作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬
学习必须往深处挖,挖的越深,基础越扎实!
阶段1、深入多线程
阶段2、深入多线程设计模式
阶段3、深入juc源码解析
阶段4、深入jdk其余源码解析
阶段5、深入jvm源码解析
码哥源码部分
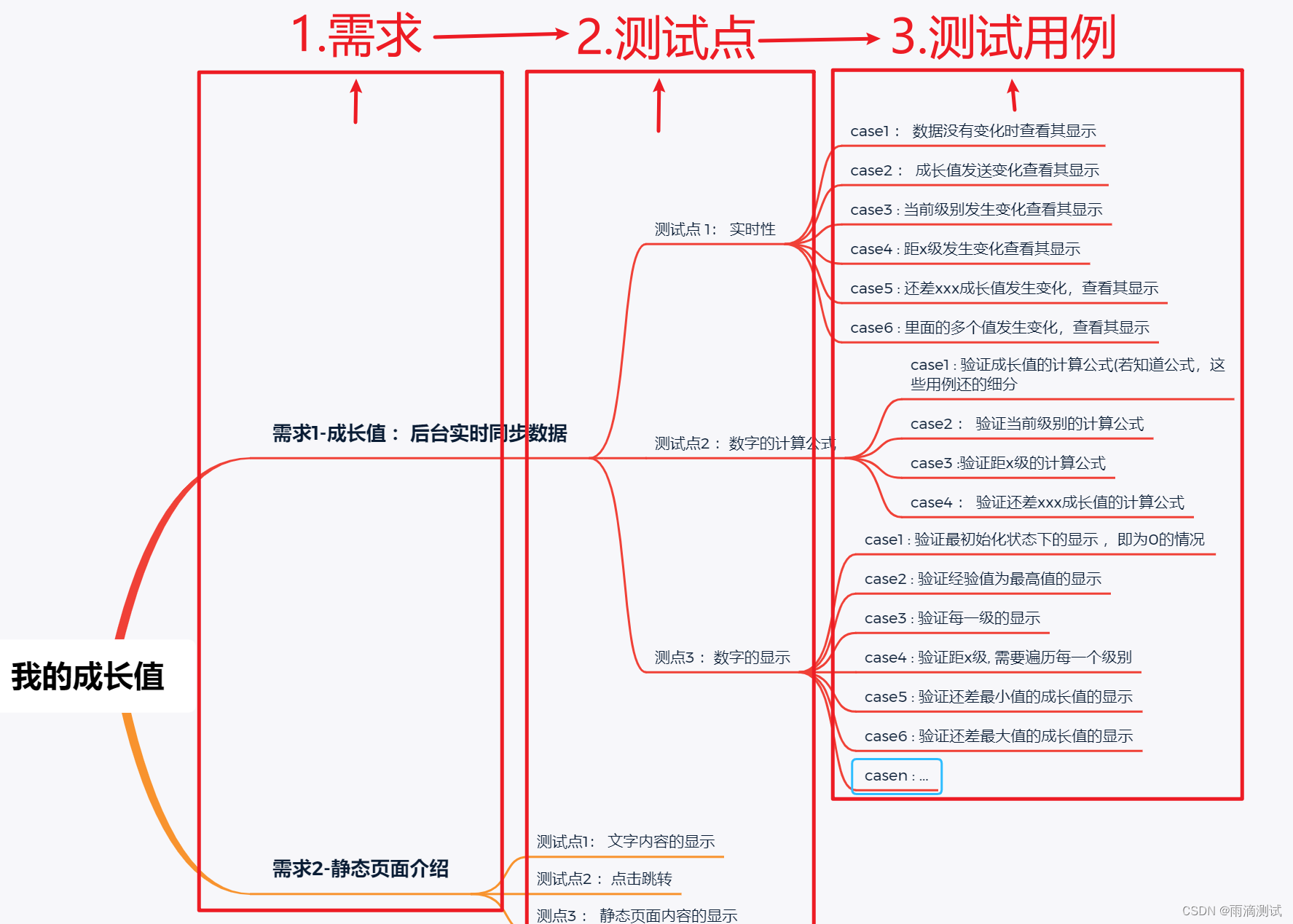
码哥讲源码-原理源码篇【2024年最新大厂关于线程池使用的场景题】
码哥讲源码【炸雷啦!炸雷啦!黄光头他终于跑路啦!】
码哥讲源码-【jvm课程前置知识及c/c++调试环境搭建】
码哥讲源码-原理源码篇【揭秘join方法的唤醒本质上决定于jvm的底层析构函数】
码哥源码-原理源码篇【Doug Lea为什么要将成员变量赋值给局部变量后再操作?】
码哥讲源码【你水不是你的错,但是你胡说八道就是你不对了!】
码哥讲源码【谁再说Spring不支持多线程事务,你给我抽他!】
终结B站没人能讲清楚红黑树的历史,不服等你来踢馆!
打脸系列【020-3小时讲解MESI协议和volatile之间的关系,那些将x86下的验证结果当作最终结果的水货们请闭嘴】
引言
在互联网、大数据、人工智能火爆的今天,“算法”这个词几乎妇孺皆知,业已成为“高薪”“牛X”的代名词。
应不少朋友的邀请,特连载本系列,旨在用最通俗的方式——“”讲人话、无废话、看得懂、用得上“”——将位于神龛之上的算法送进寻常百姓家。
本篇作为系列的第一篇,采用“What、Why、How”文章结构,来给大家普及一下算法的基本概念(也纠正一些朋友的错误概念)。
What is Algorithm?(算法是个什么鬼 )
为了不落入俗套,本文不会重复wiki上“算法”的官方定义,而采用启发式结构来阐述算法的本质,试想平时在遇到问题的时候,我们是如何解决的。
朴素而广泛的过程方法论如下:
-
重新定义问题,结构化描述
-
根据重定义,归类问题
-
根据问题类别,做经验匹配
-
根据匹配结果,分支处理:若匹配,采用经验方法;若匹配不上,设计开发新方法
-
迭代更新经验库,增强面向未来问题的能力
与算法相关的就是上面的第3步~第5步。
简单来说,算法本质是:解决某类问题的方法。如果方法已经在经验库里了,直接拿来主义,也就是“既有算法”;如果不在,那么设计开发的新方法,新方法就是“新算法”。
当然还有一种情况:虽然经验库里有针对该类问题的方法了,但是设计开发了一个更有效的新方法,那么也称为“新算法”。下面来对几个关键点进行阐述!!!
什么是“更有效的算法”?
“更有效”的背后逻辑其实比较的就是“代价”,或者称为“开销”。经济上衡量就是成本,它分为两个维度:时间成本和资源成本。
资源成本在计算机上的体现就是硬盘、内存、CPU等一系列硬件资源开销。对这些硬件资源开销进一步抽象,就是空间成本。
算法其实从学科分类上讲,属于计算数学,计算数学属于应用数学。用学科术语来描述时间成本与空间成本,就是计算复杂度,很自然地,它也有两个维度:时间复杂度和空间复杂度。描述复杂度的数学符号是O()。后面我们会详细介绍O()的表达。
综上所述,所谓的“更有效”的算法,指的就是时间复杂度或者空间复杂度更优的算法。
为什么要“重新定义问题,结构化描述”?
把人脑也看做一台机器的话,很显然这台机器的运行方式和效率与计算机有所不同(尽管现在的机器学习在尽可能地模拟人脑的机理,但是两者至少在现阶段还有本质不同)。
人脑在连续信号和非结构化场景下的处理能力是卓越的,但是计算机只能处理离散信号,并且必须最终转化成结构化数据才能进行处理(尽管现在的机器学习可以通过自我学习来将数据结构化)。
用一张图来描述这个过程就是:

Why to use Algorithm?(算法有什么鬼用)
从上面对解决现实问题的过程方法论的描述中,其实已经可以看出算法的价值就在于:经验的重用。
套用一句IT行话就是“不要重复制造轮子”。好了,既然现在你已经对算法有了大致的感性认识,那么接下来根据人类的学习习惯,就需要来看看抽象的算法概念,在现实里到底“长什么模样”。
很多人认为“算法=程序或者程序”,这其实是一个狭义的理解。如前面所说的,算法的本质是解决某类问题的方法,而程序或者代码只是方法的一种表达形式而已。你也可以用自然语言或者伪代码来进行表达算法。
算法的“模样”(应对电灯不工作的算法——代码方式):
