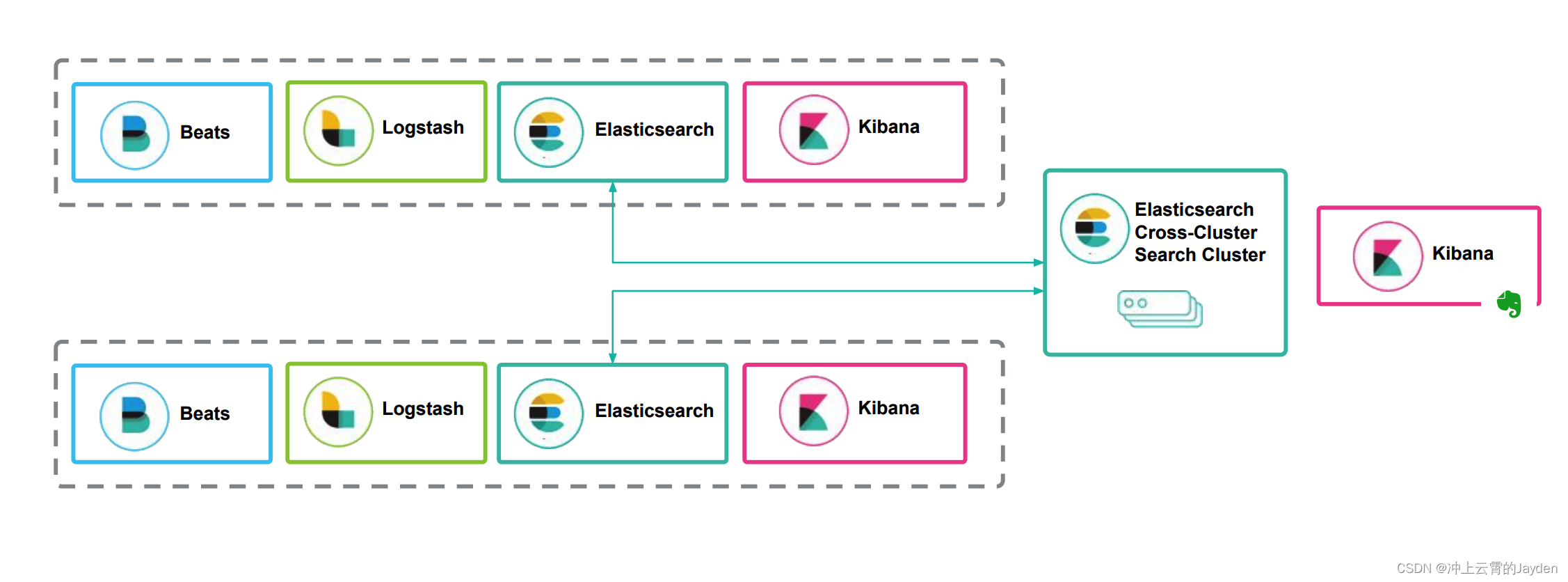
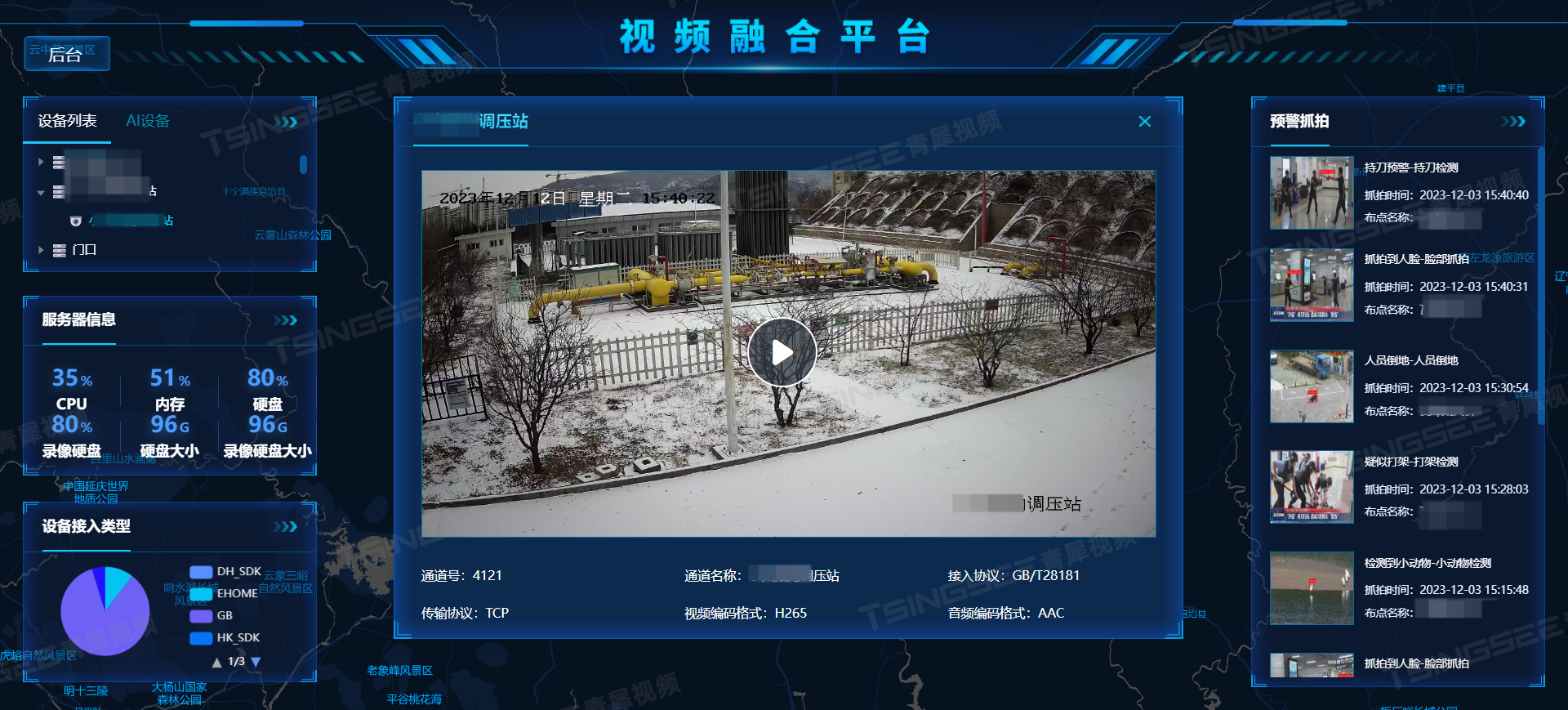
文章目录
- wordcloud库的简单示范
- 使用wordcloud库报错记录
- anaconda安装第三方jieba库
- jieba库的简单示范
- 任务 1:三国演义中的常见词汇分布在“三国"这两个隶书字上,出现频率高的词字体大
- 任务 2:三国演义中出现频率前十的人名。必须是以下这十个名字,名字组成心形
wordcloud库的简单示范
from wordcloud import WordCloud
from wordcloud import ImageColorGenerator
from PIL import Image
import numpy as nptxt = "Python Java C++ JavaScript PHP Ruby Swift Kotlin Go Rust" # 示例文本# 创建词云对象,配置参数
c = WordCloud(width=400,height=400,font_path=None,repeat=True, # 表示单词是否可以重复出现mask=np.array(Image.open("love.png")), # 给词云生成轮廓用的参数,不需要做成轮廓的背景应为白色background_color="white", # 背景颜色max_words=150 # 词云的最大单词数
)
c.generate(txt) # 指定词云的文本文件
c.to_file("词云图.jpg") # 将生成的词云文件输入到一个文件中使用wordcloud库报错记录
在使用wordcloud库的时候,运行报错:ValueError: Only supported for TrueType fonts
解决方案:去升级pillow库!!!
