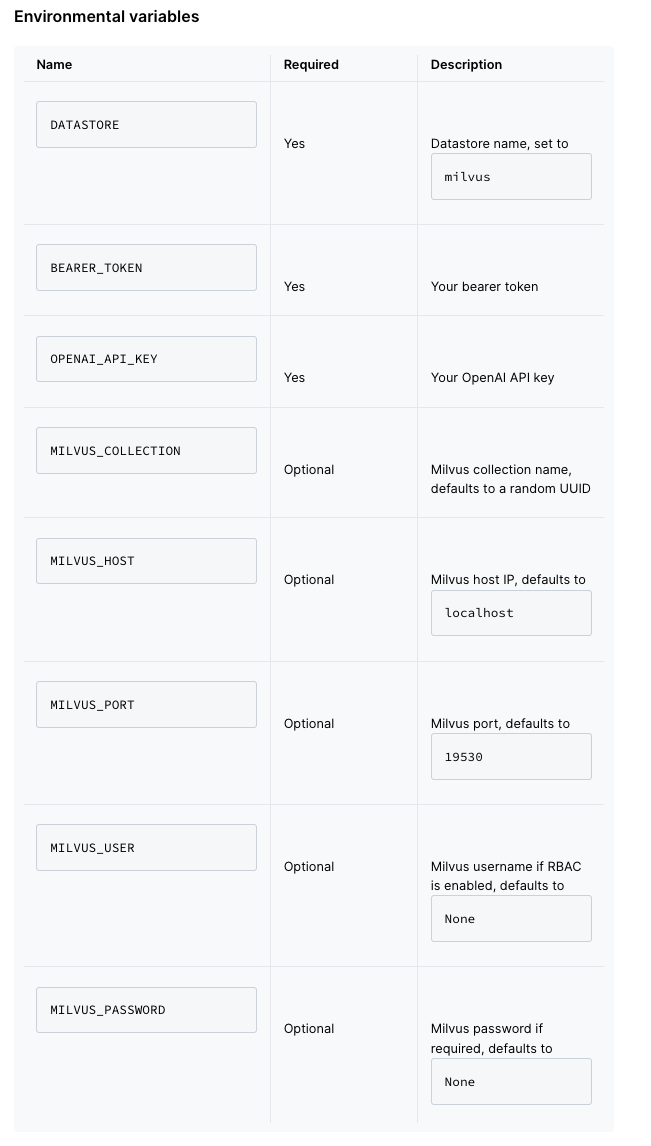
配置完成后,运行以下测试以确认集成正在使用此命令。
pytest ./tests/datastore/providers/milvus/test_milvus_datastore.py
部署插件
通过测试插件,我们可以开始部署它。 ChatGPT 通过向运行插件服务器的任何地方发送请求来访问插件,无论是 Amazon ECS、Fly.io、Heroku 等。有关如何配置它的详细指南,请查看 GitHub 自述文件中的部署部分。
记忆功能
这个新插件的一个很酷的特性是他们称之为内存的特性。 这使 ChatGPT 能够记住对话中的信息并将其存储在矢量数据库中供以后使用。