public STATUS_CODE lamp_issue_handler() { STATUS_CODE ret_val = UNKNOWN_ISSUE; if (!isPowerOn(this)) { ret_val = powerOn(this) ? NOT_POWER_ON_ISSUE : POWER_ISSE; } else if(!isBulbCrash(this)) { ret_val = replaceBulb(this) ? BULB_CRASH_ISSUE : REPLACE_ISSUE; } else { ret_val = fixBulb(this) ? BULB_FIXABLE_ISSUE : FIX_FAILURE_ISSUE;} return ret_val;}
算法的“模样”(应对电灯不工作的算法——自然语言方式):
首先检查电源是否接好了:没有接好,接上。
如果接上了仍然不工作,看看灯泡是否烧坏了:如果是,换个新灯泡
如果灯泡没有烧坏,修理灯泡
算法的“模样”(应对电灯不工作的算法——流程图方式):
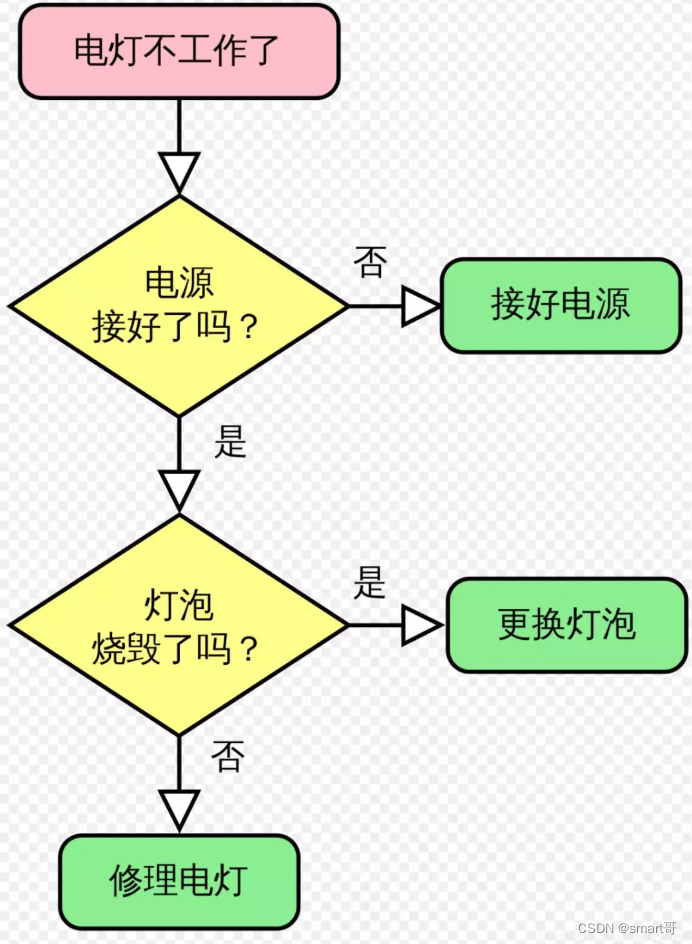
How to use Algorithm?(如何使用算法)
算法的本质就是方法,既然是方法,就是一系列的操作;既然是操作,就必然有作用对象。在软件程序设计中,这样的作用对象就是“数据结构”。
怎么来理解数据结构呢?
前面我们讲到了,解决问题的第一步就是要将问题结构化描述。结构化描述的本质就是利用一系列便于操作的“基础元素”来表达。
那么怎样的“基础元素”是便于操作的呢?
首先我们要清楚,操作的主体是谁。从上一段的阐述来看,这个主体貌似是算法,但是我们注意,算法不是凭空去运行的,是要在计算机上运行的。
所以归根结底,操作的主体是计算机。所以,这里所谓的“便于操作”指的是便于计算机运行。
计算机运行有两个维度:硬件维度和软件维度。
1.从硬件维度看:
学过计算机组成原理就知道,程序是在计算机的CPU高速缓存和内存中运行的。对应的存储结构,通常都是线性的。
为了充分提升线性结构的性能优势,硬件厂商(如CPU厂商)在设计硬件时,就抽象了针对一些结构(如堆栈)的操作(如压栈、出栈),所以很自然地,这样的结构就应该作为数据结构。
2.从软件维度看:
我们编写的应用程序一般不会直接运行在硬件之上,而是运行在操作系统、运行时或者虚拟机(如JVM)之上。
所以操作系统、运行时或者虚拟机已经抽象的结构(如数组、队列、树、图等),也应该作为数据结构。
上面赘述了这么多,其实就是要表达一个观点:算法是要配合数据结构的,抛开数据结构谈算法就是无源之水、无根之树。
看到这里,我想你一定彻底明白,为什么图灵奖得主尼古拉斯·沃斯会提出那个著名的等式了:程序 = 算法 +数据结构。
总结
看到这里,相信你已经对算法这个概念已经不再陌生,它对于你而言也不再高高在上。
无论在大学学习,还是在工作中,大家都几乎被一种说法反复洗脑:算法非常重要,它是计算机的灵魂。
在这里,我想纠正一下这个错误的观点。首先,广义的算法不仅仅只是软件算法;再次,计算机系统不仅仅只是由软件构成,还有硬件。
硬件涉及到材料科学、制造工艺等一系列技术,这些是不能简单被算法替代的。所以,脱离上下文、一味强调算法的重要性是耍流氓。