anaconda安装第三方jieba库
- 打开Anaconda Prompt,并进入目标环境。输入 activate 环境名
- 输入 pip install jieba
- 如果因为网络原因而下载失败,可使用清华大学镜像(99.9%解决下载失败问题):
pip install 名称 -i https://pypi.tuna.tsinghua.edu.cn/simple
jieba库的简单示范
import jiebas = "中国是一个伟大的国家"s1 = jieba.lcut(s) # 精确模式
print(s1)s2 = jieba.lcut(s, cut_all=True) # 全模式
print(s2)s3 = jieba.lcut_for_search(s) # 搜索引擎模式
print(s3)# jieba.add_word(str) 向分词词典添加新词 str
任务 1:三国演义中的常见词汇分布在“三国"这两个隶书字上,出现频率高的词字体大
from wordcloud import WordCloud
from wordcloud import ImageColorGenerator
from PIL import Image
import numpy as np
from jieba import *def getText(filename):text = open("{}".format(filename), encoding='utf-8').read()sign = '''!~·@¥……*“”‘’\n(){}【】;:"'「,」。-、?\u3000\ufeff'''for ch in sign: # 特殊符号替换成空格text = text.replace(ch, ' ')return textdef wordCount(text, N):words = lcut(text) # 精确分词counts = {} # 字典类型for word in words:if len(word) < 2:continueif word not in counts:counts[word] = 0else:counts[word] += 1temp = sorted(counts.items(), key=lambda d: d[1], reverse=True) # 按计数值逆序排序result = dict(temp[1:N+1])return resultdef drawWordCloud(data, N):# 创建词云对象,配置参数c = WordCloud(width=400,height=400,font_path="C:\Windows\Fonts\STXINGKA.TTF", # 设置字体repeat=False, # 表示单词是否可以重复出现mask=np.array(Image.open("三国.png")), # 给词云生成轮廓用的参数,不需要做成轮廓的背景应为白色background_color="white", # 背景颜色max_words=N # 词云的最大单词数)result_str = ' '.join(data.keys())c.generate(result_str) # 指定词云的文本文件c.to_file("自制结果1.jpg") # 将生成的词云文件输入到一个文件中if __name__ == '__main__':N = 200text = getText('三国演义utf8.txt')result = wordCount(text, N)drawWordCloud(result, N)
运行结果:

任务 2:三国演义中出现频率前十的人名。必须是以下这十个名字,名字组成心形
十个名字:刘备、赵云、关羽、周瑜、曹操、孔明、孙权、司马懿、张飞、吕布
from wordcloud import WordCloud
from wordcloud import ImageColorGenerator
from PIL import Image
import numpy as np
from jieba import *def getText(filename):text = open("{}".format(filename), encoding='utf-8').read()sign = '''!~·@¥……*“”‘’\n(){}【】;:"'「,」。-、?\u3000\ufeff'''for ch in sign: # 特殊符号替换成空格text = text.replace(ch, ' ')return textdef wordCount(text, N):words = lcut(text) # 精确分词counts = {} # 字典类型name = ["刘备", "赵云", "关羽", "周瑜", "曹操", "孔明", "孙权", "司马懿", "张飞", "吕布"]for word in words:if word in name:if word not in counts:counts[word] = 0else:counts[word] += 1else:continuetemp = sorted(counts.items(), key=lambda d: d[1], reverse=True) # 按计数值逆序排序result = dict(temp[:N])return resultdef drawWordCloud(data, N):# 创建词云对象,配置参数c = WordCloud(width=400,height=400,font_path="C:\Windows\Fonts\STXINGKA.TTF", # 设置字体repeat=False, # 表示单词是否可以重复出现mask=np.array(Image.open("love.png")), # 给词云生成轮廓用的参数,不需要做成轮廓的背景应为白色background_color="white", # 背景颜色max_words=N # 词云的最大单词数)result_str = ' '.join(data.keys())c.generate(result_str) # 指定词云的文本文件c.to_file("自制结果2.jpg") # 将生成的词云文件输入到一个文件中if __name__ == '__main__':text = getText('三国演义utf8.txt')result = wordCount(text, 10)drawWordCloud(result, 10)运行结果: