基本概念
术语
- 文档(document):每条记录就是一个文档,会以 JSON 格式进行存储

- 映射(mapping):索引中文档字段的约束信息,类似 RDBMS 中的表结构约束(schema)
- 词条(term):对文档内容分词得到的词语,是索引里面最小的存储和查询单元
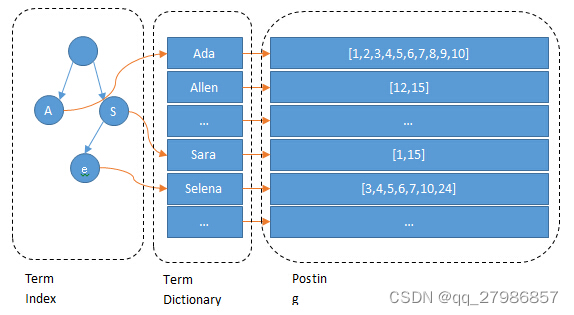
- 词典(term dictionary):由文本集合中出现过的所有词条所组成的集合
- 词条索引(term Index):为了在词典中快速找到某个词条,需要为词条建立索引。通过压缩算法,词条索引的大小只有所有词条的几十分之一,因此词条索引可以存储在内存中,从而提供更快的查找速度
- 倒排表(posting list):记录词条出现在哪些文档里,以及出现的位置和频率等信息。倒排表中的每条记录称为一个倒排项(posting)
- 索引(index):相同类型(文档结构)的文档集合
索引前的文档集合:

索引后的文档集合:

8.
比较
- RDBMS vs ES

- 使用场景:MySQL 擅长于事务类型操作,可以确保数据的安全性和一致性;ES 则擅长于海量数据的检索、分析与计算。
MySQL + ES 组合使用架构:

语法
DDL
类型

注意:index 默认为 true,即 ES 会默认给设置的字段设置倒排索引,如无需设置倒排索引需要手动设置为 false
语法示例
PUT /索引库名称
{"mappings": { // 定义 schema"properties": { // schema 的具体字段极其类型说明"字段1": {"type": "text""analyzer": "ik_smart"},"字段2": {"type": "keyword","index": false},"字段3": {"type": "object","properties": { // 嵌套字段"子字段1": {"type": integer"index": false}}}}}
}GET /索引库名DELETE /索引库名// ES 禁止修改索引库已有字段,只允许新增字段
PUT /索引库名/_mapping
{"properties": {"新字段名": {"type": "long""index": false}}
}
DML
新增文档
POST /索引库名/_doc/文档id
{"字段1": "值1","字段2": {"子字段1" : "子值1"}
}
查询/删除文档
GET /索引库名/_doc/文档idDELETE /索引库名/_doc/文档id
修改文档
- 全量修改
PUT /索引库名/_doc/文档id
{"字段1": "值1","字段2": {"子字段1" : "子值1"}
}
注意:当 文档id 指定的文档不存在时,就是新增文档
- 局部修改
POST /索引库名/_update/文档id
{"doc": {"字段2": {"子字段1" : "子值1"}}
}
DSL 查询

语法
全文检索
会先对用户输入的类型进行「分词」,然后去倒排索引库去检索
// 全部查询
GET /索引库名/_search
{"query": {"match_all": {}}
}// match 查询
GET /索引库名/_search
{"query": {"match": {"字段名": "字段值"}}
}// multi_match 查询,注意参与查询字段越多,查询性能越差
GET /索引库名/_search
{"query": {"multi_match": {"query": "字段值""fields": ["字段名1", "字段名2"]}}
}
精确查询
直接使用提供的值进行匹配查询,而不会先进行分词操作
// term 查询
GET /索引库名/_search
{"query": {"term": {"字段名": {"value": "字段值"}}}
}// range 查询
GET /索引库名/_search
{"query": {"range": {"字段名": {"gte": "字段值1", // >="lte": "字段值2", // <=}}}
}
地理查询
复合查询

打分算法原理
TF刻画了词语w对某篇文档的重要性,IDF刻画了w对整个文档集的重要性。TF与IDF没有必然联系,TF低并不一定伴随着IDF高。实际上我们可以看出来,IDF其实是给TF加了一个权重。

新版 ES 都默认使用 BM25 作为打分算法。
BM25 考虑到了文档长度对于 TF 的影响。在 TF-IDF 中,长文档可能会因为包含更多的词而得到较高的 TF 值。为了消除这种影响,BM25 引入了文档长度归一化,使得长文档和短文档在计算 TF 时能够处于同一水平。BM25 相对 TF-IDF 有哪些优势?
TF-IDF 存在的问题
- 在一个相当长的文档中,像 the 和 and 这样词出现的数量会高得离谱,以致它们的权重被人为放大。

- Bool 查询

搜索结果处理
排序

分页

深分页问题

深分页解决方案:

ES 深分页问题解决方案
search_after 是 ES 5 新引入的一种分页查询机制,其实 原理几乎就是和 scroll 一样,简单总结如下:
- 必须先要 指定排序;
- 必须 从第一页开始;
- 从第一页开始,以后每次都带上 search_after=lastEmittedDocFieldValue 从而为无状态实现一个状态,其实就是把每次固定的 from + size 偏移变成一个确定值 lastEmittedDocFieldValue,而查询则从这个偏移量开始获取 size 个 _doc(每个 shard 获取 size 个,coordinate node 最后汇总 shards * size 个)。
也就是说,无论去到多少页,coordinate node 向其它 node 发送的请求始终就是请求 size 个 docs,是个常量,而不再是 from + size 那样,越往后你要请求的 docs 就越多,而要丢弃的垃圾结果也就越多。也就是说,如果要做非常多页的查询时,最起码 search_after 是一个常量查询延迟和开销。
高亮

注意:ES 默认要求搜索字段与高亮字段一致才会高亮显示。设置 “require_field_match”: false 则可以忽视该规定
倒排索引原理
倒排索引建立的是分词(Term)和文档(Document)集合之间的映射关系,在倒排索引中,数据是面向词(Term)而不是面向文档的。
在数据生成的时候,比如插入一份文档,内容是“小米手机与华为手机”,这个时候通过使用分词器,会将它分解为“小米”、“手机”、“与”、“华为”四个词语,然后可能还会把“与”这个无具体意义的关联词语干掉,最后生成一张倒排表。

每搜索一个单词,就对倒排表进行全局遍历,效率特别低,所以需要对倒排表进行排序,以便采用二分查找等方式提高遍历效率。另一方面,光使用排序还会因磁盘 IO 导致查询速度过慢,若将数据放全部入内存,又会导致内存爆满。所以,在倒排表的基础上,又通过 FST (trie、FSA、FST(转))的形式引入了 term index,它不存储所有的单词,只存储单词前缀,并将其完全放入到内存中,通过字典树找到单词所在的块(单词的大概位置),再在块里进行二分查找,找到对应的单词,再找到单词对应的文档列表。
FST
Lucene的FST(Finite-State Transducers)是一种高效的数据结构(变种的trie树,trie树只共享了前缀,而 FST 既共享前缀也共享后缀。),是Lucene用来构建和管理自动机的一部分,它具有高度的压缩性和空间效率,能够帮助Lucene提高搜索和排序的效率。在FST中,任何字符串都可以看作一个有限状态机,每个状态代表着字符串的某个前缀。FST基于原理:序列化哈希值,通过将无序键序列化到字节数组中,强制所有的比较和排序在序列化字节上进行。
聚合

自动补全
type: “completion”
数据同步
场景
- ElasticSearch 结合工具 LogStash、 Kibana (ELK)进行日志分析、实时监控。
问题
慢查
- 使用 search 查询时,指定的查询条件不够精准,导致查询范围过大
- 返回的 id 过多,在协调节点做排序截断时,会产生比较大的 CPU 压力
- 返回的 id 过多,会导致第二步通过 id 请求数据 node 获取文档详细时,使得数据节点以及协调节点产生大量的 IO 操作,以及 CPU 消耗
seaerch 查询
GET /my-index/_search

- Client 将请求发送到任意节点 node,该 node 节点成为协调节点(coordinating node)
- 协调节点进行分词等操作后,去查询所有的数据节点 shard (primary shard 和 replica shard 选择一个)
- 所有数据节点 shard 将满足条件的数据 id、排序字段等信息返回给协调节点
- 协调节点重新进行排序,再通过截取数据后获取到真正需要返回的数据 id
- 协调节点再次请求对应的数据节点 shard (此时有 id 了,可以直接定位到对应 shard),获取数据文档
- 协调节点从数据节点获取到全量数据文档后将其返回给 Client
ID 查询
GET my-index/_doc/0

- Client 将请求发送到任意节点 node,该 node 节点就是协调节点(coordinating node)。
- 协调节点对 id 进行路由,从而判断该数据在哪个 shard。
- 从 primary shard 和 replica shard 随机选择一个,请求获取 doc。
- 接收请求的节点会将数据返回给协调节点,协调节点会将数据返回给 Client
其它
- ElasticSearch 高手之路:ES 查询语法文档
- Elasticsearch 倒排索引原理
- 为什么 ElasticSearch 比 MySQL 更适合复杂条件搜索
思考
ElaticSearch 为什么快

ES vs MySQL
Elasticsearch 比 MySQL 快的原因
- 基于分词后的全文检索:例如 select * from test where name like ‘%张三%’,对于 mysql来说,因为索引失效,会进行全表检索;对 ES 而言,分词后每个字都可以利用 FST 高速找到倒排索引的位置,并迅速获取文档 id 列表,大大的提升了性能,减少了磁盘IO。
- 精确检索:有时 MySQL 可能更快一些,比如当 MySQL 通过索引覆盖,无需回表查询时;ES 始终会通过 FST 找到倒排索引的位置获取文档 id 列表,再根据文档id获取文档并根据相关度进行排序。另外 ES 还有个优势,分布式架构使其在进行大量数据搜索时,可以通过分片降低检索规模,并且通过并行检索提升效率,使用 filter 操作时,更是可以直接跳过检索直接走缓存。

![[MRCTF2020]Ez_bypass1](https://img-blog.csdnimg.cn/direct/53bf51419c1d4b669e038a118fb983bf.png)